
英伟达推出的Blackwell B200 GPU凭借其创新的多芯片设计,旨在成为新一代数据中心和AI计算的标杆。与前代主要依赖制程工艺升级不同,B200采用了两个光罩大小的芯片,在软件层面被整合为一个统一的逻辑GPU,这也是英伟达首次在芯片层面实现GPU融合。每个物理芯片包含80个流式多处理器,其中74个处于可用状态,使整个B200 GPU共拥有148个SM,时钟频率与高功率版本的H100 SXM5相近。
缓存层级与内存访问
B200的缓存体系继承了H100和A100的基本结构。每个SM的L1缓存/共享内存池容量仍为256KB,开发者可通过CUDA API灵活分配其用于缓存或共享内存的比例(例如216KB、112KB或16KB L1缓存)。OpenCL驱动则会默认分配最大的216KB作为数据缓存。
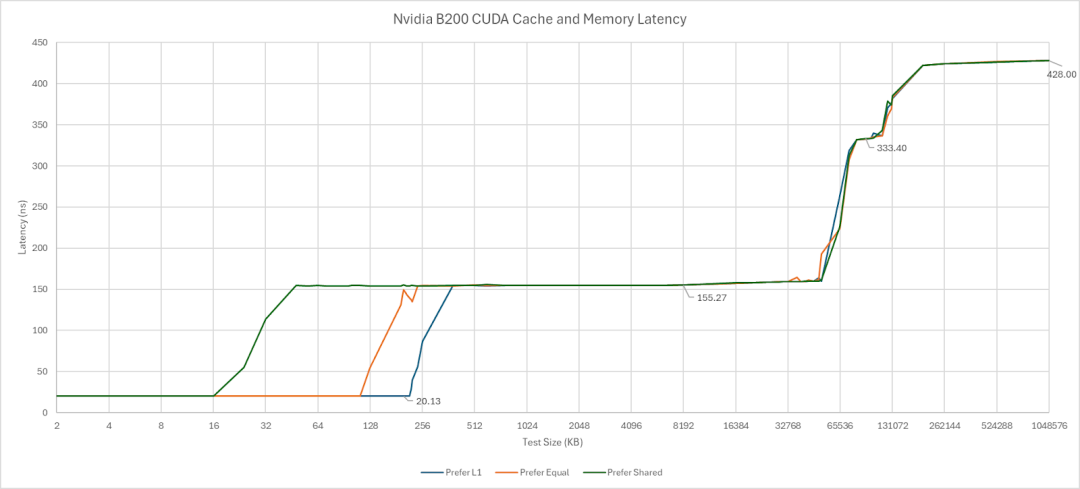
B200最大的改进在于其二级缓存。其L2缓存采用分区式设计,但总容量大幅提升至126MB,远超H100的50MB和A100的40MB。访问同一L2分区的延迟保持在约150纳秒。当访问需要跨越不同L2分区时,延迟会有一定增加,但增幅控制得相对较好,这表明其多芯片互连效率颇高。从测试来看,B200的L2缓存访问特性类似于一个三级缓存体系。
