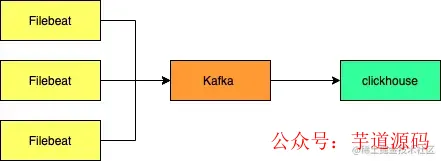
在大数据与运维监控领域,构建一个高效、稳定且低成本的日志处理系统是许多团队的目标。传统的 ELK Stack 方案虽然成熟,但在处理海量日志时,可能会面临写入吞吐瓶颈、查询延迟及较高的硬件资源消耗等问题。为了满足私有化部署与精细化运营分析的需求,我们探索了一套基于 ClickHouse、Kafka 和 FileBeat 的替代方案。本文将详细对比其与传统方案的优劣,进行成本分析,并提供从环境部署到问题排查的完整实践指南。
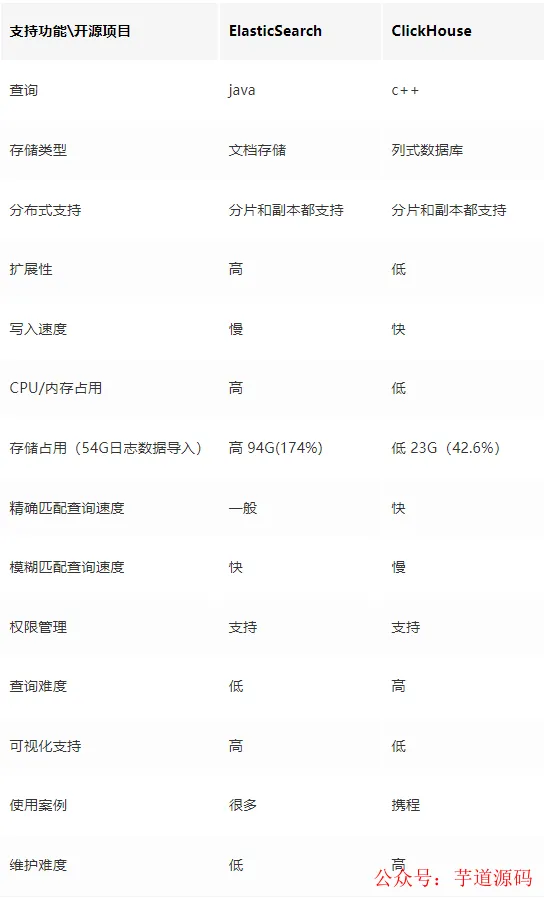
Elasticsearch vs ClickHouse
ClickHouse 是一款高性能的列式分布式数据库管理系统,在日志处理场景下,经过测试,我们发现其具备以下显著优势:
ClickHouse 写入吞吐量大
单服务器日志写入量可达 50MB 到 200MB/s,每秒写入记录数超过 60 万,是 Elasticsearch 的 5 倍以上。在 Elasticsearch 中常见的写请求被拒绝(Rejected)导致数据丢失、写入延迟等问题,在 ClickHouse 中不易发生。
查询速度快
官方宣称,当数据位于 PageCache 中时,单服务器的查询速率大约在 2-30GB/s。实际测试表明,ClickHouse 的查询速度比 Elasticsearch 快 5-30 倍以上。
ClickHouse 服务器成本更低
一方面,ClickHouse 拥有更高的数据压缩比。相同数据占用的磁盘空间通常只有 Elasticsearch 的 1/3 到 1/30,这不仅节省了存储成本,也有效降低了磁盘 IO 压力,这也是其查询效率高的原因之一。
另一方面,ClickHouse 在相同负载下比 Elasticsearch 占用更少的内存和 CPU 资源。我们预估,使用 ClickHouse 处理日志可以将服务器硬件成本降低近一半。
成本分析
在没有任何折扣的情况下,基于主流云服务商的配置进行成本估算,构建一套高可用的 ClickHouse + Kafka + FileBeat 日志系统,月度费用明细如下:

环境部署实战
接下来,我们详细介绍各组件的部署步骤与关键配置。
1、ZooKeeper 集群部署
ZooKeeper 是 Kafka 集群依赖的协调服务,需先行部署。

yum install java-1.8.0-openjdk-devel.x86_64
# /etc/profile 配置环境变量
# 更新系统时间
yum install ntpdate
ntpdate asia.pool.ntp.org
mkdir zookeeper
mkdir ./zookeeper/data
mkdir ./zookeeper/logs
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.7.1/apache-zookeeper-3.7.1-bin.tar.gz
tar -zvxf apache-zookeeper-3.7.1-bin.tar.gz -C /usr/zookeeper
export ZOOKEEPER_HOME=/usr/zookeeper/apache-zookeeper-3.7.1-bin
export PATH=$ZOOKEEPER_HOME/bin:$PATH
# 进入ZooKeeper配置目录
cd $ZOOKEEPER_HOME/conf
# 新建配置文件
vi zoo.cfg
# 配置文件内容示例
tickTime=2000
initLimit=10
syncLimit=5
dataDir=/usr/zookeeper/data
dataLogDir=/usr/zookeeper/logs
clientPort=2181
server.1=zk1:2888:3888
server.2=zk2:2888:3888
server.3=zk3:2888:3888
# 在每台服务器上执行,给zookeeper创建myid (ID分别为1,2,3)
echo "1" > /usr/zookeeper/data/myid
echo "2" > /usr/zookeeper/data/myid
echo "3" > /usr/zookeeper/data/myid
