GB10 是英伟达与联发科合作的产物,它将英伟达全新的 Blackwell 架构集成到了 GPU 中。这颗 GPU 拥有多达 48 个 Blackwell SM 单元,其核心数量与桌面级的 RTX 5070 相当。CPU 部分则配置了 10 个 Cortex X925 高性能核心与 10 个 Cortex A725 高能效核心,计算规格非常可观。如此强大的算力自然需要一个相匹配的内存子系统来支撑,这也不可避免地带来了一些性能上的取舍。
本文将聚焦于分析 GB10 的内存子系统性能,并从 CPU 端开始深入探讨。
片上系统布局
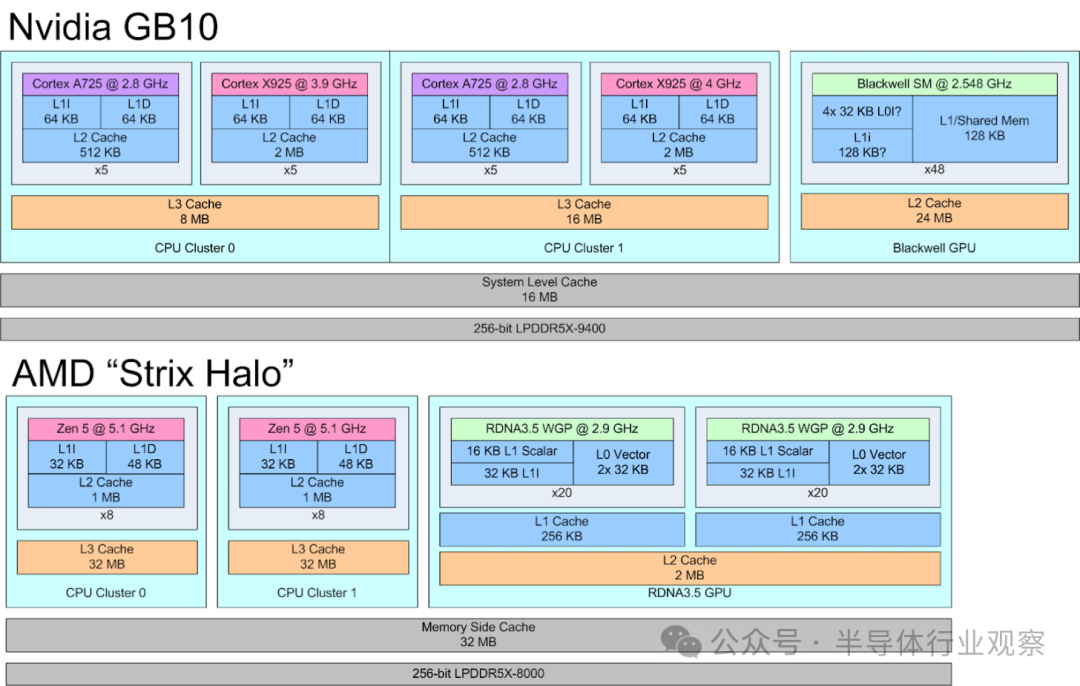
GB10 的 CPU 核心被划分为两个集群(Cluster)。每个集群都包含了 5 个 A725 核心和 5 个 X925 核心。核心编号从每个集群内的 A725 核心开始,两个集群依次排列。所有的 A725 核心运行频率均为 2.8 GHz。X925 核心在第一个集群(Cluster 0)中的最高频率可达 3.9 GHz,而在第二个集群(Cluster 1)中则能达到 4 GHz。
缓存和内存访问
Arm 的 A725 和 X925 处理器都支持可配置的缓存容量。GB10 为这两种核心都选择了 64 KB 的 L1 指令缓存和数据缓存。所有 A725 核心均配备了 512 KB 的 L2 缓存,而所有 X925 核心则拥有 2 MB 的 L2 缓存。
A725 的 L2 缓存为 8 路组相联,延迟仅为 9 个时钟周期。考虑到其 2.8 GHz 的相对低频,约 3.2 纳秒的实际延迟表现相当不错。然而,其 L3 缓存的延迟却超过了 21 纳秒,即 60 多个时钟周期,这个表现并不理想。
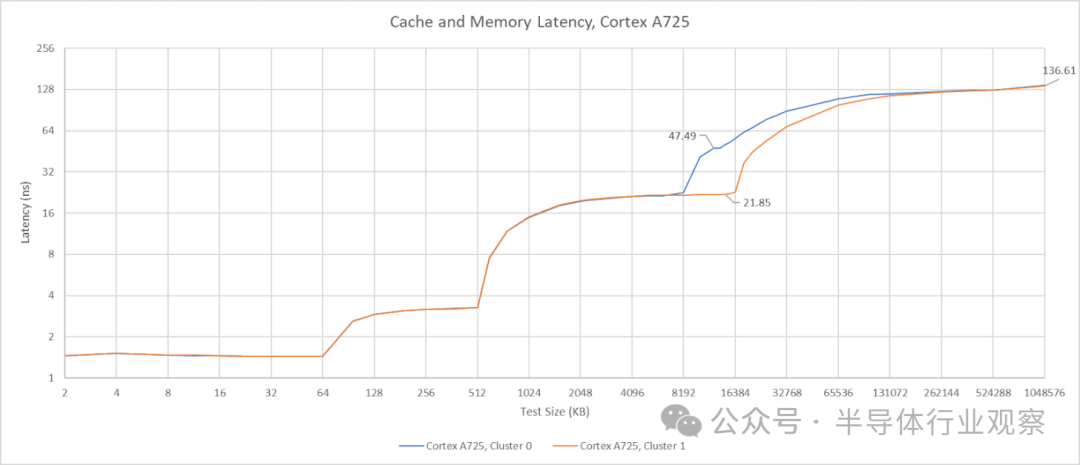
