在谷歌的新闻中看到一篇权威论文,谷歌官方的AI专家测试了所有主流大语言模型(LLM),包括Gemini、ChatGPT、DeepSeek和Claude,发现一个简单的方法能显著提升AI问答的正确率。
这篇论文发表在康奈尔大学的arXiv上,发布于2025年12月17日,链接为:https://arxiv.org/pdf/2512.14982
通常,我们认为解决AI幻觉(不准确回答)的方法是编写更复杂的提示词(Prompt),甚至使用严厉语气。但Google Research在2025年12月发布的这篇论文指出:只需把提示词复制粘贴一遍,效果就能从“不可用”变成“完美”。
这听起来似乎过于简单,就像修电视机时“拍一下”一样。以下截图展示了Google Research论文中的示例,将Prompt直接输入两次。

这项技术被称为 “Prompt Repetition”(提示词重复),它如何改变工作流呢?
为什么 AI 总是“读不懂”我们的心?
在深入实战之前,需要理解AI的一个根本性缺陷。Google的研究员在论文《Prompt Repetition Improves Non-Reasoning LLMs》中指出,主流大语言模型(LLM)如Gemini、ChatGPT、Claude、DeepSeek都是“因果模型”。简单来说,它们阅读的方式是单向的,只能从左往右读,绝不回头。
想象一下,给你一份50页的文档,让你在读的过程中找出“所有提到价格的地方”,但指令写在最后一行。你在读前49页时,根本不知道要在意“价格”,所以看得漫不经心。当你读到最后一行指令时,前面的内容早已忘记。这就是AI常遇到的“中间迷失”(Lost in the Middle)现象。

这正是SEO内容生成和长文档调研时的典型场景:信息在前,指令在后。
科学实锤:重复即正义
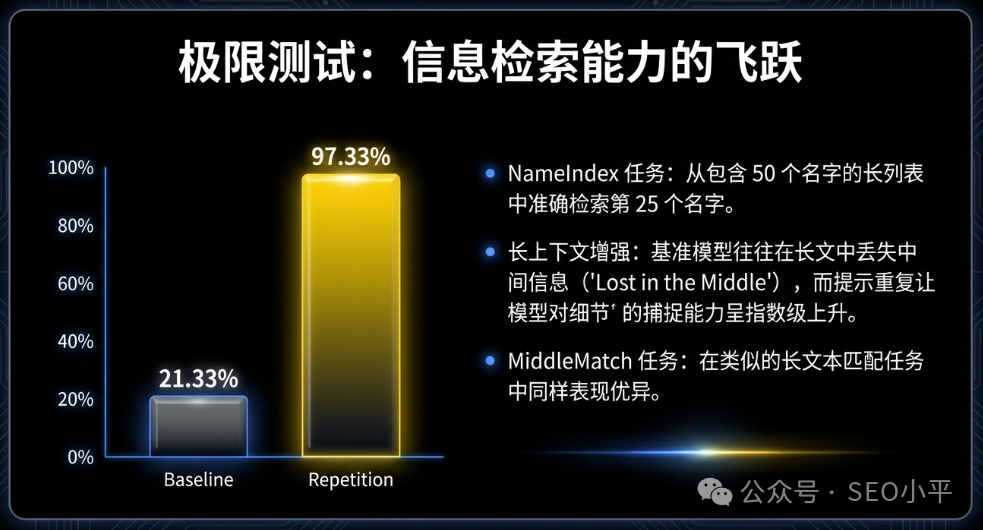
Google的团队发现了一个令人震惊的数据。他们设计了一个叫 NameIndex 的测试,本质上是在一大堆数据中找特定信息——这与竞品调研类似。
- 只说一次:模型的准确率只有 21.33%。
- 重复一次(RE2):模型的准确率飙升到了 97.33%。
仅仅把输入内容重复一遍,准确率提升了4倍多。为什么?因为在处理第二遍内容时,模型已经“预习”过了,它带着第一遍末尾的“问题”,重新审视第二遍的“内容”。这就像给了AI一双“透视眼”。

