面对琳琅满目的Deep Research Agent(深度研究智能体),究竟该如何选型?本文基于俄亥俄州立大学(OSU)与亚马逊(Amazon)最新发布的MMDR-Bench论文,为你提供一份经过严谨科学验证的“避坑指南”。
结论先行:在需要联网搜索、整合多来源信息的综合深度研究任务中,谷歌的Gemini Deep Research(智能体版)是首选。而对于以分析复杂科学图表为主、对引用来源要求相对宽松的硬核任务,如计算机科学与数据结构领域,GPT-5.2依然是专家级选择。
随着深度研究概念的爆发,我们面临一个共同的困惑:在处理包含大量复杂图表、需要多步联网检索的真实任务时,到底哪家强? 这里的评价标准早已不是简单的文本生成流畅度,而是对视觉证据的精确提取和引用源的绝对诚实。

俄亥俄州立大学联合亚马逊科学发布的 MMDeepResearch-Bench ,可能是目前业内最严苛的端到端多模态研究基准。他们用140个专家级任务,对当下最新的25款顶尖模型进行了“全身体检”。
这篇文章将为你解读这份“体检报告”背后的硬核价值:为什么谷歌在多模态整合上遥遥领先?为什么文笔最好的模型反而最容易“造假”?以及在不同的垂直技术栈中,你应该如何配置自己的智能体选型策略。
MMDR-Bench:一场高标准的多模态“高考”
研究者构建了包含 140个专家级任务 的数据集,覆盖 21个专业领域 。与以往基准不同,这些任务被设计为“图文捆绑包(Image-Text Bundle)”,强制要求AI必须结合视觉信息才能作答,杜绝了仅凭文本信息“猜答案”的可能。
能力分层:从原子技能到整合研究
官方项目主页通过一个清晰的层级图展示了其考核逻辑,这本质上是对人工智能研究能力的拆解:
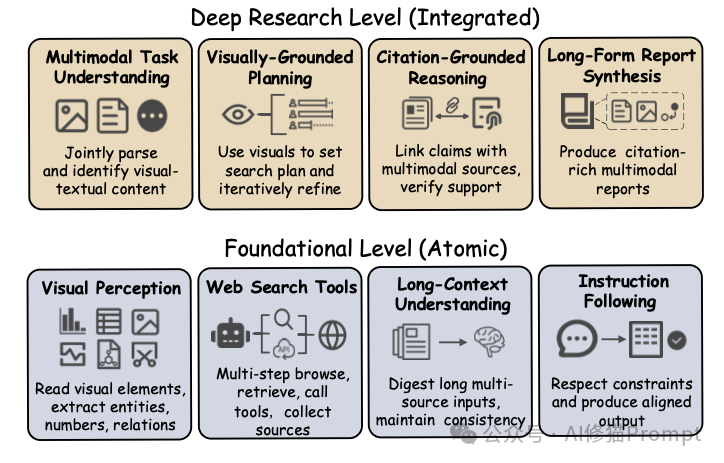
- 基础原子层 (Foundational Level):考察AI的基本功。
- 视觉感知:能否读懂图表中的数据点、识别图中的物体?
- 搜索工具:能否正确使用浏览器工具检索信息?
- 长上下文理解:能否消化冗长、多源的检索结果?
- 深度整合层 (Deep Research Level):考察AI像人类研究者一样工作的能力。
- 视觉引导规划:根据图片内容动态决定搜索策略(例如,看到一张未知的芯片架构图,知道去搜索其具体型号和参数)。
- 引证基础推理:将搜索到的文本证据与图片中的客观事实链接起来,相互印证。
- 长篇报告合成:生成图文并茂、引用规范、结构完整的专业报告。
两种实战场景:生活琐事与硬核科研
数据集模拟了两种截然不同的真实场景,以评估模型的泛化能力:

- 日常场景 (Daily Regime, 约29%):处理生活中的非结构化图片,如手机截图、产品照片。
- 示例:“我的眼睛干涩发痒,还流泪。根据这张眼药水照片,判断它是否适合我的症状?我能在伦敦地区买到其他眼药水吗?”
