刚刚,OpenAI 开发者团队发布了一篇技术博客,直接拆解了 Codex CLI 的核心工作机制,完整揭示了从用户输入到最终响应的全过程,包括 prompt 构建、模型推理、工具调用、上下文管理等关键细节。
对于希望深入了解 AI编程助手 底层机制的开发者、正在构建自己 Agent 系统的工程师,或是对 Codex 感兴趣的用户来说,这篇官方揭秘值得一读。
全文详解
你有没有想过,当你给 Codex 发送一条指令后,在它给你返回结果之前,系统内部究竟发生了什么?
实际上,每一轮对话都会经历:组装输入、运行推理、执行工具、把结果反馈回上下文 这几个步骤。这个过程会持续循环,直到任务完成为止。
这是 OpenAI 关于 Codex 技术揭秘系列的第一篇文章,官方承诺后续还会有更多深度内容放出。
什么是 Agent Loop?
Agent Loop(智能体循环)是 Codex CLI 的核心逻辑,负责协调用户、模型和工具三者之间的交互。
简单来说,其基本流程如下图所示:
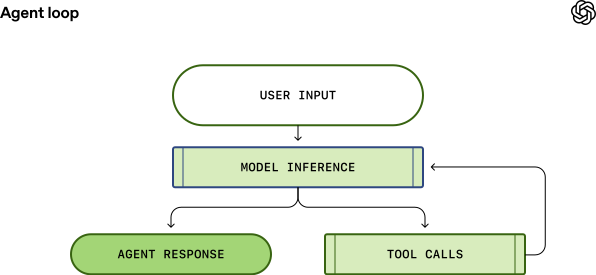
Agent 接收用户的输入,将其组装成发送给模型的指令(即 prompt)。
下一步是推理:将 prompt 发送给模型,让它生成响应。在推理过程中,文本 prompt 首先被转换成一串 token(整数索引),然后模型基于这些 token 进行采样,产生新的 token 序列。输出的 token 再转换回文本,就是模型的响应。由于 token 是逐个生成的,因此许多 LLM 应用都支持流式输出,让用户能看到回答一个字一个字地蹦出来。
推理结束后,模型可能做出两种选择:
- 直接给出最终答案。
- 请求执行一个工具调用(例如,“运行一下
ls 命令然后告诉我结果”)。
如果是第二种情况,Agent 就会去执行该工具,并将工具的输出拼接到原来的 prompt 后面,然后重新查询模型。
这个过程会一直循环,直到模型不再请求工具调用,而是产出一条给用户的最终消息(在 OpenAI 的术语中称为 assistant message)。这条消息可能直接回答了用户的问题,也可能是向用户进一步追问。
从用户输入到 Agent 响应的整个过程,称为一“轮”对话。在 Codex 里,这被称为一个“thread”。虽然是一轮对话,但其内部可能包含了多次“模型推理 → 工具调用”的迭代。
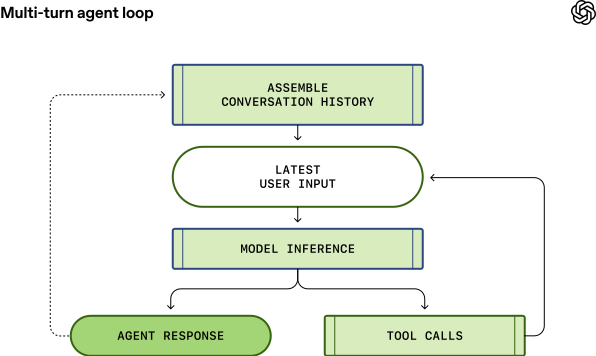
每当用户向已有的对话发送新消息时,之前的对话历史(包括所有消息和工具调用)都会作为新一轮 prompt 的一部分。这意味着对话越长,prompt 也会越长。
这一点至关重要,因为每个模型都有上下文窗口限制,即单次推理能处理的最大 token 数量。注意,这个窗口同时包含了输入和输出的 token。一个 Agent 可能在一轮对话中调用数百次工具,很容易就将上下文窗口撑满。因此,上下文窗口管理是 Agent 的一项重要职责。
模型推理
Codex CLI 通过向 OpenAI 的 Responses API 发送 HTTP 请求来驱动模型推理。该 API 端点是可配置的,因此它可以兼容任何实现了相同接口的后端服务:
- 使用 ChatGPT 登录时,端点是
https://chatgpt.com/backend-api/codex/responses
- 使用 API key 认证时,端点是
https://api.openai.com/v1/responses
- 使用
--oss 参数运行 gpt-oss 时(需配合 ollama 0.13.4+ 或 LM Studio 0.3.39+),默认使用本地 http://localhost:11434/v1/responses
- 也可以使用 Azure 等云服务商托管的 Responses API
构建初始 Prompt
作为用户,你无需手动编写完整的 prompt。你只需要在请求中指定各种输入项,Responses API 服务器会负责将这些信息组装成模型能够理解的 prompt。
你可以将 prompt 想象成一个“列表”。初始 prompt 中的每个条目都有一个 role,表示该段内容的不同权重级别,从高到低依次是:system、developer、user、assistant。
向 Responses API 发送的 JSON 请求中包含许多参数,最关键的有以下三个:
instructions:插入到模型上下文的 system(或 developer)消息。tools:模型可以调用的工具列表。input:发送给模型的文本、图片或文件输入列表。
