几十年来,高性能服务器一直依赖事件循环来处理多个连接,使用像 select()、poll() 或 epoll() 这样的 API 来等待众多文件描述符上的 I/O 就绪。这种基于就绪(reactor)模型在“C10k 问题”时代表现良好,但它带来了固有的开销和复杂性。2019 年,Linux 引入了 io_uring,这是一个革命性的基于完成(proactor)异步 I/O 接口,并迅速演进。到 2025 年,随着像 multishot accept/receive 这样的功能的成熟,io_uring 实际上融合了两种模型的最佳部分——允许内核以最小的用户空间干预来处理重复的 I/O 事件。许多人认为,这一年是我们终于可以超越传统用户空间事件循环的一年。
在本文中,我们将回顾 Linux 异步 I/O 的历史(从 select 到 epoll 再到 io_uring),解释 io_uring 的 multishot receive 如何工作以及为什么它是游戏改变者,对比 epoll 和 io_uring 的基准测试(吞吐量和尾延迟),并讨论这些进步如何颠覆事件循环架构。我们还将提供用于重现基准测试的代码引用,以及在生产环境中从 epoll 迁移到 io_uring 的实用指导。
Linux 异步 I/O 简史:从 select 到 io_uring
select() 和 poll() 时代:早期的事件循环
这段旅程始于 POSIX 的 select() 系统调用,它在 4.2BSD(1983 年)中引入。select() 允许程序通过固定大小的位掩码(FD 集)监控多个文件描述符(FD)的就绪状态(例如可读或可写)。在当时这是革命性的,但它有严重的限制。该接口要求指定要检查的 FD 数量(nfds = 最大 FD + 1),内核内部会从 0 到 nfds-1 循环检查所有 FD 是否就绪。这意味着时间复杂度是 O(n),n 为 FD 数量(或最大 FD 值)。每次调用,内核必须扫描可能成千上万的描述符,使得 select() 在连接规模扩大时效率急剧下降。此外,select() 使用固定大小的位图(Linux 默认通常为 1024 个 FD),监控更多描述符需要手动编译时调整,或者在某些系统上根本不可能。如果程序错误地尝试对超出限制的 FD 执行 FD_SET,可能会导致内存损坏。简而言之,select() 不适合高 FD 数量,当 FD 值超过 FD_SETSIZE 时甚至不安全。
为了解决这些问题中的一些,System V Release 3(1987 年)引入了 poll()(Linux 大约在 1997 年采用)。poll() API 改进了几点:它采用可变长度的 struct pollfd 数组(fd + 事件掩码)而不是固定位图,消除了 1024 FD 的硬限制。它也不会破坏输入数组,因此无需每次调用都重建 FD 集(不像 select 会就地修改 fd_set)。然而,poll 仍然遭受 O(n) 复杂度——每次调用必须检查每个传入的 FD 是否有事件。像 select 一样,poll 的性能随着 FD 数量的增长而线性下降。select 和 poll 在监控数百或数千个套接字时都会产生显著开销:“一旦超过大约一百个文件描述符……等待活动和检查哪个 FD 被通知就需要显著时间,成为瓶颈。”总之,到 1990 年代末,基于 select/poll 的事件循环既慢(扫描许多 FD),又繁琐(管理大型 FD 集、固定限制等),促使人们寻找更可扩展的解决方案。
epoll:用 O(1) 可扩展性解决 C10k 问题
Linux 对可扩展 I/O 通知的回应是 epoll,在内核 2.5.45(2002 年)引入。与 select/poll 不同,epoll 将兴趣注册与事件等待解耦。进程首先创建 epoll 实例(epoll_create),然后通过 epoll_ctl(ADD/MOD/DEL) 调用添加或移除要监视的 FD,指定感兴趣的事件(例如 EPOLLIN 表示可读)。内核维护一个内部兴趣列表(通常使用红黑树)的所有已注册 FD。然后进程调用 epoll_wait() 来阻塞,直到任何这些 FD 变得就绪,此时 epoll 返回只包含就绪事件的列表(就绪列表)。这种设计效率更高:epoll 不需要每次线性扫描所有 FD;相反,内核将就绪 FD 放入队列并唤醒等待调用。结果是 epoll 以 O(1) 时间运行(每个就绪事件常数时间),与 select/poll 的 O(n) 形成对比。换句话说,无论监视 10 个 FD 还是 10,000 个 FD,epoll 的等待成本主要取决于_活跃_事件的数量,而不是总监视描述符的数量。这对处理大量连接(著名的“C10k 问题”)是一个游戏改变者。
