前段时间大家都在讨论“Vibe Coding”,但作为技术人,我们不仅要懂“氛围”,更要懂“原理”。Anthropic官方为Claude打造的Excel Skill,就是一个绝佳的学习范本。它不仅仅是一段代码,更展示了大模型如何与实体文件进行高质量交互。
很多人以为给AI加功能就是写个Function Call,但看完这份官方源码你会发现——原来高手是这么“教”AI玩转Excel的。这个Skill把“如何写一个好的Claude Skill”的套路暴露得一清二楚:整个项目没有花哨的框架,核心就是一份结构清晰的说明文档加上少量配套脚本,便优雅地解决了复杂的Excel处理场景。
下面,我们将通过五大核心要点,深度剖析这份官方源码的设计智慧。
源码核心要点
01、在 SKILL.md 中描述“行为规约层”:零公式错误的铁律
源码(节选):
### Zero Formula Errors
- Every Excel model MUST be delivered with ZERO formula errors (#REF!, #DIV/0!, #VALUE!, #N/A, #NAME?)
### Formula Construction Rules
#### Assumptions Placement
- Place ALL assumptions in separate assumption cells
- Use cell references instead of hardcoded values in formulas
- Example: Use =B5*(1+$B$6) instead of =B5*1.05
#### Formula Error Prevention
- Verify all cell references are correct
- Check for off-by-one errors in ranges
- Ensure consistent formulas across all projection periods
- Test with edge cases (zero values, negative numbers)
- Verify no unintended circular references
### Formula Verification Checklist
- **Test 2-3 sample references**: Verify they pull correct values before building full model
- **Row offset**: Excel rows are 1-indexed (DataFrame row 5 = Excel row 6)
- **Division by zero**: Check denominators before using `/` in formulas (#DIV/0!)
- **Cross-sheet references**: Use correct format (Sheet1!A1) for linking sheets
解读:
这段看似只是“写文档”,本质上是在给Claude注入一层领域特定的行为规范(DSL):
- 把“零公式错误”设为铁律,模型在生成方案和代码时会自动偏向更保守、审慎的写法。
- 将“假设分离”、“禁止硬编码”这类Excel最佳实践,用具象化的检查清单形式列出,等于告诉模型:你不仅要算对,还要“会建模”。
- 把常见坑点(如行列偏移、交叉表引用)显式写出来,就是在给模型“注入经验”,减少LLM最容易犯的那些低级失误。
启示:
- 下次自己写Claude Skill时,可以借鉴这个套路:不要只描述“这是什么能力”,更要定义“什么是错误的行为”(例如:禁止硬编码、禁止修改既有模板格式)。
- 用检查清单的形式,把“容易出错的细节”列清楚——模型真的会依据这份清单进行思考和自我检查。
- 将“业务经验”转化为显式的规则文本写进SKILL.md,而不是心里默念“希望模型能懂”。
换句话说:好的Skill,关键不在于代码有多长,而在于能否将“人类专家的职业习惯”编写成一份可执行的行为约束。
02、用反例教学:用错误代码“调教”模型
源码(节选):
# ❌ WRONG - Hardcoding Calculated Values
# Bad: Calculating in Python and hardcoding result
total = df['Sales'].sum()
sheet['B10'] = total # Hardcodes 5000
# Bad: Computing growth rate in Python
growth = (df.iloc[-1]['Revenue'] - df.iloc[0]['Revenue']) / df.iloc[0]['Revenue']
sheet['C5'] = growth # Hardcodes 0.15
# ✅ CORRECT - Using Excel Formulas
# Good: Let Excel calculate the sum
sheet['B10'] = '=SUM(B2:B9)'
# Good: Growth rate as Excel formula
sheet['C5'] = '=(C4-C2)/C2'
解读:
这里的设计非常巧妙:
- 用“错误代码示例”塑造行为边界:它不是抽象地说“不要硬编码”,而是给出一整段标有
# Bad注释的错误写法,这对LLM来说是极强的负样本信号。
- 将“好代码”写成可复用的模板:“坏写法”是在Python里计算再写入结果值;“好写法”则把Excel视为计算引擎,Python只负责写入公式字符串。模型在后续类似场景中自然会复制这种模式。
启示:
撰写Skill时,不要吝啬提供“反例”:
- 针对你特别担心模型犯错的地方(例如:对金额字段滥用float精度、ID字段自动转型、HTML字符串拼接问题),最好写出“错误示范 + 正确示范”的对比代码。
- 给出典型的代码模式,而非仅仅讲述抽象原则。LLM对“模式”的敏感度远高于“抽象说教”。
- 可以为Claude的Skill预留一个专门章节,命名为“❌ 常见错误写法 / ✅ 推荐写法”,用这种方式将模型的输出风格“调教”至你期望的方向。
03、为了省Token的“探针”设计
我们通常编写Excel读取工具,会习惯性地使用read_excel全量读取。但官方Skill的设计却极其克制。
源码(节选):
# 这是一个 Tool 定义的抽象逻辑
def inspect_sheet_head(filepath, sheet_name, n_rows=5):
"""
Reads the first n_rows of the sheet to understand structure.