对两个集群进行测试显示,第一个 CPU 集群(Cluster 0)拥有 8 MB 的 L3 缓存,而第二个集群(Cluster 1)则拥有 16 MB。尽管容量不同,但两个集群在使用 A725 核心访问时的 L3 延迟是相同的。当 L3 延迟如此之高时,512 KB 的 L2 缓存容量就显得有些捉襟见肘。选择较小的 L2 缓存或许是为了减少核心面积,从而使 GB10 能够集成更多核心。考虑到 A725 核心本身并非追求极限单线程性能,这样的设计有其合理性。而高性能任务则最好交给 X925 核心来完成。
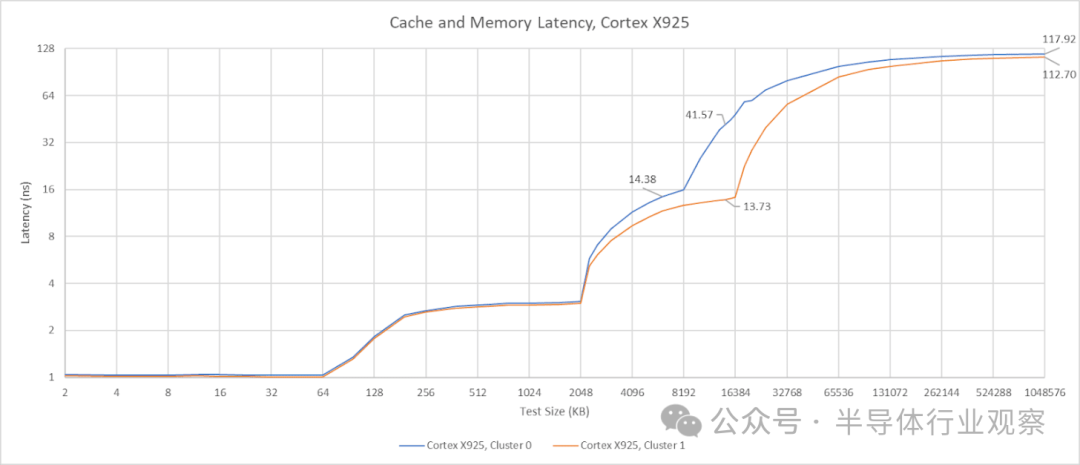
GB10 的 X925 核心配备了 2 MB、8 路组相联的 L2 缓存,延迟为 12 个时钟周期。有趣的是,尽管 A725 和 X925 核心共享同一个 L3 缓存,但 X925 核心的 L3 访问延迟却低得多,大约为 56 个时钟周期或 14 纳秒。这个延迟虽然不算惊艳,但至少在纳秒级别上可与英特尔 Arrow Lake 的 L3 缓存相媲美。更大的 L2 缓存配合更低的 L3 延迟,使得 GB10 的 X925 核心拥有了更均衡的缓存配置,从而能提供更高的性能。
在 L3 缓存之后,还有一个 16 MB 的系统级缓存(SLC)。由于其容量相对于 CPU L3 来说不算巨大,因此在延迟曲线上不易直接观察到。来自 Cluster 0 的延迟数据显示,SLC 的延迟大约在 42 到 47 纳秒之间,具体取决于访问它的是 X925 还是 A725 核心。系统级缓存与任何计算模块的耦合度都不强,这通常会牺牲一些性能,但其优势在于可以服务于芯片上的多个模块。英伟达表示,SLC 除了作为 CPU 的 L4 缓存外,还能“实现引擎之间的高效数据共享”。允许 CPU 和 GPU 之间直接交换数据而无需访问 DRAM,这很可能是 SLC 最重要的功能。
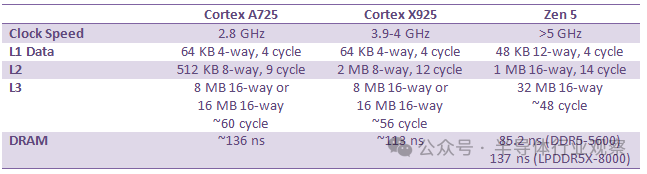
与 Strix Halo 主板上的 AMD Zen 5 架构相比,后者拥有容量更小但速度更快的核心私有缓存。GB10 的 X925 和 A725 核心具有不错的周期级延迟,但由于 Zen 5 时钟频率更高,其缓存的实际访问速度最终更快,尽管在 L2 缓存的优势上并不算太显著。AMD 的 L3 缓存设计依然亮眼,即使容量翻倍,延迟也更低。