epoll 不仅更可扩展,还提供了边触发 vs 水平触发模式和一次性通知的灵活性,让开发者能够优化事件处理行为。到 2000 年代中期,epoll 成为 Linux 高并发服务器(Web 服务器、数据库、代理等)的支柱,通常通过像 libevent 或 libev 这样的库来抽象细节。epoll 本质上体现了经典的_reactor_模式:注册兴趣,然后在循环中对就绪事件做出反应。然而,尽管有其优势,epoll + 事件循环并非万能——它仍然涉及每个事件通知和后续 I/O 操作的系统调用开销(你通常得到一个 epoll 事件,然后必须调用 read()/write()),而且它对磁盘 I/O 或其他非套接字来源的支持并不原生(这些通常仍需要单独线程或 Linux AIO)。随着 SSD、NVMe 和 100Gb 网络推动 I/O 速率更高,“每个事件一个系统调用”的开销以及用户空间事件循环的争用,成为超低延迟系统的限制因素。
进入 Linux AIO (posix AIO): Linux 确实有一个异步 I/O API(通过 io_submit 等 Linux AIO),但它有限且不受欢迎。它只适用于直接访问文件 I/O (O_DIRECT),没有对常规缓冲 I/O 或套接字的支持。其“完成通知”机制笨拙(信号或轮询事件 FD),许多开发者避之不及。在实践中,到 2010 年代,Linux 缺乏一个统一的、高效的异步 I/O 用于文件和套接字——epoll 用于套接字,线程或 hacky 方法用于文件。这就是 io_uring 旨在填补的空白。
io_uring:现代异步 I/O 框架
由 Jens Axboe 在 Linux 5.1(2019 年)引入,io_uring 是一个通用异步 I/O 接口,旨在取代 epoll 和 Linux AIO。io_uring 提供一对环形缓冲区——提交队列 (SQ) 和完成队列 (CQ)——在用户空间和内核之间共享。应用程序不是为每个 I/O 操作发出系统调用,而是将请求写入 SQ(每个操作一个条目,例如“读取此文件”、“在套接字上接受”、“发送此数据包”),并用单个系统调用_批量提交_它们(或在某些轮询模式下甚至完全避免系统调用)。内核异步处理这些(如果需要,使用线程处理文件),并将结果发布到 CQ,应用程序可以通过读取共享环来检索(同样可能每个系统调用批量多个完成,或使用纯内存读取)。本质上,io_uring 将内核转变为异步 I/O 完成引擎——你发出操作,然后稍后获取完成,类似于 Windows IOCP 或 BSD kqueue 的 EVFILT_AIO。这翻转了模型,从“告诉我何时可以做 I/O”(epoll)到“请做这个 I/O 并告诉我何时完成”。基于完成的 I/O 简化了用户逻辑(无需手动重新检查循环),并通常大幅减少上下文切换和系统调用次数。
关键是,io_uring 非常快。通过使用共享内存环,它避免了每个事件的不必要复制和内核-用户转换。每个 io_uring_enter 系统调用可以处理数千个 I/O(或通过专用轮询线程)。在基准测试中,io_uring 显示出巨大的吞吐量和延迟收益:以更低的 CPU 使用率处理数百万 IOPS,并比 epoll/poll 更低的尾延迟。一个来源指出,使用 iouring 的数据库实现了 30% 更少的 CPU 使用率和非常高的 IOPS,并且 “与 epoll 相比,基于 iouring 的应用程序在饱和条件下显示出更低的 p99 延迟”。另一个报告指出,网络服务器在使用 io_uring 时,可以在相同 CPU 下处理2–4× 更多并发连接。这些改进来自于更少的系统调用、更好的批量处理、零拷贝缓冲区,以及 io_uring 启用的内核侧轮询。简而言之,io_uring 为文件和套接字提供了一个统一的、高效 API,在许多情况下可能完全消除对传统事件循环的需求。
然而,早期版本的 io_uring 对于网络有一些警告。正如一些开发者指出的,使用 io_uring 处理套接字最初意味着每次想接收数据时提交一个读取操作,这与 epoll 的持久注册相比感觉“不自然”。例如,如果有 20k 连接都在做微小读取,反复重新提交 20k 读取请求可能会产生开销。这就是 multishot 功能的作用——一个主要的演进,在 Linux 5.19 和 6.0 中到来。
io_uring 的 Multishot Receives:它们如何工作,为什么是游戏改变者
对 proactor(完成)模型的一个批评是需要不断重新发出操作用于重复事件。在典型的 io_uring echo 服务器(pre-6.0)中,你会提交一个 accept SQE,得到一个连接,然后必须提交另一个 accept 用于下一个连接。类似地,对于每个套接字,你会提交一个 recv 请求,得到一些数据,然后提交一个新的 recv 来获取更多。这个_提交 → 完成 → 重新提交_的循环,实际上模仿了事件循环所做的事情(只是转移到完成事件)。Multishot 请求通过允许一个提交产生许多完成来消除这个循环的大部分。