相比之下,AMD的MI300X采用了真正的三级缓存。Nvidia的L1更大更快,而AMD的L2延迟更低,并且其256MB的Infinity Cache在容量和延迟上取得了更好平衡。
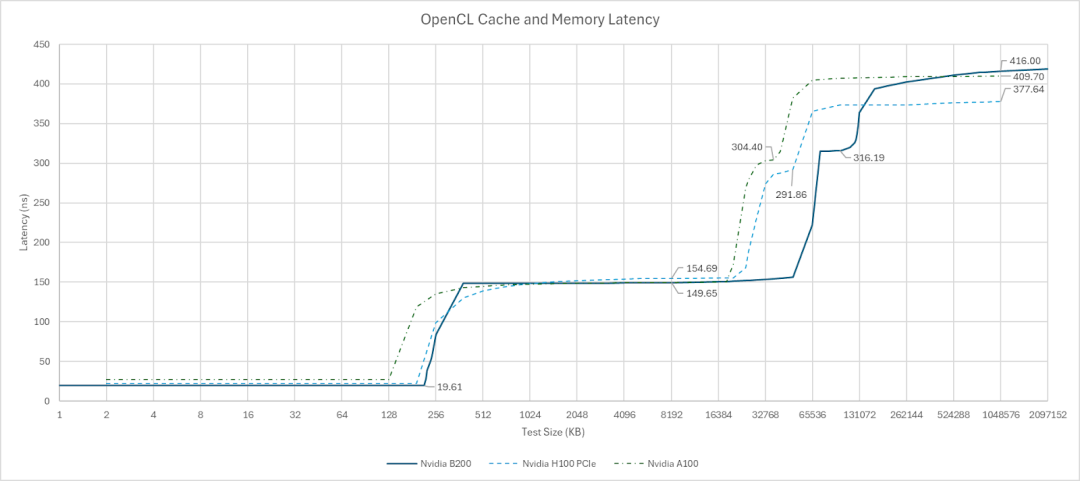
B200与MI300X缓存延迟对比
在共享内存(本地内存)延迟测试中,B200延续了英伟达在该项上的优势,其访问速度超过了包括消费级RDNA架构在内的所有已测试AMD GPU。

带宽性能
得益于SM数量的增加,B200的L1缓存带宽显著高于前代H100,并与AMD MI300X持平。由于其共享内存和L1缓存共享存储介质,两者的带宽表现一致。
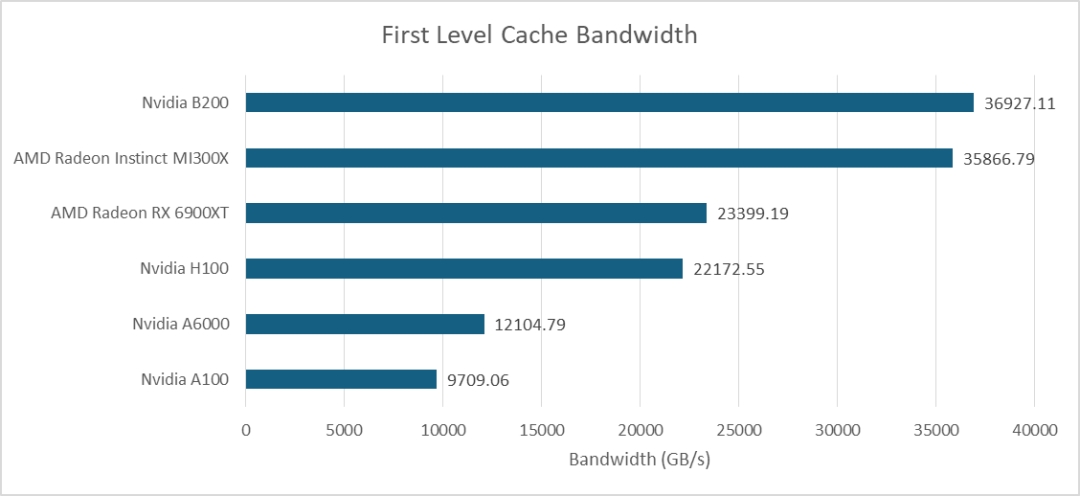
L2缓存带宽方面,在访问单个分区时,B200的峰值带宽可达21TB/s;当数据跨分区传输时,带宽降至16.8TB/s。AMD MI300X的Infinity Cache带宽为14.7TB/s。
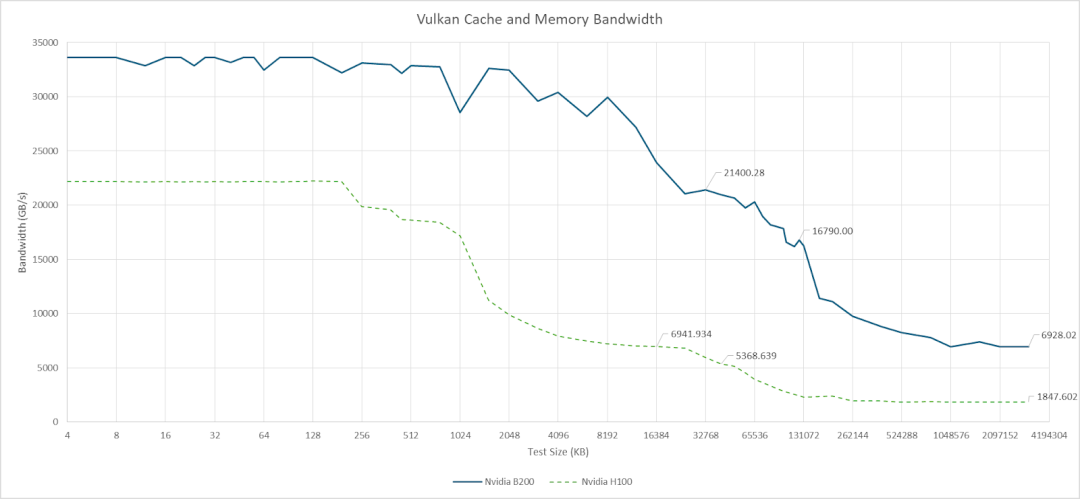
显存带宽是B200的一大亮点。凭借先进的HBM3E显存,其带宽超越了使用HBM3的MI300X(5.3TB/s),为高带宽需求的应用提供了强大支撑。
计算吞吐量与原子操作
在大多数向量运算中,B200的计算吞吐量因SM增多而高于H100。但值得注意的是,B200的FP16计算速率并非FP32的两倍,这与前代不同。英伟达可能将FP16计算的重点更多地放在了张量核心上。