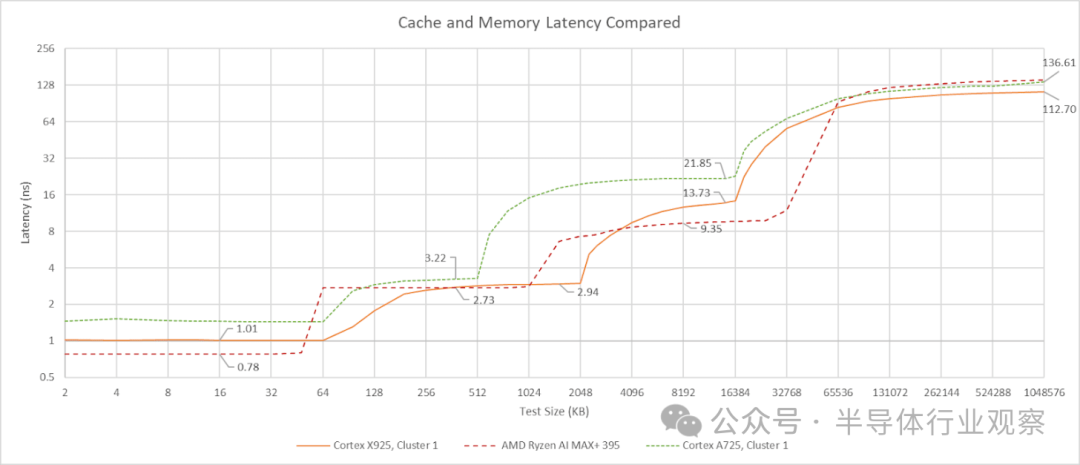
DRAM 延迟是 GB10 的一大亮点。113 纳秒的延迟对于典型的 DDR5 台式机平台来说或许平平无奇,但对于 LPDDR5X 内存而言,这个成绩已经非常出色。相比之下,华硕 Strix Halo 和英特尔 Meteor Lake 的 DRAM 延迟都超过了 140 纳秒。更快的 LPDDR5X 内存或许是 GB10 延迟表现优秀的原因之一。Hot Chips 的幻灯片显示 GB10 的内存总线速度最高可达 9400 MT/s,而 dmidecode 的实测结果为 8533 MT/s。将 CPU 核心与内存控制器集成在同一芯片上,也可能有助于降低延迟。
带宽
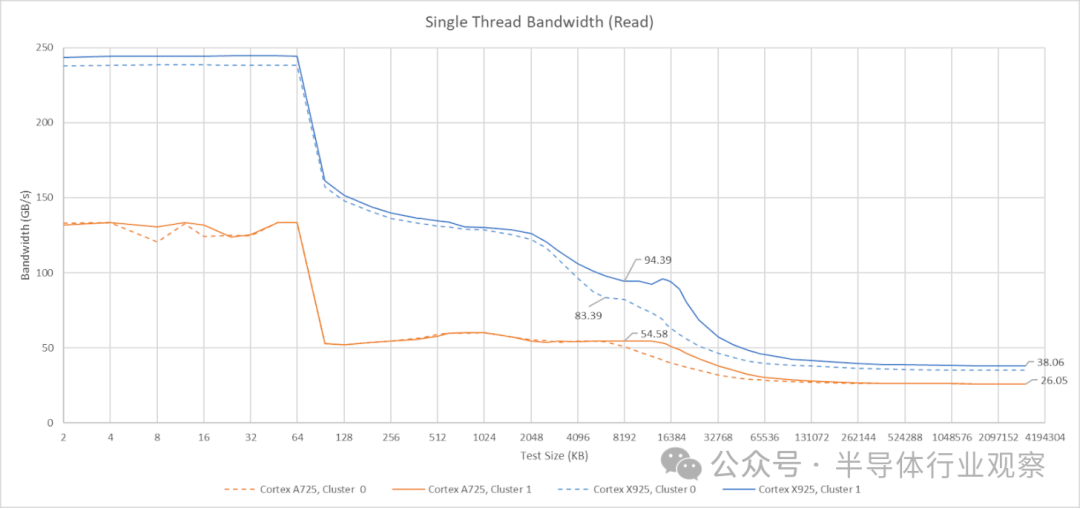
核心私有带宽的数据比较直观。A725 核心可以从 L1 缓存以 48 字节/周期的速度读取数据,并且似乎拥有 32 字节/周期的 L2 缓存数据通路。单个 A725 核心可以从 L3 缓存读取约 55 GB/s 的数据。
X925 核心的带宽表现更为出色。它能够以 64 字节/周期的速度从 L1D 缓存读取数据,L2 缓存的数据通路可能也达到了 64 字节/周期,并且可以维持接近 90 GB/s 的 L3 缓存读取带宽。此外,X925 核心的单核 DRAM 带宽也更高,达到 38 GB/s,而 A725 核心则为 26 GB/s。
相比之下,单个 AMD Zen 5 或 Zen 4 核心可以从 DRAM 读取超过 50 GB/s 的数据,从 L3 缓存读取超过 100 GB/s。这是一个有趣的差异,表明 AMD 允许单个核心排队处理更多的内存请求。不过,低线程工作负载很少需要如此高的带宽,因此这个差异的实际影响可能有限。
在多线程工作负载中,内存层次结构中的共享组件会面临更大的压力,因为激活的核心越多,带宽需求通常也越大。我通常通过让每个线程遍历一个独立的数组来测试多线程带宽。这样可以避免访问合并(因为没有两个线程请求相同的地址),并且能够显示出缓存的聚合容量,因为每个核心都可以将测试数据的不同部分保存在其私有缓存中。GB10 每个集群的核心共有 15 MB 的 L2 缓存(A725和X925合计),但 L3 缓存只有 8 或 16 MB。任何能够放入 L3 缓存的数据,其很大一部分其实都已经被缓存在 L2 中。