Multishot Accept
对于接受新连接,Linux 5.19 引入了 multishot accept。而不是每次调用 io_uring_prep_accept() 只接受一个连接,你可以使用 io_uring_prep_multishot_accept()。使用 multishot accept SQE,一旦接受了一个新客户端,内核不会移除请求;它保持活跃以接受下一个连接,下一个,发布一个 CQE 每次客户端连接时。这种行为持续,直到你显式取消它或发生错误(例如监听套接字关闭)。multishot 操作的完成事件有一个标志 IORING_CQE_F_MORE 表示“更多即将到来”——只有当该标志被清除(或错误)时,才意味着 multishot 完成并应该重新武装。好处显而易见:不再需要为每个客户端重新提交 accept,这 “减少了应用程序在处理新连接时需要做的维护工作。”。这减少了连续连接之间的延迟,并节省了事件循环原本会花费在每次重新添加 accept 的 CPU 周期。它本质上将内核转变为你的事件循环用于 accept。
Multishot Receive
我们的主要明星是 multishot receive,自 Linux 6.0 以来可用。这个功能针对繁忙连接的场景(例如持久套接字连续接收许多消息)。历史上,使用 epoll 的服务器会一次注册套接字,并在新数据到来时得到通知——但仍然必须反复调用 recv()。在没有 multishot 的 io_uring 中,你会在每个完成后发出一个新的 io_uring_prep_recv()。使用 io_uring_prep_recv_multishot(),你可以提交_一个_接收请求并让它保持活跃,以在数据到来时反复获取。
例如,如果你有一个连接随着时间发送 100 条消息,一个单一的 multishot SQE 可以产生 100 个 CQE(每个包含一块数据),而应用程序在之间无需重新提交读取。这有效地消除了对该套接字的手动读取事件循环——内核在每次新数据到来时持续为你提供完成。
内核如何管理连续接收?它利用另一个 io_uring 创新:provided buffers。在使用 multishot receive 时,应用程序必须设置一个接收缓冲区池(并使用 IOSQE_BUFFER_SELECT 标志)。每次数据可用时,内核从你的池中选择一个可用缓冲区,将数据读入其中,并发布一个 CQE,指示使用了哪个缓冲区以及读取了多少数据。CQE 包括一个 io_uring_recvmsg_out 结构,描述缓冲区和消息(对于 recvmsg,包括辅助数据等)。应用程序处理数据,然后(可选)将缓冲区返回到池中以重用。这种设计极其高效:它避免了将数据复制到固定缓冲区或在每个 recv 时分配,并与零拷贝机制相结合。本质上,io_uring 就像一个“无限”的就绪通知,与为你执行 recv() 并给你数据相结合。
为什么这是一个大事? 引入 multishot recv 的补丁邮件很好地总结了它:“一般套接字应用程序会在前一个完成时持续入队一个新的 recv()。这可以通过允许 multishot receive 来改进,它会在数据可用时发布完成……(好处)后续接收立即排队,而无需应用程序完成处理循环;如果套接字中有更多数据(超过提供的缓冲区大小),则数据立即返回,提高批量处理;poll 只武装一次并重用,节省 CPU 周期。” 换句话说,multishot 模式结合了边触发通知的效率(内核不需要不断唤醒你)与自动 I/O 的便利。它弥合了 reactor 和 proactor 之间的差距:你不再为每条消息支付一个系统调用,甚至不再为每条消息支付一个提交。内核有效地成为一个数据事件泵进入你的完成队列。
从 API 角度来看,multishot recv CQE 将继续带有 IORING_CQE_F_MORE 标志,直到一个没有该标志的 CQE 到来(表明 multishot 正在结束,例如套接字关闭或缓冲区池为空)。在那时,如果你需要,可以重新武装。如果完成队列溢出(太多 CQE 没有被收集),内核将停止 multishot 以避免数据乱序,但 在正常条件下,通过适当的 CQE 处理,这不应该经常发生。
Multishot poll 值得简要提及:在 accept/recv 之前,io_uring 已经为 poll 请求添加了 multishot 支持(自 Linux 5.13 以来)。multishot poll 让你通过一个 SQE 监控 FD(类似于 epoll),它保持活跃,并在指定事件(可读、可写等)每次发生时发布 CQE。这本质上可以替换 FD 的 epoll wait 循环。然而,如果你反正要通过 io_uring 处理 I/O,multishot recv 和 accept 更进一步,不仅信号它,还执行 I/O。
