1、引言
在之前的探讨中,我们曾“形而上”地关联了深度学习与泰勒级数之间的深层类比:
深度学习模型中的层数对应于泰勒级数中的展开项数。深度学习模型广泛采用的残差连接对应于泰勒级数中的展开项相加操作。
这个框架帮助我们理解了为何残差连接如此有效——它本质上在进行一种可控的累加逼近。
近期,DeepSeek发布了一篇新论文 mHC: Manifold-Constrained Hyper-Connections,对残差连接这一十年经典架构提出了创新。有趣的是,论文讨论的核心问题与解决方案,恰好能从泰勒级数的框架中获得形象的解释。
因此,本文将继续这一“可解释性杂谈”,从泰勒级数的视角解读mHC的设计思路,探讨:
- 为什么扩展残差流宽度(HC)会带来不稳定性?
- mHC的“流形约束”究竟在做什么?
- 双随机矩阵为何是“正确答案”之一?
2、回顾:泰勒级数与残差连接的类比
在深入mHC之前,让我们快速回顾核心类比框架。
泰勒级数通过累加各阶导数项来逼近函数:
f(x) ≈ f(a) + f'(a)(x-a) + 1/2! f''(a)(x-a)^2 + ...
而残差网络通过累加各层的残差函数来逼近目标映射:
x_{L} = x_{0} + ∑_{l=1}^{L} F_{l}(x_{l-1})
两者的相似性体现在:
| 泰勒级数 |
残差网络 |
| 展开项数 |
网络层数 |
| 各阶导数项 |
各层残差函数 |
| 累加逼近 |
残差累加 |
| 高阶项捕捉复杂变化 |
深层捕捉高级特征 |
这个类比成立的关键前提是:每一项(每一层)的贡献是可加的、受控的。正是这种“受控性”,使得残差网络能够稳定地训练至很深层数。
3、Hyper-Connections:从“单变量”到“多变量”泰勒展开
3.1 HC的设计思想
标准残差连接可以看作是“单通道”的信息流:
x_{l} = x_{l-1} + F_{l}(x_{l-1})
Hyper-Connections (HC) 的核心创新是将残差流从单通道扩展为 n通道:
x_{l} = A_{l} * h_{l-1} + F_{l}(B_{l} * h_{l-1})
h_{l} = C_{l} * F_{l}(B_{l} * h_{l-1}) + D_{l} * h_{l-1}
并引入三个可学习的映射矩阵来管理这n条并行的信息流:
H_l^{res} = C_l (I + J_{F_l} B_l) D_l
其中:
H_l^{res}:多通道残差流内部的混合矩阵(混合矩阵)B_l:从n流聚合到单一层输入(聚合矩阵)C_l:将层输出分发回n流(分发矩阵)
3.2 泰勒级数视角下的理解
用泰勒级数框架理解HC,需关注它引入的两层耦合。
标准残差连接展开后是各项独立累加:
x_L = x_0 + ∑_{l=1}^{L} F_l(x_{l-1})
就像泰勒级数,每一项独立贡献,互不干扰。
HC展开后则完全不同:
h_L = (∏_{l=1}^{L} D_l) h_0 + ∑_{l=1}^{L} (∏_{i=l+1}^{L} D_i) C_l F_l(B_l h_{l-1})
这里出现了两种“耦合”:
耦合1:同一层内n条流之间的混合(流内耦合)
H_l^{res}的作用是在第 l 层内部,对n条并行流进行混合。第 j 条流的输出依赖于所有n条流的输入。
耦合2:不同层的修正项被累积矩阵调制(层间耦合)
注意到每一层的贡献 C_l F_l(...) 在最终输出中都被 ∏ D_i 这串矩阵乘积所调制。
用泰勒级数的语言:这就像让各阶导数项的系数不再独立,而是被一组累积因子统一缩放。
HC的形而上解读:将“各项独立累加”变成了“各项被累积矩阵调制后再累加”——原本独立的展开项现在都被同一组矩阵连乘所“污染”了。
这种设计直觉上很美好:更丰富的信息表示、更灵活的层间交互、在FLOPs不变的情况下增加拓扑复杂度。但问题随之而来——这种“自由度”会带来什么代价?

4、HC的致命问题:无约束的累积矩阵导致“级数发散”
4.1 泰勒级数为什么稳定?