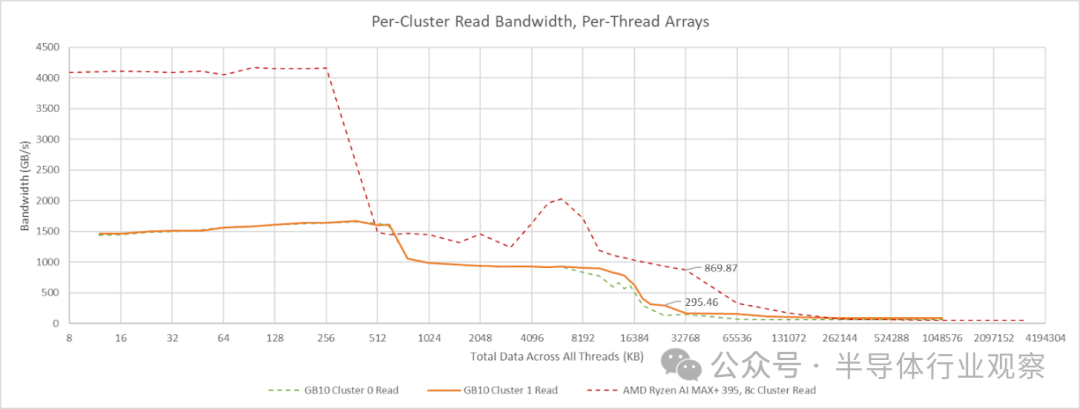
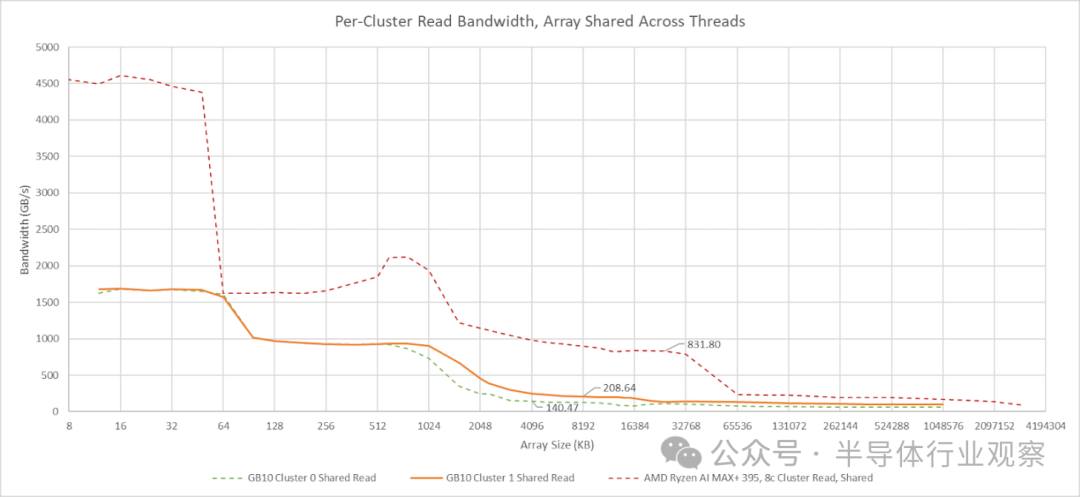
让所有线程指向同一个数组可能会因为访问合并而高估带宽,但这似乎只会在共享缓存层级之后才发生。我最初在 Zen 2 和 Skylake 架构上验证过这种带宽测试方法,其结果与 L3 性能计数器的数据基本一致。在 GB10 上使用共享数组的测试提供了另一个评估 L3 性能的数据点。结合线程私有数组的测试结果来看,这些数据表明 GB10 的 L3 带宽远低于 AMD 的 Strix Halo。不过,其超过 200 GB/s 的 L3 带宽仍然可观,并且可能已经足够使用。
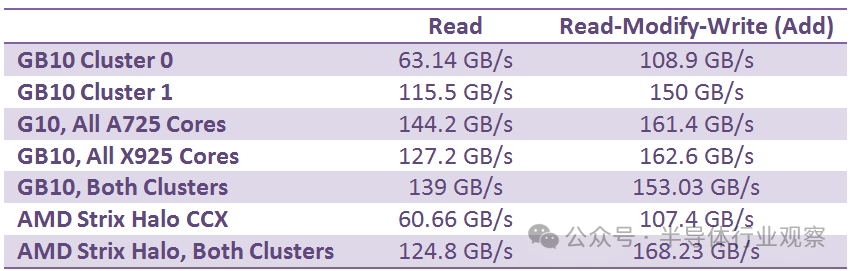
GB10 的两个 CPU 集群除了 L3 缓存容量不同外,其外部带宽也是不对称的。Cluster 0 的带宽表现有点像 Strix Halo 的 CCX(核心复合体)。而 Cluster 1 的读取带宽则超过了 100 GB/s,这让人联想到 AMD 的 GMI-Wide 互联。将读写比例调整为 1:1(读-修改-写)后,测得的带宽显著提升,这表明两个集群都拥有独立的读写路径,且带宽相近。GB10 的 CPU 集群基于 Arm 的 DynamIQ 共享单元 120 (DSU-120) 构建,该单元最多可配置四个 256 位 CHI 接口,因此两个集群可能配置了不同数量的接口。
与 Strix Halo 类似,GB10 的 CPU 端带宽比典型的客户端配置更高,但仍无法完全利用 256 位 LPDDR5X 总线的全部潜力。CPU 工作负载通常对延迟更为敏感,对带宽的需求相对较低。这两款大型集成显卡芯片的内存子系统都体现了这一点,它们都着重利用缓存来提升 CPU 性能。
异构集群配置?