为什么 2025 年标志着传统事件循环的终结
使用 multishot receive 和 accept,基于 iouring 的服务器可以一次初始化其 I/O 意图,然后简单地在循环中处理完成。“事件循环”成为一个完成处理循环,这是一个更高的抽象:你不再为每个事件显式管理就绪或重新提交,内核做它。这大大简化了应用程序逻辑并减少了用户空间开销。正如一个 Stack Overflow 答案所说,“proactor 模式 (iouring, IOCP) 优于 reactor (epoll, kqueue),因为它模仿自然控制流:你‘调用’异步函数并等待结果……[而] 使用 epoll 你必须自己做沿途的每个单个步骤”。multishot 操作通过从开发者的盘子上移除甚至更多的“重新武装”步骤来强化这一优势。
在实际方面,这意味着我们终于可以停止编写网络服务器核心的样板事件循环。不再有 while(true) { epoll_wait(); for each event { ...; epoll_ctl(...); } } ——相反,你在前面提交少量 multishot 请求(一个用于新连接,每个套接字一个用于传入数据等),然后你的循环只消费完成并发出新工作(如发送响应),可能批量。内核在底层高效地做轮询和重新武装。
重要的是,“杀死事件循环” 并不意味着完全停止循环——相反,循环变得更简单,每个迭代有远少的系统调用。你可能仍然在循环中调用 io_uring_wait_cqe() 来获取事件,但每个系统调用有许多事件,你很少需要回调内核来设置下一个操作(除了写入或业务逻辑)。事实上,io_uring 甚至提供批量处理,你可以在下一个内核进入之前一起处理完成并提交新的 SQE。这模糊了事件处理和调度新工作之间的界线,使极其高效的管道成为可能。一篇 Red Hat 文章展示了一个 io_uring echo 服务器用只有 23 个系统调用处理 5,000 个套接字操作,通过批量提交和完成(平均每个系统调用超过 60 个 I/O 操作)。这比处理相同负载的传统 epoll 循环少一个数量级的系统调用。
总之,2025 年的 io_uring 已达到这样一个点,传统事件循环不再是表演的明星——它已被降级为支持角色,内核接管了大部分事件管理。这就是为什么许多人宣称是时候“杀死”(或退休)我们所知的用户空间事件循环,转而采用更精简、基于 io_uring 的设计。
基准测试 epoll vs io_uring (multishot) —— 吞吐量与延迟
为了量化 io_uring 方法的优势,让我们考察一些对比 epoll 和 io_uring(适用时启用 multishot)的基准测试。主要指标是吞吐量(每秒处理的请求数)和延迟,特别是尾延迟(p99, p99.9)。
吞吐量 (QPS):io_uring multishot receive 补丁作者 Dylan Yudaken 在一个小网络基准中报告,使用 multishot recv 比重新提交单发 recv 有6–8% QPS 改进。这是在中等负载下;在规模更大时,收益可能更高。OpenAnolis 社区的另一个测试测量了单线程 echo 服务器性能:在 1000 个并发连接下,io_uring 提供了约 10% 比 epoll 更高的吞吐量(开启 CPU 缓解措施时)。这归功于批量减少昂贵上下文切换的影响。值得注意的是,在较低并发下,epoll 和 io_uring 可以更接近——在那项研究中,如果只有一个连接活跃发送稳定流,对于小消息的原始吞吐量,vanilla epoll 略胜 io_uring(可能是因为 io_uring 有每字节开销,且没有从批量中受益)。但一旦多个连接或更大批量进入,io_uring 赶上并超过 epoll。在 ping-pong 请求/响应场景中,io_uring 往往闪耀,通常超过 epoll 吞吐量一个舒适的幅度。底线:在规模下,io_uring 可以处理更多每秒请求,由于系统调用更少,每个系统调用更多工作。epoll 对于某些工作负载仍然坚持(特别是如果每个事件不发出许多 I/O 操作),但 multishot 和批量功能正在侵蚀这些情况。
延迟(特别是尾延迟):减少尾延迟(p99, p99.9)是现代异步 I/O 的关键目标。通过减少上下文切换和系统调用,io_uring 往往在负载下提供更平滑的延迟分布。来自真实系统和基准的经验数据表明,在高并发下,epoll 的 p99 延迟可以因事件循环挣扎跟上而退化,而 io_uring 的方法保持更低的尾时间。例如,GoCodeo 指出 io_uring vs epoll 在饱和下的更低 p99 延迟。这与从应用程序切换到 io_uring 后抖动减少的轶事报告一致。