- 研究场景 (Research Regime, 约71%):处理信息密度高的科学图表、技术架构图。
- 示例:“从这张Transformer架构图、缩放点积注意力图和绝对位置编码图中提取关键信息,并利用公开资料说明自注意力机制关于序列长度L和隐藏大小d的时间、空间复杂度。”
专家级的数据质量保证
为了保证任务的难度和合理性,所有任务都经过了对应领域的博士级专家反复打磨。
- 多模态必要性:确保任务必须看图才能完成,无法通过纯文本推理蒙混过关。
- 可验证性:确保模型生成的报告中的每一个声明,原则上都可以通过其提供的引用链接进行回溯和验证。
评估方法论:一套严苛的“三审”机制
仅有高难度的题目是不够的,如何给一篇几千字、包含大量引用和图表分析的专业报告打分?这是该论文最大的技术贡献之一。
研究者提出了一套名为 MMDR-Eval 的统一评估管道,包含三个核心模块,依次对报告进行深度“体检”。
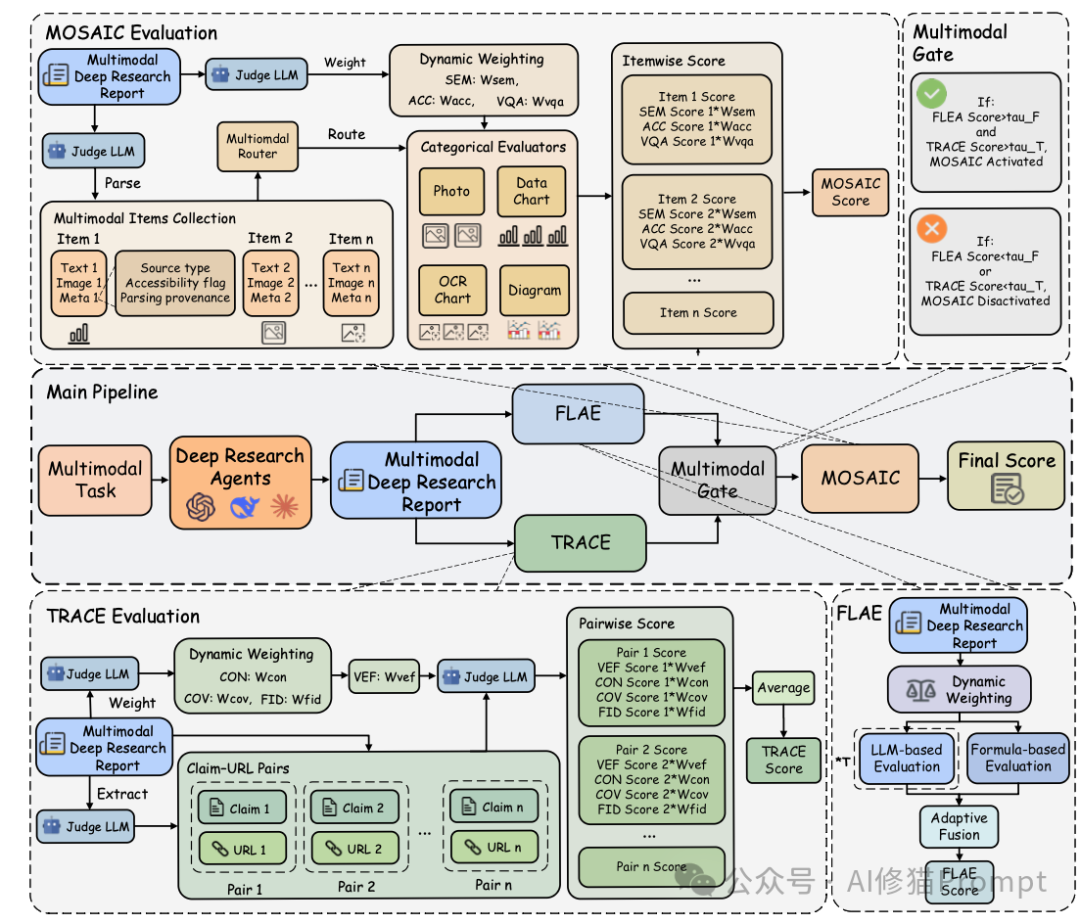
第一关:FLAE - 报告写得像样吗?
