近年来,混合专家(MoE)模型凭借其“参数量巨大但计算量稀疏”的特性,成为了扩展大型语言模型(LLM)的主流技术路径。然而,其“甜蜜的烦恼”也同样突出。
MoE 的“甜蜜烦恼”
| 优点 |
痛点 |
| 参数多、算力省 |
负载均衡难、训练不稳定 |
| 专家粒度越细,表达能力越强 |
通信碎片、延迟高、专家利用率低 |
| 前沿 LLM 标配 |
黑盒化,几乎不可解释 |
能否既享受稀疏参数红利,又避开动态路由的坑?

核心思路:把“矩阵乘法”变成“查表”
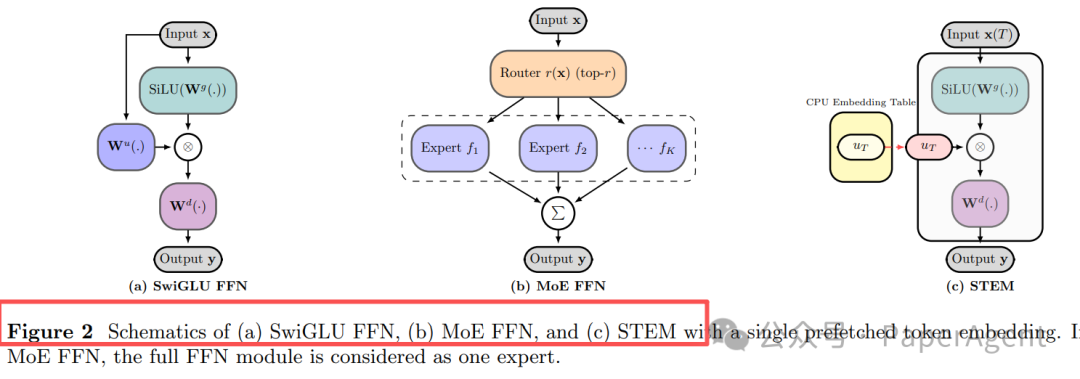
图 2:架构对比——(a) SwiGLU FFN, (b) MoE FFN, (c) STEM(单token嵌入预取)
STEM(Scaling Transformers with Embedding Modules)的核心在于:它只在每层FFN(前馈网络)的上投影(up-projection)部分进行改造,其余结构保持不变。
具体而言,它用一种“查表”操作替代了动态路由。以下是FFN层的公式变化:
| 原 FFN (SwiGLU) |
STEM 改造 |
SiLU(Wg·x) ⊙ (Wu·x) |
SiLU(Wg·x) ⊙ U[t] |
U[t] ∈ Rᵈ_ff:这是当前token t 在本层专属的静态行向量,存储在庞大的嵌入表(Embedding Table)中。- 无需路由、无all-to-all通信:选择哪个“专家”(即哪个嵌入向量)完全由token ID决定,是确定性的。
- 支持CPU离线存储与GPU异步预取:庞大的嵌入表可以存储在CPU内存,仅将当前batch需要的少数token嵌入预取到GPU,极大地节省了宝贵的GPU显存。
- 通信量仅与batch内唯一token数有关:与MoE模型通信量随专家数增长不同,STEM的通信开销只取决于当前序列中有多少不同的token,与“专家”(即词汇表大小)数量无关。