让我们回归基础。对于解析函数,泰勒级数的系数 f^{(n)}(a)/n! 不是任意的,它们由函数本身的导数性质严格决定。更关键的是,对于收敛的泰勒级数,有一个隐含约束:系数必须“足够小”,才能保证无穷累加后不会发散。
4.2 标准残差连接的“恒等映射”性质
标准残差连接 x_l = x_{l-1} + F_l(x_{l-1}) 有一个关键性质:恒等映射。递推展开后:
x_L = x_0 + ∑_{l=1}^{L} F_l(x_{l-1})
信号 x_0 可以无损地直接传递到任意深度!这就像泰勒级数的常数项 f(a)——它永远在那里,不被其他项“污染”。
4.3 HC打破了这个性质
当我们将HC递推展开到多层时,原始信号 h_0 传递到第 L 层时变成了:
h_L = (∏_{l=1}^{L} D_l) h_0 + ...
注意到那个矩阵连乘 ∏ D_l 了吗?
用数学直觉理解:
- 如果
D_l 的谱半径 > 1:信号指数级爆炸
- 如果
D_l 的谱半径 < 1:信号指数级消失
- 多层连乘会放大这种效应
4.4 实验证据
mHC论文中的 Figure 3 给出了意料中的实验证据:
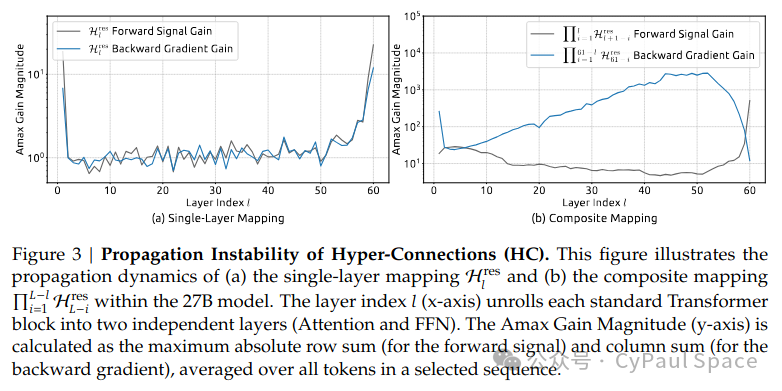
在27B模型中,H_l^{res} 复合映射的“增益幅度”(Amax Gain Magnitude)可以达到近3000——远离理想值1。
这意味着:
从浅层到深层,信号可能被放大3000倍,或者梯度在反向传播时被放大3000倍。
这已经超越了“训练是否稳定”的范畴,直接进入了“训练灾难”的领域。
5、mHC的解决方案:将矩阵约束到“安全流形”
5.1 核心思想
mHC (Manifold-Constrained Hyper-Connections) 的核心思想可以用一句话概括:
将可任意学习的系数矩阵 H_l^{res} 约束到一个数学上保证“信号不发散”的流形上。
具体而言,mHC选择的流形是双随机矩阵(Doubly Stochastic Matrix)空间:
P_{M^{res}}(H_l^{res}) = Sinkhorn-Knopp(σ(H_l^{res}))
简单来说:
- 每行之和 = 1(输出是输入的加权平均)
- 每列之和 = 1(每个输入对输出的总贡献守恒)
- 所有元素非负(没有“负权重抵消”)
双随机矩阵之所以叫“双随机”,是因为它在“行”和“列”两个方向上都满足概率分布的约束(行随机 + 列随机,行和 & 列和 都等于 1)。
5.2 为什么双随机矩阵是“安全”的?
