简介
QAnything 是一个面向文档问答与检索增强生成(RAG)的系统。本文从入口脚本 run.sh 出发,拆解启动分支与运行时各组件(etcd、minio、OCR、Embedding、Rerank、Milvus、qanything_local、MySQL)的职责、调用时机、排障与性能建议,方便开发与运维快速定位与优化。
运行入口与决策点(基于 run.sh)
- 检测
docker compose/docker-compose,选择 DOCKER_COMPOSE_CMD。
- 参数解析(影响运行时):
-c <local|cloud>:生成(LLM)使用本地还是云(OpenAI);cloud 模式下仍可保留本地 Embedding/Rerank。-i <device_id>:GPU id 列表,脚本据此计算 tensor_parallel 与 GPUID1/GPUID2 并写入 .env。-b <runtime_backend>:LLM 后端(default=FasterTransformer, hf=Hugging Face, vllm=vLLM)。-m, -t, -p, -r:模型名、对话模板、tensor parallel、vLLM 显存利用比例。
- 平台分支:WSL/Windows 使用 docker-compose-windows.yaml;Linux 使用 docker-compose-linux.yaml。脚本会创建 volumes、调整权限并执行
docker compose -f ... up -d,然后 tail qanything_local 日志。
架构简图(文本)
前端 ←→ qanything_server(API)
存储层:minio(对象存储)
配置/协调:etcd
预处理:OCR 服务(图像/PDF → 文本)
向量化:Embedding 服务(本地或云)
向量检索:Milvus(milvus-standalone-local)
精排:Rerank 服务(local rerank)
生成:qanything_local(或 cloud LLM)
关系:上传 → OCR → 切片 → Embedding → Milvus upsert / search → Rerank → LLM 生成 → 返回
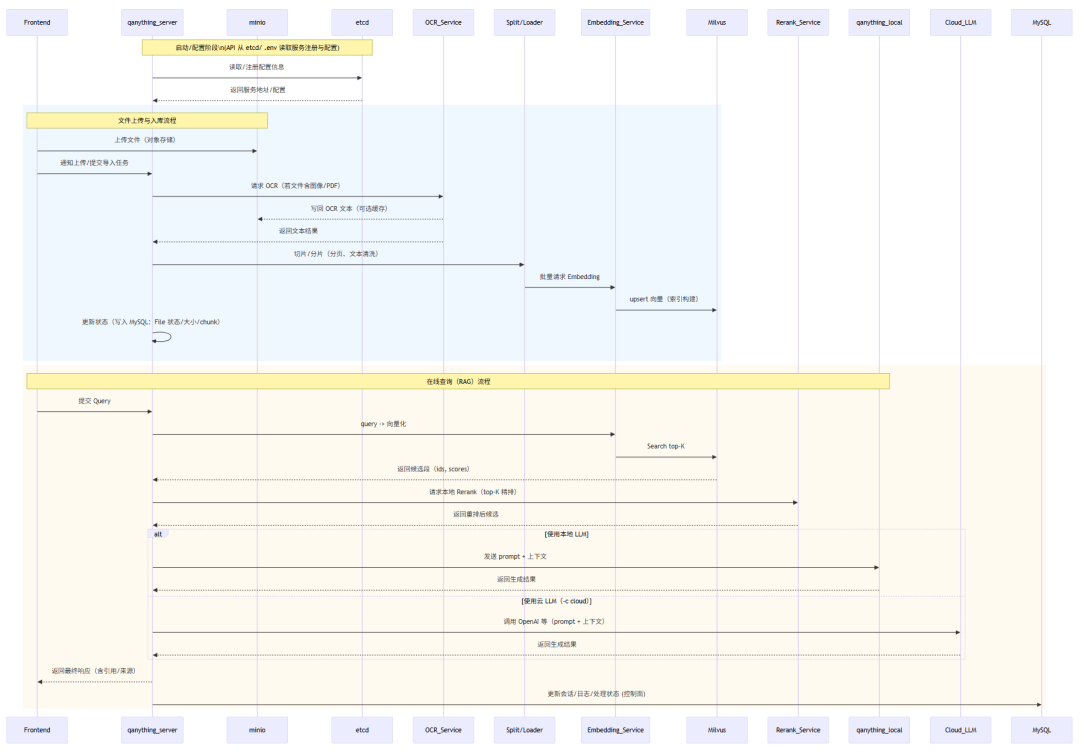
时序图
组件职责与调用时机
- etcd
- 职责:分布式配置、服务发现与协调(多实例/配置下发)。
- 调用时机:容器编排和服务启动时读取/写入配置与注册;运行时用于发现下游服务地址。
- 运维要点:监控成员、leader、网络分区;etcd 不可用会导致服务发现失败。
- minio
- 职责:S3 兼容对象存储,用于上传文件、OCR 中间产物、模型/索引快照、备份。
- 调用时机:用户上传、OCR 输出持久化、索引/会话备份。
- 要点:检查
.env 中凭证与桶策略;大文件用分片上传;关注磁盘 IO、网络带宽。
- OCR(dependent_server/ocr_serve)
- 职责:将图片/PDF → 可索引文本。
- 调用时机:上传包含图像/PDF 时的预处理阶段(
LocalDocQA.get_ocr_result 被调用)。
- 优化:异步化 OCR、结果缓存到 minio、对多页并行处理、预处理提升识别率。
- Embedding(connector/embedding)
- 职责:文本或段落 → 向量(语义表示)。
- 调用时机:文档入库(批量向量化并 upsert 到 Milvus)与在线查询(query → 向量)。
- 优化:合适
batch_size 控制显存;缓存热点 query embedding;保持向量归一化与一致维度。
- Rerank(dependent_server/rerank_for_local_serve)
- 职责:对 Milvus 返回的 top-K 用更精细模型重排序,提升精确率。
- 调用时机:向量检索后、送 LLM 之前(
LocalDocQA.rerank_documents_for_local)。
- 优化:只对 top-N(如 20)做 rerank;分层 rerank 策略;监控延迟并设置回退策略。
- Milvus / milvus-standalone-local
- 职责:向量持久化、索引构建与 ANN 检索(HNSW/IVF/PQ 等)。
- 调用时机:索引构建(upsert/flush/compact)与在线检索(search)。
- 优化:调优索引参数(metric_type、nlist、nprobe、ef_search、ef_construction);生产应考虑集群化与备份;本地 standalone 适合开发/单机环境。
- qanything_local(本地 LLM 服务)
- 职责:接收 prompt + 上下文并返回生成(可以是 FasterTransformer/vLLM/HF/FastChat)。
- 调用时机:检索 + rerank 后,用最终上下文调用 LLM(或在
-c cloud 情形下调用 OpenAI)。
- 要点:run.sh 决定
model_size、TP、后端;监控 OOM、生成延迟;高负载时可切换到 cloud 模型。
- MySQL(元数据存储)