上述观察表明,Cluster 1 更侧重于性能优化,而 Cluster 0 则侧重于密度优化。缓存是现代芯片中占用面积最大的部件之一,因此将 Cluster 0 的 L3 缓存削减到 8 MB,几乎肯定是为了节省面积。Cluster 0 的外部接口可能也更窄,因为减少集群外部的布线同样能节省面积。但英伟达和联发科并没有完全为每个集群进行完全专门化的设计。
Cluster 0 和 Cluster 1 的核心配置是相同的:都是 5 个 X925 核心加 5 个 A725 核心。X925 核心旨在追求最高性能,而 A725 核心则专注于密度。因此,A725 核心出现在高性能集群中显得有些不协调,尤其是在其 L2 缓存仅为 512 KB 且 L3 缓存延迟超过 20 纳秒的情况下。

我不禁思考,如果采用彻底的集群专门化方案,将所有 10 个 A725 核心集中在 Cluster 0 以追求极致密度,而将所有 10 个 X925 核心集中在 Cluster 1 以追求极致性能,是否会更好?将两个异构集群简化为两个同构集群还能简化操作系统调度器的工作。例如,调度器可以更轻松地将工作负载限制在单个集群内,从而使硬件能够对第二个集群进行调频甚至下电。
带宽负载下的延迟
延迟和带宽往往是紧密相关的。高带宽需求会导致请求在内存子系统的各个队列中积压,从而推高平均请求延迟。理想情况下,内存子系统既能提供高带宽,又能防止带宽密集型线程影响对延迟敏感的线程。为此,我测试了在同一集群中,使用 X925 核心与其他核心的不同组合产生带宽负载时,对延迟造成的影响。
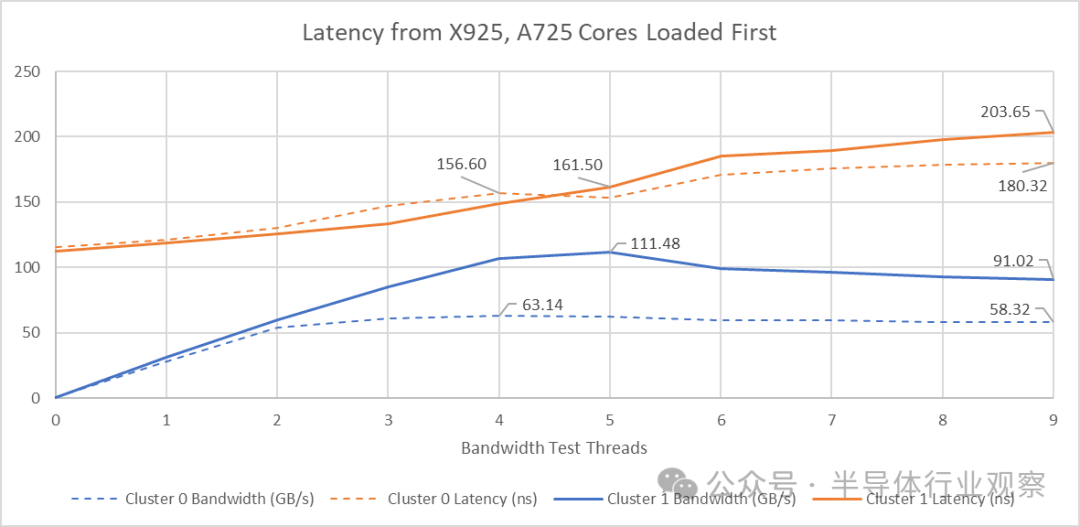
