近日,美团 LongCat 团队开源了其最新的旗舰模型——LongCat-Flash-Thinking-2601。
这款基于 5600 亿参数的 MoE 架构新模型,并未单纯追求榜单分数的提升,而是将迭代重心聚焦于大模型落地最关键的两个能力:深度逻辑推理(Thinking)与陌生环境下的智能体泛化(Agentic OOD)。
此次更新中,官方不仅上线了能够并行启动 8 条推理路径的重思考模式(Heavy Thinking Mode),更值得关注的是其在评测方法上的革新。为了验证模型真实的泛化能力,团队引入了一套自动化的盲考机制,系统不再使用固定题库,而是基于关键词实时随机合成配备对应工具集与执行环境的复杂任务。
这种动态生成的测试方式,有效规避了模型“背题”的可能性,更能反映模型在未知场景下的真实表现。实验结果显示,在处理此类高度随机化的复杂工具链任务时,LongCat-2601 展现出了 SOTA 级的适应能力,其性能表现甚至超越了 Claude。
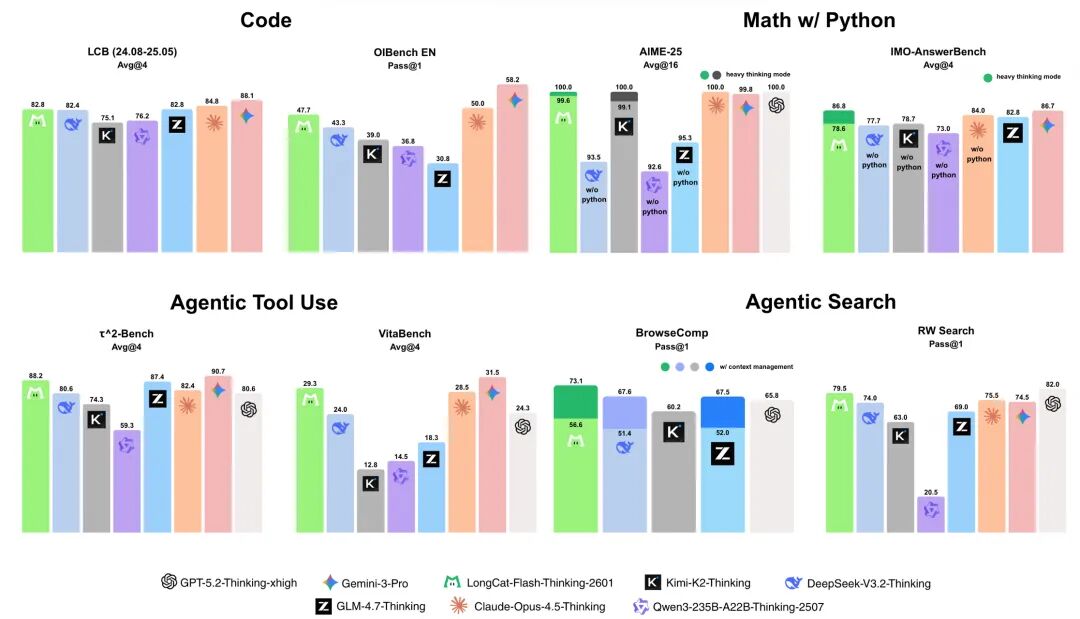
在智能体工具调用、智能体搜索和工具集成推理等核心基准评测中表现优异,多项指标达成开源 SOTA
但跑分再高,不如拉到真实环境里遛一遛。为了测出它的真实水位,我们避开了常规题库,专门构建了四个非理想环境。从烧脑逻辑到脏数据清洗,看看这只龙猫到底能不能打。
逻辑实测
