2025年初,DeepSeek的走红让更多人明白,不仅仅是模型本身,训练和推理过程中工程上的优化同样重要。元旦假期看了朱亦博老师的一篇帖子,很受启发。2025年过去了,我尝试把亦博老师总结的这一年AI Infra的六个重点方向,用一些简单易懂的方式向大家介绍一下,希望能帮助更多同学快速了解AI基础设施领域的关键进展。如果你想深入探讨这些技术,欢迎到云栈社区交流。
一、分布式推理
在深入之前,我们先快速理解两个关键概念:
- 混合专家模型(MoE):由门控网络和若干个专家模型组成。门控网络负责针对具体问题选择合适的专家模型进行处理。得益于其稀疏激活特性,每次请求通常只激活少量专家,这大大提升了效率。
- 自回归仅解码架构(Decode-Only):基于前文逐步生成下一个词。其推理过程分为Prefill(预填充)和Decode(解码)两个阶段。Prefill阶段将输入计算为K、V缓存;Decode阶段则基于这些K、V缓存逐词生成输出。显然,这两个阶段对计算和内存资源的需求截然不同。
目前主流的“MoE模型 + Decoder-Only推理架构”正是基于上述特性,将不同阶段或模块解耦部署以提升效率,主要围绕以下三个方向展开。
1. PD分离的持续演进
最初,Decode-Only模型的Prefill和Decode阶段是混合部署的。在优化TTFT(首Token响应时间)和TPOT(后续Token平均生成时间)这两个核心指标时,遇到了两大难题:Prefill和Decode阶段的强相互干扰,以及资源分配与并行策略的紧密耦合。
(1)PD分离部署的提出
为了解决这两个阶段因资源需求不同导致的干扰和耦合问题,DistServe论文首次提出了PD分离的概念。
- Prefill阶段:将输入的prompt转换为Q、K、V并生成首个Token,同时将K、V缓存存储起来供后续Decode阶段使用。此阶段计算密集,核心优化目标是TTFT。
- Decode阶段:利用已生成的K、V缓存,自回归地逐个生成后续Token。此阶段访存密集,核心优化目标是TPOT。
下图直观展示了两个阶段的关系(思考一下:为什么只存储K、V缓存,而不存Q缓存?):
