在浏览GitHub时,一个词反复出现:Model1。没有发布会,没有海报,这个名字已经悄无声息地出现在了DeepSeek官方仓库的数百个文件中。这种感觉似曾相识,就像当年某款手机尚未发布,供应链已先行动。
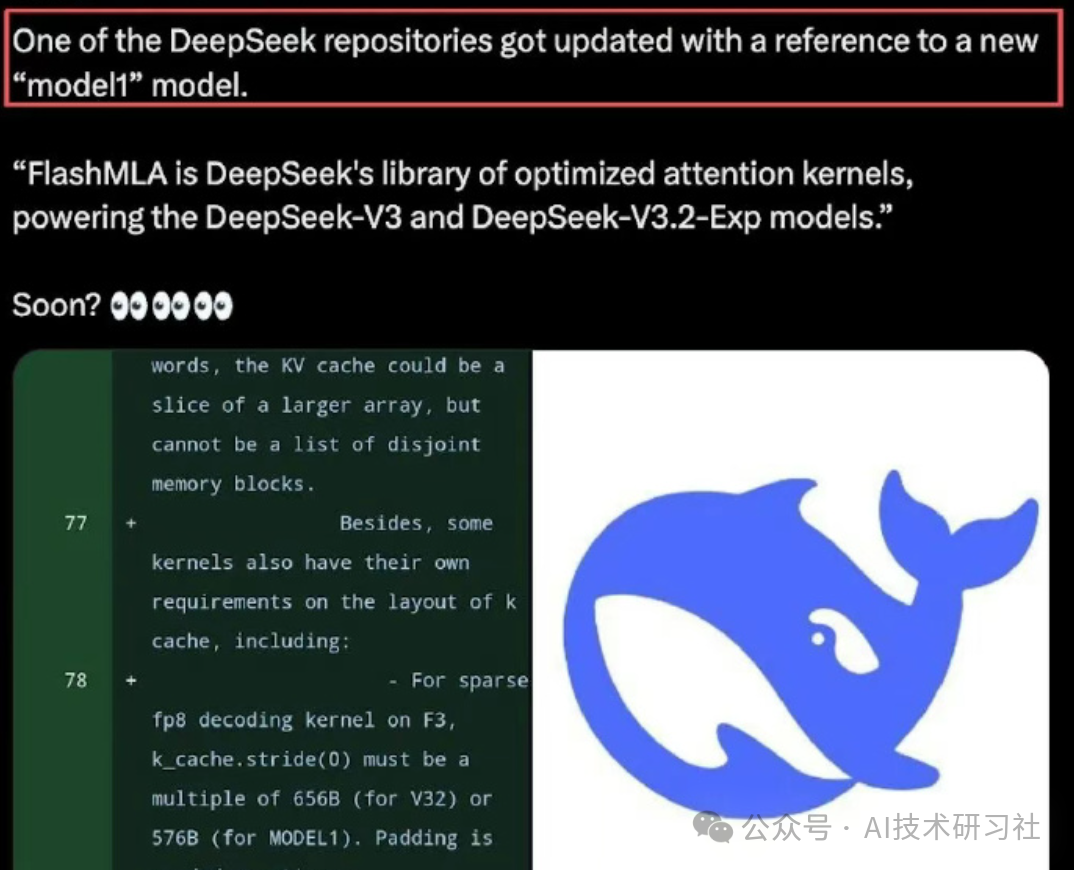
更值得关注的是,Model1并非仅存在于注释中,而是与V3.2并列,直接嵌入了推理内核、FlashMLA、attention kernel这些核心“脏活累活”的代码里。坦率地说,稍有工程经验的人都明白,这种底层代码的改动,绝非小修小补。
我的第一反应不是“V4要来了”,而是一个更意味深长的想法:DeepSeek开始动系统层了。如果这是真的,那么这次升级的意义,可能远超简单的“参数翻倍”。

许多人一看到V4传闻,条件反射般追问:多少参数?上下文多长?能否超越GPT?但我想先泼一盆冷水。真正让技术圈兴奋的,往往不是“更大”,而是“不一样”。
此次Model1暴露出的变化,聚焦于三个关键领域:KV Cache结构、attention kernel接口、推理流程适配。这些对普通用户而言几乎无感,但对模型本身而言,无异于更换了“发动机”。
一个或许不严谨但易于理解的比喻是:以往的模型升级,好比“同一辆车,加大排量、换更好的油”。而这次,则像是直接从燃油车,切换到了混合动力甚至纯电平台。
回顾DeepSeek近期接连发布的两篇论文:mHC 和 Engram。若只看标题,或许会觉得又是“新名词轰炸”。但深入阅读后,我发现他们正在试图解决一个古老却一直被回避的根本问题:模型是否应该同时承担“记忆一切”和“推理一切”的重任?