Crucial: Converts output to Markdown Table for LLM readability.
"""
df = pd.read_excel(filepath, sheet_name=sheet_name, nrows=n_rows)
# 重点:转化为 LLM 最容易理解的 Markdown 格式,且只给表头和前几行
return df.to_markdown(index=False)
解读:
这就好比相亲不会上来就查户口本(全量读取),而是先看看照片(预览头部)。此设计的精妙之处在于nrows=5和to_markdown()。
- Token经济学:一个10万行的Excel文件可能蕴含海量Token,直接读取必然导致上下文爆炸。只读取前5行,消耗极低,但足以让LLM理解列名和基本数据格式(例如,某一列是日期还是数字)。
- 格式对齐:LLM的训练数据中包含大量Markdown表格,使用
to_markdown输出,模型解析和理解的准确率远高于CSV或JSON等格式。
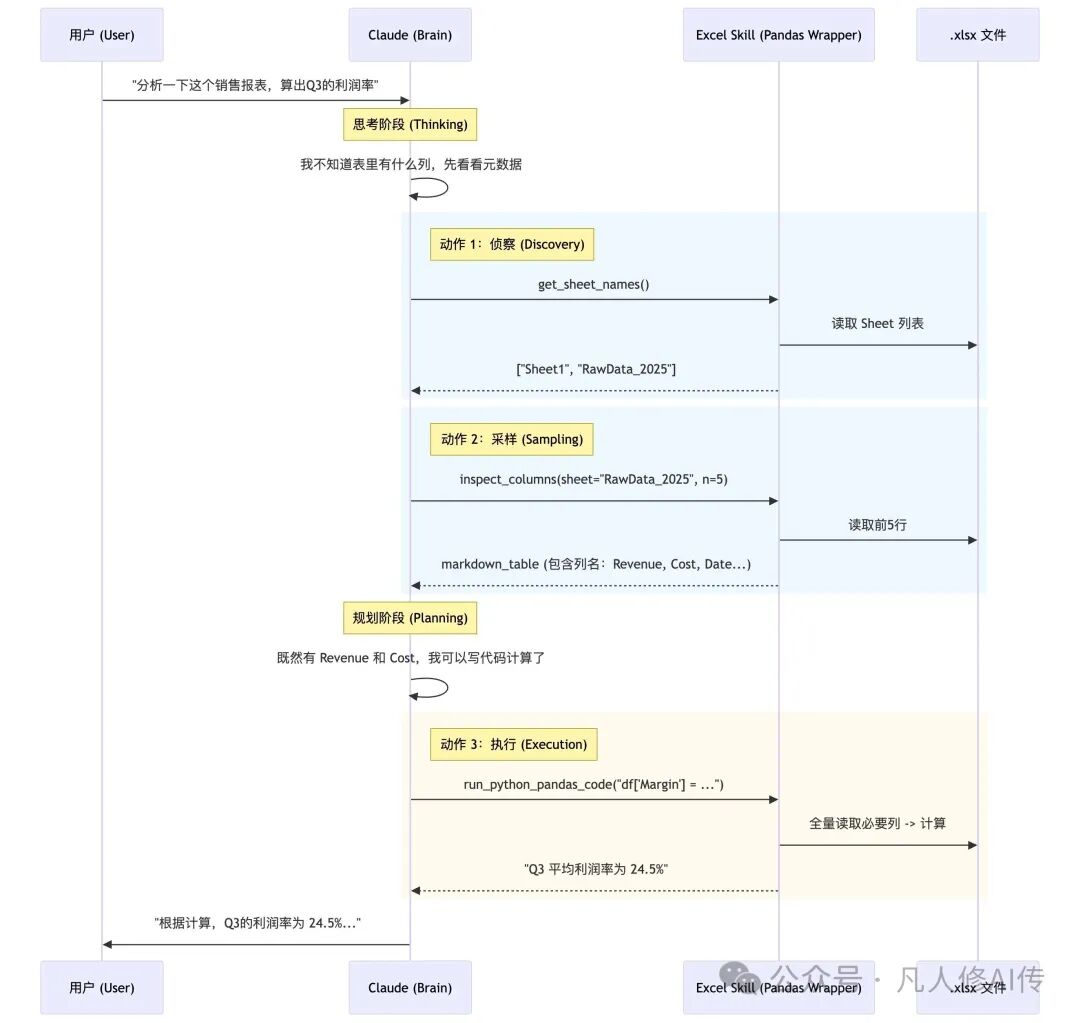
启示:
在进行RAG或文档分析任务时,应始终提供一个peek(预览)接口。让AI自主决定是否需要读取更多内容,而不是一次性“喂饱”它导致效率低下或出错。这种设计思路体现了优秀的Agent交互逻辑。
04、错误处理的“反弹机制”
虽然代码中通常包含Python的try-except,但此Skill的设计亮点在于如何将错误信息有效反馈给LLM。
源码(节选):
try:
result = exec(generated_pandas_code)
return result
except KeyError as e:
# 不只是返回 Error,而是返回“引导性”错误信息
return f"Error: Column {e} not found. Please check column names using `inspect_sheet` and retry."