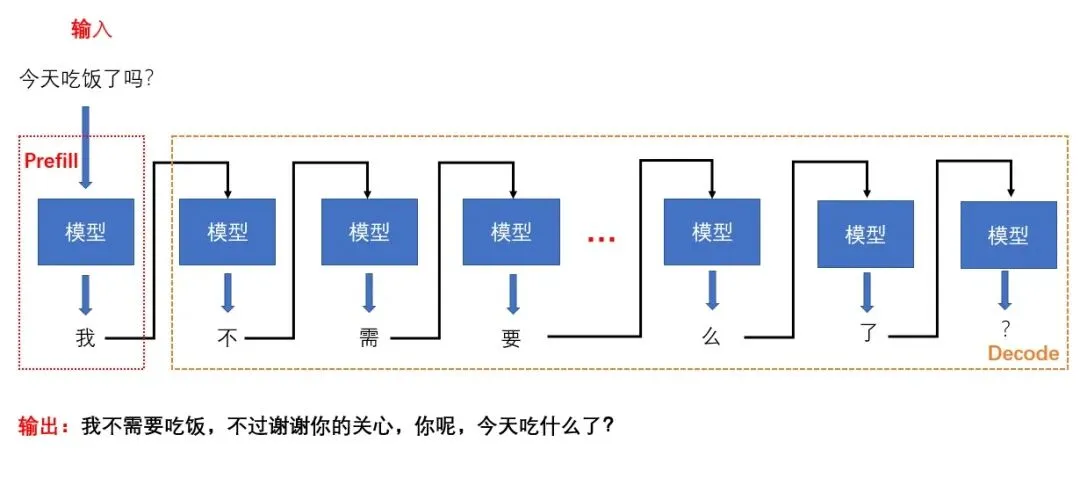
KV缓存的传输:在具备InfiniBand或RoCE网络的环境中,将P、D两个阶段部署在不同的设备或不同的GPU上,可以有效规避阶段间的干扰和策略耦合问题,为独立优化TTFT和TPOT创造了条件。下图展示了P、D分离部署的逻辑架构:
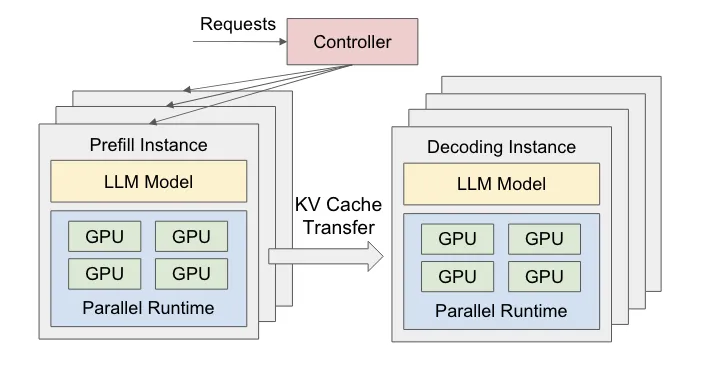
根据论文实验和大规模推理服务的实践,在相同资源下,PD分离模式确实能在满足相同TTFT和TPOT要求的前提下承载更多请求,或者为相同请求提供更优的时延体验。
(2)PD分离部署的进一步优化
PD分离虽然解决了阶段间干扰问题,但在工程实践中,特别是在处理长度各异的混合请求时,出现了新的挑战:Prefill实例生产KV缓存的速度与Decode实例消费的速度不匹配,导致资源利用率不均。DOPD论文为此提出了动态调整P、D实例配比的策略。
关键在于,推理过程中P、D实例的负载高度依赖于请求的长度。因此,一个优秀的动态PD分离系统应具备以下能力:
- 预测短期推理负载。
- 根据预测和当前负载,以极低开销计算出最优的P、D实例配比。
- 缓解高并发混合长度请求带来的干扰。
- 基于建议配比,实现P、D实例的自动扩缩容。
DOPD论文设计了一个动态最优PD分离调节系统,主要包括五个组件:资源监控器、请求路由器、KV通信连接器、P&D实例管理器和请求调度器。其系统架构如下:
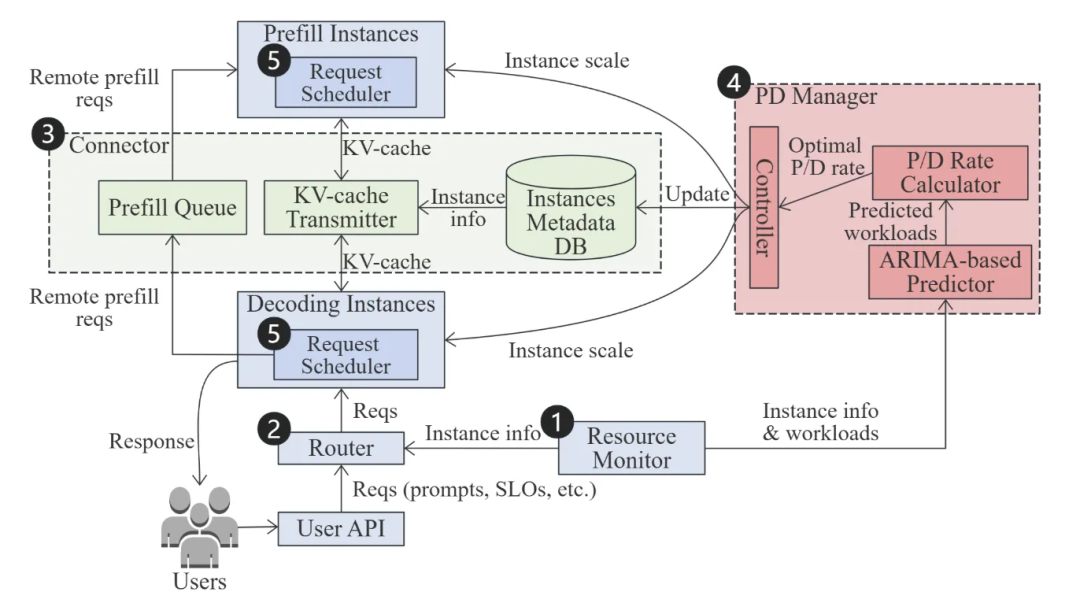
其工作原理简述为:资源管理器监控集群数据并提供给其他组件;P&D实例管理器实时调整实例数量和张量并行度(TP);请求路由器根据KV命中率和负载为请求选择目标D实例;KV通信连接器负责与远端P实例通信;在高并发场景下,请求调度器通过批处理来提升系统效率。实验表明,动态PD分离尤其适合负载波动大、请求长度混合的场景。
2. AFD的提出
既然Prefill和Decode阶段可以分离,那么单个阶段内部能否进一步优化?基于Attention的LLM模型通常由注意力模块和前馈网络模块组成。在Decode阶段,注意力模块参数量少但需要大量KV交互,是访存密集型的;而前馈网络模块参数量大,是计算密集型的。因此,Step-3模型论文提出了AFD架构,即在PD分离的基础上,进一步将注意力模块和前馈网络模块部署在不同设备上。下图展示了AFD的架构:
