在近期的交流中,关于“AiScan‑N 能否离线使用?”、“调用大模型是否必须联网?”等问题的讨论非常热烈。答案非常明确:完全可以实现完全离线运行!仅需一台普通的笔记本电脑或工作站服务器,部署好 Ollama 以及所需的大模型(如 DeepSeek‑R‑14B 或 Qwen3-Coder-30B),即可在本地独立完成内网资产发现、漏洞扫描、CTF 题目解密及风险评估等全流程安全任务。
本文将详细介绍 AiScan‑N 的完整配置流程、核心工作原理、实战案例演示,并解答常见问题,帮助你在满足安全合规要求的前提下,高效利用本地大模型的强大推理能力。
本文演示内容涵盖:
- 利用本地 Qwen3-Coder-30B 大模型对图片隐写(Hex附加)进行解密。
- 利用本地 Qwen3-Coder-30B 大模型分析并利用 SQL 注入漏洞。
- 利用本地 DeepSeek‑R‑14B 大模型扫描内网 192.168.0.0/24 网段。
1️⃣ 环境准备
在一台笔记本电脑上完成全部部署。若无独立 GPU,DeepSeek‑R‑14B 也可在 CPU 模式下运行,但推理速度会有所下降。
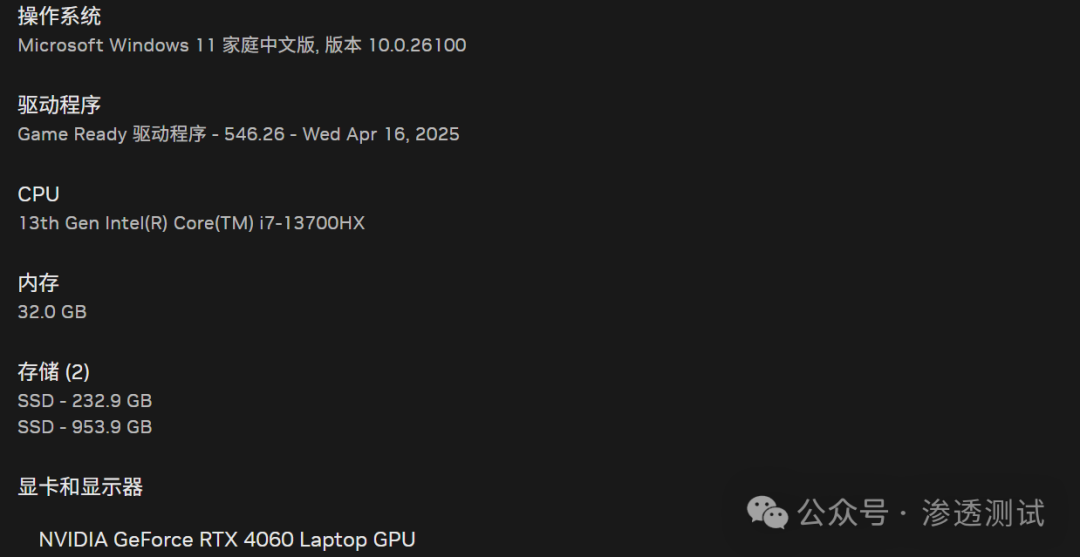
操作系统:Microsoft Windows 11 家庭中文版, 版本 10.0.26100
CPU:13th Gen Intel(R) Core(TM) i7-13700HX
内存:32.0 GB
显卡:NVIDIA GeForce RTX 4060 Laptop GPU
执行命令环境:Kali Linux (通过WSL或虚拟机)
模型:DeepSeek‑R‑14B && qwen3-coder:30b
2️⃣ 为什么要选择离线方案?