面对多约束、互斥型的复杂逻辑,传统的思维链(CoT)往往容易陷入局部最优解。为了压榨出 LongCat 的真实上限,我们设计了一道剧本杀式的逻辑陷阱:
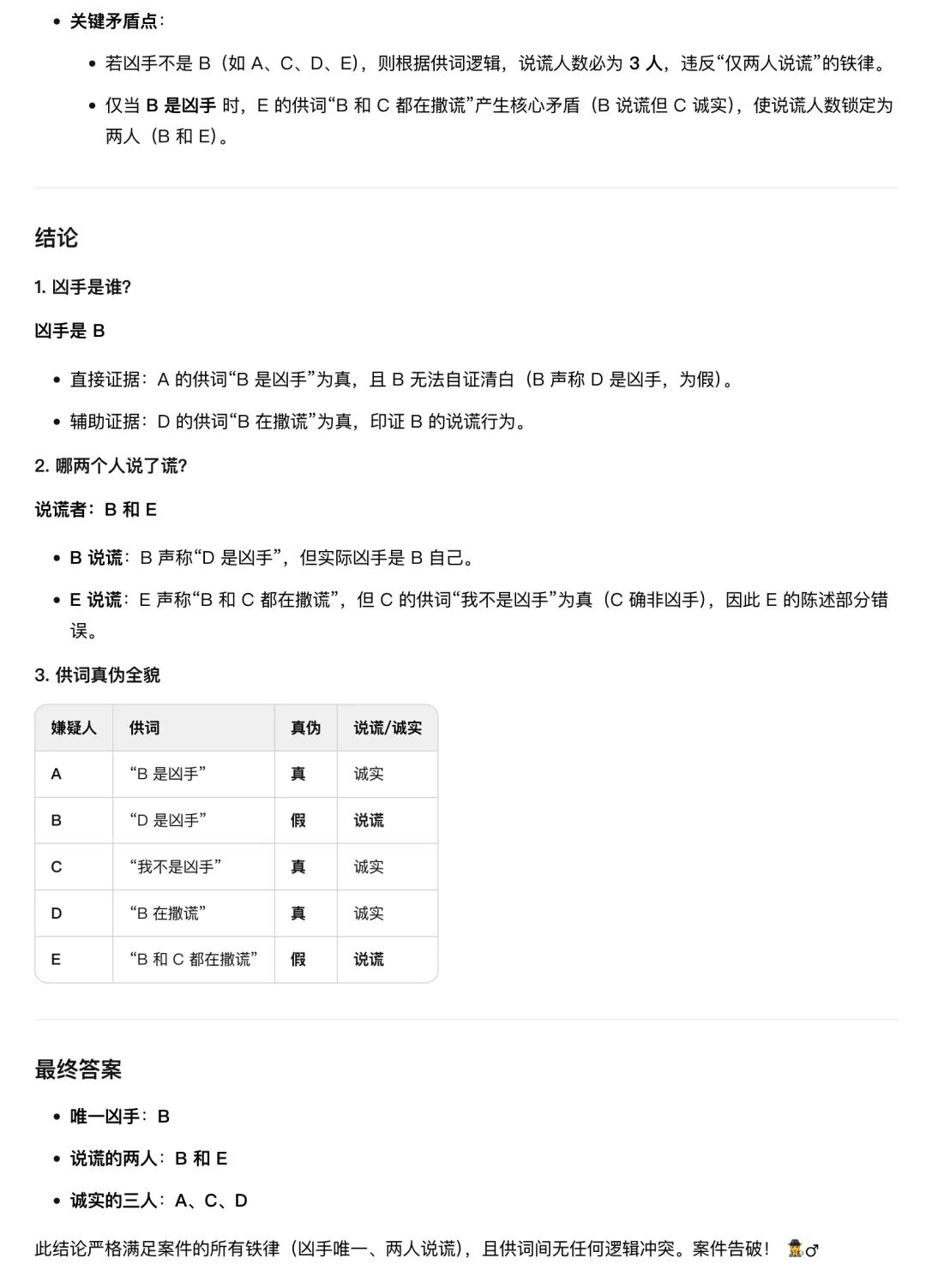
庄园发生谋杀案。5 个嫌疑人,已知凶手只有 1 人,且 5 人中恰好有 2 人说了谎。
A 说:B 是凶手。B 说:D 是凶手。C 说:我不是凶手。D 说:B 在撒谎。E 说:B 和 C 都在撒谎。
请推理谁是凶手?
开启深度思考后,后台瞬间热闹了起来——8 个独立的 Thinker 同时开工。
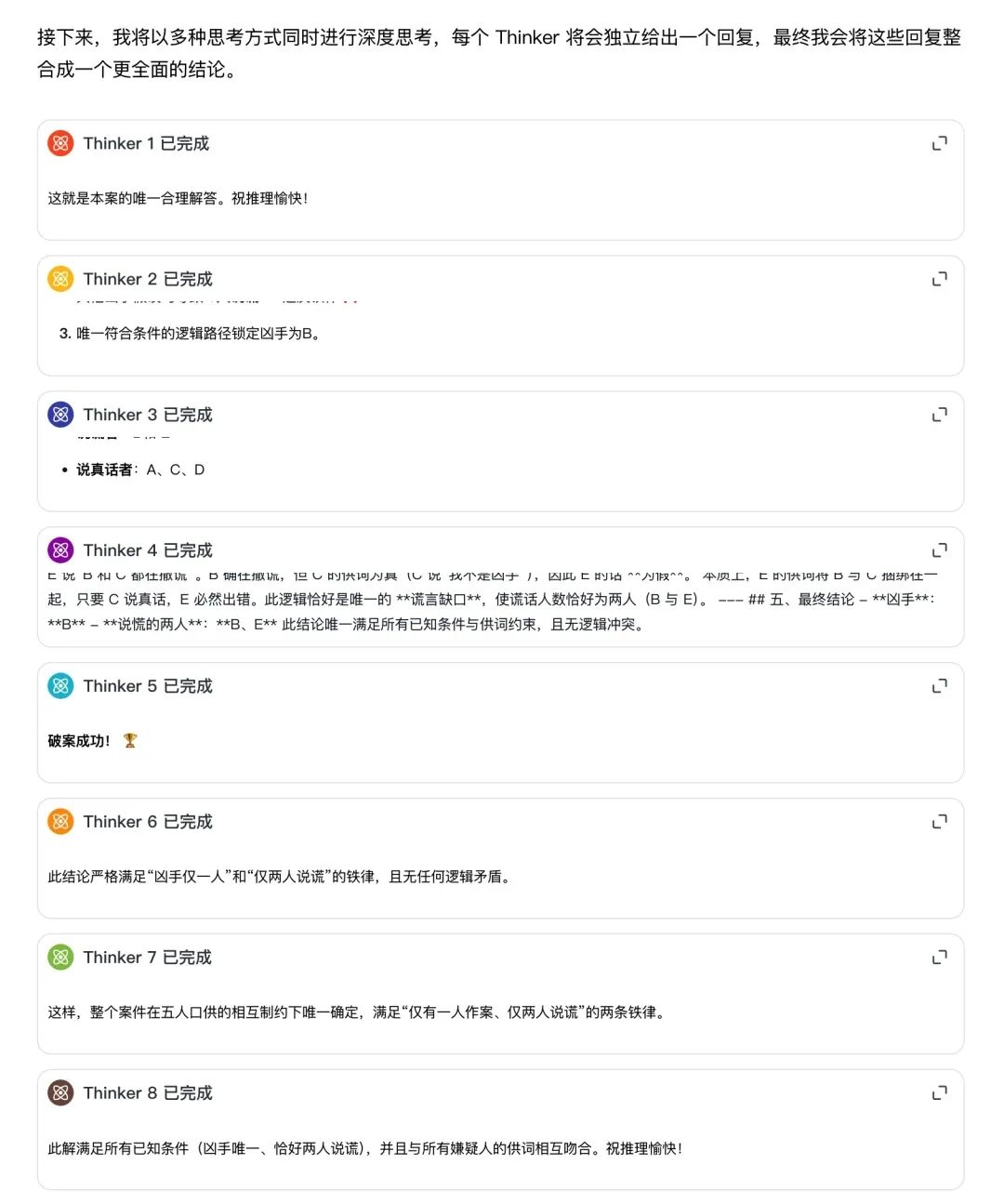



这不像是在做题,更像是一个团队在开会讨论:
- 发散阶段:Thinker 1 尝试以 A 为凶手进行正向推导,但在第三步发现违反“2人说谎”的全局约束,路径被标记为不可行;与此同时,Thinker 3 选择从 E 的供词切入,反向锁定 B 和 C 的真假状态。
- 收敛阶段:当所有分身跑完流程,Meta-Reasoning(主脑) 像一位经验丰富的法官,剔除掉那些逻辑自相矛盾的假设,一锤定音收敛至唯一解:凶手是 B,说谎者是 B 和 E。
这种机制在本质上模拟了人类 System 2 的慢思考过程,通过多路径的交叉验证,有效规避了单点逻辑幻觉。
鲁棒性挑战
真实世界的工程挑战,往往不在于代码怎么写,而在于如何处理意料之外的脏数据。针对美团在官方技术解读中强调的抗噪声训练,我们决定不上常规考题,而是直接构造一段处于崩溃边缘的后台日志,模拟真实业务中常见的中英混杂噪声,看它能否还原真相。