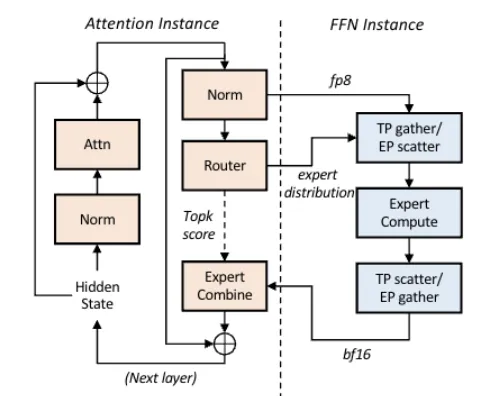
论文实验使用H20部署Attention实例,H800部署FFN实例。数据显示,AFD部署能有效提升推理效率并降低整体硬件成本,同时指出FFN部分具备使用国产化硬件的可行性,有助于打破对高端GPU的单一依赖。
3. 跨机EP的持续优化
我们知道MoE模型由大量专家组成,例如DeepSeek V3系列就有约1.4万个专家。将所有专家部署在单卡或单机上是不现实的,原因有三:
- 显存无法容纳过多参数。
- MoE的稀疏激活特性会导致大量算力闲置。
- 大规模模型对通信开销和扩展效率要求极高。
由于MoE的稀疏性,多机部署时GPU间通信(all-to-all)只需按需传输Token给被激活的专家。传统的NCCL库擅长密集通信,在这种稀疏场景下效率低下,会造成带宽浪费。
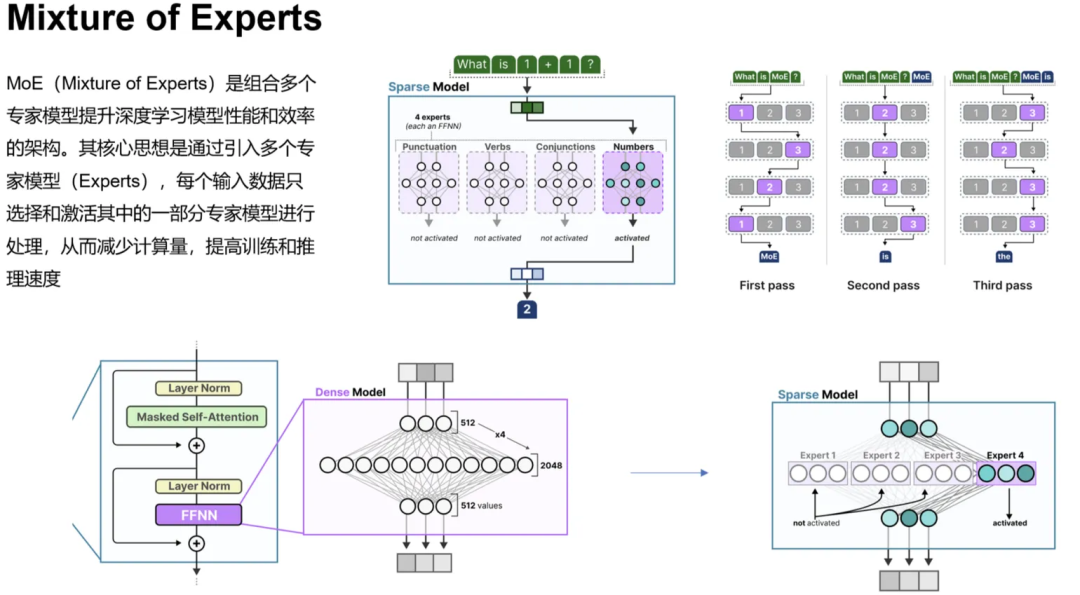
(1)DeepEP
这是由DeepSeek开发的开源项目,是专为MoE模型专家并行设计的通信库,其优势包括:
- 针对稀疏通信设计,大幅提升带宽和降低时延。
- 支持原生FP8精度通信。
- 具备NVlink-RDMA非对称带宽域的转发能力。
- 实现通信-计算重叠。
根据项目实测数据,在DeepSeek V3/R1等典型业务模型下,其跨机通信表现优异。
(2)TRMT
DeepEP在IB网络上表现出色,但在RoCE网络上效率不佳。腾讯网络平台部门在DeepEP基础上,结合TRMT技术进行优化,显著提升了其在RoCE网络下的效率。这些成果已开源并得到了DeepEP社区的官方致谢。
二、面向Tile的开发语言
高性能训练或推理中的内核与算子优化极为精细,需要精确调度线程、块、网格,并充分利用硬件的计算核心和缓存。传统方式依赖针对硬件特性的手工设计与复杂调优。那么,能否有一种开发语言,让开发者只需关注数据流,而将底层调度交给编译器呢?