传统大模型的做法颇为简单粗暴:将所有任务全塞给Transformer。记忆、推理、上下文理解,全部混杂在一起。模型越大,越像一个既要背诵整部百科全书,又要现场解题的学生,难免手忙脚乱,效率低下。
Engram 这套机制,可以用一句大白话概括:将“记忆”与“思考”分离。
它不再要求模型每次都从上下文中费力“回想”事实,而是赋予模型一个条件记忆模块,就像一个随时待命的资料管理员。当遇到问题时,模型先从这个专门的记忆区调取事实,再返回推理区组织语言和逻辑。

举个例子。当你提问:“秦始皇是哪一年统一六国?”
- 传统模型:从输入的token中翻找历史信息 → 拼接时间线 → 组织语言回答。
- Engram思路:先查询专用记忆表 → 瞬间回复“公元前221年” → 再由推理模块补充背景细节。
速度快不快?回答稳不稳?答案显而易见。
这里有一句我个人认为极具价值的话:“AI不需要每次都重新变得聪明,它只需要别再假装自己什么都记得。” 这正是阅读Engram论文后最深刻的感受。对普通用户而言,这意味着长对话不易跑偏,知识型问答不再依赖“玄学发挥”,Agent 可以真正进行长期、连贯的工作,而非对话十轮后就“失忆”。
如果Model1真的将Engram理念融入核心架构,那么用户体验上的提升,可能会比单纯的参数增长更为显著。
再谈mHC。这个名字听起来很学术,但其工程实现却非常“朴素”。传统的深度网络中,信息传递路径是固定的,好比一条设有固定收费站的高速公路,旨在防止梯度爆炸等问题。mHC做了一件聪明事:将“固定收费站”替换为“动态匝道”。
在模型训练过程中,信息流动的路径不再是写死的,而是根据当前的状态动态调整。其结果就是:信息传递更顺畅,模型学习得更扎实,且更不容易过拟合。
读到这里,我突然意识到:DeepSeek的野心已不止于“训练出一个强大的模型”,而是在致力于构建“一个高效的推理系统”。
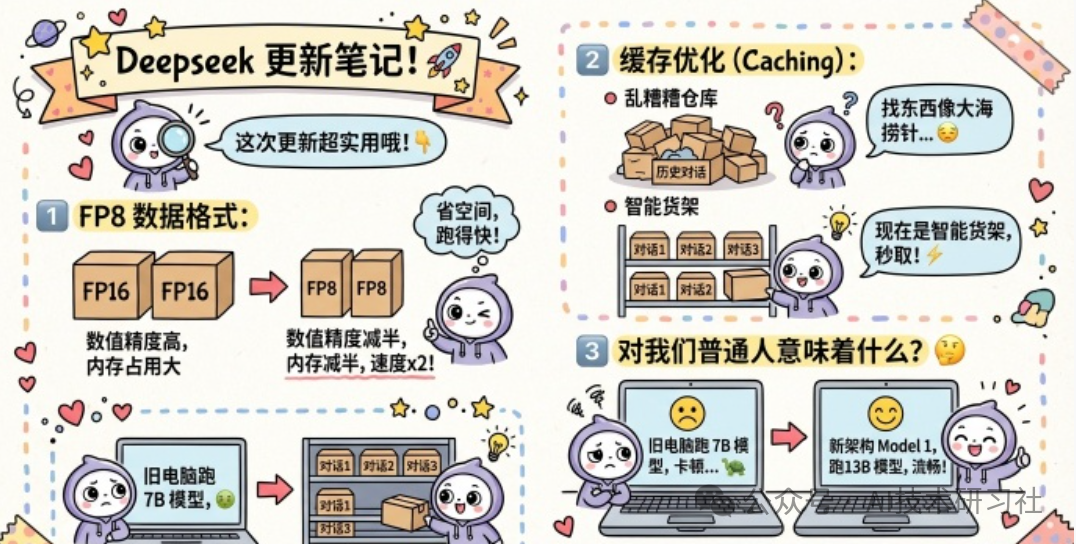
再看几个非常工程化、却极为现实的改进点:FP8数据格式与缓存结构重构。
FP8的本质可以概括为:精度减半,速度翻倍,显存占用减半。这对大厂是降低成本,对个人开发者则是“救命稻草”。
缓存优化则更为直接。以往处理长上下文对话,犹如在杂乱无章的仓库里大海捞针。现在的优化,更像是给每个常用物品贴上了RFID标签,随用随取,精准高效。
如果你是从事Agent开发、代码分析或长文档处理的开发者,这种提升带来的爽快感将是肉眼可见的。
说到这里,我必须插入一句个人主观判断:我不认为DeepSeek此次升级的主攻方向是“谁更聪明”。他们想赢得的,可能是一句更务实的宣言:“在同等硬件条件下,我能运行得更持久、更稳定、更经济。” 这远比在某个榜单上夺得第一名更有实际价值。
许多人会问:“DeepSeek缺乏语音功能,是否会一直停留在工具层面?”