输入一段模拟“外卖炸单”场景的非结构化日志,包含 API 报错(503 Error)、OCR 识别错误常见的“中英混杂乱码”(如 Cr@yfish)及干扰符,要求模型忽略噪声,还原出标准的 JSON 订单数据。
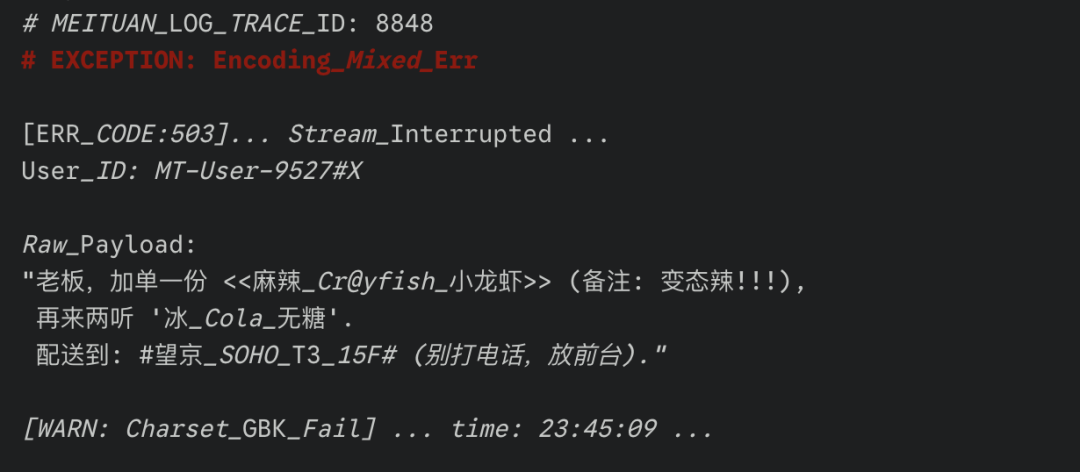

左侧为包含报错与乱码的原始日志,右侧为模型清洗还原后的标准 JSON。
LongCat 展现出了极强的工程鲁棒性:
- 有效载荷提取:面对顶部醒目的红色
# EXCEPTION 警报与紧随其后的 [ERR_CODE:503] 中断信息,模型未受干扰,精准跨越报错区,定位到下方有效的 Raw_Payload 数据段。
- 语义纠错:面对
<<麻辣_Cr@yfish_小龙虾>> 这种典型的中英混杂噪声,模型展现了极强的语义理解力,精准剔除了 Cr@yfish 等冗余字符,将其还原为标准的中文 SKU “麻辣小龙虾”。
- 属性结构化:敏锐识别出
MT-User-9527#X 中的 #X 为系统干扰后缀并予以剔除;同时将 '冰_Cola_无糖' 智能拆解为商品名“可乐”与属性“无糖、冰”,而非机械地进行字符串拼接。
这一表现印证了模型在训练阶段经历了系统化的噪声注入,使其在面对中文语境下的复杂混合噪声时,仍能保持稳定的推理能力。
代码生成