FLAE (Formula-LLM Adaptive Evaluation) 主要负责评估长篇报告的整体质量。写报告这件事,不同领域要求不同。FLAE采用了一种“混合评价”策略:
- 公式化指标:统计词汇多样性、句子结构、排版合规性等硬指标,这部分完全客观、可复现。
- 大模型裁判:利用经过校准的大模型,根据任务的具体领域和要求,动态调整评分权重。
它从三个维度对报告进行打分:
- 可读性 (Readability):文章是否通顺、清晰,逻辑流畅。
- 深刻性 (Insightfulness):是否进行了深度分析、对比和综合,而非简单的信息罗列。
- 结构完整性 (Structural Completeness):章节安排是否合理,是否包含了摘要、分析、结论、参考文献等必要部分。
第二关:TRACE - 引用是瞎编的吗?(核心!)
TRACE (Trustworthy Retrieval-Aligned Citation Evaluation) 是整个评估体系中最核心的部分,在最终得分中权重占比最高(50%)。它不仅检查AI是否找到了信息,更检查AI是否 诚实。
AI生成内容最令人头疼的就是“幻觉”——一本正经地胡说八道。TRACE通过以下步骤进行审计:
- 解析与提取:自动提取报告中的每一个“声明(Claim)”及其对应的“引用链接(URL)”。
- 联网核查:系统会真的去访问那些URL,抓取网页的实际内容。
- 一致性校验:由另一个大模型判断,抓取到的网页内容是否真的支持、证实了AI报告中的观点。
核心创新:视觉证据保真度 (VEF)
在TRACE中,研究者引入了一个极其严格的指标:VEF (Visual Evidence Fidelity)。
- 原理:专家为每个任务预先撰写了“文本化视觉真值”,精确记录了图片中所有客观存在的事实(如具体的数值、物体名称、图表趋势、坐标轴标签)。
- 一票否决制:这是一个硬性的 事实检查。如果AI在报告中对图片内容的描述出现了任何事实性错误(比如把图表里的10% 读成了20%,或者编造了图片里根本没有的物体),那么这一项的得分会直接大幅拉低。
- 目的:强迫AI对视觉证据负责,绝不容忍“看图说话编故事”。
第三关:MOSAIC - 图文逻辑真的通顺吗?