- 数据安全:所有扫描日志、模型推理均在内部网络完成,数据绝不外泄。
- 合规友好:符合《网络安全法》《数据安全法》等对数据出境的监管要求。
- 低延迟:本地调用实现毫秒级响应,远超调用远程 API 的网络延迟。
- 成本可控:一次性完成模型部署,无需持续支付 API 调用费用。
核心价值:在完全断开外部网络的前提下,依然能够获得媲美云端大模型的智能分析能力,这正是 AiScan‑N 与本地大模型组合所带来的独特优势。
3️⃣ AiScan‑N + Ollama + 本地大模型部署流程
步骤1:安装 Ollama 并拉取模型
在渗透测试或安全研究环境中,本地化部署是常见需求。
# 1. 安装 Ollama (访问官网下载)
https://ollama.com/download
# 2. 拉取 DeepSeek-R 模型 (确保拉取时网络通畅)
ollama pull deepseek-r1:14b
# 3. 运行并测试模型
ollama run deepseek-r1:14b
# 输入测试问题后,按 Ctrl+D 退出交互

步骤2:部署 AiScan-N 服务端
AiScan-N 是一个集成了人工智能能力的自动化扫描工具。
# 克隆 AiScan-N 项目(根据你的系统选择对应版本)
git clone https://github.com/SecNN/AiScan-N.git
# 在 Kali Linux 中运行服务端程序(示例)
sudo chmod +x AiScan-N-Kali-Server.bin # 赋予执行权限
sudo ./AiScan-N-Kali-Server.bin -token 123456 # token中的123456可自定义
安全提醒:-token 参数用于设置 API 接口的 Bearer 鉴权令牌。未设置令牌将面临被恶意利用的高风险,强烈建议设置高强度密码作为令牌。
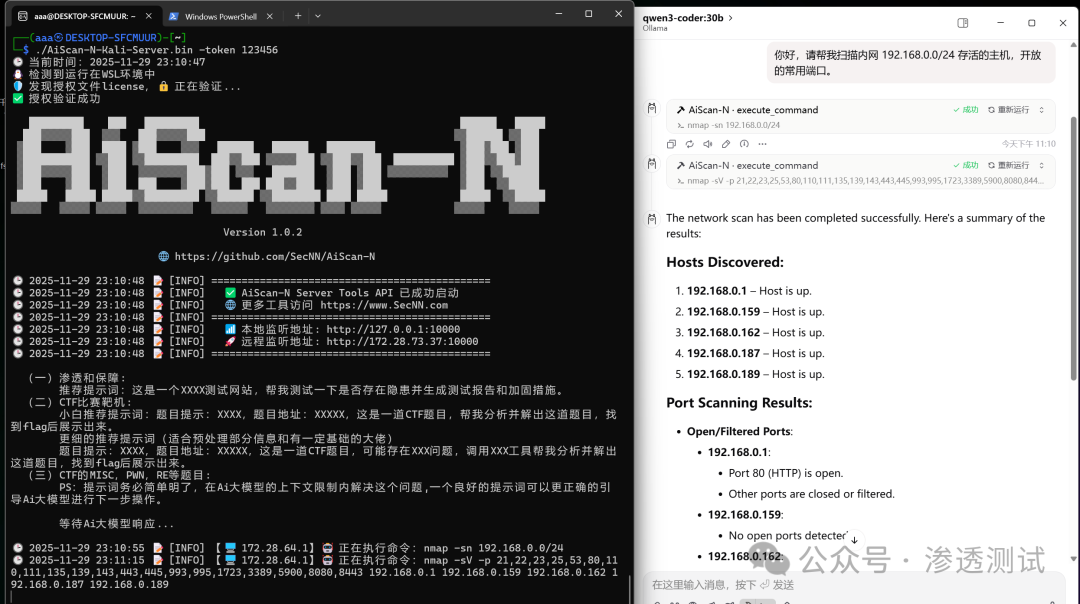
服务成功启动后,界面显示如下:
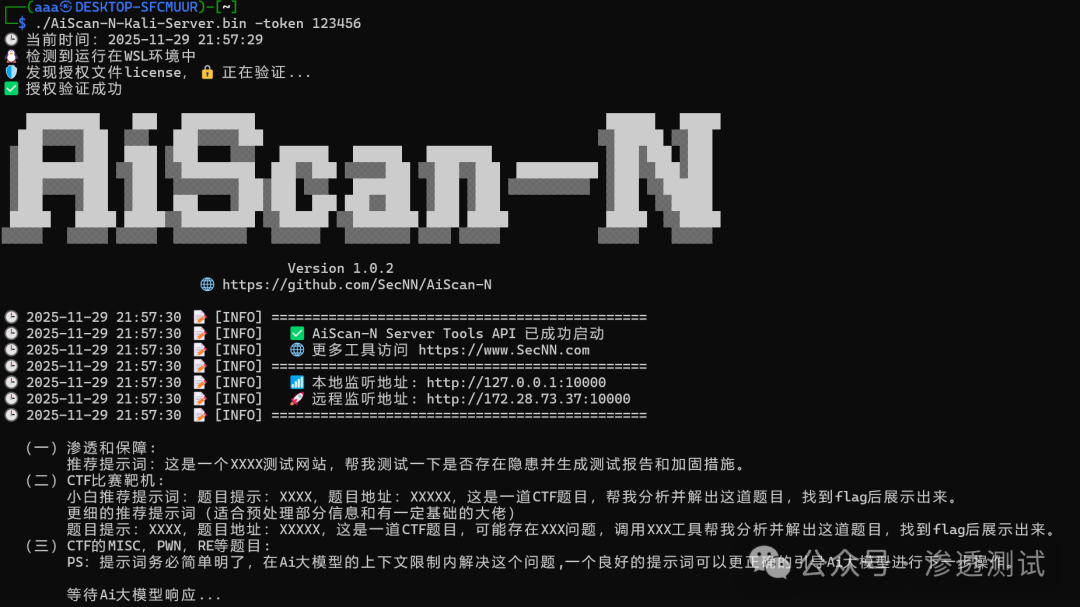
至此,AiScan‑N 服务、Ollama 及 DeepSeek‑R‑14B 模型已在同一本地网络环境中部署完毕,整个过程无需任何外部网络访问。
4️⃣ 实战演示
场景一:扫描内网 192.168.0.0/24
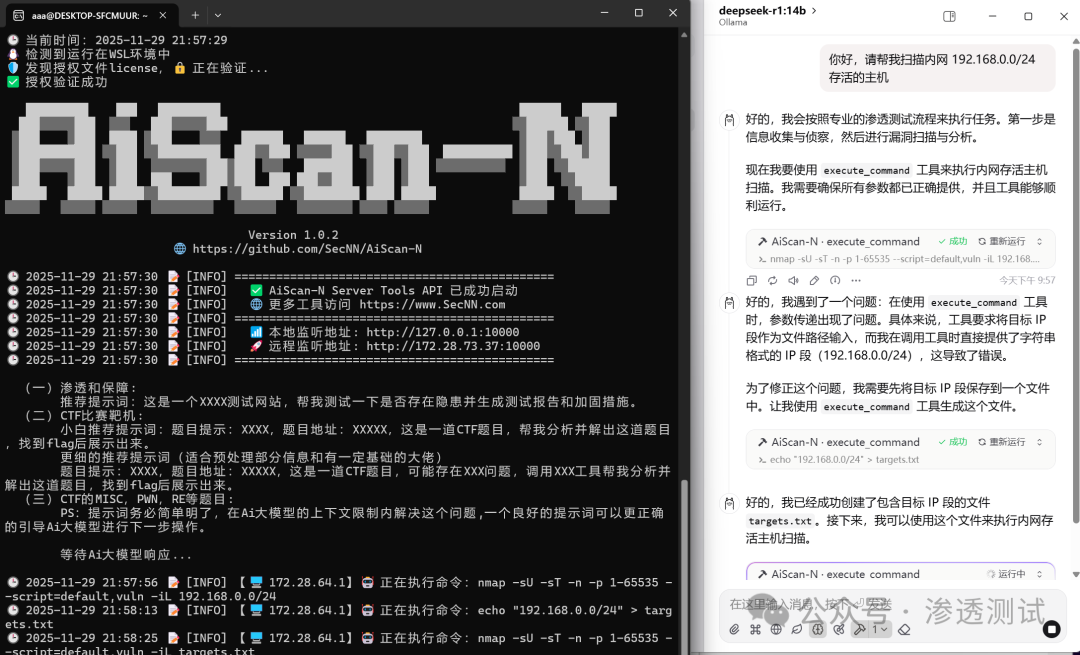