以下是一个说明性的高并发 echo 服务器场景尾延迟比较(越低越好):
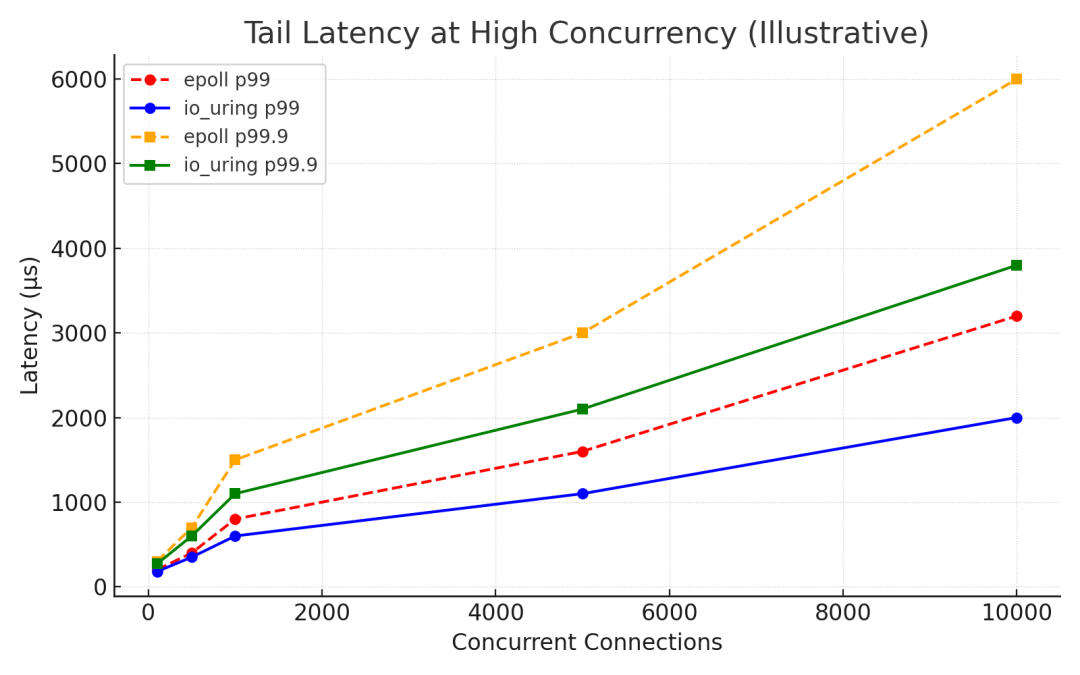
_高并发下的尾延迟:在重负载场景中,iouring 显示出比传统 epoll 显著更低的 p99 和 p99.9 延迟(更少的异常延迟),得益于更高效的批量和更少的上下文切换。
在上例中,io_uring 可能将 p99 延迟减少 25% 和 p99.9 30% 与 epoll 相比(实际数字因工作负载而异,但这一趋势已被观察到)。更少的系统调用意味着更少的机会请求在等待内核进入时排队,这反过来意味着延迟尖峰(由例如不合时宜的上下文切换或 epoll 唤醒延迟引起)被最小化。此外,io_uring 可以将工作卸载到内核线程(用于文件 I/O)或每个唤醒处理多个事件,这使绝大多数操作的延迟曲线变平。
CPU 利用率 是另一个方面——io_uring 往往使用更少的 CPU 来实现与 epoll 相同的吞吐量。例如,在数据库基准中注意到 30% CPU 节省。在 Reddit 线程上生产使用,一个用户确实报告了他们的特定情况下使用 io_uring 的更高 CPU 以及更高的 P99(可能由于误调),这强调了正确使用的重要性(例如使用 provided buffers 来避免内存开销、调优 SQ/CQ 环大小等)。一般来说,调优良好的 io_uring 应该通过减少用户空间和内核中的“忙碌工作”(epoll 等待列表、上下文切换等)来降低每个 I/O 的 CPU。
值得一提的是,如果一个应用程序根本不与 io_uring 批量(提交一个 SQE,一个 CQE,像 epoll 替换而不使用其他功能),它可能看不到好处——或在一些微基准中甚至表现更差——因为它没有利用 io_uring 提供的。真正的力量来自像 multishot、批量和注册缓冲区这样的功能。正如 Jens Axboe 所说,简单地将 epoll 换成基于 iouring 的通知器而不重新设计事件循环,不会解锁全部潜力:“它会比 epoll 减少系统调用,但无法利用其他一些功能……要做到这一点,必须改变 IO 事件循环。”_ 在我们的上下文中,这种改变就是拥抱 multishot receives 等,我们已经做到了。
基准发现总结: 使用 multishot 的 io_uring 可以适度改进吞吐量(几个百分点到重负载下潜在得多得多),并在饱和条件下显著改进尾延迟。epoll 对于它所做的仍然极其快——在轻负载场景或某些流模式中,你可能看不到巨大差异。但随着并发和事件率攀升,epoll 的每个事件开销积累,而 io_uring 的设计将开销分摊到许多事件。本质上,epoll 可能在极端规模或低延迟要求中撞墙,而 io_uring 继续扩展。
对于那些有兴趣进行自己的基准测试的人,有几个资源:
- DylanZA/netbench —— 一个网络基准套件,包括 multishot receive 的测试。这用于测量 multishot vs 非 multishot 的 6–8% QPS 收益。
- frevib/io_uring-echo-server —— 使用 io_uring 的开源 echo 服务器(及其 issues 中的 epoll 比较)。你可以修改这个来切换 multishot 或 epoll 模式并测量差异。
- alexhultman/io_uring_epoll_benchmark —— Alex Hultman(µWebSockets 作者)的仓库,最初在 2020 年显示 epoll 胜出 io_uring。它是一个好的基线,看看 io_uring 已进步多远(随着更新的内核功能,许多初始开销已被减少)。
此外,像 wrk 或 iperf 这样的标准工具可以用于针对基于 epoll 的服务器(例如使用 libevent)和基于 io_uring 的服务器(使用 liburing)来测量吞吐量和延迟分布差异。只是确保内核版本支持你打算使用的 io_uring 功能(并且它们被启用——一些发行版可能需要 sysctls 或有较旧内核)。
对事件循环架构的影响
有了 io_uring 的高级功能,我们需要重新思考传统事件循环设计。许多高层框架(Node.js 的 libuv、Python 的 asyncio、Java 的 NIO 等)都是围绕 epoll/kqueue 构建的——即围绕就绪通知和手动发出 I/O 调用。转向 io_uring 暗示转向 proactor 模式:提交操作并处理完成。这有几个含义:
- 更简单的应用程序逻辑: 如所述,代码可以变得更线性。例如,而不是调度