- 职责:保存用户、KnowledgeBase、File 等元数据(状态、文件大小、chunk 数、时间戳)。
- 调用时机:系统初始化时由
KnowledgeBaseManager 连接并创建表(见 mysql_client.py);知识库/文件的增删改查、状态更新、处理进度都写入 MySQL。
- 要点:MySQL 是控制面(状态与进度),不存向量、不做检索/生成;常见错误包含数据卷冲突或容器无法启动(参见 FAQ_zh.md 中 MySQL 相关条目)。
端到端请求时序(精确步骤)
- 前端上传文件或提交 query(文件写入
minio 或直接到后端)。
- 预处理:若有图片/PDF → OCR 服务被触发(异步/同步视实现),结果写回或供后续步骤使用。
- 文本分片:loader 将文本切片为文档单元。
- Embedding:每个文档单元生成向量;批量 upsert 到 Milvus(或在线查询时生成 query 向量)。
- 检索:Milvus 执行 ANN 搜索,返回 top-K。
- Rerank:对 top-K 进行精排,筛选最终上下文。
- 生成:将 prompt + 上下文发至
qanything_local(或云 LLM)生成答案。
- 返回前端并根据策略持久化会话/索引/结果(minio/MySQL)。
故障排查与常用命令
- 查看
qanything_local 日志(tail):
docker compose -f docker-compose-linux.yaml logs -f qanything_local
- 查看 MySQL 日志与状态:
docker compose -f docker-compose-linux.yaml logs -f mysql
docker exec -it mysql-container-local mysql -uroot -p123456 -e "SHOW DATABASES;"
- Milvus 检查:
docker ps | grep milvus
docker compose -f docker-compose-linux.yaml logs -f milvus
- etcd 检查:
docker exec -it <etcd_container> etcdctl member list
docker exec -it <etcd_container> etcdctl endpoint status --write-out=table
- MinIO 检查(使用
mc):
mc alias set local http://minio:9000 MINIO_ACCESS_KEY MINIO_SECRET_KEY
mc ls local
性能与部署建议(工程级)
- 分层降低延迟:embedding & Milvus 做高频检索路径,rerank & LLM 做高成本精化。必要时只在 top-N 执行 rerank。
- 异步与缓存:OCR、embedding 结果应缓存(minio/DB),并尽可能异步执行以平滑峰值。
- Milvus 调优:根据召回与延迟目标调整
nlist/nprobe/ef;大规模索引在离线窗口构建并逐步合入。
- GPU 与模型选择:run.sh 的
model_size + device_id 决定显存与并行策略;vLLM 适高并发场景但需额外配置。
- 高可用:生产把 Milvus、MySQL、MinIO 做 HA/备份、etcd 做集群保证服务发现稳定。
常见故障与快速应对
- qanything_local OOM:降低模型(或使用
-c cloud 切换到云 LLM)、减少并行度、检查 GPUID 配置。
- MySQL 无法连接:检查容器是否起(
docker compose ps)、检查数据卷冲突(volumes)与 FAQ_zh.md 中常见解决办法。
- 检索质量差:排查 embedding 模型、向量规范、Milvus 索引参数、检索 top-K 与 rerank 策略。
- OCR 质量低或慢:改进图像预处理、换 OCR 模型、启用并行页级 OCR、缓存结果。
实用运维清单(上线前/排障快速核查)
.env 中关键项是否正确:LLM_API, GPUID1/2, MODEL_SIZE, OPENAI_API_*(若使用 cloud)。- 容器状态:
docker compose -f docker-compose-*.yaml ps,重点看 qanything_local、milvus、mysql、minio、etcd。
- 日志顺序排查:
qanything_local → rerank → embedding → milvus → minio → etcd → mysql。
- 在高负载时的临时降级策略:禁用 rerank → 降低 top-K → 切换到云 LLM(
run.sh -c cloud)。
结语
本文基于 run.sh 启动脚本与仓内模块位置,对 QAnything 的启动分支、组件职责与调用时序进行了系统化总结,并给出运维与性能优化建议。如果你对这个开源项目的更多实战细节或部署技巧感兴趣,欢迎到云栈社区进行交流探讨。 |  发表于 2026-1-26 01:43:55
|
查看: 182|
回复: 0
发表于 2026-1-26 01:43:55
|
查看: 182|
回复: 0
