在攻防演练中,我们经常会遇到目标单位名称提供不准确的情况。这导致在后续搜集资产时“查无此家”,极大地影响了效率。例如,目标可能给出“浙江中医六院”这样的简称,但其备案全称实为“浙江中医药大学附属第六医院”;又或者某单位已更名,但各类备案信息仍未更新。手动对大量此类名称进行纠错既费时又费力,在争分夺秒的演练前期阶段尤为吃亏。为此,开发一个能够批量、自动纠正目标名称的脚本就显得非常必要。
起初,我的思路是寻找一个类似爱企查或天眼查的企业信息查询网站,通过抓包分析后替换参数来实现批量请求。然而,这些大型商业网站的 API 参数和风控校验极为严格,很难绕过。经过一番寻找,最终在 https://riskbird.com/ 这个网站上找到了突破口,成功实现了批量查询。
其核心是编写一个向风鸟(RiskBird)网站发送查询请求的 Python 函数:
def req_riskbird(company_name, token):
url = "https://riskbird.com/riskbird-api/newSearch"
headers = {
"Host": "riskbird.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36",
"Accept": "application/json",
"App-Device": "WEB",
"Content-Type": "application/json",
"Origin": "https://riskbird.com",
"Referer": "https://riskbird.com/search/company",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": f"token={token}; app-device=WEB;"
}
payload = {
"queryType": "1",
"searchKey": company_name,
"pageNo": 1,
"range": 10,
"selectConditionData": "{\"status\":\"\",\"sort_field\":\"\"}"
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status() # Raise an exception for HTTP errors
data = response.json()
if data.get("code") == 20000 and data.get("success"):
# Extract company names from the response
company_names = []
for company in data.get("data", {}).get("list", []):
if "entName" in company:
company_names.append(company["entName"])
return company_names
else:
print(f"Error: {data.get('msg', 'Unknown error')}")
return []
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return []
except json.JSONDecodeError:
print("Failed to parse response as JSON")
return []
我们指定查询“美的”进行测试,可以看到函数成功返回了包含“美的”关键词的一系列公司名称,功能正常。
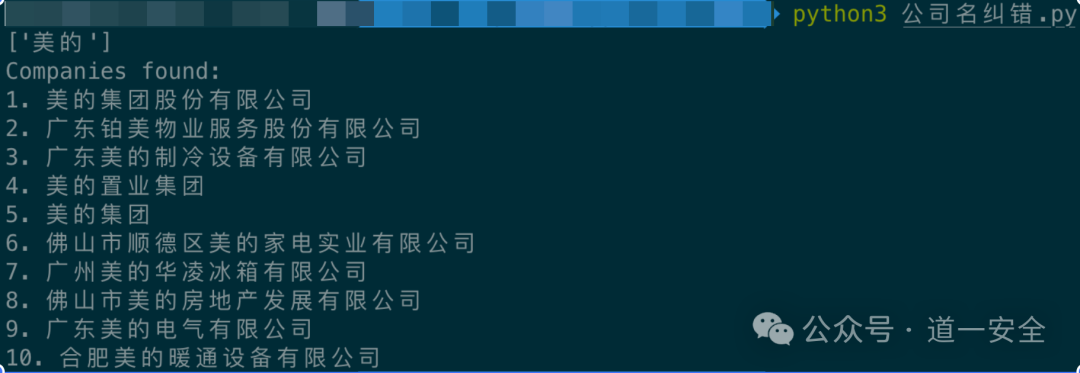
接下来是实现自动化纠错逻辑。我设计了两种模式:当 num 参数为 1 时,程序默认选择匹配度最高的第一个结果;为 2 时,则会列出所有结果让用户手动选择。
def compare_company(company_name, num, token):
# 调用 req_riskbird 函数获取公司名称列表
company_names = req_riskbird(company_name, token)
if not company_names:
# 如果没有返回任何公司名,则返回空列表
print("未找到相关公司:",company_name)
return []
if num == 1:
# 如果选择 1,返回第一个结果
return [company_names[0]]
elif num == 2:
# 如果选择 2,返回所有结果并允许用户手动选择
print("以下是搜索到的所有公司名称:")
for i, name in enumerate(company_names, 1):
print(f"{i}. {name}")
# 用户选择公司
try:
print("搜索单位:",company_name)
selected = int(input("请输入选择的公司编号:"))
if 1 <= selected <= len(company_names):
return [company_names[selected - 1]]
else:
print("无效的选择")
return []
except ValueError:
print("无效的输入")
return []
else:
print("无效的 num 参数")