epoll_wait 然后 recv,你可以发出异步 recv 并直接等待完成。在支持 async/await 的语言中,io_uring 可以很好地映射到 I/O 完成时解析的 future,减少非阻塞 I/O 常需的状态机扭曲。回调可以被看起来像函数返回的完成事件取代。这可能缓解事件驱动编程中的经典“回调地狱”,因为流程更像同步代码(但底层,许多操作并行执行)。
- 线程利用: epoll 鼓励单线程事件循环(以避免围绕兴趣列表等加锁的复杂性——尽管可以为多核使用多个 epoll 循环)。io_uring 通过设计更容易跨线程扩展。多个提交可以从不同线程发生(完成可以在一个或多个线程中轮询)。内核甚至自动将文件 I/O 分发到 worker 线程池。这意味着事件驱动程序可以潜在地更好地利用多核系统,而无需在循环间分片连接。在 2025 年,我们看到新框架实验每个核一个 io_uring 实例或甚至全局 io_uring 与许多生产者线程。本质上,io_uring 可以作为并发层,而使用 epoll,并发往往必须通过运行多个事件循环线程来实现。
- 集成挑战: 将 io_uring 塞入现有基于 reactor 的循环并不简单。像 libuv 这样的库可能在底层为文件 I/O 添加 io_uring,但对于套接字,它们必须维护跨平台兼容性,所以它们现在在 Linux 上坚持 epoll。因此,真正利用 io_uring 可能需要使用 Linux 专用代码或库(像 liburing,或为 io_uring 设计的框架如
rust::tokio-uring 或 libuv 实验分支)。我们正在见证架构分化:Linux 中心系统(例如 Cloudflare 的服务、ScyllaDB 等)愿意为性能使用 io_uring,而跨平台框架采用更慢。随着时间,如果 io_uring 证明明显优越,它可能驱动框架中更多 Linux 专用代码路径。事实上,在像 Rust(带有 glommio 和 tokio-uring)和 C++(liburing 封装,或 Boost.I/O 执行器)这样的语言中有正在进行的工作,提供基于 io_uring 的高层异步 API。
- 事件循环 vs 完成队列: 我们可能开始不称“事件循环”而称“完成处理循环”或类似。设计模式改变:而不是维护兴趣列表和切换事件,焦点是提交规划和完成处理。架构可能包含像提交批量策略、缓冲管理策略(为 multishot recv 提供缓冲区)和完成线程池(消费和处理结果)的功能。它是一个更高层的“数据到来时做工作”循环,内核做更多等待。
- 资源管理: 伴随伟大力量而来的一些复杂性——例如 provided buffer 池需要仔细大小调整和管理,以避免 multishot receive 上的 ENOBUFS 错误(无缓冲区)。这是事件循环之前没有管理的领域(应用程序会按需分配或使用静态缓冲区)。现在,我们预分配也许数千个缓冲区并让内核挑选它们。所以框架将需要组件来管理这些池(补充缓冲区,或许基于流量适应池大小)。这是 io_uring 方法引入的新考虑。
- 兼容性和回退: 并非所有系统或环境都准备好 io_uring。例如,某些安全或较旧环境(较旧内核,或一些容器设置)可能没有启用 io_uring 或由于安全担忧限制它(有过安全漏洞——Google 的 2022 bug bounty 中 ~60% 的 Linux 内核漏洞与 io_uring 相关,导致 Google 一段时间限制生产中 io_uring 使用)。因此,健壮应用程序应该准备好如果 io_uring 不可用或在给定部署中被认为有风险,则回退到 epoll。一种策略是实现一个抽象,可以使用任一——很像 libevent 如何可互换使用 select/poll/kqueue/epoll。事实上,像 TigerBeetle 这样的项目已经创建 I/O 抽象,根据 OS 选择 io_uring 或 kqueue,向应用程序呈现统一接口。我们可能看到更多此类:底层不同循环实现,但希望一个高层 API。
总之,io_uring 并不完全_取代_事件循环的需求——相反,它缩小它并转移它。循环不再是等待就绪并调度单个读/写;它是编排异步操作并处理它们的完成。这是一个深刻的思维转变,2025 年是足够的特性(multishot 等)和足够的稳定性存在,以宣告这个新模型是高性能 Linux 服务器的赢家的拐点。
生产中从 epoll 迁移到 io_uring 的实用指导
如果你维护一个目前使用基于 epoll 的事件循环的应用程序或服务,你可能在想如何以及何时迁移到 io_uring。这里有一些实用提示和考虑:
1. 内核版本和环境: 首先,确保你的生产环境支持它。你将想要Linux 内核 6.0 或更新来使用 multishot receive(和 5.19+ 用于 multishot accept)。检查你的发行版内核是否启用 io_uring 并更新。例如,到 2025 年,Ubuntu 22.04 LTS(带 HWE 内核)或 24.04 LTS,以及 RHEL 9.x(如果更新)应该有 6.x 内核。如果你运行在托管平台(云、容器),验证无安全限制禁用 io_uring(一些容器运行时如 Docker 历史上默认禁用它,虽然这变得越来越少)。