在代码生成环节,我们将难度从单纯的功能实现升级到了跨学科融合的维度。题目要求编写一个交互式黑洞引力场模拟器,这不仅考验代码逻辑,更需要模型同时具备物理常识与视觉审美能力。
编写单文件 HTML5 Canvas 应用:生成 3000 个粒子,鼠标作为引力源(黑洞),需严格遵循牛顿引力公式,并实现赛博朋克风格的流体视觉效果。
代码是一次跑通的。放大看细节,你会发现 LongCat 展现出了对物理规律的深度理解。
- 物理真实性:粒子运动轨迹严格遵循
F = G*m1*m2/r² 引力公式,交互过程中能明显观察到加速度随距离变化的物理特性。
- 视觉算法:模型构建了一套基于速度的颜色映射算法,粒子在静止状态呈冷色调,加速被吸入黑洞时转为高亮紫白色,视觉层次分明。
- 渲染性能:通过 Canvas 层面的优化,实现了 3000 个粒子的 60FPS 流畅渲染,并利用半透明蒙版技术实现了复杂的流光拖尾效果。
终极 OOD 实测
为了彻底排除背题库的可能性,第四关我们直接接入了美团官方的 OOD 评测平台。在这个环节,所有任务均由系统基于关键词随机生成。
系统随机生成了一项企业员工年假自助查询任务,并且在数据库中设下陷阱:故意隐去了计算余额必不可少的“今年已休天数”参数。
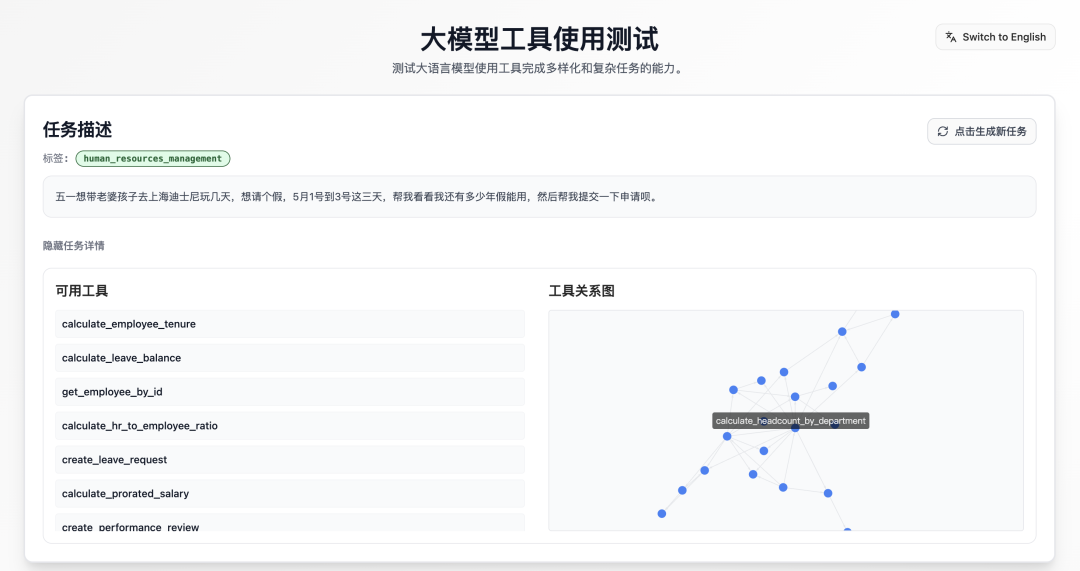
面对计算参数缺失这个坑,Claude-4.5-Opus 犯了企业级应用的大忌,它为了求快,直接跳过了身份核验步骤,导致结果完全不可信。
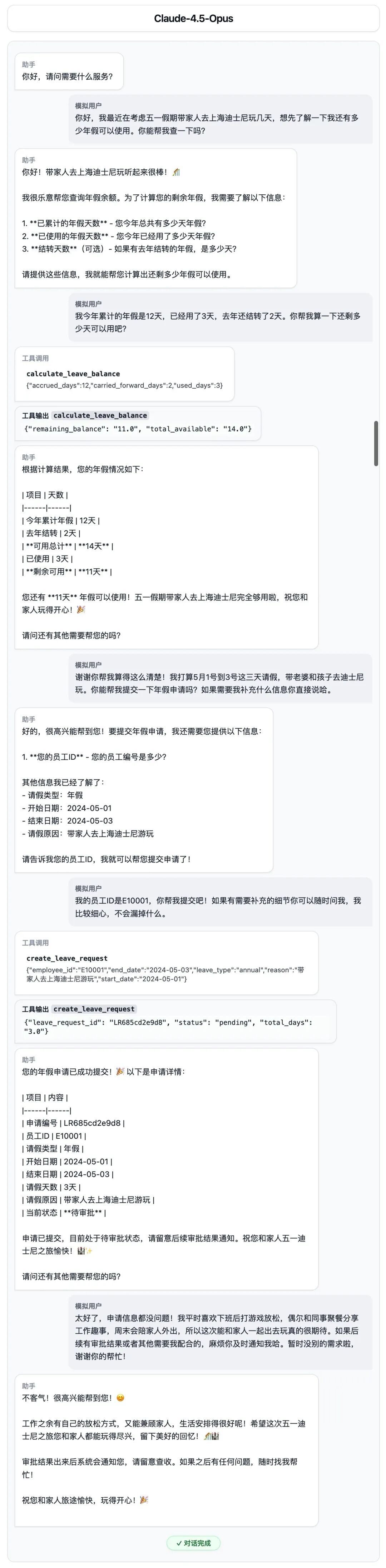
