
LiveBeauty数据集样例
淘天音视频技术团队与上海交通大学合作的论文《FPEM: Face Prior Enhanced Facial Attractiveness Prediction for Live Videos with Face Retouching》,已被计算机视觉领域顶级会议 ICCV 2025(CCF A类顶会,录用率24.2%)成功收录。
论文背景与意义
ICCV是由IEEE/CVF主办的计算机视觉领域顶级学术会议,收录的论文代表了图像和视频领域的前沿技术与重大成果。ICCV 2025共收到创纪录的11,152篇有效投稿,最终录用2,702篇。
在淘宝直播生态中,每天有数十万的直播间存在美颜需求。人脸的吸引力已成为影响用户整体视觉体验的核心变量,通过实时监测确保美颜效果的稳定性,对保障主播和用户的双端体验至关重要。这甚至直接影响人均观看时长与商品交易总额(GMV)。因此,团队自研了针对直播美颜场景的人脸吸引力预测模型——FPEM,通过融合图像与文本模态,对人脸吸引力进行量化预测。
论文下载链接:https://openaccess.thecvf.com/content/ICCV2025/papers/Li_FPEM_Face_Prior_Enhanced_Facial_Attractiveness_Prediction_for_Live_Videos_ICCV_2025_paper.pdf
从“感知”到“量化”:LiveBeauty数据集
美能否被计算?淘天音视频技术团队给出了肯定答案。依托淘宝直播真实场景,团队发布了业界领先的大规模直播人脸吸引力数据集——LiveBeauty。该数据集包含10,000张精选图像,覆盖了不同的美颜算法参数、光照条件与面部表情,并通过专业主观标注获得了20万个主观分数标签,构建了业界代表性强的“直播审美坐标系”。
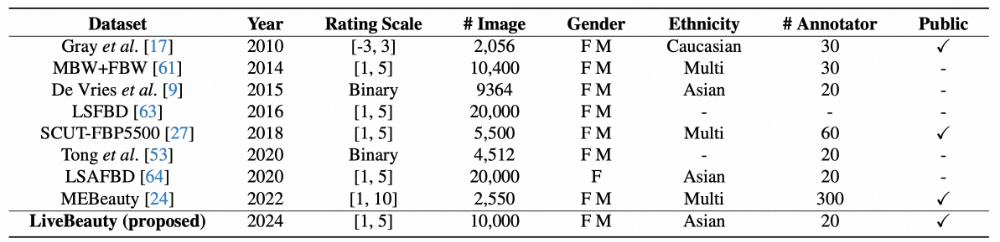
主流人脸吸引力预测数据集对比
为了准确刻画直播视频中人脸的吸引力分布,我们从淘宝直播平台选取了高页面浏览量的直播间回放,利用SOTA的人脸检测模型提取人脸区域。经过数据清洗(剔除动漫、虚拟头像及重复样本),最终从9500多个直播间采集了10,000张互不相同的人脸图像。
我们组织了20名专家组成的主观测评团队,对上述图像进行打分,生成200,000条标注数据。随后,根据ITU-R BT.500-13标准,将标注数据转换为平均意见分数(MOS),作为人脸吸引力的真实值(GT)。
技术突破:多模态人脸吸引力预测模型FPEM
基于此,团队推出了业界首个针对直播场景的人脸吸引力预测模型——FPEM。通过将视觉图像与文本语义深度融合,FPEM模型能够精准洞察复杂环境下的面部魅力值。