让我们深入理解双随机矩阵的三个关键性质。
性质1:信号均值守恒
当权重 w_i 满足 ∑ w_i = 1 且 w_i ≥ 0 时,∑ w_i x_i 称为 x_i 的凸组合,本质就是加权平均。
双随机矩阵的作用之一就是对每个输出分量做凸组合。对于双随机矩阵 P 作用于向量 x:
(Px)_i = ∑_j P_{ij} x_j
由于 ∑_j P_{ij} = 1(行和为1)且 P_{ij} ≥ 0,所以每个输出元素都是所有输入元素的加权平均。
关键性质:信号均值在变换下保持不变。设输入均值 μ_in = (1/n) ∑_i x_i,输出均值 μ_out = (1/n) ∑_i (Px)_i。
μ_out = (1/n) ∑_i ∑_j P_{ij} x_j = (1/n) ∑_j (∑_i P_{ij}) x_j = (1/n) ∑_j 1 * x_j = μ_in
使用的关键条件:∑_i P_{ij} = 1(列和为1),均值守恒依赖的是列随机性。
总结:
- 行随机 -> 每个输出是凸组合
- 列随机 -> 均值守恒
双随机矩阵保持信号均值不变,可以理解为一个质量守恒的线性传输算子。
直觉理解:水池类比
想象n个水池,每个水池有不同的水量 x_i。双随机矩阵就像一个“公平的泵系统”:从每个水池抽水,按比例分配到各个水池。每个水池流出的总比例 = 1(行和为1),每个水池流入的总比例 = 1(列和为1)。这样的系统不会创造水,也不会消灭水——总水量守恒,平均水位守恒。这就是“信号守恒”的含义:信息在n条流之间重新分配,但总量不变。
性质2:范数不扩张——信号幅度有界
双随机矩阵的谱范数(最大奇异值)满足 ‖P‖₂ ≤ 1。
证明:对于任意向量 x,考虑 y = Px。由于双随机矩阵满足 P_{ij} ≥ 0 且 ∑_j P_{ij} = 1(行和为1),应用 Jensen 不等式(凸函数 φ(t)=t²):
y_i² = (∑_j P_{ij} x_j)² ≤ ∑_j P_{ij} x_j²
因此:
‖y‖₂² = ∑_i y_i² ≤ ∑_i ∑_j P_{ij} x_j² = ∑_j (∑_i P_{ij}) x_j² = ∑_j 1 * x_j² = ‖x‖₂²
最后一步用到了列和为1的条件。这就证明了 ‖P‖₂ ≤ 1。这意味对于任意向量 x:‖Px‖₂ ≤ ‖x‖₂。
结论:双随机矩阵(变换)是一个非扩张映射,它不会放大向量的长度(不会放大信号的幅度)。
对训练稳定性的意义
虽然神经网络的层数 L 有限,但“范数不扩张”保证了:
- 前向传播:信号幅度不会随深度指数增长
- 反向传播:梯度幅度不会随深度指数增长
这是稳定训练的必要条件——没有它,深层网络几乎无法训练。
性质3:乘法封闭——深度无关的稳定性
这是mHC最关键的性质:双随机矩阵的乘积仍然是双随机矩阵。
定理:若 P 和 Q 都是双随机矩阵,则 R = PQ 也是双随机矩阵。
证明:需要验证 R 满足三个条件:
- 非负性:
R_{ij} = ∑_k P_{ik} Q_{kj} ≥ 0,因为 P_{ik} ≥ 0 且 Q_{kj} ≥ 0。
- 行和为 1:
∑_j R_{ij} = ∑_j ∑_k P_{ik} Q_{kj} = ∑_k P_{ik} (∑_j Q_{kj}) = ∑_k P_{ik} * 1 = 1。
- 列和为 1:
∑_i R_{ij} = ∑_i ∑_k P_{ik} Q_{kj} = ∑_k (∑_i P_{ik}) Q_{kj} = ∑_k 1 * Q_{kj} = 1。