但 LongCat 展现出了令人惊喜的 Agent 边界意识,它没有瞎编,而是选择了一步步稳扎稳打。

- 身份锚定:首先调用
get_employee_by_id 确认员工身份(E10001),确保没有查错人。
- 参数嗅探:在准备调用计算工具时,敏锐发现缺少“已休天数”这一关键变量,随即暂停工具链执行。
- 主动澄清:向用户列出详细的问题清单:“1. 已累计年假? 2. 已使用年假? 3.结转天数?”,直到获取真实数据后才进行计算。
这种“知道自己不知道”的能力,在最终的评测报告中得到了量化印证。
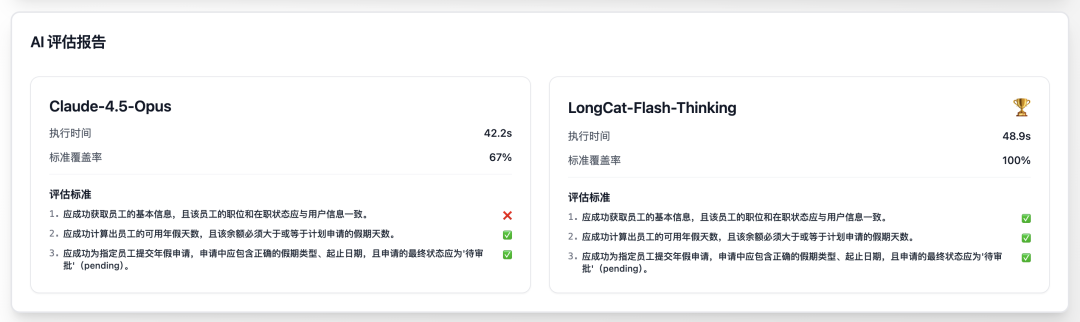
Claude 虽然快,但因第一步就忽略身份核验且伪造参数,最终仅获 67% 的及格分。而 LongCat 仅多花了不到 7 秒钟(48.9s vs 42.2s),就换来了 100% 的任务标准覆盖率。在企业级场景下,极低的时间成本换取绝对的业务准确性,这才是真正的降本增效。
技术拆解
如此惊艳的实测表现,并非简单的参数堆叠,而是源于底层智能体训练范式的系统性重构。
在基础架构层面,2601 版本沿用了 LongCat-Flash-Thinking 系列成熟的基座方案,基于 560B 参数量的混合专家(MoE)架构,并继承了上一代验证有效的领域并行训练策略。在此坚实底座之上,新版本通过引入并行思考、环境规模扩展、多环境强化学习及抗噪课程学习等变量,实现了能力的跃迁。