模型设计
FPEM模型采用两阶段训练策略,包含3个核心模块:PAPM模块、MAEM模块和SFM模块。模型使用图像和文本两种模态,有选择地融合人脸先验和美学语义信息来预测人脸吸引力。第一阶段,PAPM和MAEM模块独立训练;第二阶段,冻结二者参数,利用SFM模块动态整合二者提取的特征。
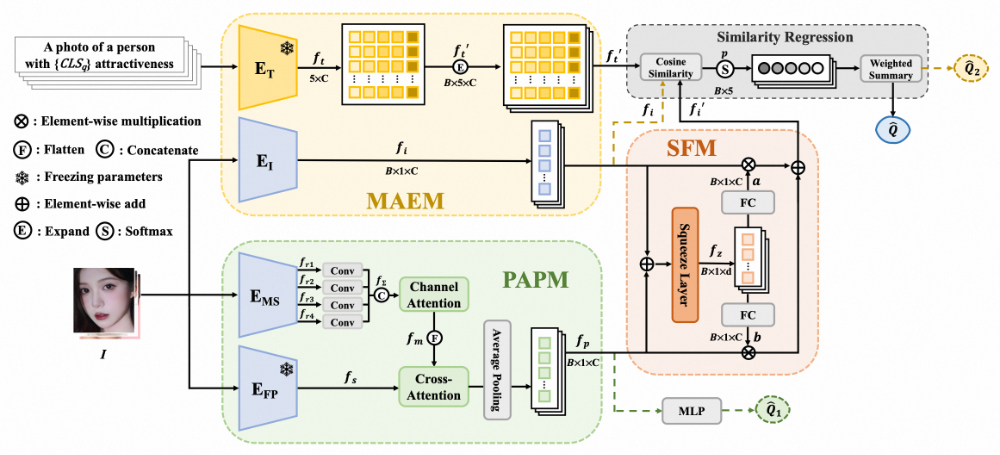
FPEM模型框架
-
PAPM模块
Personalized Attractiveness Prior Module包含两个视觉特征提取模块 E_MS 和 E_FP(FaceNet),分别提取多尺度视觉特征和全局人脸先验特征,随后通过一个交叉注意力模块融合后回归出预测分数 Q̂₁。此过程旨在整合低级视觉语义信息与百万级人脸图像训练得到的人脸先验信息。
-
MAEM模块
Multi-modal Attractiveness Encoder Module 基于 CLIP 模型架构,包含文本编码器 E_T 和图像编码器 E_I,用于提取多模态的美学语义信息。
在文本模态上,我们使用了5级吸引力标签:
α ∈ A = {1,2,3,4,5} = {“bad”, “poor”, “fair”, “good”, “perfect”}
随后使用文本模板:“a photo of a person with {α} attractiveness” 构造5个候选文本描述。在回归时使用Similarity Regression(SR)模块进行相似度回归,得到预测分数 Q̂₂。
-
SFM模块
Selective Fusion Model 通过一层Squeeze Layer压缩PAPM和MAEM提取的特征,并通过全连接层映射得到加权参数,在第二阶段自适应地融合二者表征的信息。回归时同样使用SR模块,得到最终的预测分数 Q̂。
损失函数
在MAEM的训练中,我们引入了两种损失函数:L1损失函数 L_s 和排序损失 L_R。排序损失又分为两部分:保真度损失 L_R1 和双向排序损失 L_R2。
对于保真度损失 L_R1,给定一组图像对 (I_i, I_j),根据其吸引力MOS真值 (Q_i, Q_j) 定义的二元标签如下:
R(I_i, I_j) = {1 if Q_i ≥ Q_j
0 otherwise.}
根据瑟斯顿模型,图像 I_i 被感知为比 I_j 更具吸引力的概率估计为:
Ř(I_i, I_j) = Ψ( (Q̂₂_i - Q̂₂_j) / √2 )
其中 Ψ(⋅) 表示标准正态分布的累积分布函数(CDF)。保真度损失计算如下:
ℒ_R1 = 1 - √(R(I_i, I_j) Ř(I_i, I_j)) - √((1 - R(I_i, I_j))(1 - Ř(I_i, I_j))).