结论:R 满足所有三个条件,因此 PQ 是双随机矩阵。
为什么这个性质至关重要?
这意味着,无论网络有多深,复合映射:∏_{l=1}^{L} P_{M^{res}}(H_l^{res}) 始终是双随机矩阵!因此,从第1层到第 L 层的信号传播,无论 L 多大,都满足:均值守恒、范数不扩张。这就是深度无关的稳定性:网络可以任意深,信号都不会爆炸或消失。
用泰勒级数类比:
即使我们让“各项系数”相互耦合,只要每个系数矩阵都落在双随机流形上,它们的累积效应就永远是“安全”的。
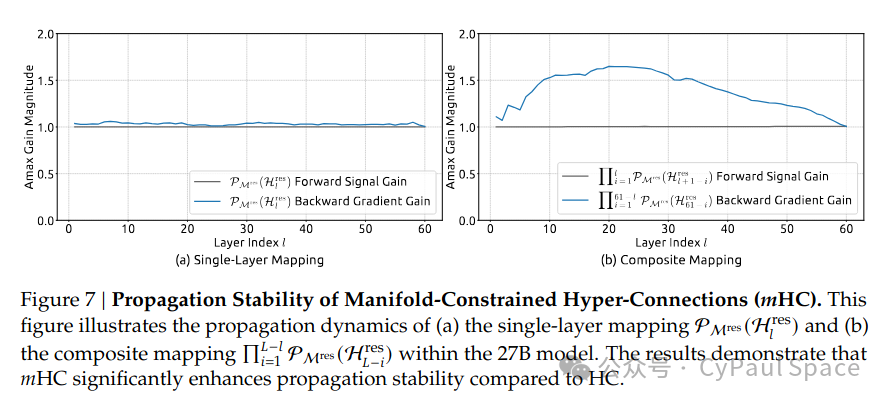
mHC论文的 Figure 7 证实了这一点:复合映射的增益幅度始终保持在1.6以内,比HC的3000降低了三个数量级。

6、双随机矩阵的更多介绍
6.1 Birkhoff多面体:置换矩阵的凸包
双随机矩阵构成的空间有一个优美的几何名字——Birkhoff多面体。Birkhoff-von Neumann定理告诉我们:
任何双随机矩阵都可以表示为置换矩阵的凸组合。
P = ∑_{k} θ_k Π_k, 其中 θ_k ≥ 0, ∑ θ_k = 1,Π_k 是置换矩阵。
6.2 置换 = 重排,双随机 = 软重排
置换矩阵 Π 的作用是将输入向量的元素重新排列,不改变任何值:(Πx)_i = x_{π(i)}。用泰勒级数理解:这相当于改变各项的顺序,但不改变其值。信息完全守恒。
双随机矩阵是置换矩阵的凸组合,可以理解为“软置换”或“概率置换”:
它是多种“重排方案”的概率混合——既能交换信息,又保持总量守恒。
6.3 信息论视角:熵与信号守恒的关系
从信息论角度,双随机矩阵因为是凸组合操作,它倾向于“混合”信息、“平滑”分布,而不是“放大”差异。这与稳定训练的直觉完美吻合:
我们希望信息在网络中流动和融合,而不是被放大或消失。
| 概念 |
数学含义 |
在神经网络中的意义 |
| 范数守恒 |
‖Px‖ ≤ ‖x‖ |
信号幅度不爆炸 |
| 均值守恒 |
mean(Px) = mean(x) |
信号的“中心”不漂移 |
| 熵不减 |
H(Pp) ≥ H(p)(对概率分布) |
信息分布趋于均匀 |
双随机矩阵同时满足这三个性质,确保信息在网络中流动时:不会被无限放大(范数有界)、不会整体漂移(均值守恒)、不会过度集中或发散(熵有界)。
双随机矩阵确保信息在网络中“有序流动”,而非“混乱爆炸”。
7、Sinkhorn-Knopp算法:如何投影到双随机流形
mHC使用经典的Sinkhorn-Knopp算法将任意矩阵投影到双随机矩阵空间。这个经典的优化算法与许多计算机基础中的迭代思想相通。
7.1 算法思想
给定一个正矩阵 M^{(0)} = exp(H_res)(通过指数函数保证非负),交替进行行归一化和列归一化:
M^{(t)} = T_r(T_c(M^{(t-1)}))
其中:
T_r:行归一化(每行除以行和,使行和为1)T_c:列归一化(每列除以列和,使列和为1)
迭代足够多次后,M^{(t)} 收敛到一个双随机矩阵。

7.2 直觉理解
这个算法可以理解为:
将“任意矩阵”迭代地修正到满足“行和=1、列和=1”的约束空间。
就像在泰勒级数中,如果某一项的系数“不合规”,我们就把它“投影”回合理范围。mHC选择迭代20次作为效率与精度的平衡点。论文实验表明,这个近似已足够好——复合映射的增益幅度保持在1.6以内。
8、实验验证与可解释性总结
8.1 稳定性的飞跃
mHC论文的实验结果达到了期望的效果:
| 方法 |
复合映射增益幅度 |