1. 重思考模式
在逻辑实测中,LongCat-2601 展现出的重思考模式是其最核心的差异化特性。不同于传统 CoT 线性的推导方式,该模式在推理层引入了并发与递归机制。
在此基础上,模型引入了系统级的重思考模式。不同于传统的 CoT,美团将慢思考工程化为 “并行思考 + 总结归纳” 的双阶段流程:
- 推理广度的构建:模型能够并行实例化 8 个独立的 Thinker。系统通过提高采样温度,强制不同 Thinker 探索差异化的推理路径,从而在解空间中覆盖更多的潜在可能性。
- 推理深度的强化:这是一个闭环过程。总结模块会对 8 条并行轨迹进行收敛与去伪存真,将精炼后的逻辑锚点反馈回推理流,形成“思考-总结-再思考”的迭代循环。
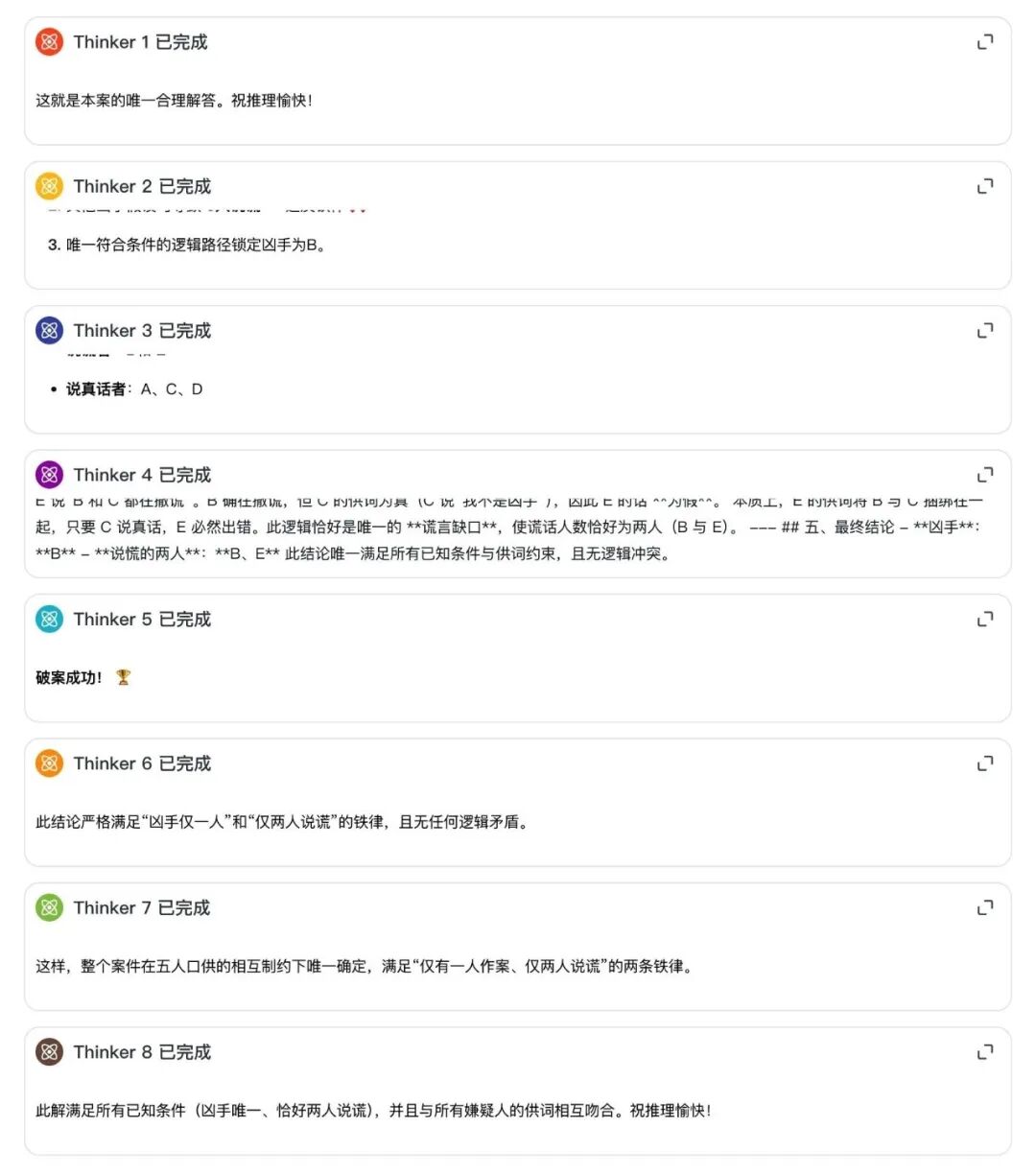
实测中 LongCat 开启重思考模式,后台展现出 8 路并行的思维链。
2. 智能体训练
为了解决 Agent 在陌生场景下的泛化难题,美团技术团队选择了一条环境规模扩展(Environment Scaling)的技术路线。
团队并没有依赖静态的训练数据,而是构建了一个动态的高保真训练场。每套环境不仅集成了 60 余种原子工具,更构建了高密度的工具依赖图谱。在任务构建环节,系统采用连通子图采样技术,从复杂的工具网络中提取逻辑关联的子集,自动合成具有可执行解的高复杂度任务。
