
2026年初,DeepSeek发布了一篇新论文,提出了一种名为mHC(流形约束超连接)的新架构。这项研究旨在解决传统超连接在大规模模型训练中的不稳定性问题,同时保持其显著的性能增益。
DeepSeek发布的mHC架构以“几何约束”为核心突破,试图破解超大规模模型训练中“性能与稳定性不可兼得”的行业困局。这一架构不仅在270亿参数模型中实现平稳收敛,更在8项核心基准测试中全面超越现有方案,标志着大模型架构设计从“经验试错”向“理论驱动”的关键转型。
一、架构诞生:破解超连接的“稳定性死穴”
要理解mHC的创新价值,需要先厘清大模型架构演进中的核心矛盾。
1.1 从残差连接到超连接的演进困境
自2015年ResNet提出残差连接(y = x + F(x))以来,这一“恒等映射”设计成为深度学习的基石——它通过保留主信号传输通道,避免了深层网络的梯度消失问题。但随着模型规模突破千亿参数,单一残差流的表达力不足逐渐显现:
- Pre-Norm瓶颈:主流LLM采用的Pre-Norm残差结构虽保证稳定性,却导致“表示坍塌”,近半数深层网络特征冗余;
- Post-Norm局限:维持特征多样性的Post-Norm结构,在深层网络中易引发梯度爆炸。
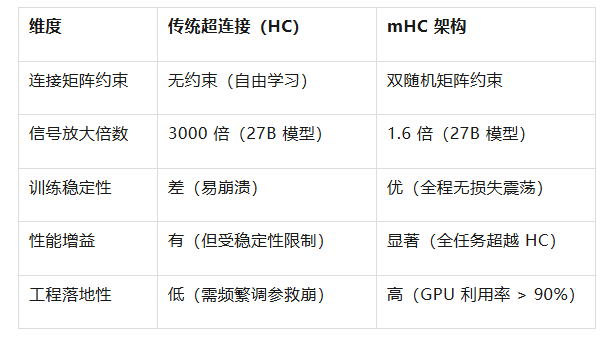
2024年字节跳动提出的超连接试图通过“多并行残差流 + 可学习连接矩阵”突破瓶颈,但其无约束设计存在致命缺陷:连接矩阵破坏了恒等映射特性,导致信号在传播中失控。DeepSeek实验显示,270亿参数模型中,传统超连接的信号放大倍数可达3000倍,训练至12000步时必然出现损失骤升与崩溃。
1.2 mHC的核心解法:流形约束下的信号守恒
mHC架构的本质是为超连接引入数学硬约束,将连接矩阵限制在“双随机矩阵构成的流形空间(Birkhoff多胞形)”中,实现“约束下的自由探索”。其核心设计包含三层逻辑:
(1)几何约束:给连接矩阵装“安全锁”
双随机矩阵的三大特性从根源上解决了稳定性问题:
- 谱范数有界:最大特征值为1,信号传播仅做特征凸组合,不会系统性放大(实测信号放大倍数压缩至1.6倍);
- 乘法封闭:多层矩阵连乘后仍保持双随机性,避免累积误差爆炸;
- 兼容恒等映射:单位矩阵是双随机矩阵的特例,完整保留传统残差连接的稳定性基线。
形象地说,传统超连接是“无规则飙车的多车道”,而mHC通过“车道规划”让信息在能量守恒的边界内高效流转。
(2)工程实现:低开销的约束落地
为避免“稳定性牺牲效率”,mHC采用算法优化 + 硬件适配的组合策略:
- 约束算法:使用工程成熟的Sinkhorn-Knopp算法,将无约束矩阵投影为双随机矩阵,计算简单且可与主干流程融合,额外开销仅6.7%;
- 硬件优化:通过TileLang混合精度核、内核融合等技术,将GPU利用率维持在90%以上,270亿参数模型训练内存占用降低40%。
(3)实验验证:规模越大优势越显著