# 进入ZooKeeper bin目录并启动服务
cd $ZOOKEEPER_HOME/bin
sh zkServer.sh start
2、Kafka 集群部署
Kafka 作为消息队列,负责承接 FileBeat 收集的日志并缓冲分发给 ClickHouse。
mkdir -p /usr/kafka
chmod 777 -R /usr/kafka
wget --no-check-certificate https://mirrors.tuna.tsinghua.edu.cn/apache/kafka/3.2.0/kafka_2.12-3.2.0.tgz
tar -zvxf kafka_2.12-3.2.0.tgz -C /usr/kafka
# 编辑 server.properties 配置文件,关键参数如下(不同Broker需修改broker.id和listeners中的IP):
# broker.id=1
# listeners=PLAINTEXT://ip:9092
# socket.send.buffer.bytes=102400
# socket.receive.buffer.bytes=102400
# socket.request.max.bytes=104857600
# log.dir=/usr/kafka/logs
# num.partitions=5
# num.recovery.threads.per.data.dir=3
# offsets.topic.replication.factor=2
# transaction.state.log.replication.factor=3
# transaction.state.log.min.isr=3
# log.retention.hours=168
# log.segment.bytes=1073741824
# log.retention.check.interval.ms=300000
# zookeeper.connect=zk1:2181,zk2:2181,zk3:2181
# zookeeper.connection.timeout.ms=30000
# group.initial.rebalance.delay.ms=0
# 后台常驻进程启动kafka
nohup /usr/kafka/kafka_2.12-3.2.0/bin/kafka-server-start.sh /usr/kafka/kafka_2.12-3.2.0/config/server.properties >/usr/kafka/logs/kafka.log >&1 &
# 停止命令
# /usr/kafka/kafka_2.12-3.2.0/bin/kafka-server-stop.sh
# 创建Topic示例
$KAFKA_HOME/bin/kafka-topics.sh --create --bootstrap-server ip:9092 --replication-factor 2 --partitions 3 --topic xxx_data
3、FileBeat 部署与配置
FileBeat 负责从应用服务器收集日志文件并发送至 Kafka。
首先安装 FileBeat:
sudo rpm --import https://packages.elastic.co/GPG-KEY-elasticsearch
# 在/etc/yum.repos.d/ 目录下创建elastic.repo,内容如下:
[elastic-8.x]
name=Elastic repository for 8.x packages
baseurl=https://artifacts.elastic.co/packages/8.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
yum install filebeat
systemctl enable filebeat
chkconfig --add filebeat
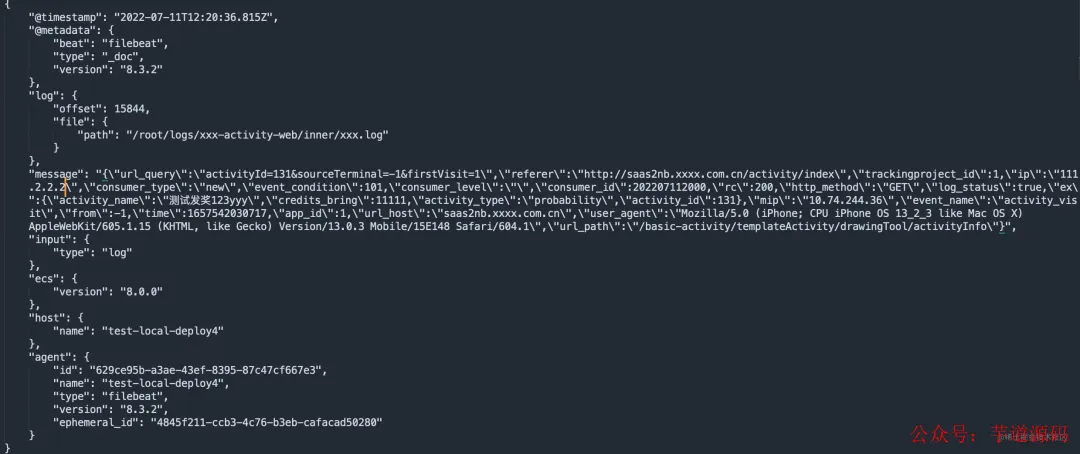
FileBeat 配置文件说明与关键坑点:
配置项 keys_under_root: true 至关重要。如果不设置,所有日志字段都会嵌套在 message 字段内,不利于后续解析;设置后,JSON 日志的字段会被平铺展开。