在 Codex 中,instructions 字段来自 ~/.codex/config.toml 里的 model_instructions_file;如果未配置,则使用模型自带的 base_instructions。不同模型的指令文件打包在 CLI 中(例如 gpt-5.2-codex_prompt.md)。
tools 字段是一个工具定义的列表,包括 Codex CLI 自带的工具、Responses API 提供的工具,以及用户通过 MCP server 配置的工具,其结构大致如下:
[
// Codex 自带的 shell 工具,用于在本地执行命令
{
"type": "function",
"name": "shell",
"description": "Runs a shell command and returns its output...",
"strict": false,
"parameters": {
"type": "object",
"properties": {
"command": {"type": "array", "description": "The command to execute", ...},
"workdir": {"description": "The working directory...", ...},
"timeout_ms": {"description": "The timeout for the command...", ...},
...
},
"required": ["command"],
}
},
// Codex 内置的 plan 工具
{
"type": "function",
"name": "update_plan",
"description": "Updates the task plan...",
"strict": false,
"parameters": {
"type": "object",
"properties": {"plan":..., "explanation":...},
"required": ["plan"]
}
},
// Responses API 提供的网页搜索工具
{
"type": "web_search",
"external_web_access": false
},
// 用户配置的 MCP server,比如天气查询
{
"type": "function",
"name": "mcp__weather__get-forecast",
"description": "Get weather alerts for a US state",
"strict": false,
"parameters": {
"type": "object",
"properties": {"latitude": {...}, "longitude": {...}},
"required": ["latitude", "longitude"]
}
}
]
input 字段是一个条目列表。在添加用户的消息之前,Codex 会首先插入以下内容:
1. 一条 role=developer 的消息,用于描述沙箱环境,但仅适用于 Codex 自带的 shell 工具。这意味着 MCP server 提供的工具不受 Codex 沙箱保护,需要自行实现安全机制。
这条消息通过模板生成,核心内容来自打包在 CLI 里的 Markdown 文件(如 workspace_write.md 和 on_request.md),格式类似:
<permissions instructions>
- 沙箱说明,解释文件权限和网络访问
- 什么时候该向用户请求执行 shell 命令的权限
- Codex 可写的文件夹列表(如果有的话)
</permissions instructions>
2. (可选)一条 role=developer 的消息,内容是用户 config.toml 里的 developer_instructions。
3. (可选)一条 role=user 的消息,即“用户指令”。这不是来自单一文件,而是从多个来源聚合而来。规则是:越具体的指令出现得越靠后。
$CODEX_HOME 目录下的 AGENTS.override.md 和 AGENTS.md 内容。- 从 Git/项目根目录到当前目录的每个文件夹里(受 32 KiB 限制),查找