except Exception as e:
return f"Execution failed: {str(e)}. Review your code logic."
解读:
普通程序报错是给程序员看的(堆栈跟踪),但Agent工具报错是给AI看的。这里的亮点在于:报错信息本身就是一条引导性的Prompt。当发生KeyError时,工具不仅报告“出错了”,更建议“请使用inspect_sheet检查列名后重试”。这赋予了LLM自我修复(Self-Healing) 的能力。
启示:
当你的Tool报错时,不要直接抛出原始异常堆栈。尝试将异常信息“翻译”成“下一步的行动建议”再返回给模型。让模型能够理解:“噢,我明白了,我应该换个方法再试一次。”
05、用 LibreOffice + recalc.py 做“结果兜底校验闭环”
调用示例:
python recalc.py output.xlsx 30
The script:
- Automatically sets up LibreOffice macro on first run
- Recalculates all formulas in all sheets
- Scans ALL cells for Excel errors (#REF!, #DIV/0!, etc.)
- Returns JSON with detailed error locations and counts
Example output:
{
"status": "success", // or "errors_found"
"total_errors": 0, // Total error count
"total_formulas": 42,
"error_summary": { // Only present if errors found
"#REF!": {
"count": 2,
"locations": [
"Sheet1!B5",
"Sheet1!C10"
]
}
}
}
解读:
这个设计将Skill从“写完即结束”提升到了“可验证的工程化流程”:
openpyxl等库写入的公式只是字符串,不会自动计算,必须借助Excel或LibreOffice引擎重新计算。recalc.py脚本实现了这个步骤的一键自动化。- 脚本不仅重算公式,还会遍历所有单元格,将
#REF!、#DIV/0!等错误收集成结构化的JSON,相当于生成了一份详细的“测试报告”。