不设置时的 Kafka 消息字段结构(部分):
配置文件 /etc/filebeat/filebeat.yml 示例:
filebeat.inputs:
- type: log
enabled: true
paths:
- /root/logs/xxx/inner/*.log
json:
# 关键配置:使JSON日志字段平铺,而不是全部塞入message
keys_under_root: true
output.kafka:
hosts: ["kafka1:9092", "kafka2:9092", "kafka3:9092"]
topic: 'xxx_data_clickhouse'
partition.round_robin:
reachable_only: false
required_acks: 1
compression: gzip
processors:
# 剔除filebeat自动添加的无用字段,减少数据量
- drop_fields:
fields: ["input", "agent", "ecs", "log", "metadata", "timestamp"]
ignore_missing: false
# 启动命令(调试时可前台运行)
# nohup ./filebeat -e -c /etc/filebeat/filebeat.yml > /user/filebeat/filebeat.log &
4、ClickHouse 部署与集群配置
ClickHouse 是本方案的核心,负责最终的日志存储与高效查询。

基础部署步骤:
# 1. 检查CPU是否支持SSE 4.2指令集
grep -q sse4_2 /proc/cpuinfo && echo "SSE 4.2 supported" || echo "SSE 4.2 not supported"
# 2. 添加官方存储库并安装
yum install yum-utils
rpm --import <https://repo.clickhouse.tech/CLICKHOUSE-KEY.GPG>
yum-config-manager --add-repo <https://repo.clickhouse.tech/rpm/stable/x86_64>
yum list | grep clickhouse
yum -y install clickhouse-server clickhouse-client
# 3. 基础优化配置(可选但建议)
# CPU调频至性能模式
echo 'performance' | tee /sys/devices/system/cpu/cpu*/cpufreq/scaling_governor
# 禁用透明大页,避免性能下降
echo 'never' | tee /sys/kernel/mm/transparent_hugepage/enabled
# 4. 修改配置文件 /etc/clickhouse-server/config.xml
# 调整日志级别,默认trace太详细,可改为information
# <level>information</level>
# 5. 启动服务
sudo clickhouse start
# 查看版本
clickhouse-server --version
ClickHouse 集群配置与问题排查
部署多节点 ClickHouse 集群时,会遇到一些典型问题,以下是解决过程。
1)创建 Kafka 引擎表
此表用于从 Kafka Topic 中实时消费数据。
CREATE TABLE default.kafka_clickhouse_inner_log ON CLUSTER clickhouse_cluster (
log_uuid String ,
date_partition UInt32 ,
event_name String ,
activity_name String ,
activity_type String ,
activity_id UInt16
) ENGINE = Kafka SETTINGS
kafka_broker_list = 'kafka1:9092,kafka2:9092,kafka3:9092',
kafka_topic_list = 'data_clickhouse',