TileLang
同名论文提出的TileLang语言,正是为了实现数据流与调度逻辑的彻底解耦。开发者专注于数据流,编译器负责生成最优调度策略,从而用简洁的代码表达复杂计算并获得高性能。论文中以矩阵乘法为例,仅用高级语法定义了矩阵、内存分配、流水线和算子调用,便实现了一个高效的GEMM运算:
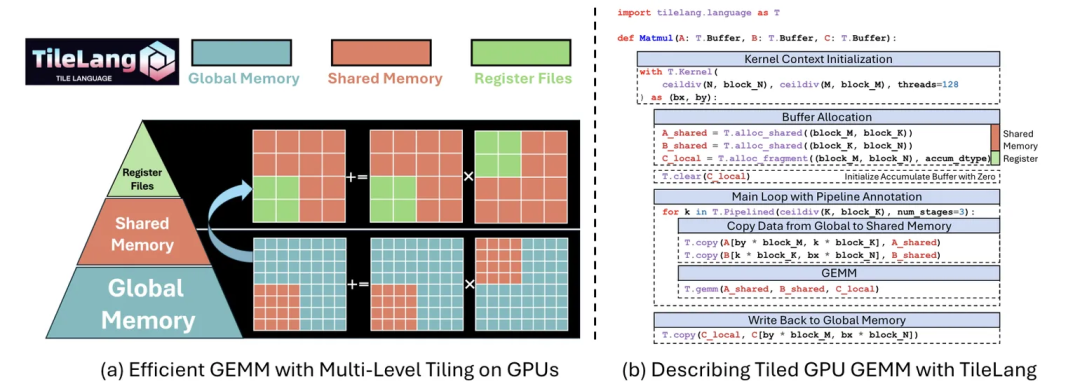
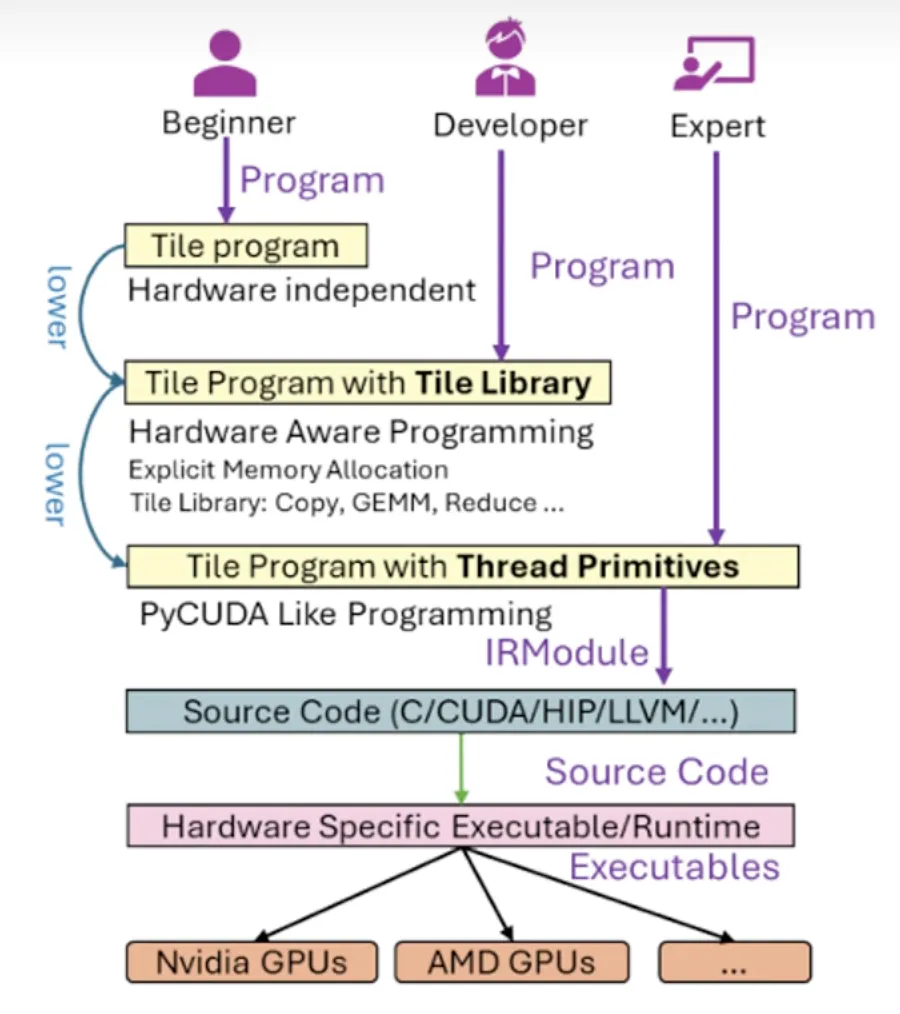
TileLang提供了三个层级的编程模式以满足不同开发者:
- 入门版:仅描述数据块和计算逻辑,所有硬件细节和优化由编译器完成。
- 进阶版:可调用封装好的算子,平衡开发效率与灵活性。
- 精细版:支持线程级精细开发,适用于极致性能优化场景。
这三种模式也支持混合使用。下图展示了这三个层级:
相较于传统手工优化,TileLang能实现自动调度。论文实验表明,它能以更少的代码提供更优的模型效率。值得一提的是,DeepSeek V3.2的官方文档中也确认,部分算子已采用TileLang进行重构。这种提升开发效率与性能的思路,正是人工智能领域基础设施进步的一个缩影。
三、RL训推分离
在强化学习训练中,训练所用的数据通常由模型推理产生。若将训练任务和生成数据的推理任务部署在同一集群,虽然部署简单,但会带来以下问题:
- 训练和推理的优化目标不同,耦合在一起会相互影响,优化难度大。
- 两者对硬件需求不同,无法通过异构部署提升性价比。
- 任一环节出现异常都可能波及对方。
思路依旧是解耦。但将训练与推理分离后,又出现了新挑战:
- 推理输出可能经过Agent的复杂处理(如涉及记忆),直接用于训练会丢失上下文一致性。
- 训练和推理流程间的时序依赖容易造成“气泡”,导致算力闲置。
1. SeamlessFlow的训-推数据交互平面机制
针对第一个问题,SeamlessFlow论文设计了一个位于Agent与LLM之间的数据交互平面,其核心是一个“轨迹管理器”。它能精确记录Agent调用LLM的全过程及所有输入输出,确保训练数据的一致性,且整个过程对Agent透明。