return []
指定参数 -n 2 运行脚本,程序会列出所有搜索结果并等待用户输入选择,功能正常。
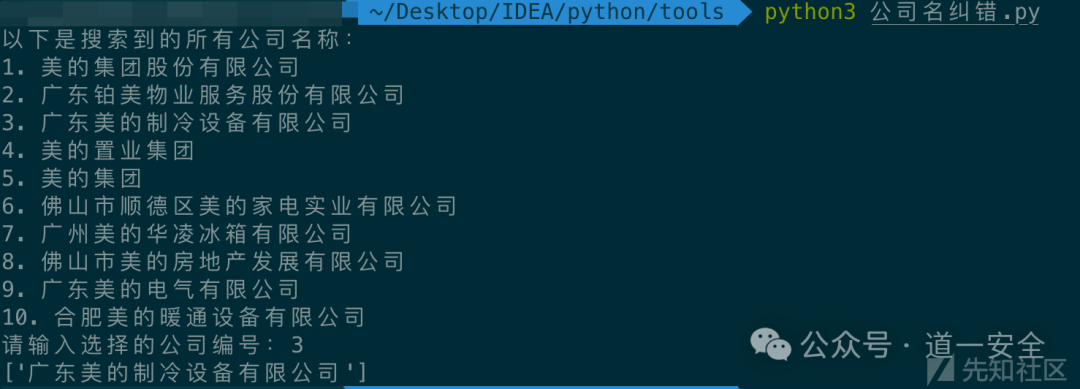
我们的最终目标是从文件中批量读取目标名称进行处理。因此,需要一个读取文件的函数:
def read_file():
"""
读取同目录下的tar.txt文件,将每行内容(公司名称)存入列表并返回
参数:
无
返回值:
list: 包含所有公司名称的列表
异常:
如果文件读取失败,将抛出相应的异常
"""
company_list = []
try:
with open('tar.txt', 'r', encoding='utf-8') as file:
for line in file:
# 去除每行的空格和换行符
company_name = line.strip()
if company_name: # 确保不添加空行
company_list.append(company_name)
return company_list
except FileNotFoundError:
raise FileNotFoundError("错误:tar.txt 文件不存在")
except IOError:
raise IOError("错误:无法读取 tar.txt 文件")
except Exception as e:
raise Exception(f"读取文件时发生错误: {str(e)}")
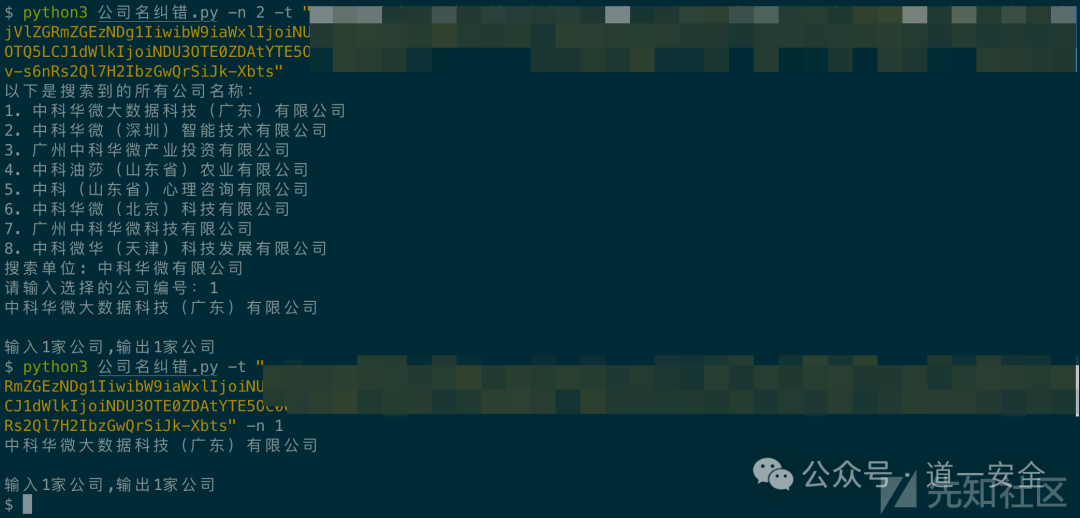
将待纠正的单位名单放入 tar.txt,运行脚本后,工具能够成功输出纠正后的标准化名称列表。例如,输入文件中可能包含大量不规范的简称或旧称,输出则是对应的准确全称。

在实际攻防演练中,这个工具能发挥巨大作用。例如,某目标单位在信息中使用了简称“中科华微有限公司”,这可能导致资产发现引擎无法准确关联。通过工具纠正,我们得到了其准确的全称“中科华微大数据科技(广东)有限公司”,从而能够顺利展开后续的资产搜集与漏洞扫描工作。
另一个典型案例是“浙江省中山医院”。通过查询得知,其完整名称应为“浙江中医药大学附属第三医院(浙江省中山医院)”。这对于精准定位该医院的官网、子域名、备案系统等资产至关重要。

最终完整的脚本代码如下,它整合了文件读取、API查询、交互选择与结果输出功能,可通过命令行参数灵活调用:
import requests
import json
import argparse
def read_file():
"""
读取同目录下的tar.txt文件,将每行内容(公司名称)存入列表并返回
参数:
无
返回值:
list: 包含所有公司名称的列表
异常:
如果文件读取失败,将抛出相应的异常
"""
company_list = []
try:
with open('tar.txt', 'r', encoding='utf-8') as file:
for line in file:
# 去除每行的空格和换行符
company_name = line.strip()
if company_name: # 确保不添加空行
company_list.append(company_name)
return company_list
except FileNotFoundError:
raise FileNotFoundError("错误:tar.txt 文件不存在")
except IOError:
raise IOError("错误:无法读取 tar.txt 文件")
except Exception as e:
raise Exception(f"读取文件时发生错误: {str(e)}")
def req_riskbird(company_name, token):
url = "https://riskbird.com/riskbird-api/newSearch"
headers = {
"Host": "riskbird.com",
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/140.0.0.0 Safari/537.36",
"Accept": "application/json",
"App-Device": "WEB",
"Content-Type": "application/json",
"Origin": "https://riskbird.com",
"Referer": "https://riskbird.com/search/company",
"Accept-Language": "zh-CN,zh;q=0.9",
"Cookie": f"token={token}; app-device=WEB;"
}
payload = {
"queryType": "1",
"searchKey": company_name,
"pageNo": 1,
"range": 10,
"selectConditionData": "{\"status\":\"\",\"sort_field\":\"\"}"
}
try:
response = requests.post(url, headers=headers, json=payload)
response.raise_for_status() # Raise an exception for HTTP errors
data = response.json()