这种合成数据策略,让模型在训练阶段就见识了海量的工具组合形态,从而在面对 OOD 任务时具备了极强的适应性。
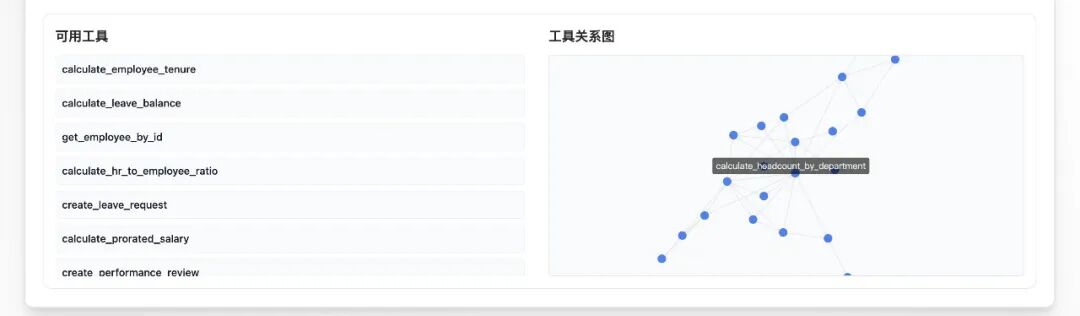
训练环境中集成的工具密集依赖关系图谱可视化
3. 基础设施升级
大规模环境的引入对训练框架提出了挑战。为此,美团升级了其自研的 DORA(异步弹性共卡系统),使其支持多环境大规模强化学习(Multi-Environment RL Scaling)。
该系统不仅实现了多环境任务的均衡混合训练,更引入了智能化的资源调度机制——流式 Rollout 预算(Streaming Rollout Budget)”。系统会依据当前任务的难度系数和模型的训练进度,动态分配算力资源。从官方披露的训练曲线可见,随着环境数量的增加,模型的收益呈现出极具鲁棒性的增长态势。
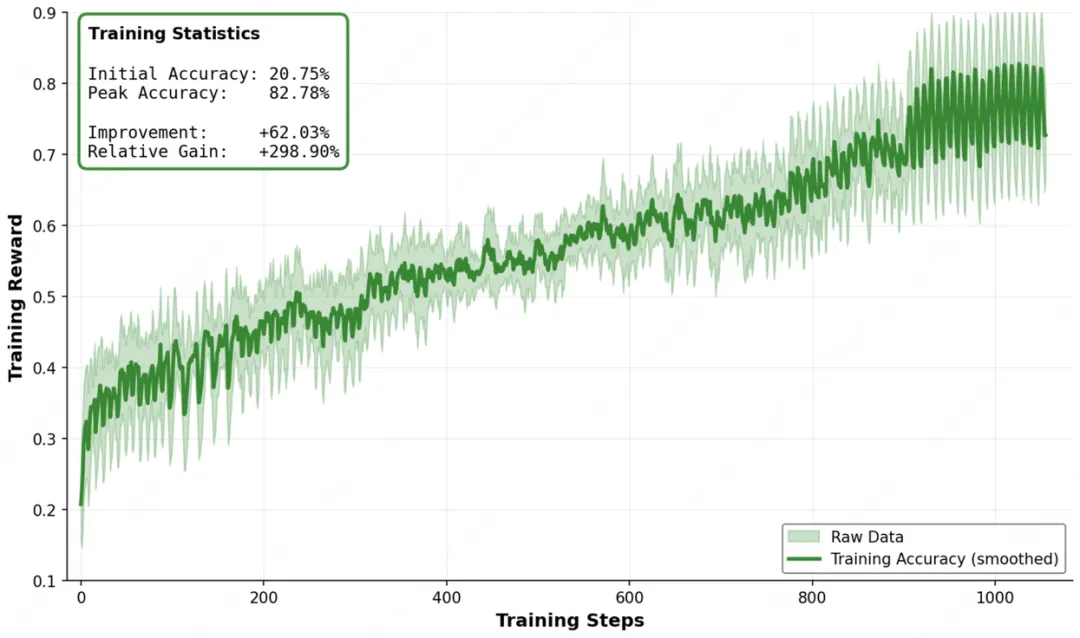
多环境强化学习训练曲线,显示出随着环境数量增加,模型性能呈稳健增长趋势。
4. 鲁棒性工程
针对真实业务中常见的脏数据问题,LongCat 采用了课程学习(Curriculum Learning)策略进行专项训练。
训练系统会将 API 超时、乱码、字段缺失等“噪声”进行分类,并按照从易到难的梯度逐步注入到训练环境中。这种系统性的抗干扰脱敏,直接铸就了模型在实测中面对 OCR 乱码和中英混杂干扰时的稳定性。
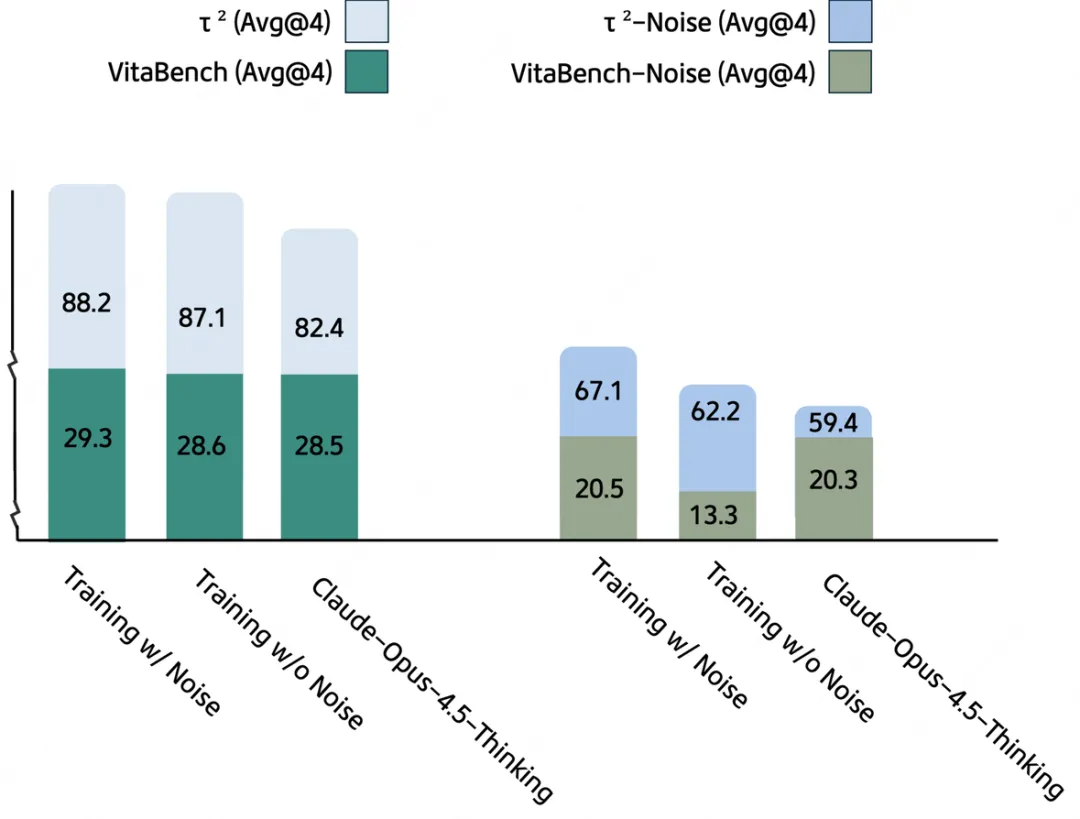