实验结果速览
Meta的研究表明,STEM模型在多项指标上表现优异:
| 规模 |
平均准确率↑ |
知识任务↑ |
长文本↑ |
算力↓ |
| 350 M |
+3.0 % |
ARC-C +9.4 % |
NIAH +8.4 % |
FLOPs –22 % |
| 1 B |
+3.4 % |
OpenBookQA +10 % |
32k 窗口 +13 % |
参数访问 –33 % |
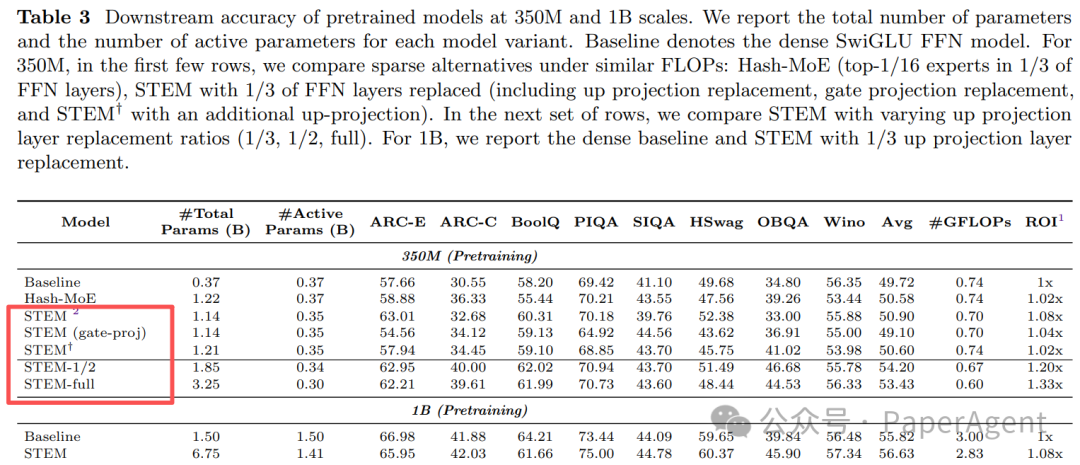
表 3:预训练模型在350M和1B规模下的下游任务准确率总表
四大核心优势
1. 训练稳定——告别 Loss Spike
动态路由的MoE模型常因专家负载剧烈波动导致训练损失出现尖峰(spike),而STEM的静态查表机制从根本上避免了这个问题。
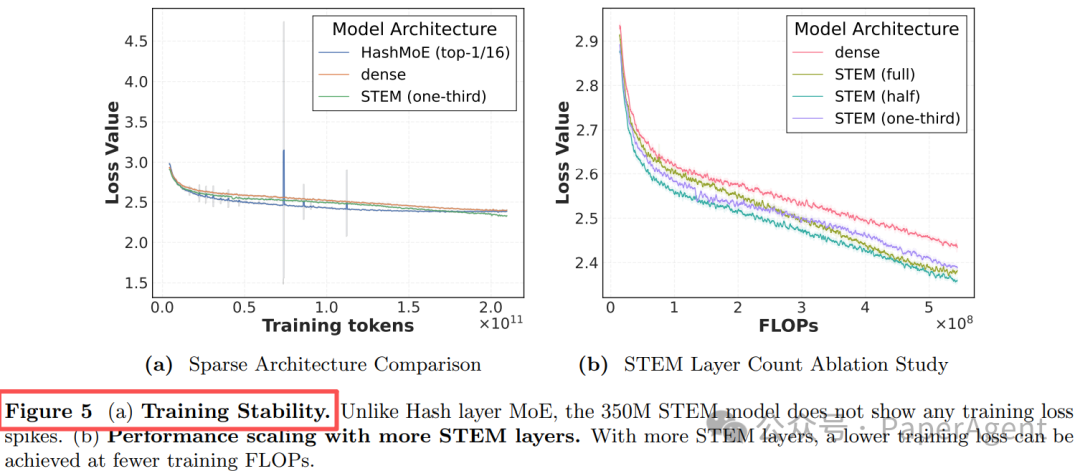
图 5 (a):训练稳定性对比。与Hash-MoE层不同,350M的STEM模型没有出现任何训练损失尖峰。
2. 知识容量大——嵌入空间“低耦合”
研究发现,STEM为不同token学习的嵌入向量之间的余弦相似度极低(峰值约0.03),远低于传统Dense FFN内部表示的相似度(约0.25)。这意味着不同概念的表示在向量空间中分得更开,有效降低了知识“串扰”,提升了模型的记忆容量。
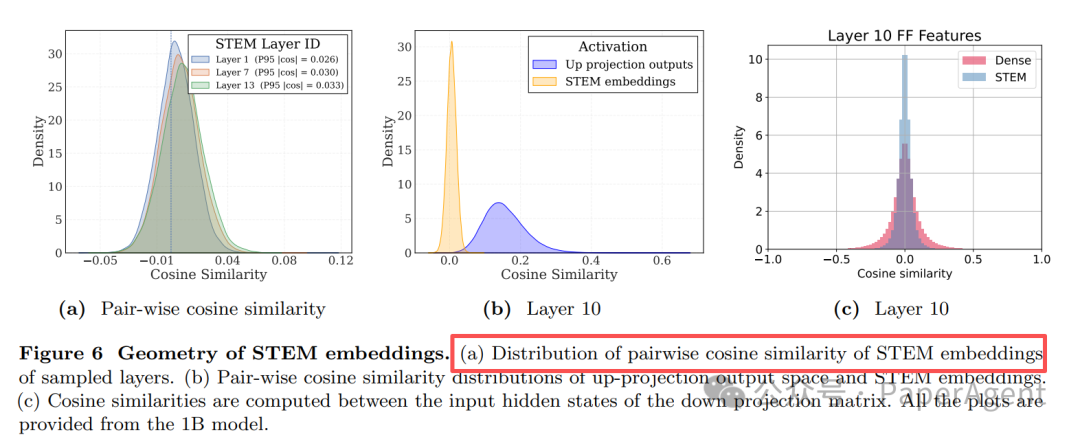
图 6:STEM嵌入的几何特性。(a) 采样层STEM嵌入的成对余弦相似度分布。
3. 可解释与可编辑——直接“换表”改事实
这是STEM最引人注目的特性之一。由于知识被明确地存储在与token ID绑定的嵌入表中,因此可以直接通过替换特定token(如“Spain”)在所有层的嵌入向量为另一个token(如“Germany”)的嵌入,来“编辑”模型的事实知识,而无需修改输入文本。