if data.get("code") == 20000 and data.get("success"):
# Extract company names from the response
company_names = []
for company in data.get("data", {}).get("list", []):
if "entName" in company:
company_names.append(company["entName"])
return company_names
else:
print(f"Error: {data.get('msg', 'Unknown error')}")
return []
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return []
except json.JSONDecodeError:
print("Failed to parse response as JSON")
return []
def compare_company(company_name, num, token):
"""
该函数通过调用 req_riskbird 函数,获取与公司名称相关的搜索结果,
根据 num 的值来返回用户选择的企业名称。
参数:
company_name (str): 需要查询的目标公司名称
num (int): 选择显示结果的方式,1表示选择第一个结果,2表示输出所有结果并手动选择
token (str): 用户登录后获取的授权令牌,用于API鉴权
返回值:
list: 包含用户选择的公司名称的列表,若查询失败或没有结果,则返回空列表。
异常:
若调用 req_riskbird 发生异常,将返回空列表。
"""
# 调用 req_riskbird 函数获取公司名称列表
company_names = req_riskbird(company_name, token)
if not company_names:
# 如果没有返回任何公司名,则返回空列表
print("未找到相关公司:",company_name)
return []
if num == 1:
# 如果选择 1,返回第一个结果
return [company_names[0]]
elif num == 2:
# 如果选择 2,返回所有结果并允许用户手动选择
print("以下是搜索到的所有公司名称:")
for i, name in enumerate(company_names, 1):
print(f"{i}. {name}")
# 用户选择公司
try:
print("搜索单位:",company_name)
selected = int(input("请输入选择的公司编号:"))
if 1 <= selected <= len(company_names):
return [company_names[selected - 1]]
else:
print("无效的选择")
return []
except ValueError:
print("无效的输入")
return []
else:
print("无效的 num 参数")
return []
# Example usage
if __name__ == "__main__":
parser = argparse.ArgumentParser(description="主程序功能:根据输入查询公司信息。")
parser.add_argument("-n", "--num", type=int, choices=[1, 2], default=1,
help="选择查询方式:1 - 默认选择匹配度最高的公司;2 - 手动选择公司")
parser.add_argument("-f", "--file", type=str, default="tar.txt",
help="存放公司名称的文件路径,默认为当前目录下的 'tar.txt'")
parser.add_argument("-t", "--token", type=str, required=True,
help="风鸟网站的认证令牌,用于 API 鉴权")
args = parser.parse_args()
company_list=read_file()
res = []
for i in company_list:
res.extend(compare_company(i,args.num, args.token))
for j in res:
print(j)
print(f"\n输入{len(company_list)}家公司,输出{len(res)}家公司")
使用方法:
- 将需要纠正的目标名称按行存入
tar.txt 文件。
- 从
riskbird.com 网站获取登录后的 token。
- 运行命令:
python3 公司名纠错.py -t "你的token" -n 1(自动模式)或 -n 2(交互模式)。
这个工具本质上属于 安全/渗透/逆向 资产信息收集环节的辅助脚本,通过 Python 自动化解决了名称数据清洗的痛点,能显著提升在攻防演练、应急响应等场景下的前期准备工作效率。如果你对这类实战型脚本开发感兴趣,欢迎到 云栈社区 交流讨论。
 发表于 2026-1-22 04:08:21
|
查看: 143|
回复: 0
发表于 2026-1-22 04:08:21
|
查看: 143|
回复: 0