训练稳定性 |
| HC |
~3000 |
不稳定(loss突增) |
| mHC |
~1.6 |
稳定 |
增益幅度降低三个数量级,直接体现了双随机约束的威力。
8.2 性能的提升
在27B模型的下游任务评测中,mHC相比HC在推理任务上有显著提升:
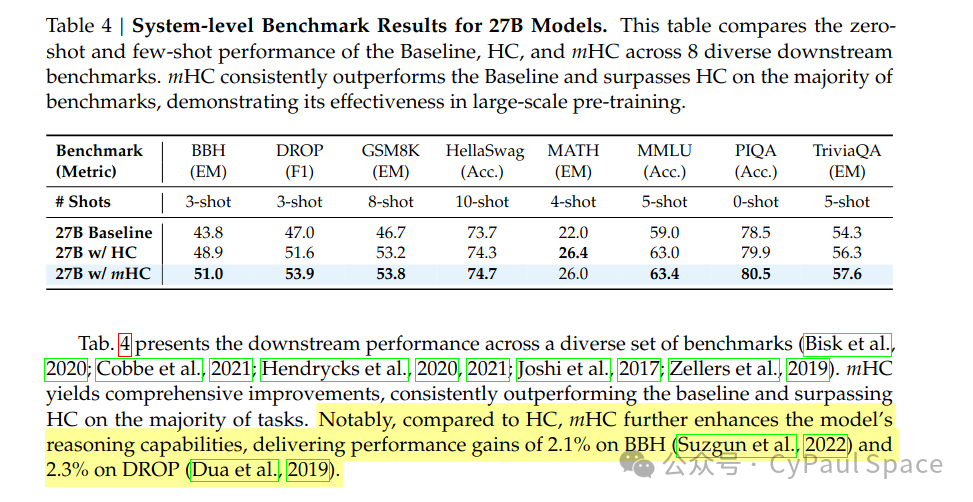
这印证了我们的分析:
稳定的信号传播让网络能够更有效地学习,而不是在对抗数值爆炸/消失中浪费容量。
8.3 可解释性总结
用一张表总结三种方法在泰勒级数框架视角下的对比:
| 概念 |
标准残差 |
HC |
mHC |
| 泰勒级数类比 |
各项独立累加 |
各项被累积矩阵调制 |
各项被“安全”累积矩阵调制 |
| 系数空间 |
恒等(标量1) |
任意矩阵 R^{n×n} |
双随机矩阵(Birkhoff多面体) |
| 恒等映射 |
完全保持 |
被破坏 |
部分恢复(均值/范数守恒) |
| 信号稳定性 |
保证 |
不保证(可能爆炸/消失) |
保证 |
| 表达能力 |
基础 |
强(但不稳定) |
强且稳定 |
mHC的形而上总结:在保留HC“多通道信息流”丰富表达能力的同时,通过将混合矩阵约束到双随机流形,恢复了信号传播的稳定性,从而实现了稳定的大规模训练。
9、延伸思考
9.1 其他可能的流形约束
双随机矩阵是不是唯一的选择?还有哪些矩阵结构可以保证稳定性?
- 正交矩阵:
Q^T Q = I,完全保持欧氏范数,但计算投影更复杂。
- 随机矩阵(仅行和为1):更宽松的约束,但不保证列和守恒。
- 缩放矩阵:
αI (α<1),主动衰减信号,可能导致信息损失。
每种选择都有不同的几何和信息论含义,值得探索。
9.2 与正则化的关系
传统的L2正则化通过惩罚参数大小来防止过拟合。mHC的流形约束可以看作一种几何正则化——约束参数的“形状”而非“幅度”。
不是限制参数的“大小”,而是限制参数必须落在某个“几何结构”上。
9.3 深度与宽度的新理解
此前我们指出:“增加模型的宽度只能增加某一阶项的影响,而增加模型深度则等价于引入新的高阶展开项。”mHC提供了新视角:
- HC的n流设计:在每一“阶”引入n个并行的子项。
- mHC的约束:确保这n个子项的混合是“守恒”的。
这就像在深度(层数)之外,开辟了一个新的扩展维度(流数),同时通过双随机约束保证这个新维度不会引入不稳定性。
10、总结
通过泰勒级数这一可解释性框架,我们递进式地解读了mHC:
- HC的创新:将“各项独立累加”扩展为“各项被累积矩阵调制”,引入更丰富的层间交互。
- HC的问题:无约束的累积矩阵破坏了恒等映射性质,导致信号爆炸或消失。
- mHC的解决方案:将混合矩阵约束到双随机流形,利用其三大性质——列随机(保持信号均值)、范数不扩张(限制信号幅度)、乘法封闭(保证任意深度的稳定性)。
- 核心洞见:深度学习的稳定性来自于“受控的信号传播”,mHC正是在多流架构中恢复这种“控制”的优雅方案。
感想:深度网络的稳定在于信息流的守恒。mHC用双随机矩阵,让“多流架构”学会了“信号守恒”,从而在保持丰富表达能力的同时,实现了稳定的大规模训练。这或许暗示了一个更深刻的设计原则:
在追求模型表达能力的同时,必须尊重某种“守恒律”——这是深度学习稳定性的基石。
欢迎在云栈社区继续探讨更多关于模型架构与优化的话题。
 发表于 2026-1-21 04:10:51
|
查看: 207|
回复: 0
发表于 2026-1-21 04:10:51
|
查看: 207|
回复: 0