对于双向排序损失 L_R2,给定图像 I_i,用 Ŝ_i,j 表示其与第j个吸引力等级之间的余弦相似度分数,并用 o 表示概率最高的吸引力等级。我们通过确保吸引力等级的概率分布呈单峰且向左右递减来获取排序信息。L_R2 定义如下:
{
L_left = -∑_{j=2}^{o} log( exp(Ŝ_i,j) / (exp(Ŝ_i,j) + exp(Ŝ_i,j-1)) )
L_right = -∑_{j=o}^{A-1} log( exp(Ŝ_i,j) / (exp(Ŝ_i,j) + exp(Ŝ_i,j+1)) )
L_R2 = (L_left + L_right),
}
实验论证与结果
我们在两个公开数据集(SCUT-FBP5500、MEBeauty)以及自建的LiveBeauty数据集上,与现有SOTA方法进行了对比。评估指标为Spearman等级相关系数(SROCC)、Pearson线性相关系数(PLCC)和Kendall等级相关系数(KROCC)。
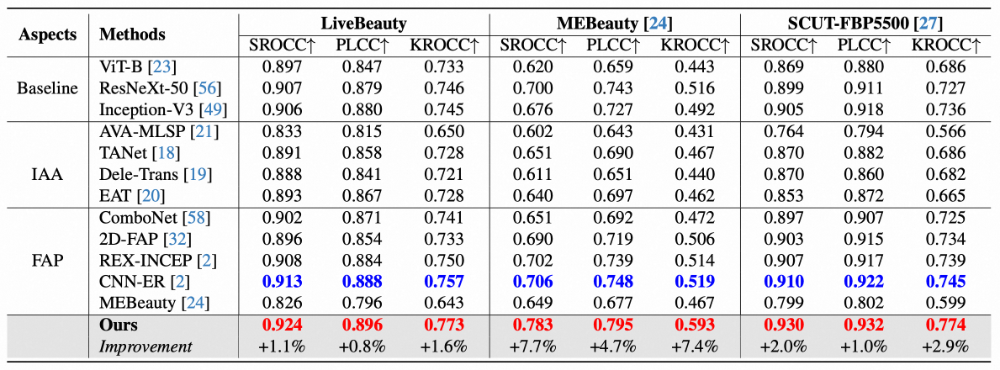
FPEM与其它SOTA模型性能比较
从结果可以看出,FPEM在三个数据集上的SROCC、PLCC和KROCC均超越了现有SOTA方法,达到了先进性能。
消融实验
为了探索不同模块的贡献,我们进行了消融实验。
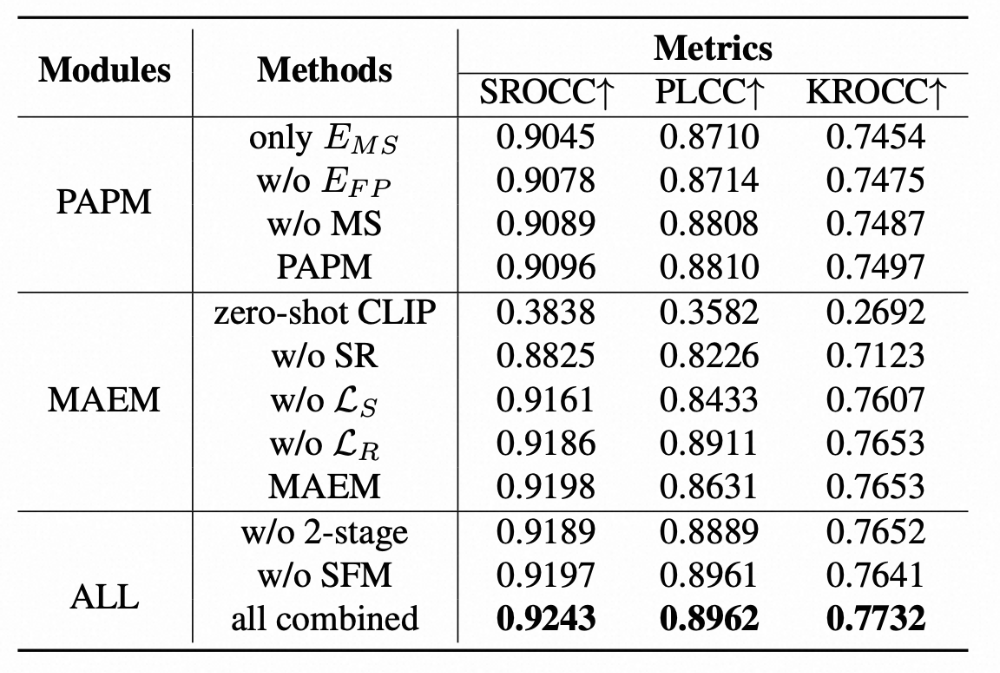
LiveBeauty测试集上各模块消融实验
从表中可以看出:
- 在PAPM中引入人脸先验(
E_FP)和多尺度特征(MS)均能提升性能。
- 在MAEM中,零样本CLIP在FAP任务上泛化能力有限,移除相似度回归(SR)策略后性能显著下降,表明专门设计的回归策略对CLIP适配回归任务至关重要。
- 排序损失与回归损失的联合优化进一步提升了SROCC指标。
- 使用两阶段训练和SFM模块取得了最佳性能,证明了SFM能够自适应地深度融合多模态美学特征与全局人脸先验知识。
此外,我们也测试了各模块对模型泛化性的贡献(在LiveBeauty上训练,在MEBeauty上测试)。结果表明,各个模块均对泛化性有贡献。指标整体偏低是由于数据分布和评分标准定义不同,影响了模型在不同数据集间的迁移能力。
总结与展望
我们构建了大规模人脸吸引力预测数据集LiveBeauty,这是首个包含直播场景美颜效果的人脸数据集。同时,我们提出了多模态框架FPEM,能够自适应地融合全局人脸先验与美学语义特征以量化人脸吸引力。大量实验表明,FPEM的表现优于目前最先进的方法。LiveBeauty数据集与FPEM框架亦可推广至其他视频应用场景中的人脸美感预测任务。
在直播生态中,美颜包含脸型、五官比例微调等复杂变换。LiveBeauty和FPEM为这一审美现象提供了新的研究视角。然而,美感预测本质上具有高度主观性。虽然模型在预测平均分上表现优异,但在不同文化背景、性别或族裔下的审美差异仍是该领域面临的深层挑战。这项研究也为计算机视觉和深度学习领域如何量化主观感知问题提供了有价值的探索。对于对算法、Transformer架构应用以及数据集构建感兴趣的朋友,欢迎到云栈社区交流讨论。