AGENTS.override.md、AGENTS.md 或 project_doc_fallback_filenames 指定的文件。
- 如果配置了 skills:
- 一段关于 skills 的简短说明。
- 每个 skill 的元数据。
- 关于如何使用 skills 的说明。
4. 一条 role=user 的消息,描述 Agent 当前运行的本地环境,包括当前工作目录和用户的 shell:
<environment_context>
<cwd>/Users/mbolin/code/codex5</cwd>
<shell>zsh</shell>
</environment_context>
在上述计算完成后,Codex 将用户的消息追加到 input 里,对话便正式开始。
每个 input 元素都是一个 JSON 对象,包含 type、role 和 content,例如用户的消息:
{
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "Add an architecture diagram to the README.md"
}
]
}
Codex 构建好完整的 JSON 后,便向 Responses API 发送 HTTP POST 请求(带上 Authorization header,以及配置中指定的其他 header 和参数)。
当 OpenAI 的 Responses API 服务器收到请求后,会按照下图所示的方式从 JSON 构建 prompt:
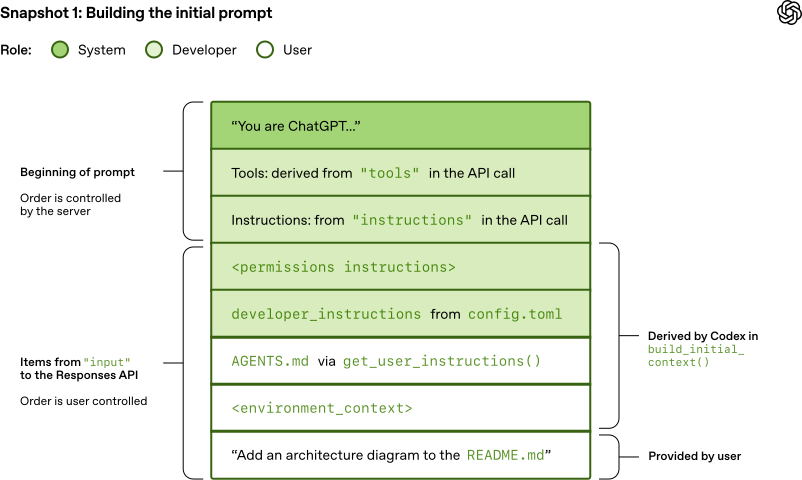
可以看到,前三项(System Message, Tools, Instructions)的顺序由服务器决定,而非客户端。不过,在这三项中,只有 system message 的内容也由服务器控制,tools 和 instructions 的内容是由客户端决定的。之后是 JSON 里的 input,共同构成了完整的 prompt。有了 prompt,就可以开始进行模型采样了。
第一轮对话
向 Responses API 发送的 HTTP 请求启动了 Codex 对话的第一“轮”。服务器以 Server-Sent Events(SSE)流的形式返回响应。每个事件的 data 字段是一个 JSON 对象,其 type 以 response 开头,可能像这样:
data: {"type":"response.reasoning_summary_text.delta","delta":"ah ", ...}
data: {"type":"response.reasoning_summary_text.delta","delta":"ha!", ...}
data: {"type":"response.reasoning_summary_text.done", "item_id":...}
data: {"type":"response.output_item.added", "item":{...}}
data: {"type":"response.output_text.delta", "delta":"forty-", ...}
data: {"type":"response.output_text.delta", "delta":"two!", ...}
data: {"type":"response.completed","response":{...}}
Codex 消费这些事件流,将其转换为内部事件对象供客户端使用。例如,response.output_text.delta 这样的事件用于支持 UI 的流式显示,而 response.output_item.added 这样的事件则会被转换成对象,并追加到后续 Responses API 调用的 input 里。
假设第一次请求返回了两个 response.output_item.done 事件:一个是 type=reasoning,另一个是 type=function_call。当我们再次查询模型时,这些事件必须在新的 input 里体现出来:
[
/* ... input 数组里原来的 5 个条目 ... */
{
"type": "reasoning",
"summary": [
"type": "summary_text",
"text": "**Adding an architecture diagram for README.md**\n\nI need to..."