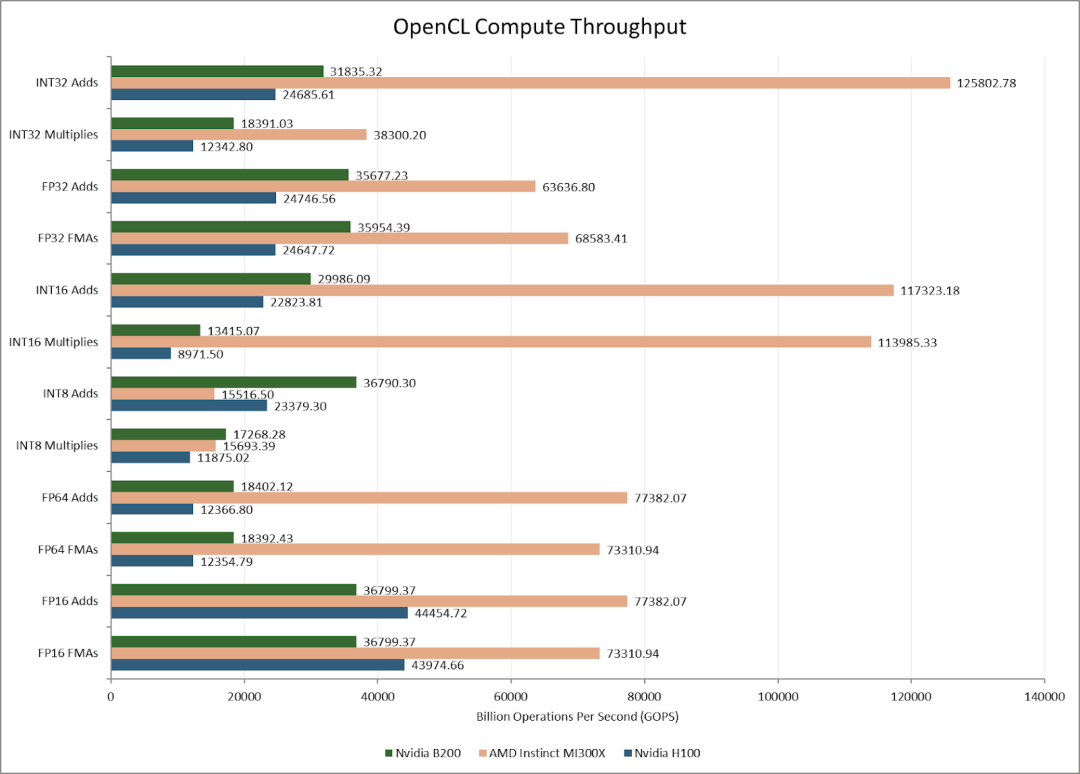
在全局内存原子操作测试中,B200表现出双峰延迟分布。理想情况下(线程位于同一L2分区)延迟为90-100纳秒;较差情况下(线程跨分区通信)延迟为190-220纳秒。这揭示了其多芯片架构在极端细粒度通信时的影响。
张量内存:为AI优化的专用存储
B200的核心目标是加速人工智能负载。其第五代张量核心支持工作小组(CTA)级的矩阵乘法运算。更关键的是引入了张量内存。

TMEM是一个专为张量核心服务的、类似于寄存器文件的专用存储。开发者可以将矩阵数据暂存于TMEM中,Blackwell的矩阵乘指令直接从此读取操作数,而非通用寄存器。每个SM子分区拥有一个512列x32行的TMEM分区,总计64KB。
TMEM的设计理念与AMD CDNA架构的累加器寄存器文件类似,但实现更为成熟和灵活。它采用动态分配机制,支持从共享内存或通用寄存器加载数据,并能解压缩低精度数据类型。TMEM的引入有效缓解了通用寄存器文件的压力和带宽需求,是英伟达在维持寄存器文件容量不变的情况下,提升AI计算效率的巧妙设计。
基准测试表现
在流体动力学模拟软件FluidX3D的测试中,B200凭借其高显存带宽优势,性能超越了MI300X。