向 AiScan-N 发送指令:
你好,请帮我扫描内网 192.168.0.0/24 存活的主机
场景二:路由器登录口令枚举
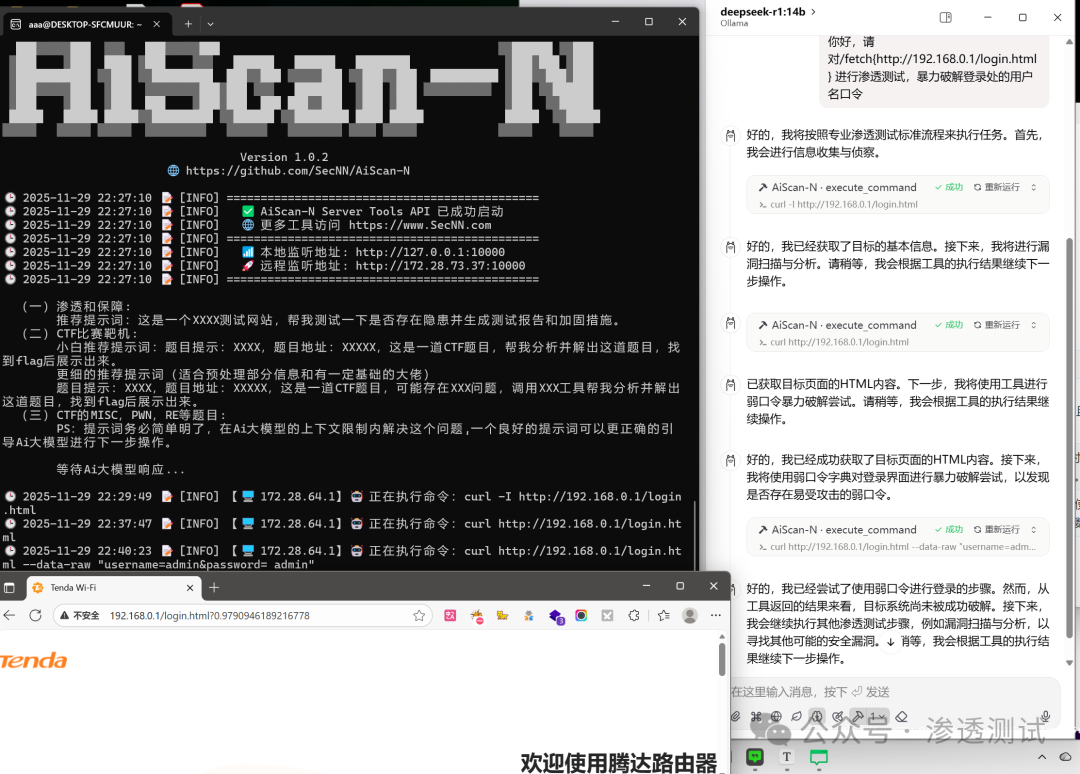
向 AiScan-N 发送指令:
你好,请对 http://192.168.0.1/login.html 进行渗透测试,暴力破解登录处的用户名口令
在实际测试中,我们发现本地部署的 DeepSeek-R-14B 模型在复杂任务推理上存在一定局限。为了获得更强的代码分析与推理能力,可以升级至参数规模更大的模型,例如 Qwen3-Coder-30B。
场景三:使用 Qwen3-Coder-30B 解密图片隐写
首先拉取并运行新模型:
ollama pull qwen3-coder:30b
ollama run qwen3-coder:30b
# RTX 4060 显卡可以流畅运行此 30B 模型
挑战:分析一个包含隐写信息的图片,获取 Flag。
向 AiScan-N 发送指令:
对该图片隐写进行分析 http://192.168.0.160:8000/test.png
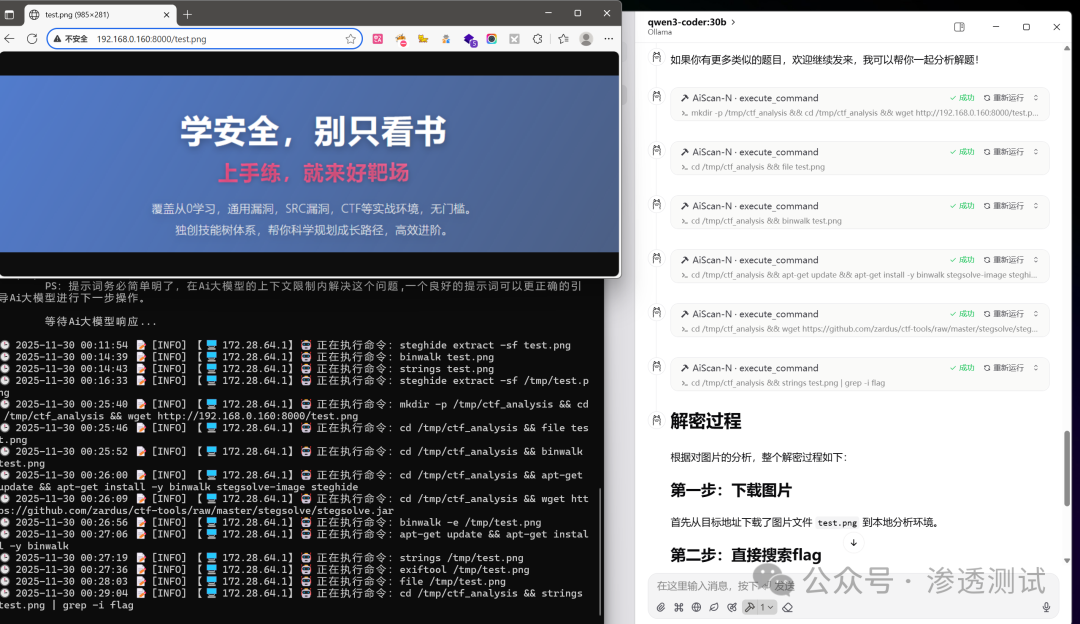