kafka_group_name = 'clickhouse_xxx',
kafka_format = 'JSONEachRow',
kafka_row_delimiter = '\n',
kafka_num_consumers = 1;
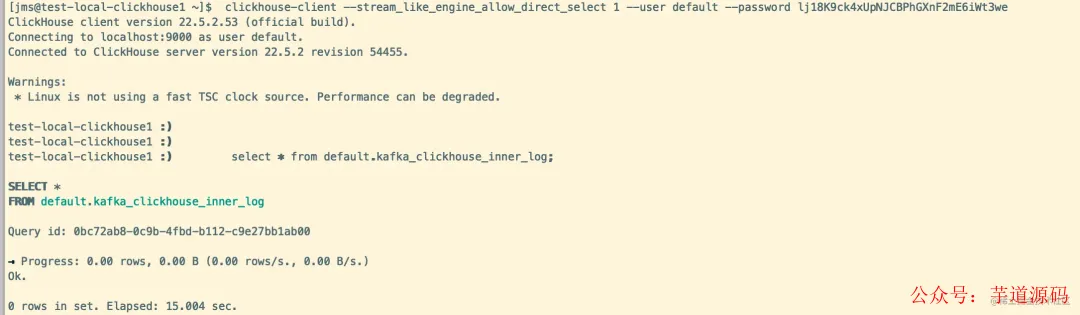
问题 1:ClickHouse 客户端无法直接查询 Kafka 引擎表
Direct select is not allowed. To enable use setting stream_like_engine_allow_direct_select.(QUERY_NOT_ALLOWED)

解决方案:
需要在连接客户端时添加特定设置。
clickhouse-client --stream_like_engine_allow_direct_select 1 --password xxxxx
2)创建本地复制表 (ReplicatedReplacingMergeTree)
create table default.bi_inner_log_local ON CLUSTER clickhouse_cluster (
log_uuid String ,
date_partition UInt32 ,
event_name String ,
activity_name String ,
credits_bring Int16 ,
activity_type String ,
activity_id UInt16
) ENGINE = ReplicatedReplacingMergeTree('/clickhouse/tables/default/bi_inner_log_local/{shard}', '{replica}')
PARTITION BY date_partition
ORDER BY (event_name,date_partition,log_uuid)
SETTINGS index_granularity = 8192;
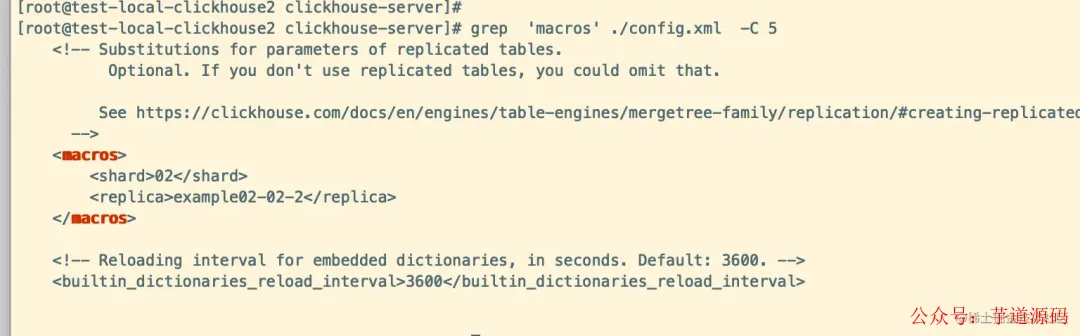
问题 2:创建表时报错 “No macro ‘shard’ in config”
这个错误是因为没有在 ClickHouse 节点的配置文件中定义分片(shard)和副本(replica)宏变量。
解决方案:
在每个 ClickHouse 节点的 /etc/clickhouse-server/config.xml 文件中,添加 <macros> 部分,且每个节点的值必须唯一。
例如,节点1配置:
<!-- Substitutions for parameters of replicated tables. -->
<macros>
<shard>01</shard>
<replica>example01-01-1</replica>
</macros>

节点2配置:
<macros>
<shard>02</shard>
<replica>example02-02-2</replica>
</macros>
问题 3:创建表时报错 “Replica ... already exists”
这意味着 Zookeeper 中已经存在该表路径的元数据,可能由于之前创建失败残留所致。
解决方案:
连接到 Zookeeper 客户端,删除对应的表元数据节点路径(例如 /clickhouse/tables/default/bi_inner_log_local),然后重新执行建表语句。
3)创建分布式表
分布式表本身不存储数据,而是将查询路由到集群各分片的本地表上。
CREATE TABLE default.bi_inner_log_all ON CLUSTER clickhouse_cluster AS default.bi_inner_log_local
ENGINE = Distributed(clickhouse_cluster, default, bi_inner_log_local, xxHash32(log_uuid));
问题 4:查询分布式表时报认证失败
Authentication failed: password is incorrect or there is no user with such name.