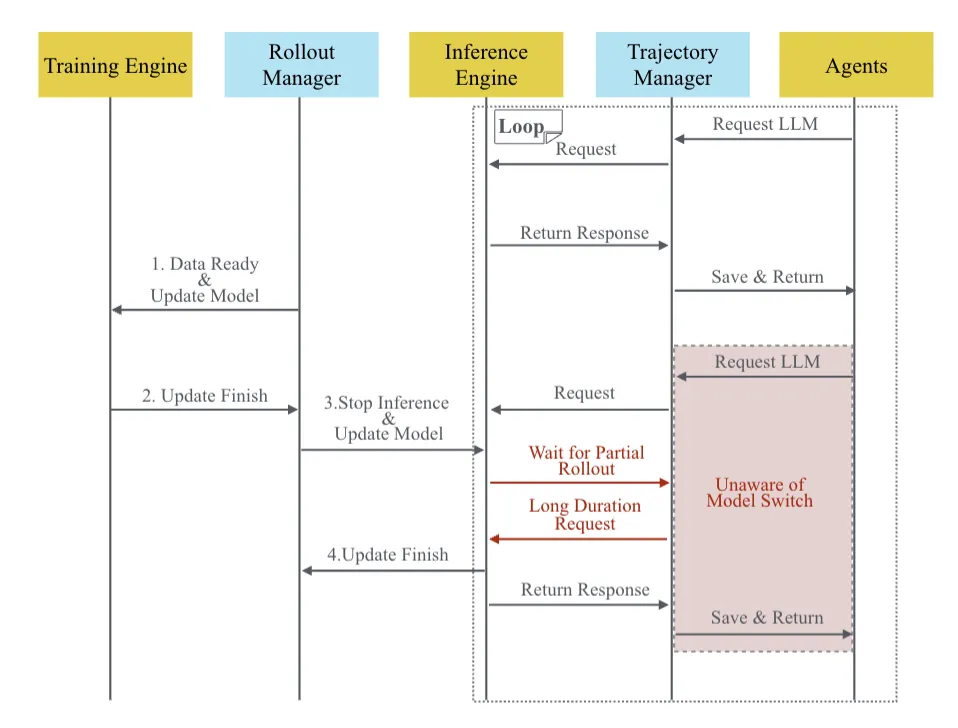
2. SeamlessFlow的标签资源调度机制
针对第二个“气泡”问题,SeamlessFlow没有在“完全分离”和“完全一体”中二选一,而是采用了灵活的标签调度机制。通过给计算资源打上标签,使其可以根据需求灵活执行推理或训练任务,从而消除计算资源的气泡,实现高效利用。
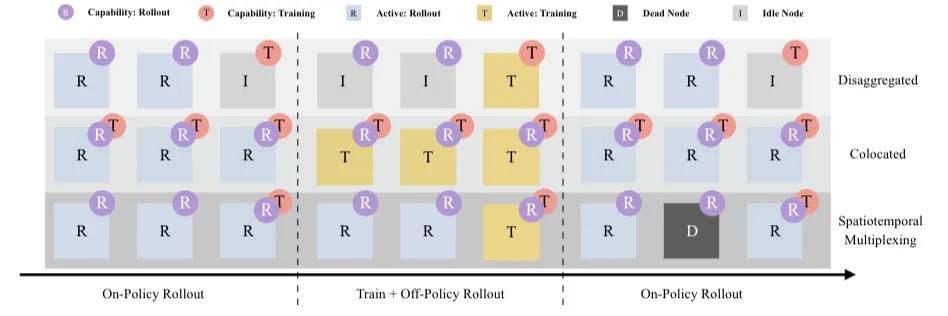
四、模型-系统的协同设计思路
前文提到的优化大多是基于现有模型特点进行的。如果能在模型设计之初,就综合考虑目标硬件的特性,那么将在效率、性价比和优化难度上获得显著优势。Step-3模型正是这种模型-系统协同设计思路下的产物。
Step-3论文引入了“算术强度”的概念,即平均每从显存读取一个字节所需进行的运算次数。它主要与注意力模块的设计相关,而与Batch Size、上下文长度等参数无关。同时,GPU的算力与显存带宽之比(即roofline模型中的“屋顶线”)是固定的。
因此,当模型的“算术强度”高于硬件的“屋顶线”时,算力成为瓶颈;反之,内存带宽成为瓶颈。模型设计的目标,是让注意力模块的“算术强度”尽可能接近主流硬件的“屋顶线”。如下图所示,Step-3的设计恰好接近A800或昇腾910B的屋顶线。
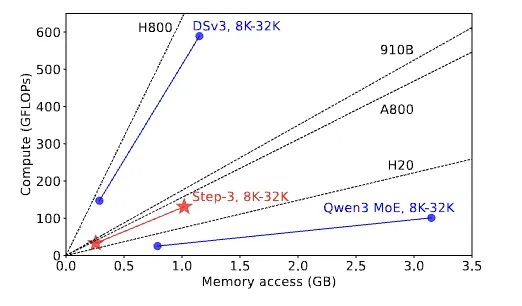
量化的协同设计:对于注意力模块,若采用MQA/GQA或KV Cache与计算使用不同精度,模型的“算术强度”会发生变化。Step-3模型在设计时考虑了这一点,如上图所示,其算术强度无论升降,都有相匹配的硬件可选。
MoE模型与系统架构的联合设计:对于以算力需求为主的FFN模块,论文给出了公式:BatchSize_MoE >= FLOPs / (2 * S * Bandwidth)。这意味着,对于特定显卡,提升计算效率要么增大Batch Size,要么让MoE激活更稀疏。但在AFD架构下,过大的Batch Size会增加网络传输耗时,进而影响TPOT。