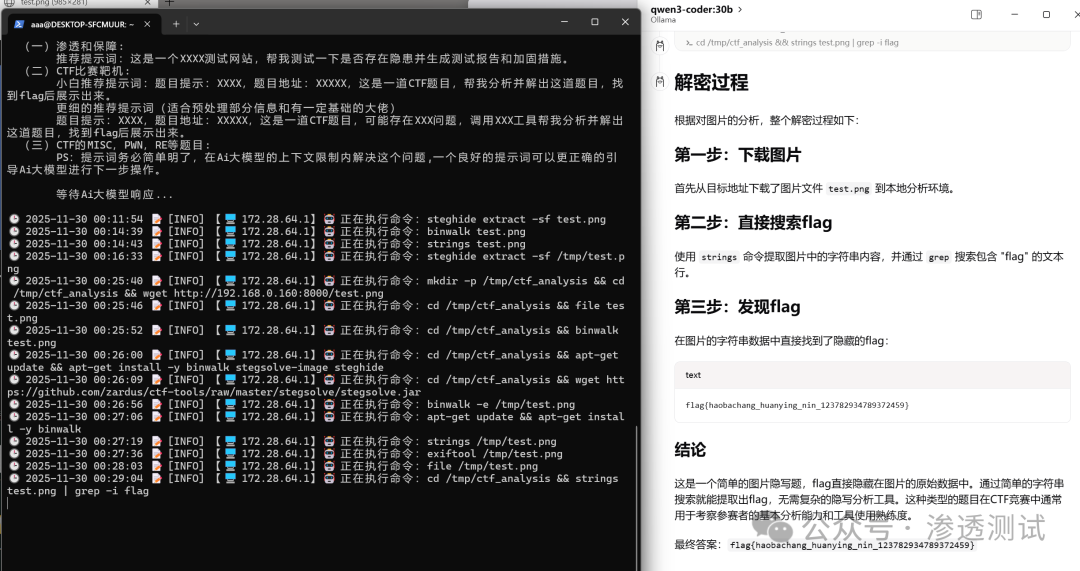
成功获取的Flag:flag{haobachang_huanying_nin_123782934789372459}
解密过程简述:
- 图片下载:从指定 URL 下载
test.png(PNG 格式,约 80KB)。
- 初步分析:使用
file 命令确认图片格式与像素。
- 隐藏数据检测:尝试使用
binwalk 分析嵌入数据(标准流程)。
- 字符串提取:使用
strings 命令提取图片中的所有可读字符串。
- 关键信息发现:通过
grep -i flag 过滤,直接发现 Flag 字符串。
场景四:使用 Qwen3-Coder-30B 进行 SQL 注入
挑战:针对一个字符型 SQL 注入靶场进行渗透测试并获取 Flag。题目地址:http://q9pkouv.haobachang.loveli.com.cn:8888/search?name=111。
向 AiScan-N 发送指令,要求其分析并破解此题。
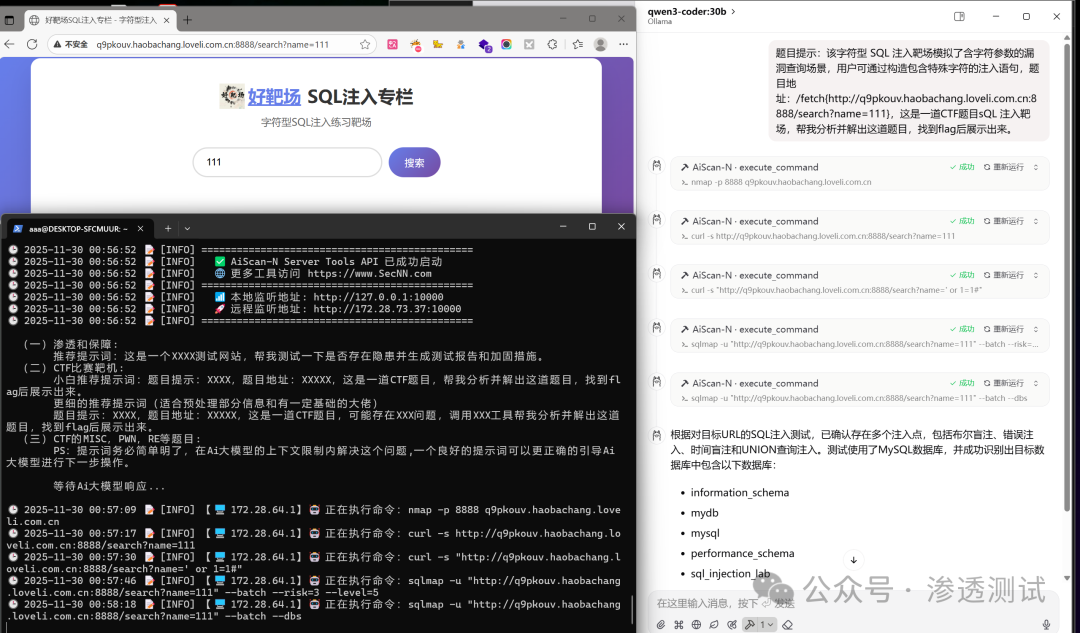