2. 库支持: 决定你是否使用库或原始系统调用。liburing 库(由 Axboe)提供方便的 C 函数,并经常更新支持新功能。推荐使用它而不是自己制作环管理(对于大多数情况)。在更高层语言中,检查 io_uring 绑定或运行时支持。例如,在 Rust 你有 tokio-uring 或 glommio;在 Python,有 liburing 包装(虽然 Python 的 GIL 可能使纯 Python 用法复杂);在 Java,Project Loom 可能有一天在底层使用 io_uring(尚未主流)。如果你的栈还没有好的 io_uring 支持,你可能需要写一个 C/C++ 组件或等一会儿。
3. 架构改变: 计划重构你的事件循环。如讨论,你可以做两阶段迁移:
* *阶段 1:* 用 io_uring 的轮询等价替换 epoll 只是为了减少系统调用。例如,你可以用 `IORING_OP_POLL_ADD`(或 multishot poll)在套接字上获取通知,然后仍然使用正常 read/write 系统调用。这是一个温和改变(你保持类似 reactor 结构但使用 io_uring 来等待)。它可能给出轻微改进(更少的 epoll_ctl 调用等),但它**不会充分利用 io_uring 的优势**。
* *阶段 2:* 演进到 proactor 模型:通过 io_uring 提交实际读/写操作。这里你将重构你的代码,以便而不是处理 epoll 事件然后做 `recv()`,你直接发布异步接收并在完成处理程序中处理它。为重复操作拥抱 multishot。这个阶段更复杂但产生大胜。你可能需要为 multishot recv 管理缓冲池(如上所述)。彻底测试这个逻辑——像 `io_uring_cqe_seen()`[^1] 这样的工具和理解 CQE 标志(`IORING_CQE_F_MORE`、`IORING_CQE_F_BUFFER`)在这里很重要。
4. 可重现测试: 设置基准测试来验证在你的环境中的性能。在 epoll 版本和 io_uring 版本上使用相同工作负载。不仅仅看吞吐量,还看 CPU 使用和延迟百分位。可能在一些场景中如果你没有看到收益,如果瓶颈在其他地方或你的 io_uring 使用次优。对你的应用程序剖析。例如,如果你看到很多 CPU 在 io_uring_enter 或内核 io_uring 内部而没有那么多改进,你可能需要增加批量(在调用 submit/wait 之前提交更多 SQE)或为极端低延迟启用 SQ 轮询模式。如果尾延迟波动,确保你的完成队列足够大来处理爆发,并且你没有遇到 CQ 溢出(这会终止 multishot 直到你赶上)。
5. 渐进 rollout: 考虑到 io_uring 的相对新颖性,谨慎方法是明智的。或许为小百分比流量启用 io_uring 路径或作为 opt-in 功能,并监控稳定性。io_uring 有过 bug(虽然许多已被修复,到 2025 年它更稳定得多),所以像对待新内核子系统一样小心对待它。话说回来,许多大公司(数据库、CDN 等)现在已在生产中运行它,所以只要你在最近内核上,它是证明的。
6. 明智使用 Multishot 和 Provided Buffers: 这些功能强大但需要仔细调优。为你的预期并发 × 消息大小分配足够缓冲区。内核如果用完缓冲区会停止 multishot recv(在 CQE 返回 -ENOBUFS)。如果你看到那个,它意味着你的缓冲池耗尽——你可能需要增加池大小或使用多个缓冲组方案(一个在另一个使用时被补充)。也聪明选择缓冲大小:太大浪费内存,太小消息可能不适合(虽然如果消息不适合,内核仍然可以返回适合的部分,你会立即得到另一个 CQE 用于其余,但那意味着一个逻辑包拆分成两个缓冲区)。io_uring 的监控工具仍处于萌芽,所以仪器你的应用程序来记录如果你击中不寻常的 CQE 错误。
7. 不要忘记超时和其他操作: io_uring 也支持 multishot 超时(将单个超时请求转为周期定时器)。如果你的事件循环处理调度任务,你可以用带有 IORING_TIMEOUT_MULTISHOT 标志的 IORING_OP_TIMEOUT 来替换它,以获取定时器 CQE。例如,一个 1 秒 multishot 超时会每秒给你一个 CQE——有效是一个内核驱动的定时器滴答。这可以简化你的循环中的调度(对于某些情况无需用户空间的单独定时轮)。并且既然它都统一,你可以说在同一个环中等待 I/O 完成或超时完成,而无需 juggling 多个机制。