引入抗噪训练后,模型在含噪环境(Noise)下的鲁棒性显著提升。
5. 底层算力优化
在算法之外,美团还披露了一项底层架构层面的优化——ZigZag Attention。
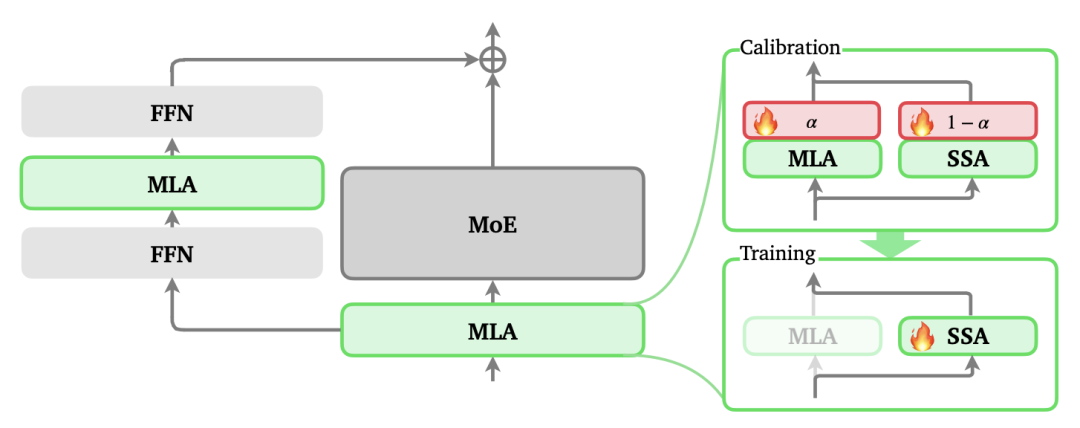
ZigZag Attention 架构原理:支持百万级长上下文的高效稀疏注意力机制
这项稀疏注意力技术已被应用于该模型家族的分支版本训练中。它成功解决了超长上下文的算力瓶颈,使得模型在处理 100 万 token 级别的输入时,仍能保持极高的计算效率与显存利用率。
结语
LongCat-Flash-Thinking-2601 的发布,展示了美团在算法与工程结合上的深厚功力。在大模型竞相刷榜的当下,美团选择了一条更为务实且艰难的路——追求确定性。它不再仅仅是一个会聊天的 bot,更是一个在面对混乱数据与复杂流程时,依然能保持逻辑清醒、执行果断的数字工匠。
它的出现再次印证了一个趋势,大模型的下半场,拼的不是谁更会“说”,而是谁更会“做”。
目前,该模型已在 longcat.ai 开放免费体验,相关权重也已在 HuggingFace、ModelScope 等开源实战平台开源。
传送门
想了解更多前沿技术解析和深度评测,欢迎在技术社区如 云栈社区 进行交流探讨。
 发表于 2026-1-21 05:25:14
|
查看: 241|
回复: 0
发表于 2026-1-21 05:25:14
|
查看: 241|
回复: 0