- 在上层流程中,Claude可以:1. 按规范编写Excel;2. 运行
recalc.py;3. 读取JSON报告,如果status是"errors_found",则自动定位到对应单元格修复公式。
从Skill设计思路上看,这形成了一个经典模式:“LLM生成 → 外部工具验证 → LLM读取验证结果并自我修正”。而且返回的是结构化JSON而非日志字符串,这一点至关重要——模型可以像处理普通数据一样去解析、统计并生成修复代码。
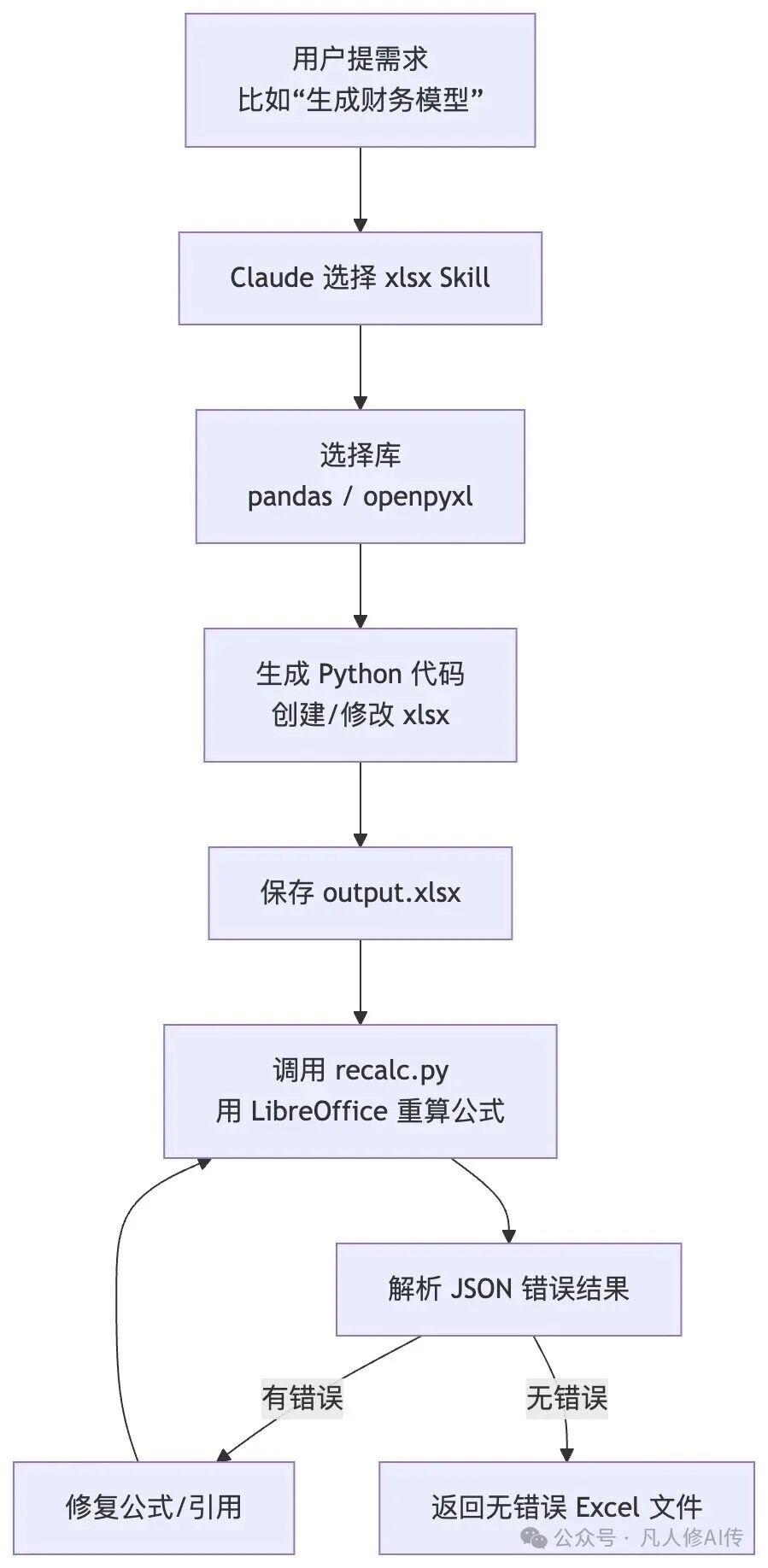
启示:
编写Claude Skill时,如果你的目标领域存在现成的“权威校验器”(如JSON Schema校验器、TypeScript编译器、SQL Linter、Markdown链接检查器),强烈建议将其集成进来。让Skill明确规定:“生成结果后必须运行校验工具;校验工具需输出结构化结果(JSON/YAML);出现错误时应按预定策略重试(例如,仅修改有问题的部分)。” Skill不仅要教“怎么写”,还要教“写完怎么验,验完怎么改”。
一句话概括:优秀的Skill,不只输出结果,还要自带CI/CD般的验证闭环。 这种对工程质量的追求,正是进行高质量源码分析时需要学习的精髓。
总结与思考
当然,这个xlsx Skill也有其局限性:
- 其逻辑主要依赖于详尽的说明文档和示例,没有复杂的代码抽象。真正的“智能”依然源于Claude本身,Skill更像一份“超长的System Prompt加工具调用协议”。
- 所有最佳实践都偏向“专业财务/建模”风格(如指定颜色编码、格式规则),可能不适合所有轻量级Excel应用场景,需要你在自定义Skill时做适当裁剪。
然而,作为编写Skill的模板,它传递了一个至关重要的理念:
一个好的Claude Skill,本质上是“将领域专家的职业习惯固化为行为规约,并利用外部工具对输出结果进行验证,直至完美”。
如果只用一句话收尾——
不要指望Claude天生就是专家,而是通过一份精良的SKILL.md,将它调教成你期望的那种专家。
希望这次对官方Excel Skill的拆解,能为你设计自己的AI应用技能带来启发。在云栈社区,你可以找到更多关于AI应用开发与最佳实践的深度讨论。
 发表于 2026-1-25 05:38:27
|
查看: 198|
回复: 0
发表于 2026-1-25 05:38:27
|
查看: 198|
回复: 0