当集群中所有 A725 核心都产生带宽负载时,两个集群都达到了最大带宽。此时加入 X925 核心反而导致总带宽下降,同时延迟上升。反转核心负载顺序的测试表明,X925 核心似乎是造成内存子系统资源争用的主要源头。当四个 X925 核心尝试请求尽可能多的带宽时,延迟达到了峰值。这似乎表明 X925 核心不知道何时应该“让路”以避免独占内存子系统资源。而当 A725 核心加入后,GB10 似乎意识到了问题所在,开始更好地平衡带宽需求。带宽得到改善,令人意外的是,延迟也随之降低了。
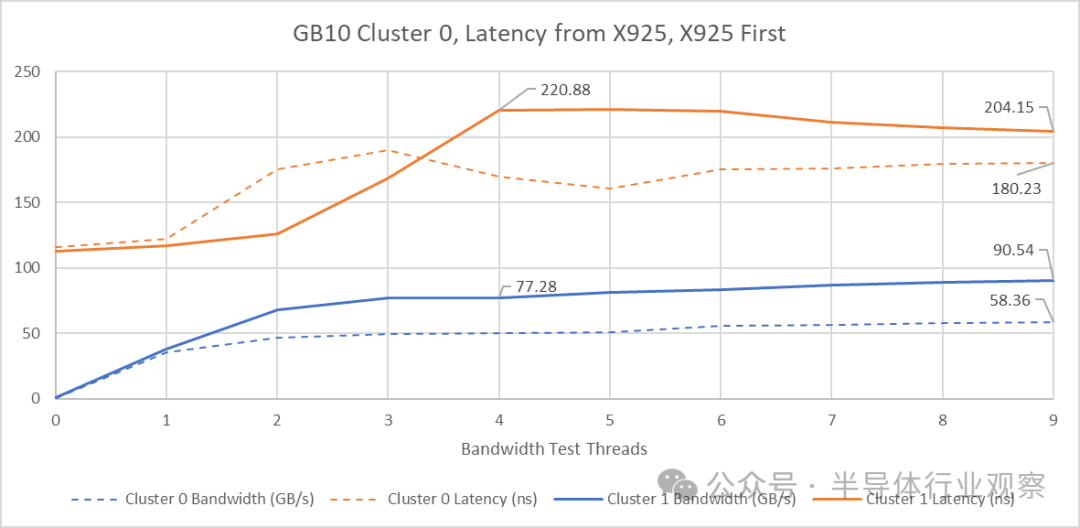
尽管 Cluster 1 拥有更高的可用带宽,但其在控制延迟方面的表现却更差。这与我们在 AMD GMI-Wide 架构上的测试结果不符,在 GMI-Wide 上,更高的集群外带宽在高带宽负载下能带来更好的延迟控制。
在两个集群上同时对核心施加负载的测试表明,在相同的带宽水平下,GB10 的延迟要低于 Strix Halo。GB10 更低的基线延迟,加上 Cluster 1 的高外部带宽,使其在这方面具有明显优势。
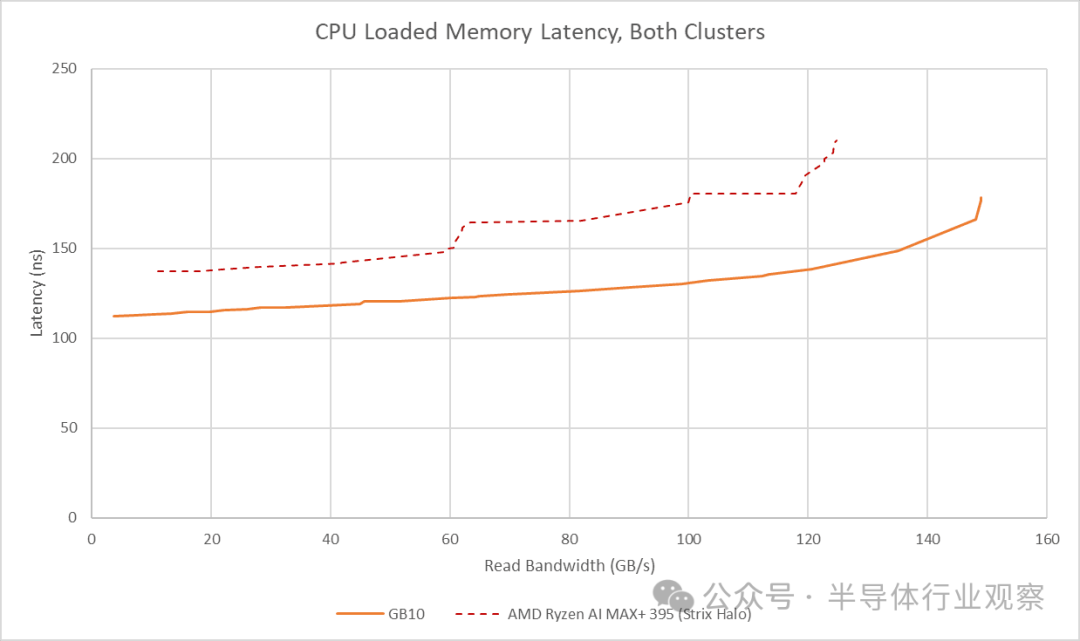
将 GB10 的集成显卡(iGPU)纳入考虑会带来额外的挑战。与 Strix Halo 类似,iGPU 对带宽的需求增加会导致 CPU 端的延迟上升。GB10 的 DRAM 基础延迟优于 Strix Halo,并且在 GPU 带宽需求适中的情况下也能保持更低的延迟。
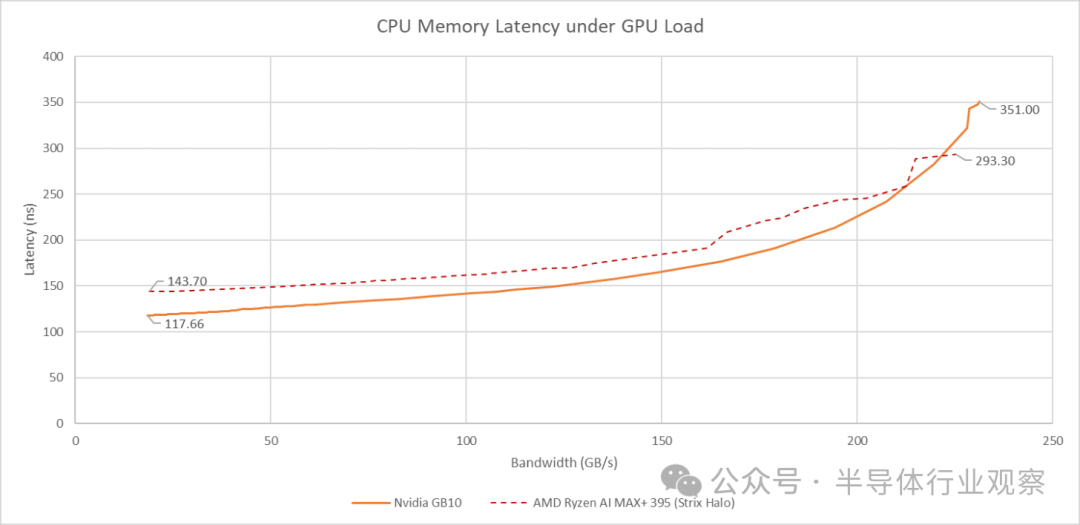
然而,GB10 的架构在 GPU 需要高带宽时会严重挤压 CPU 的可用带宽。当 GPU 带宽达到 231 GB/s 时,CPU 端的延迟会飙升到超过 351 纳秒。
上述测试中,我只使用了 GPU 来产生带宽负载,并运行了一个 CPU 延迟测试线程。如果同时出现高 CPU 带宽需求和高 GPU 带宽需求,情况会变得更加复杂。