因此,需要综合设计模型与系统,参考论文中的另一个公式:S/(H * L) >= FLOPs / (Net * Bandwidth * β)。其中β是与FFN量化精度、AFD流水线级数及目标TPOT相关的常数。该公式清晰地表明,要达到高效率,模型的稀疏度S、隐状态维度H、层数L必须与卡型、网络带宽及期望的TPOT值进行合理匹配。
五、Agent Infra
关于Agent基础设施,这里简要介绍几个关键方向和思考。
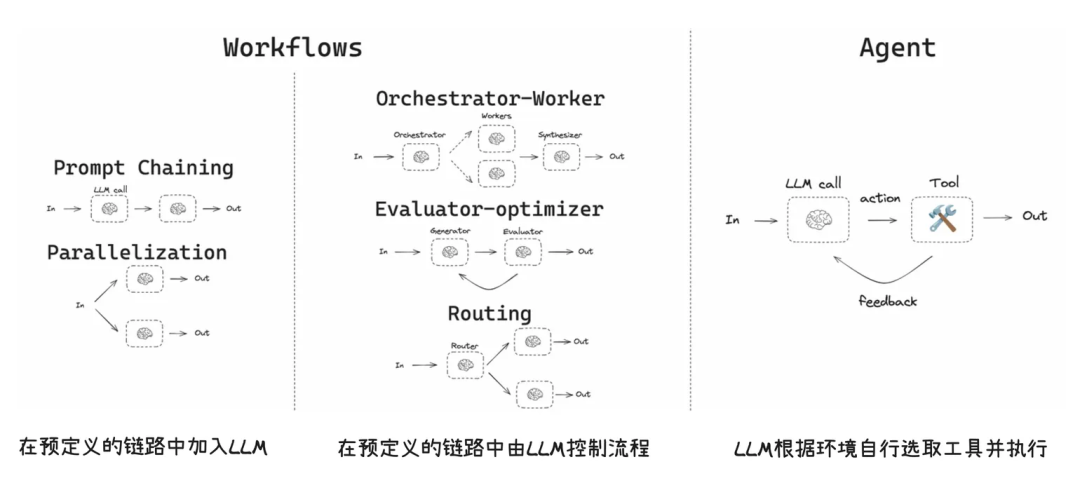
1. Workflow vs Agent
理解两者的区别对于架构选型至关重要:
- Workflow:适合任务步骤确定、分支有限的流程,通过预设路径执行任务。
- Agent:适合任务步骤不固定、需要在对话中动态决策、跨工具组合、执行“思考-行动-观察”循环的场景。
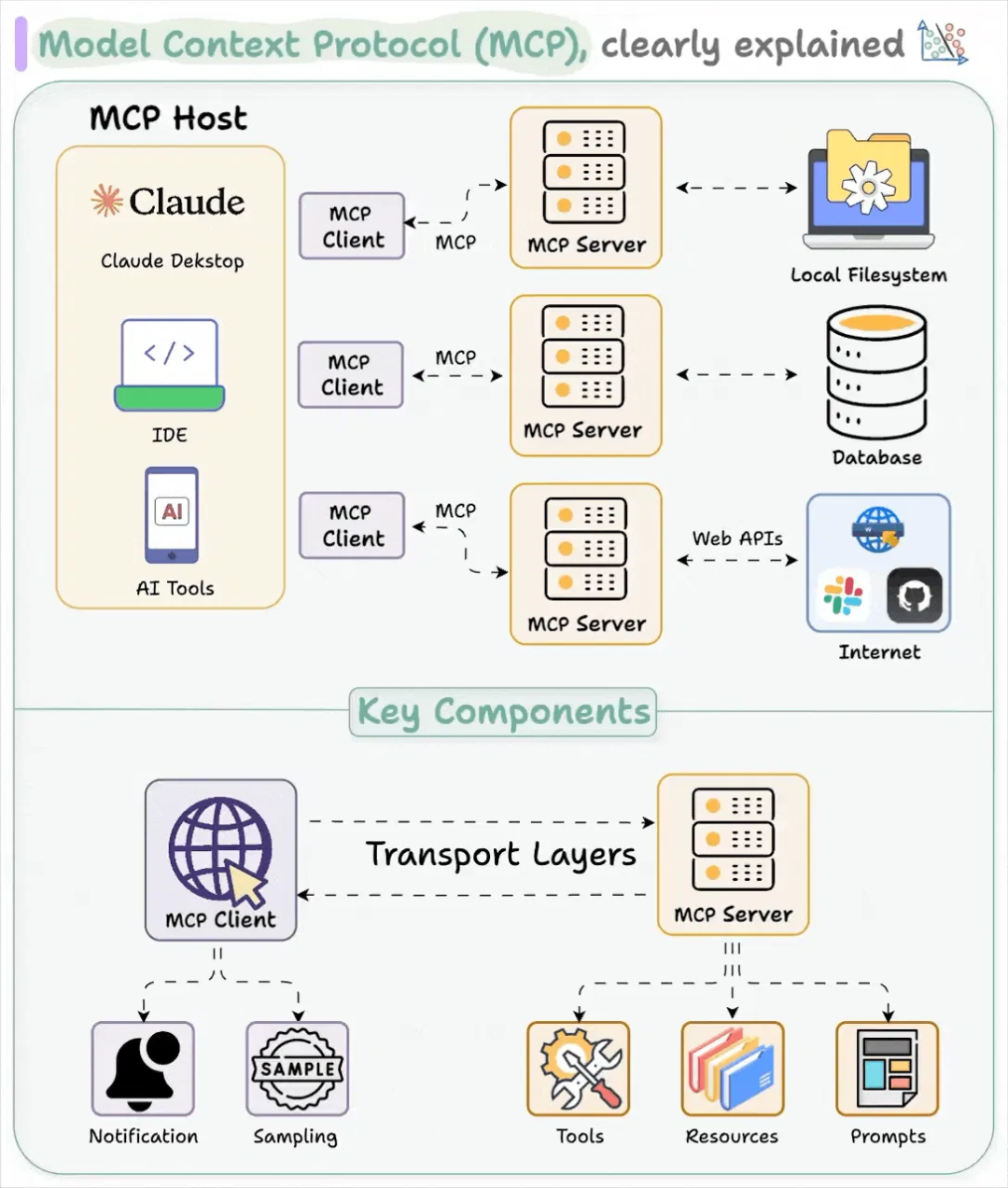
2. MCP:Agent应用开发新范式
模型上下文协议(Model Context Protocol, MCP)是一个定义了AI应用与外部工具、数据源交互方式的标准协议。其目标是创建通用标准,简化AI应用的开发和集成。在实践中,用户可以通过对话指示Agent,模型再通过MCP协议将相应操作传递给MCP应用来执行任务。
MCP的核心组件包括:
- MCP Server:提供工具执行、资源访问等功能。
- MCP Client:作为AI模型与Server的桥梁。
- MCP Host:发起请求的应用程序(如Claude Desktop或IDE)。
与各厂商实现各异、效果不稳定的Function Calling相比,MCP采用标准协议,生态更统一、健壮。
3. Agent Infra 落地关键技术要求
当前成熟的容器、虚拟机或Serverless技术并不完全适合承载Agent业务:
- 容器(如Docker)问题在于安全性:其进程级隔离在运行LLM生成的不可信代码时,于多租户环境下风险极高。
- 传统虚拟机问题在于启动时延:Agent高频的“思考-执行”循环无法忍受分钟级的VM启动等待。