],
"encrypted_content": "gAAAAABpaDWNMxMeLw..."
},
{
"type": "function_call",
"name": "shell",
"arguments": "{\"command\":\"cat README.md\",\"workdir\":\"/Users/mbolin/code/codex5\"}",
"call_id": "call_8675309..."
},
{
"type": "function_call_output",
"call_id": "call_8675309...",
"output": "<p align=\"center\"><code>npm i -g @openai/codex</code>..."
}
]
此时,发给模型的 prompt 会变成这样:

注意,旧的 prompt 是新 prompt 的精确前缀。这是故意设计的,这样后续请求就能利用 prompt 缓存,从而大幅提升效率(下文会详述)。
回顾我们最开始的 Agent Loop 图,在推理和工具调用之间可能进行多次迭代。Prompt 会不断增长,直到我们最终收到一条 assistant message,标志这一轮结束:
data: {"type":"response.output_text.done","text":"I added a diagram to explain...", ...}
data: {"type":"response.completed","response":{...}}
在 Codex CLI 里,我们会将这条 assistant message 展示给用户,并将焦点移至输入框,等待用户继续对话。如果用户回复,上一轮的 assistant message 和用户的新消息都要被追加到新请求的 input 里:
[
/* ... 上次 Responses API 请求的所有条目 ... */
{
"type": "message",
"role": "assistant",
"content": [
{
"type": "output_text",
"text": "I added a diagram to explain the client/server architecture."
}
]
},
{
"type": "message",
"role": "user",
"content": [
{
"type": "input_text",
"text": "That's not bad, but the diagram is missing the bike shed."
}
]
}
]
因为是继续对话,所以发送给 Responses API 的 input 长度会持续增加:
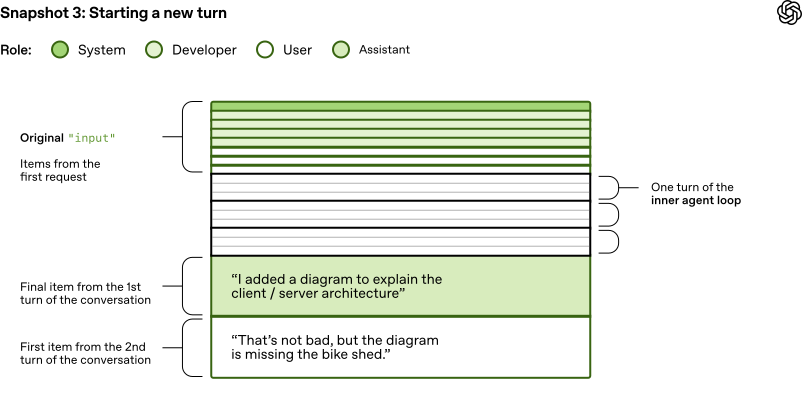
性能考量
你可能会问:“等等,这个 Agent Loop 在整个对话过程中发送的 JSON 数据量难道不是平方级增长吗?”