在3B、9B、27B参数模型的对比测试中,mHC展现出三大优势:
- 稳定性:训练曲线全程平稳,梯度范数波动较传统超连接降低87%,1万亿token训练无过拟合;
- 性能:BBH复杂推理任务得分51.0(超HC 2.1个百分点),DROP阅读理解得分53.9(超HC 2.3个百分点);
- 可扩展性:参数规模从3B增至27B时,性能增益持续扩大,证明对超大规模模型的适配性。
二、架构对比:mHC与主流方案的核心差异
mHC的突破性可通过与三类核心架构的对比凸显:
2.1 与传统残差连接对比

2.2 与传统超连接对比
2.3 与业界主流大模型架构对比
当前GPT-4o、Gemini等头部模型仍基于改进型Transformer架构,mHC在核心设计上实现了代际突破:
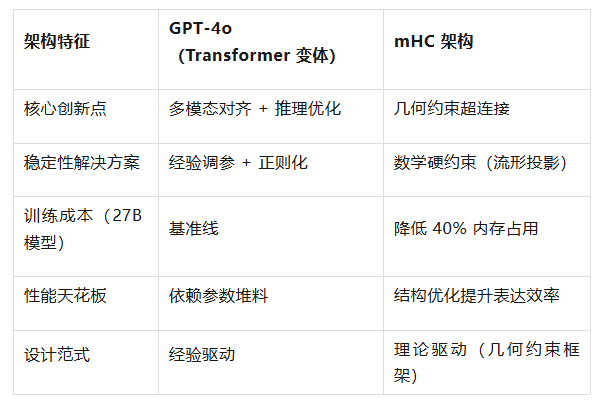
需要强调的是,mHC并非要取代Transformer,而是对其核心组件(残差连接)的重构——可无缝集成到现有Transformer框架中,这为行业升级降低了迁移成本。
三、技术新范式:从技术突破到生态重构
mHC的发布不仅解决了工程痛点,更重塑了大模型发展的底层逻辑:
3.1 降低超大规模模型门槛
通过40%的内存占用降低和80%的硬件门槛下降,mHC让中小企业有机会参与百亿级模型研发。例如农产品识别创业公司,无需依赖大厂API,即可用6块显卡训练高精度模型。
3.2 推动架构设计范式转型
以往架构创新多依赖“试错式调参”,而mHC证明“几何约束 + 谱性质优化”是系统性解决方案。这一思路可延伸至多模态、稀疏模型等领域,为更复杂的网络拓扑设计打开空间。
3.3 强化国产架构话语权
在全球大模型架构竞争中,mHC是首个由中国团队提出的、具备理论开创性的基础组件。其开源后有望成为行业标准,推动国产大模型从“参数跟跑”转向“架构领跑”。
四、未来展望:流形约束的扩展空间
DeepSeek在论文中强调,双随机矩阵仅是起点。未来mHC架构将向两个方向演进:
- 场景化流形设计:针对医疗诊断、自动驾驶等任务,定制专属流形空间,平衡推理速度与精度;
- 多约束融合:结合稀疏性约束、低秩约束等,进一步优化模型效率;
- 跨架构适配:与MoE(混合专家)、注意力机制结合,打造“约束 + 稀疏”的下一代架构。
对行业而言,mHC的价值不仅在于当下的性能提升,更在于提供了一套“稳定性、表达力、效率”的三角平衡框架。在AI从“参数竞赛”转向“效率竞赛”的关键期,这类底层创新将成为产业高质量发展的核心动力。
这项来自DeepSeek的研究展示了如何通过严谨的数学约束来解决大规模模型训练中的核心稳定性问题,为未来的开源实战项目提供了重要的理论参考。对于希望深入理解大模型架构演进和优化细节的开发者,可以在云栈社区的技术文档板块找到更多相关的深度解析和讨论。
 发表于 2026-1-12 17:07:59
|
查看: 188|
回复: 0
发表于 2026-1-12 17:07:59
|
查看: 188|
回复: 0