客观地说,这个问题对了一半。语音确实是迈向“智能生活助理”的重要门票,但并非衡量“强大模型”的核心门槛。
就我个人而言,目前最频繁使用DeepSeek的场景是辅助写作、查询资料、阅读代码。在这些场景下,文字输入远比语音交互来得清晰高效。当然,我也承认,在辅导孩子作业、练习英语口语等场景,使用豆包、通义千问的语音模式体验确实很好。
那么,DeepSeek为何迟迟不推出语音功能?我猜测一个很“工程师”的答案:优先级。
语音是场景的扩展器,而强大的编程能力、逻辑推理能力和长上下文处理能力,才是其坚实的护城河。如果Model1真的在为其下一代AI系统“打地基”,那么语音这类“上层应用”,反而可以稍后布局。
这让我想起初学AI时的经历:贪多求全,反而难以深入。后来才明白,把核心能力做到极致,远比追求“功能齐全”更重要。
这里有一句值得分享的观点:“真正拉开差距的,不是功能的多寡,而是谁先把地基打对、打牢。”
对于开发者而言,Model1可能带来的实际变化,可以拆解为三步:
- 更敢用长上下文:无需再疯狂切分文本块,不再担心对话跑偏。
- Agent可以真正跑通流程:记忆不再完全依赖Prompt硬塞,拥有更稳定的“工作记忆”。
- 算力预算更可控:同样的显卡,能够处理更复杂的任务。
以下是一段简化的伪代码,用以示意Engram将记忆与推理分离后的工作形态:
# 查询阶段:从专用记忆模块检索事实
facts = engram.retrieve(query)
# 推理阶段:模型专注于“思考”与组织
response = model.reason(
query=query,
memory=facts,
context=conversation_state
)
return response
你会发现,模型不再试图扮演“万能工人”,而是成为了一个被合理分工的系统化推理节点。我的最后一个个人判断是:Model1或许并非DeepSeek下一代的“明星模型”,它更像是构建下一代AI推理系统的“核心基础构件”。
未来我们看到的竞争,可能不再是一个模型单打独斗的胜利,而是一个完整、高效、低成本的技术体系的胜利。比拼的不再是谁的参数更多,而是谁的体验更好、更实用。
写到这里,我内心既充满期待,也保持克制。期待的是,国内团队终于有人沉下心来认真打磨“推理系统”这件至关重要的事;克制的是,我们已厌倦了被华丽的PPT轰炸。真正的技术升级,其迹象应该首先出现在 GitHub 的commit记录里,而非发布会的舞台上。
最后,留一个开放性问题:你更期待DeepSeek下一步优先发展哪个方向?
A. 语音交互、多模态能力、情感陪伴
B. 更强的编程能力、更稳定的Agent、更低的推理成本
欢迎在云栈社区交流你的真实想法与专业见解。
 发表于 2026-1-25 04:14:25
|
查看: 160|
回复: 0
发表于 2026-1-25 04:14:25
|
查看: 160|
回复: 0