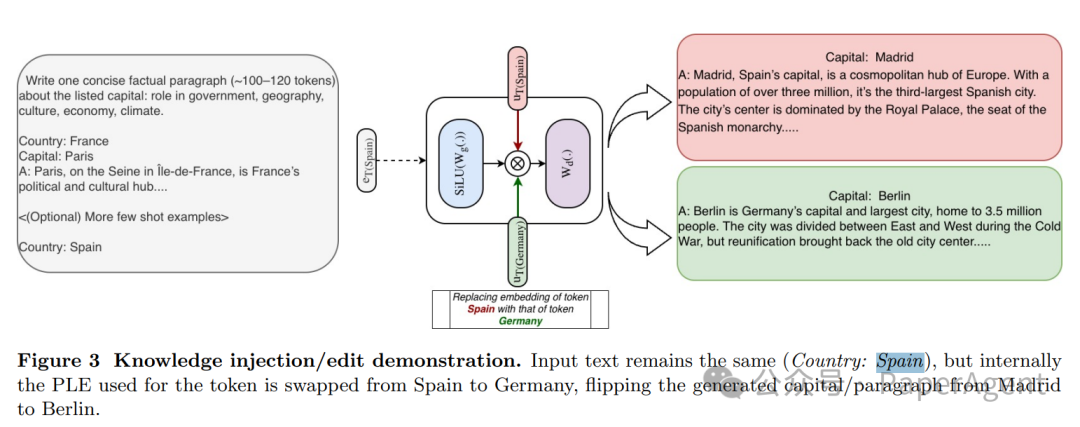
图 3:知识注入/编辑演示。输入文本保持不变(Country: Spain),但内部用于该token的PLE(可编程查找嵌入)被从Spain交换为Germany,从而将生成的段落从关于Madrid翻转为关于Berlin。
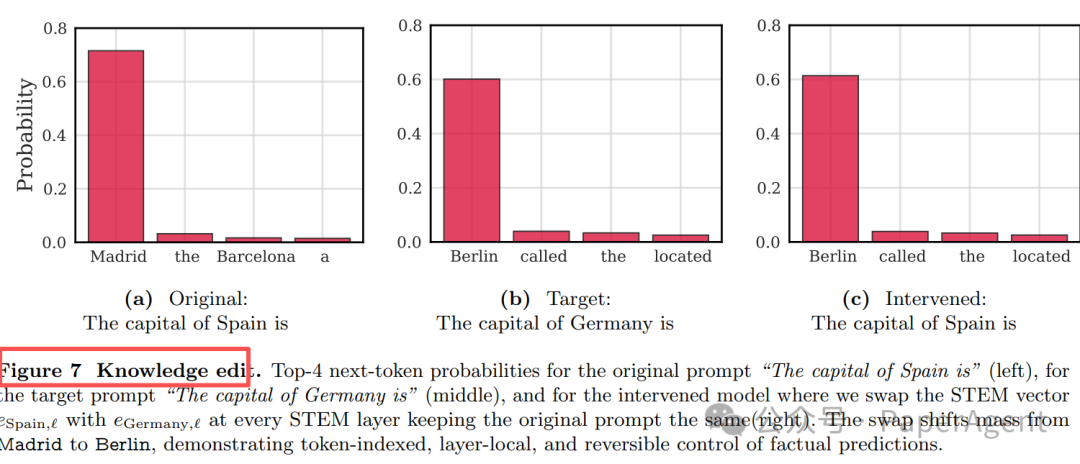
图 7:知识编辑。从左到右分别为原始提示、目标提示及干预模型的下一个token Top-4概率。交换嵌入向量将概率质量从Madrid转移到了Berlin,展示了对事实预测的token索引化、层局部化且可逆的控制。
4. 长文本处理能力随长度增强
在长序列中,激活的不同token嵌入数量自然增加,这意味着模型在长上下文场景下“动用”的有效参数量更大。实验证实,在“大海捞针”(Needle-in-a-Haystack, NIAH)测试中,随着上下文长度从8k增至32k,STEM相对于Dense模型的优势从8%扩大到了13%。
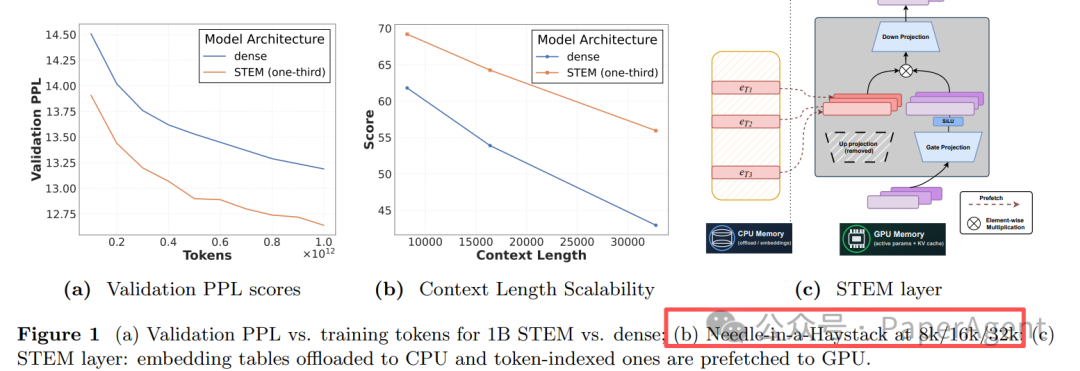
图 1: (a) 1B规模下STEM与Dense模型的验证PPL随训练token数变化曲线;(b) 在8k/16k/32k上下文长度下的NIAH分数。
消融实验:关键设计选择
研究团队通过系统的消融实验,验证了STEM设计中的关键选择。
替换哪个部分?
实验表明,替换FFN中的“上投影”部分效果最佳,而替换“门控投影”部分会导致性能下降,这验证了“门控必须依赖于当前输入x”的直觉。
| 替换位置 |
平均得分 (350M) |
| 上投影 (STEM) |
50.60 |
| 门控投影 |
49.10 ↓ |
| 上投影 + 附加表 (STEM†) |
50.58 ≈ |
替换多少层?
研究尝试了在不同比例的FFN层中应用STEM。结果显示,替换比例越高,在相同FLOPs下能达到更低的训练损失,并且投资回报率(ROI,即准确率/FLOPs)持续提升。