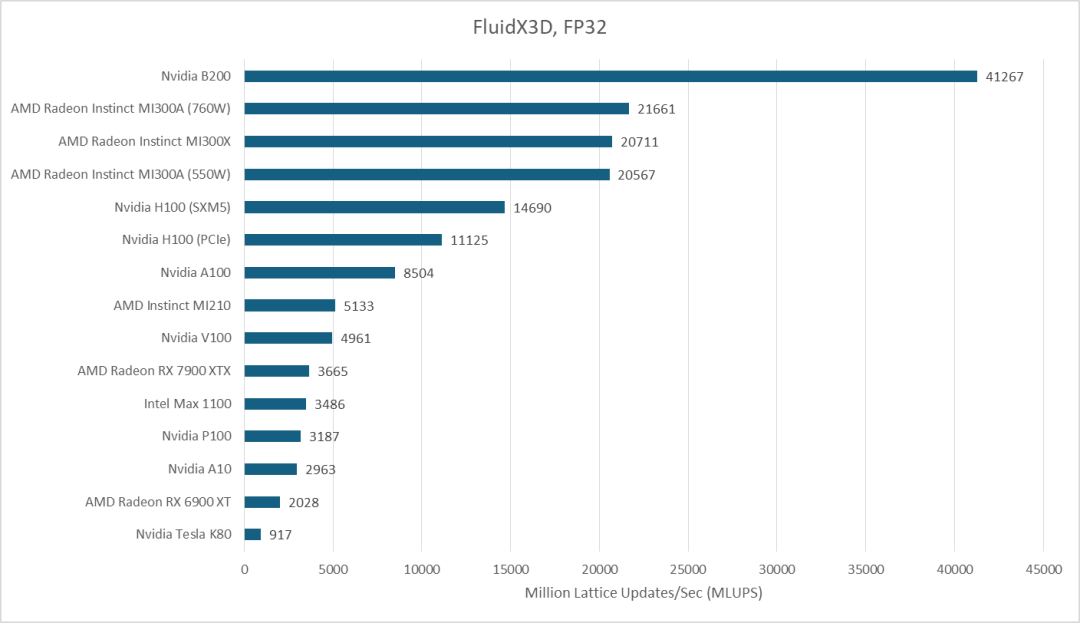
当测试负载对缓存友好且能放入大容量末级缓存时,MI300X则凭借其强大的计算吞吐量展现优势。在涉及高精度FP64计算或高计算强度的FP16格式流体模拟中,MI300X的性能领先于B200。
总结与竞争格局
英伟达Blackwell B200是一次成功的迭代升级。其双芯片设计在软件层面实现了无缝统一,并未对开发者造成额外负担。与AMD MI300X这种采用12芯片的激进设计相比,英伟达的策略显得更为稳健。
B200在显存带宽、缓存容量和整体能效上建立了优势,巩固了其在AI模型训练等场景的领导地位。而AMD MI300X则在绝对计算吞吐量和缓存延迟方面展示了其硬件设计的威力。

这场竞争的深层逻辑在于软件生态。英伟达强大的CUDA生态构成了其最深的护城河,使其无需在硬件上处处冒险追求极致,只需保持足够领先即可维持市场主导。而AMD则通过MI300X这样的硬件杰作,证明了其在高端计算领域的技术实力,为市场提供了有竞争力的差异化选择。未来,随着AMD下一代产品(如MI350X)在显存带宽等方面的追赶,两强的技术竞赛将更加激烈。
 发表于 2025-12-24 02:48:19
|
查看: 282|
回复: 0
发表于 2025-12-24 02:48:19
|
查看: 282|
回复: 0