实战应用:如何用“笨办法”做聪明事
读完论文后,可以改良AI Prompt方法。以下是两个核心场景的应用:
场景一:深度的竞争对手调研(解决“数据遗漏”)
以前,把一份2万字的行业白皮书丢给AI,问它:“列出文中提到的所有公司及其市场份额。”结果通常是,只列出了开头和结尾的几家大公司,中间的黑马公司全漏了。
现在的做法(RE2策略):不再只发一次。设计Prompt如下:
[粘贴2万字白皮书]
[指令:请提取所有公司及市场份额]
--- (分割线) ---
[再次粘贴2万字白皮书]
[再次指令:请提取所有公司及市场份额]
效果:提取的数据量通常增加 30%-50%。隐藏在报告角落里的数据点被AI一个不落地抓出。虽然输入字数翻倍,但对于精准数据调研,这完全值得。
场景二:SEO 文章写作(解决“指令健忘”)
SEO对文章结构要求严格:必须包含特定LSI关键词,用H2/H3标签,甚至输出JSON格式。AI经常写着写着就“忘词”,导致关键词密度不够或格式乱套。
现在的做法(三明治重复法):不再把SEO要求只写在最后,而是采用“三明治”结构:
[第一层 - 核心指令]:主题:2026年数字营销趋势 核心关键词:AI代理、零点击搜索、视频SEO 格式要求:严格遵循H2-H3结构,关键词自然植入。
[第二层 - 参考素材]:(粘贴背景资料、参考文章...)
[第三层 - 重复指令]:重要提示:请再次确认你的任务: 主题:2026年数字营销趋势 核心关键词:AI代理、零点击搜索、视频SEO 格式要求:严格遵循H2-H3结构,关键词自然植入。
效果:这种重复就像对AI耳提面命。生成的文章中,关键词的覆盖率几乎达到100%,且出现位置更自然。对于输出JSON Schema的技术性SEO任务,格式错误率几乎为零。

大家关心的成本问题:会变贵吗?
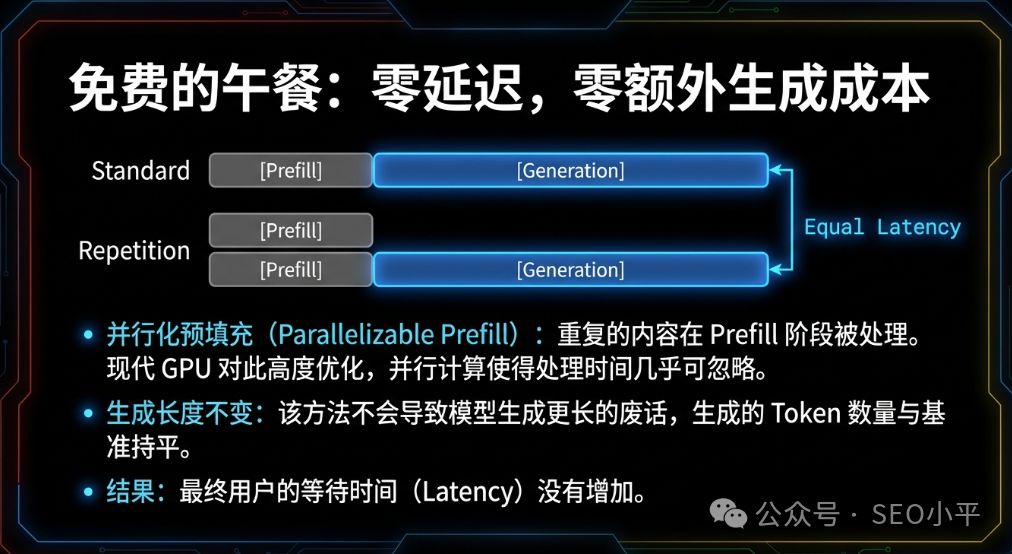
输入内容翻倍,API费用会增加吗?需要算一笔账:
- 输入比输出便宜:在DeepSeek或GPT-4o-mini等模型中,输入Token价格极低(通常只有输出价格的1/10甚至更低)。
- 缓存红利(Prompt Caching):主流模型(DeepSeek, Claude, Gemini)支持“提示词缓存”。如果重复发送相同的大段背景资料(Prefix),第二次的成本几乎可以忽略不计。
- 避免返工:以前因AI漏数据,需要人工复核半小时或重新生成三次。现在一次搞定。在这个“人工比算力贵”的时代,多花几分钱的Token费来节省半小时人力,简直是暴利。
我们正处于有趣的AI阶段。一方面,模型越来越聪明;另一方面,它们依然有像“只能从左往右读”这样的原始局限。
Google的这篇论文提醒我们,有时最有效的解决方案不是寻找更高级的模型,而是回归最朴素的逻辑:重要的事情说两遍。
如果你的AI在做数据提取、格式转换或遵循复杂SEO规则时表现不稳定,别急着怀疑模型,试试Ctrl+C,Ctrl+V。这可能就是你离“完美结果”之间那层还没捅破的窗户纸。
更多技术讨论,欢迎访问云栈社区。
 发表于 2026-1-21 03:14:03
|
查看: 177|
回复: 0
发表于 2026-1-21 03:14:03
|
查看: 177|
回复: 0