- Serverless问题在于状态保持:Agent的连续任务需要维持上下文(如内存中的数据),而FaaS的无状态特性会导致巨大的I/O开销和延迟。
因此,一个理想的Agent基础设施需要满足:
- 强隔离与安全性:防止不可信代码逃逸。
- 长程任务稳定性:支持分钟甚至小时级任务的稳定运行。
- 状态管理与持久化:崩溃后能恢复运行状态。
- 可观测性与审计:全面监控沙箱内的命令执行和资源访问。
六、超节点形态的硬件基础设施
随着模型规模扩大,训练和推理中的跨卡、跨机通信已成为刚需。相较于RDMA,GPU间的专用高速互联(如NVLink)效率更高。“超节点”的核心思想正是通过这种专用互联将大量GPU连接成一个高效的大规模计算域。
例如,NVIDIA公布的Vera Rubin NVL144架构,单域可包含144颗Rubin GPU,支持FP4精度,域内互联带宽高达260TB/s。

超长上下文模型的推理:在推理场景中,模型上下文长度的增长对算力的需求呈平方级增长,对显存和卡间通信带宽的需求也极大。结合前文提到的PD分离、AFD等思路,更大规模的NVLink高带宽域将为超长上下文模型推理提供理想的基础设施。NVIDIA官方技术博客指出,面对未来百万Token(1M+)上下文成为主流的趋势,采用Rubin架构结合NVL144超节点并以PD分离方式部署,将成为最佳实践。不仅NVIDIA,多家异构计算硬件厂商都在规划类似的超节点形态基础设施。
总结与展望
相较于2024年,同样参数规模的模型,其能力可能已有数量级的提升,这是模型、系统、数据等多方面协同进步的结果。2025年,工程和系统工作的整体方向是更精细化的设计与优化,而非单纯追求“超级硬件”和“超级集群”。
展望2026年,系统优化将更加精细化,并进一步探索基于低成本硬件的极致性价比。而工程发展的重点方向很可能在AI Agent基础设施,因为所有模型与工程技术的进步,最终都服务于AI应用的实际落地。“贾维斯”来到我们身边的那一天,或许已不远了。
参考
- DistServe: Disaggregating Prefill and Decoding for Goodput-optimized Large Language Model Serving. https://arxiv.org/pdf/2401.09670
- DOPD: A Dynamic PD-Disaggregation Architecture for Maximizing Goodput in LLM Inference Serving. https://arxiv.org/pdf/2511.20982
- Step-3 is Large yet Affordable: Model-system Co-design for Cost-effective Decoding. https://arxiv.org/pdf/2507.19427
- DeepEP. https://github.com/deepseek-ai/DeepEP
- TileLang: A Composable Tiled Programming Model for AI Systems. https://arxiv.org/pdf/2504.17577
- SeamlessFlow: A Trainer–Agent Isolation RL Framework Achieving Bubble-Free Pipelines via Tag Scheduling. https://arxiv.org/pdf/2508.11553
- NVIDIA Rubin CPX Accelerates Inference Performance and Efficiency for 1M+ Token Context Workloads. https://developer.nvidia.com/blog/nvidia-rubin-cpx-accelerates-inference-performance-and-efficiency-for-1m-token-context-workloads/
 发表于 2026-1-26 02:17:36
|
查看: 198|
回复: 0
发表于 2026-1-26 02:17:36
|
查看: 198|
回复: 0