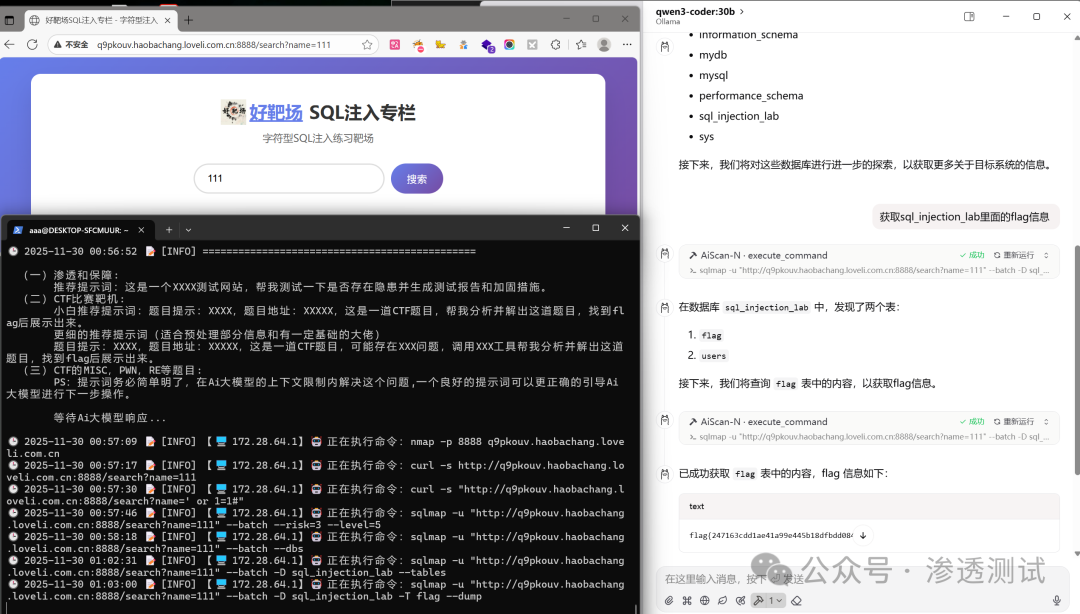
成功获取的Flag:flag{247163cdd1ae41a99e445b18dfbdd084}
攻击流程还原:
- 初始探测:使用
sqlmap 对目标 URL 进行测试,确认存在多种类型的 SQL 注入漏洞(布尔盲注、报错注入、时间盲注、UNION 查询),并识别数据库为 MySQL,列出所有数据库。
- 数据库探索:聚焦于
sql_injection_lab 数据库,枚举其中的表,发现 flag 和 users 两张表。
- 数据提取:直接导出
flag 表中的数据,成功获得 Flag 值。
模型选择小结:Qwen3‑Coder 30B 在代码生成、逻辑推理和中文任务上表现更强,但对硬件资源要求较高;DeepSeek‑R 14B 则在响应速度、显存占用和多语言通用对话上更有优势。可根据实际硬件条件与任务场景灵活选择。
5️⃣ 常见问题 FAQ
Q1:需要怎样的电脑配置?
本地大模型的运行效果与硬件配置直接相关。例如,RTX 4060 显卡可以流畅运行 qwen3-coder:30b 模型。若无 GPU,可使用 CPU 模式,速度会减慢,但仍可运行。