| 替换比例 |
平均准确率↑ |
ROI (准确率/FLOPs) |
| 1/3 层 |
+1.8 % |
1.08× |
| 1/2 层 |
+4.5 % |
1.20× |
| 全替换 |
+4.9 % |
1.33× |
系统级实现技巧
为了高效管理海量的嵌入表,STEM在系统工程上也做了精心设计:
- CPU-offload:将主要的嵌入表存储在主机内存中,GPU仅异步预取当前计算所需的少量嵌入。
- Token 去重:在一个batch内,只传输和获取唯一的token ID对应的嵌入,通信量可减少30-50%。
- LFU 缓存:利用自然语言中token出现的Zipf分布特性,采用最不经常使用缓存策略,可实现超过80%的命中率。
- 训练并行:嵌入表可以按照词汇表进行分片,这种数据并行方式与模型本身的张量并行(TP)/流水线并行(PP)策略解耦,简化了分布式训练。
总结
STEM模型用一种“最朴素的查表”机制,优雅地规避了“最花哨的动态路由”所带来的诸多难题。它证明了静态稀疏性与基于token的精准参数定位,同样能在扩展模型规模、提升知识容量的战场上取得卓越成效。更重要的是,它为AI模型的可解释性与可控性打开了一扇极具潜力的“后门”。对于希望深入理解大型Transformer模型内部机制的研究者和开发者而言,这项研究提供了宝贵的思路。
相关资源:
- 项目代码与论文:你可以在 GitHub 和 arXiv 上找到STEM的开源实现与详细技术文档。
- 论文标题:
STEM: Scaling Transformers with Embedding Modules
如果你对这类前沿的AI模型架构创新感兴趣,欢迎在云栈社区与我们一同探讨。
 发表于 2026-1-24 12:55:06
|
查看: 288|
回复: 0
发表于 2026-1-24 12:55:06
|
查看: 288|
回复: 0