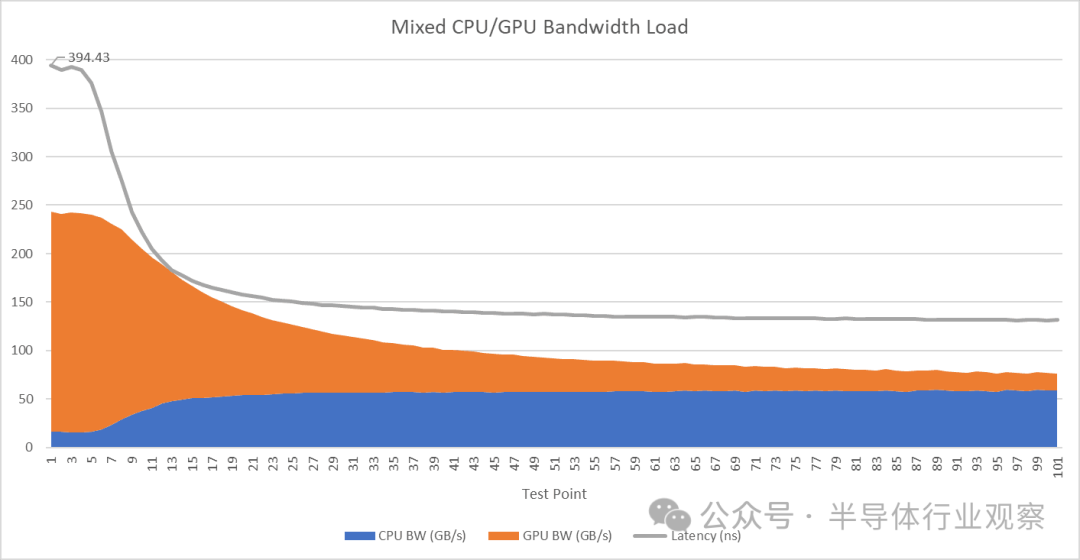
当 Cluster 1 上的两个 X925 核心竭尽全力占用带宽,同时 GPU 也全速运行时,性能最强的 X925 核心所经历的延迟接近 400 纳秒。进一步分析 CPU 和 GPU 的带宽使用情况可以发现,GPU 在带宽测试线程中占据了主导地位。
核心间延迟
内存访问通常以垂直方向遍历缓存层次结构,即某一级缓存未命中会向下一级缓存传递。然而,为了维护缓存一致性,内存子系统可能需要在同一级别的缓存之间进行横向数据传输。这个过程可能相当复杂。内存子系统必须确定是否存在对等缓存,以及哪个对等缓存可能拥有更新的缓存行副本。Arm 的 DSU-120 配备了一个侦听控制单元,它使用侦听过滤器来协调核心复合体内的对等缓存传输。而英伟达/联发科的高性能一致性架构(HPCF)则负责维护集群之间的缓存一致性。
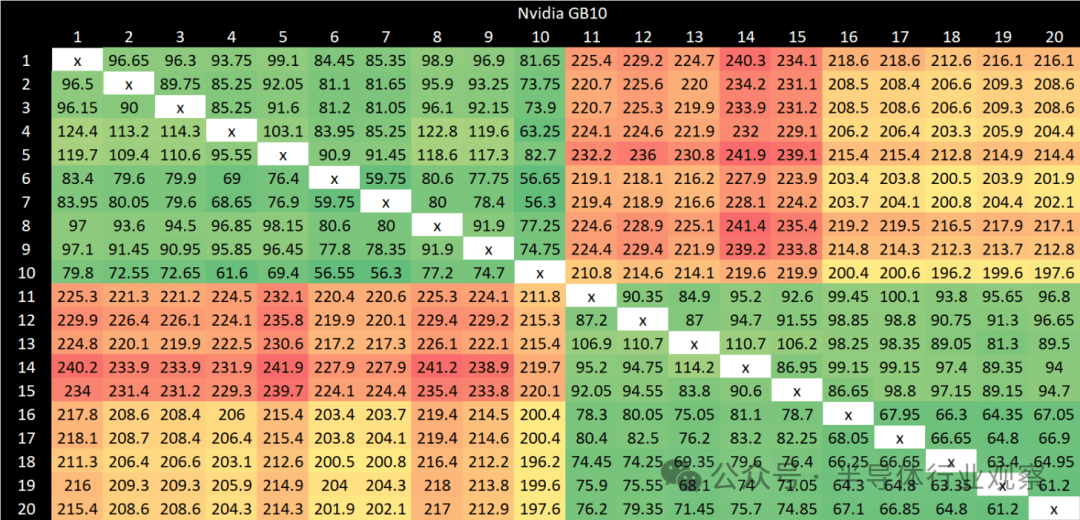
通过对所有结果点应用着色方案,可以清晰地看到 GB10 的集群边界。即使在同一集群内部,结果也远非均匀。为集群内和集群间的数据点设置不同的着色方案可以更清晰地展示这一点。通常,X925 核心能提供更好的集群内延迟结果。最佳的延迟情况出现在同一集群内的 X925 核心之间。最差的情况则出现在不同集群的 A725 核心之间,延迟最高可达 240 纳秒。
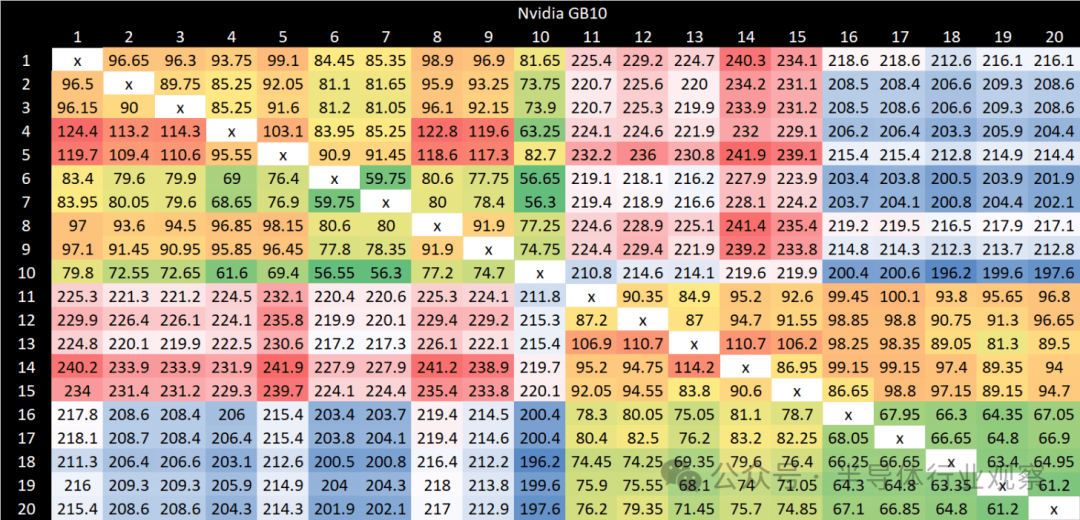
与 Strix Halo 相比,GB10 的核心间延迟总体偏高。Strix Halo 的跨集群延迟控制在 100 纳秒左右,虽然比 AMD 的桌面平台处理器稍差,但远优于 GB10 的 200 纳秒。在集群内部,AMD 的延迟均低于 50 纳秒,而 GB10 即使在最佳情况下也只能达到 50-60 纳秒。