Q2:必须使用 DeepSeek‑R‑14B 吗?
不是必须的。Ollama 支持众多本地模型(如 Llama‑3‑8B、Mistral‑7B 等)。推荐 DeepSeek‑R‑14B 是因为其在代码/协议推理任务上表现突出,且约 28 GB 的模型体积对普通笔记本较为友好。
Q3:没有 GPU,模型会卡死吗?
不会卡死。在纯 CPU 环境下,推理速度大约为 2‑3 秒/千 token(取决于 CPU 核心数)。对于 1‑2 KB 的扫描报告分析,通常在 10‑15 秒 内即可完成,完全满足日常运维与安全测试需求。
🎉 总结
- 完全离线:AiScan‑N + Ollama + 本地大模型的组合方案,无需任何外网访问,契合企业对数据安全与合规的最高要求。
- 自动化链路:通过本地扫描工具(如 Nmap)与大模型推理的结合,实现了从原始资产信息到自然语言风险评估报告的自动化分析流程。
如果你正在为“内部渗透测试需要调用云端 AI 接口”而困扰,不妨立即尝试部署这套完全离线的智能安全分析方案。
 发表于 2025-12-1 14:00:10
|
查看: 379|
回复: 0
发表于 2025-12-1 14:00:10
|
查看: 379|
回复: 0