这是因为在集群配置 remote_servers 中,访问其他节点时使用的用户名密码不正确或未配置。
解决方案:
确保 /etc/clickhouse-server/config.xml 中 remote_servers 配置段内,每个 replica 的 user 和 password 与对端 ClickHouse 节点上配置的权限一致。
<!--分布式表配置-->
<remote_servers>
<clickhouse_cluster>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ip1</host>
<port>9000</port>
<user>default</user>
<password>xxxx</password>
</replica>
</shard>
<shard>
<internal_replication>true</internal_replication>
<replica>
<host>ip2</host>
<port>9000</port>
<user>default</user>
<password>xxxx</password>
</replica>
</shard>
</clickhouse_cluster>
</remote_servers>
4)创建物化视图完成数据同步
物化视图将 Kafka 引擎表的数据实时转换并插入到分布式表(最终落入各本地表)。
CREATE MATERIALIZED VIEW default.view_bi_inner_log ON CLUSTER clickhouse_cluster TO default.bi_inner_log_all AS
SELECT
log_uuid ,
date_partition ,
event_name ,
activity_name ,
credits_bring ,
activity_type ,
activity_id
FROM default.kafka_clickhouse_inner_log;
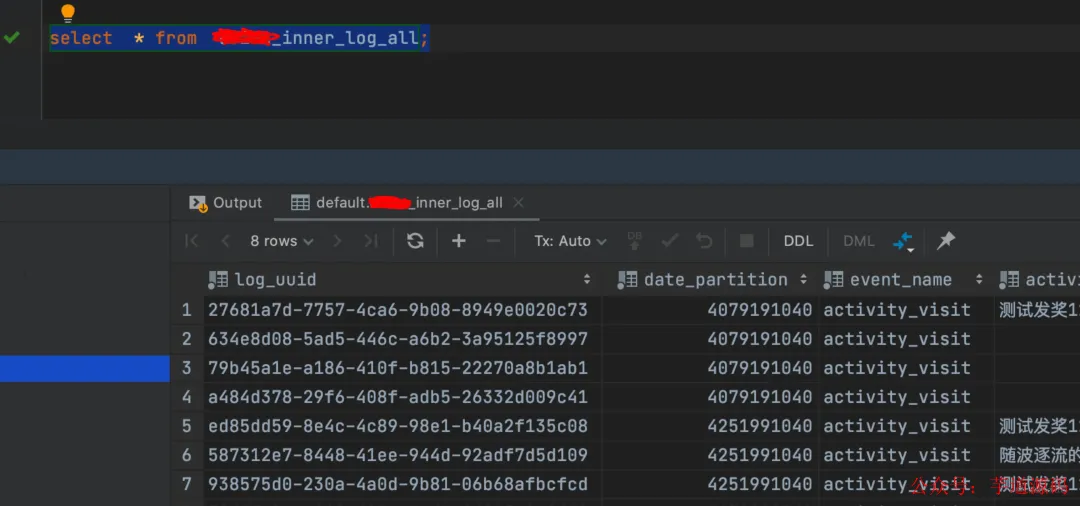
当以上所有步骤完成且问题解决后,数据链路便正式打通:FileBeat -> Kafka -> ClickHouse Kafka引擎表 -> 物化视图 -> 分布式表 -> 本地复制表。此时,可以在分布式表上查询到聚合后的日志数据。
总结
通过本文的实践,我们成功部署了一套以 ClickHouse 为核心的日志处理系统。相较于传统 ELK 方案,它在写入吞吐量、查询速度和硬件成本上展现出明显优势。整个部署过程涉及 ZooKeeper、Kafka、FileBeat 和 ClickHouse 集群的配置与联调,虽然步骤略显复杂,但遵循官方文档并耐心排查,总能找到解决方案。这套架构特别适合对日志查询性能要求高、且希望控制成本的中大规模应用场景。
技术的迭代日新月异,没有银弹。ELK 栈在全文搜索和生态成熟度上仍有不可替代的价值,而 ClickHouse 则在海量数据的实时分析领域锋芒毕露。如何选择,关键在于贴合自身的业务规模、技术栈和团队运维能力。希望这篇实战记录能为正在面临日志系统选型或优化难题的开发者提供有价值的参考。更多关于系统架构与运维部署的深入讨论,欢迎在云栈社区与大家交流分享。
 发表于 2026-1-24 11:49:01
|
查看: 205|
回复: 0
发表于 2026-1-24 11:49:01
|
查看: 205|
回复: 0