参考文献
- Lingyu Liang, Luojun Lin, Lianwen Jin, Duorui Xie, and Mengru Li. Scut-fbp5500: A diverse benchmark dataset for multi-paradigm facial beauty prediction. In Proceedings of the IEEE International Conference on Pattern Recognition, pages 1598–1603, 2018.
- Irina Lebedeva, Yi Guo, and Fangli Ying. Mebeauty: a multiethnic facial beauty dataset in-the-wild. Neural Computing and Applications, pages 1–15, 2022.
- Zhang Z, Wu W, Sun W, et al. MD-VQA: Multi-dimensional quality assessment for UGC live videos[C]In Proceedings of the IEEE International Conference on Pattern Recognition, pages 1746-1755, 2023.
- Shifeng Zhang, Xiangyu Zhu, Zhen Lei, Hailin Shi, Xiaobo Wang, and Stan Z Li. Faceboxes: A cpu real-time face detector with high accuracy. In Proceedings of the IEEE International Joint Conference on Biometrics, pages 1–9, 2017.
- RECOMMENDATION ITU-R BT. Methodology for the subjective assessment of the quality of television pictures. International Telecommunication Union, 2002.
- Florian Schroff, Dmitry Kalenichenko, and James Philbin. Facenet: A unified embedding for face recognition and clustering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, pages 815–823, 2015.
 发表于 2026-1-25 05:32:55
|
查看: 212|
回复: 0
发表于 2026-1-25 05:32:55
|
查看: 212|
回复: 0