确实如此。虽然 Responses API 支持可选的 previous_response_id 参数来缓解这个问题,但 Codex 目前并未使用它,主要是为了保持请求的完全无状态,以及支持零数据保留(ZDR)配置。
避免使用 previous_response_id 简化了 Responses API 提供方的实现,因为每个请求都是独立的。这也让支持 ZDR 的客户变得简单:存储支持 previous_response_id 所需的数据会与 ZDR 原则相矛盾。ZDR 客户仍然可以受益于之前轮次的专有推理消息,因为相关的 encrypted_content 可以在服务器端解密。
一般来说,采样模型的计算成本远超网络传输成本,因此采样是效率优化的主要目标。这就是为什么 prompt 缓存如此关键:它能让我们复用之前推理调用的计算。当缓存命中时,采样模型的计算是线性的而非平方级的。
OpenAI 的 prompt 缓存文档解释到:
缓存命中只对 prompt 内精确的前缀匹配有效。要实现缓存收益,请把静态内容(如指令和示例)放在 prompt 开头,把可变内容(如用户特定信息)放在末尾。图片和工具也是如此,它们必须在不同请求之间完全一致。
考虑到这一点,哪些操作可能导致 Codex 的“缓存未命中”呢?
- 在对话中途改变可用的
tools 列表。
- 改变 Responses API 请求的目标
model(实际上这会改变原始 prompt 的第三项,因为它包含模型特定的指令)。
- 改变沙箱配置、审批模式或当前工作目录。
Codex 团队在引入可能影响 prompt 缓存的新功能时必须非常谨慎。例如,最初支持 MCP 工具时有一个 bug,工具枚举顺序不一致,导致了缓存未命中。MCP 工具尤其棘手,因为 MCP server 可以通过 notifications/tools/list_changed 通知动态改变工具列表。在长对话中途响应这个通知可能导致代价高昂的缓存未命中。
在可能的情况下,我们通过在 input 后面追加新消息来处理对话中途的配置变更,而不是修改之前的消息:
- 如果沙箱配置或审批模式变更,我们插入一条新的
role=developer 消息,格式与原来的 <permissions instructions> 相同。
- 如果当前工作目录变更,我们插入一条新的
role=user 消息,格式与原来的 <environment_context> 相同。
我们竭尽全力确保缓存命中以提升性能。此外,另一个关键资源需要管理:上下文窗口。
我们避免上下文窗口耗尽的通用策略是:当 token 数超过某个阈值时,压缩对话。具体来说,我们用一个更小的、能代表原对话的条目列表替换 input,让 Agent 能带着对已发生内容的理解继续工作。
早期的压缩实现需要用户手动执行 /compact 命令,它会用已有对话加上自定义的摘要指令查询 Responses API,然后用返回的 assistant message 作为后续对话轮次的新 input。
后来,Responses API 演进出了专门的 /responses/compact 端点来更高效地执行压缩。它返回一个条目列表,可以替代之前的 input 继续对话,同时释放上下文窗口。这个列表包含一个特殊的 type=compaction 条目,带有不透明的 encrypted_content,保留了模型对原始对话的隐式理解。现在,当超过 auto_compact_limit 时,Codex 会自动使用这个端点来压缩对话。
后续计划
在这篇 技术文档 中,OpenAI 介绍了 Codex 的 Agent Loop,并详细讲解了 Codex 在查询模型时如何构建和管理上下文。同时,也分享了一些对任何在 Responses API 上构建 Agent Loop 的开发者都适用的实践考量和最佳实践。
虽然 Agent Loop 是 Codex 的基础,但这只是一个开始。在后续文章中,OpenAI 承诺会深入探讨 CLI 的架构、工具使用的具体实现,以及 Codex 的沙箱安全模型。
相关链接:
对于关注前沿 AI 开发工具和架构实践的开发者来说,持续跟踪这类官方深度解析,是提升技术视野和架构设计能力的绝佳途径。欢迎在 云栈社区 交流讨论更多关于 AI 代理和编程助手的实战经验。
 发表于 2026-1-26 14:30:19
|
查看: 297|
回复: 0
发表于 2026-1-26 14:30:19
|
查看: 297|
回复: 0