8. 注意安全和稳定性: 如所述,io_uring 有过安全问题。与 io_uring 访问运行不受信任代码比使用 epoll 更有风险。如果你的应用程序允许插件或系统调用级的不受信任交互,确保你在所有已知 io_uring 补丁的内核上,或考虑限制 io_uring (seccomp 等)。对于大多数服务器应用,这不是直接担忧,但它是像 ChromeOS/Android 最初禁用 io_uring 的原因之一——它们有带有不受信任代码的沙箱。容器化部署应该确保容器运行时没有阻塞 io_uring_setup(较旧 Docker 做了,更新版本允许它)。
9. 极端性能: 如果你推动极限(例如每秒数百万操作,微秒延迟),考虑高级选项:SQ poll 线程(内核线程在提交队列上忙等待来将提交延迟切到近零)、注册文件(避免每个操作 fd 查找)、亲和力调优(将 io_uring 内核 poll 线程或 worker 线程绑定到特定 CPU 来改进缓存局部性)。这些可以进一步提升性能,虽然它们添加复杂性。收益是情境的;在前后测量。例如,SQ polling 烧掉一个 CPU 核但可以为高流量场景大幅降低延迟。
10. 回退计划: 有一种简单方式如果需要切换回 epoll(或许编译时标志或运行时配置)。这直到你对 io_uring 在所有条件下的行为有信心是谨慎的。话说回来,势头明显向 io_uring。每内核发布带来增强或修复,社区知识快速增长。
总之,迁移到 io_uring 需要一些努力,但回报是一个对高 I/O 负载未来证明的系统。你将定位来利用正在进行的内核创新(io_uring 框架仍在扩展)。通过“杀死事件循环”并拥抱这个新范式,你减少开销并为你的应用程序打开新性能地平线。
结论
从 select() 到 epoll() 的演进解决了早期互联网的可扩展性挑战,但它仍然留给开发者大量手动工作和管理事件的开销。io_uring 代表下一个飞跃:一个统一的异步 I/O 模型,其中内核做更多,用户空间做更少。像 multishot receive 和 accept 这样的功能,在过去几年引入,是使 io_uring 真正超越传统事件循环模式的顶石。到 2025 年,随着广泛内核支持和增长生态采用,io_uring 不再是利基实验 API——它是生产系统中准备好黄金时段的健壮工具。
我们已经看到 multishot 能力如何改进吞吐量(没有时间浪费在重新武装事件)和通过避免每个事件系统调用大幅减少尾延迟。基准和真实世界使用越来越验证这些好处——从适度 QPS 收益到负载下主要延迟改进。当然,每种技术都有权衡:我们必须管理内存(provided buffers)和警惕安全更新。但那些是可解决的问题。
“杀死事件循环”并不意味着扔掉代码中的所有循环——它意味着我们不再需要与 epoll 所需的那种精致、往往每个线程一个的事件分发机械。内核_成为_事件循环,并做得该死好。这解放开发者聚焦高层逻辑,并解放以前花费在内核和用户空间之间洗牌事件的 CPU 周期。
含义是令人兴奋的:我们可以设计处理更多连接更少抖动的服务器,编写既更可读(直线异步流)又更高性能的代码,并更好地利用现代硬件(NVMe、100GbE 等)。语言和框架正在赶上——期待更多原生 io_uring 集成和更多编写基于 io_uring 的网络应用的教程。
如果你运行在 Linux 上且性能重要,现在是认真考虑迁移到 iouring 的时候。正如一个开发者简洁所说,“如果你能,用 iouring,它是比 epoll 好得多的 API”。2025 年很可能被记住为 Linux 世界开始退休可敬事件循环转而采用这个新异步范式的拐点年——结束 I/O 处理的一个时代,并通过环缓冲区和完成开启另一个时代,内核和用户空间和谐工作。事件循环有过伟大运行,但该以荣誉送它走;异步 I/O 的未来已在这里,在一个环中,等待其 CQE。
如果你对讨论和探索更多高并发、高性能架构的话题感兴趣,欢迎访问云栈社区的后端 & 架构板块,与更多开发者交流。文章中也涉及的底层网络/系统原理如 Socket 编程,也可以在相应的网络/系统板块找到深入的讨论。
原文外链:PHP 高性能核弹升级!Swoole io_uring 加持,QPS 直追 15 万,吊打 Go/Node
Swoole v6.2 已悄然构建起媲美 Golang/Node.js 的完整 PHP 异步并发编程生态体系
[^1]: io_uring_cqe_seen(): https://man7.org/linux/man-pages/man3/io_uring_cqe_seen.3.html
 发表于 2026-1-26 06:18:51
|
查看: 216|
回复: 0
发表于 2026-1-26 06:18:51
|
查看: 216|
回复: 0