结语
与 Strix Halo 相比,GB10 的 CPU 架构更侧重于密度优化。GB10 拥有 20 个 CPU 核心,而 Strix Halo 为 16 个,GB10 是通过高度异构的 CPU 配置和更少的缓存占用实现的。我最初的想法是,在其他条件相同的情况下,我宁愿选择 32 MB 的单一级别高速缓存,而不是 16 MB 的 L3 缓存加上 16 MB 的低速系统级缓存。话虽如此,性能是一个复杂的问题,我仍在持续对 Strix Halo 和 GB10 进行基准测试。
GB10 的内存子系统也有其亮点。对于 LPDDR5X 而言,其 DRAM 延迟表现非常出色。联发科还为其中一个集群提供了超过 100 GB/s 的外部读取带宽,这是 AMD 迄今为止在任何客户端设计中都未做到的。
CPU 端带宽是另一个值得关注的细节,两款芯片在此有很多相似之处。无论是 GB10 还是 Strix Halo,CPU 核心都无法完全利用 LPDDR5X 的全部带宽。256 位内存总线主要是为 GPU 准备的,而非 CPU。GPU 的高带宽需求可能会对两个内存子系统中的 CPU 性能都造成压力。也许英伟达/联发科和 AMD 都对那些 CPU 和 GPU 性能需求不会同时达到峰值的工作负载进行了优化。
我希望看到英伟达和 AMD 继续改进这类大型集成显卡的设计。像 GB10 和 Strix Halo 这样的产品可以实现更小的设备尺寸,并规避当前独立显卡普遍存在的显存容量瓶颈问题。从硬件发烧友的角度来看,它们非常具有吸引力。希望这两家公司未来能够进一步优化设计,并让产品的价格更具竞争力。
 发表于 2026-1-21 04:06:35
|
查看: 197|
回复: 0
发表于 2026-1-21 04:06:35
|
查看: 197|
回复: 0