如果报告在前两关的基础质量上达标(得分非零),就会触发 MOSAIC (Multimodal Support-Aligned Integrity Check)。
这个模块专门检查报告中“文本描述”和“引用的视觉附件”之间的逻辑整合度。因为图表和照片的分析逻辑是不同的,MOSAIC设计了一个 路由机制(Router):
- 数据图表:重点检查报告中引用的数值是否精确,对趋势的解读是否合理。
- 技术图示/架构图:重点检查文本描述的结构关系是否与图中的组件对应正确。
- 普通照片:重点检查语义描述是否与图片内容匹配。
这种分而治之的策略,确保了无论是分析财务报表中的柱状图,还是识别植物学照片中的物种,都能得到公正且有针对性的评价。
参赛选手:25位顶尖AI的华山论剑
研究者在2024年底到2025年初的测试窗口期内,选取了25个最具代表性的系统进行评测,并将它们分为三个梯队:
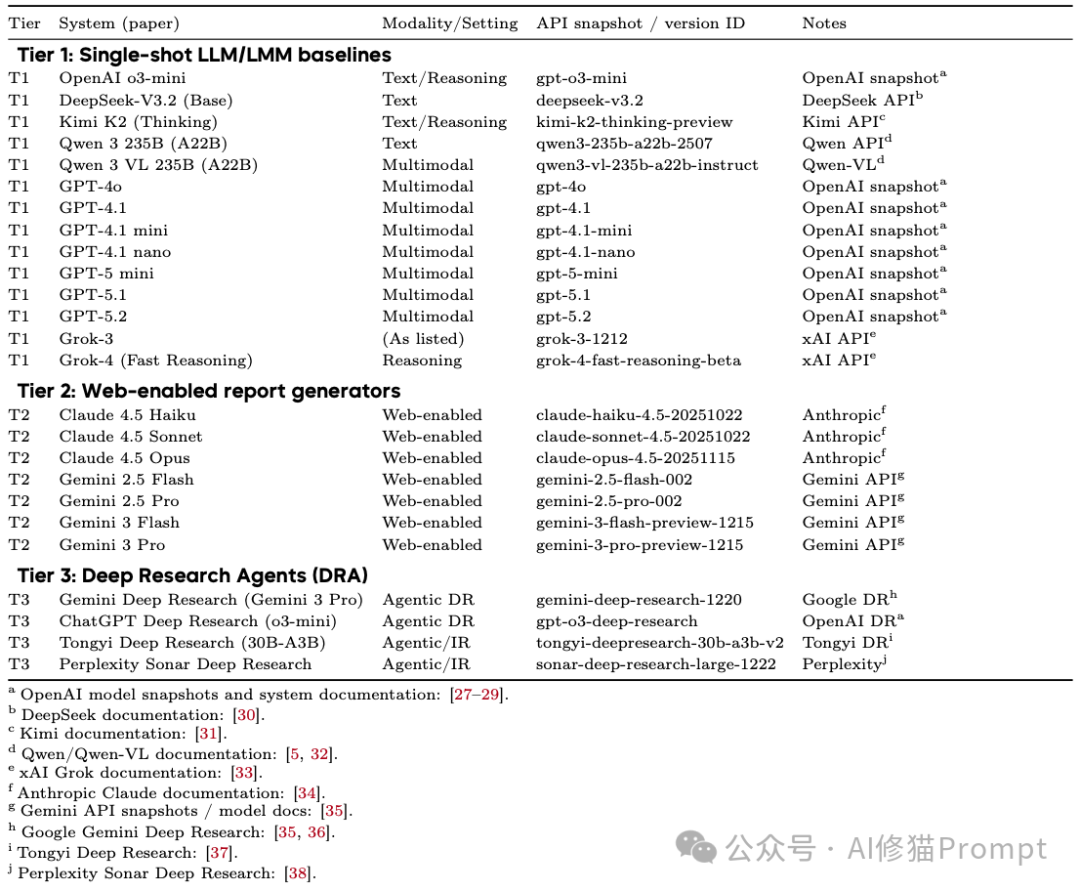
- 单模态基准(Tier 1):
- 代表:DeepSeek-V3.2, Qwen 3 (235B), OpenAI o3-mini。
- 特点:没有联网搜索能力,纯靠模型内建知识进行推理,作为基线参考。
- 联网多模态模型(Tier 2):
- 代表:GPT-4.1/5.1/5.2 系列, Claude 4.5 系列, Gemini 2.5/3 系列。
- 特点:具备内置的浏览器工具,可以看图并自主搜索,是目前最主流的高级应用模式。
- 深度研究智能体(Tier 3):
- 代表:Gemini Deep Research, ChatGPT Deep Research, 通义Deep Research, Perplexity Sonar Deep Research。
- 特点:专门为深度研究设计的智能体系统,能够自主规划多步搜索、整合分析大量来源并撰写结构化的长篇报告。
战况揭晓:深度解析总排名榜单
实验结果不仅是一个简单的排名,更揭示了当前顶尖AI模型在深度研究任务上的 能力断层 与 领域特化。
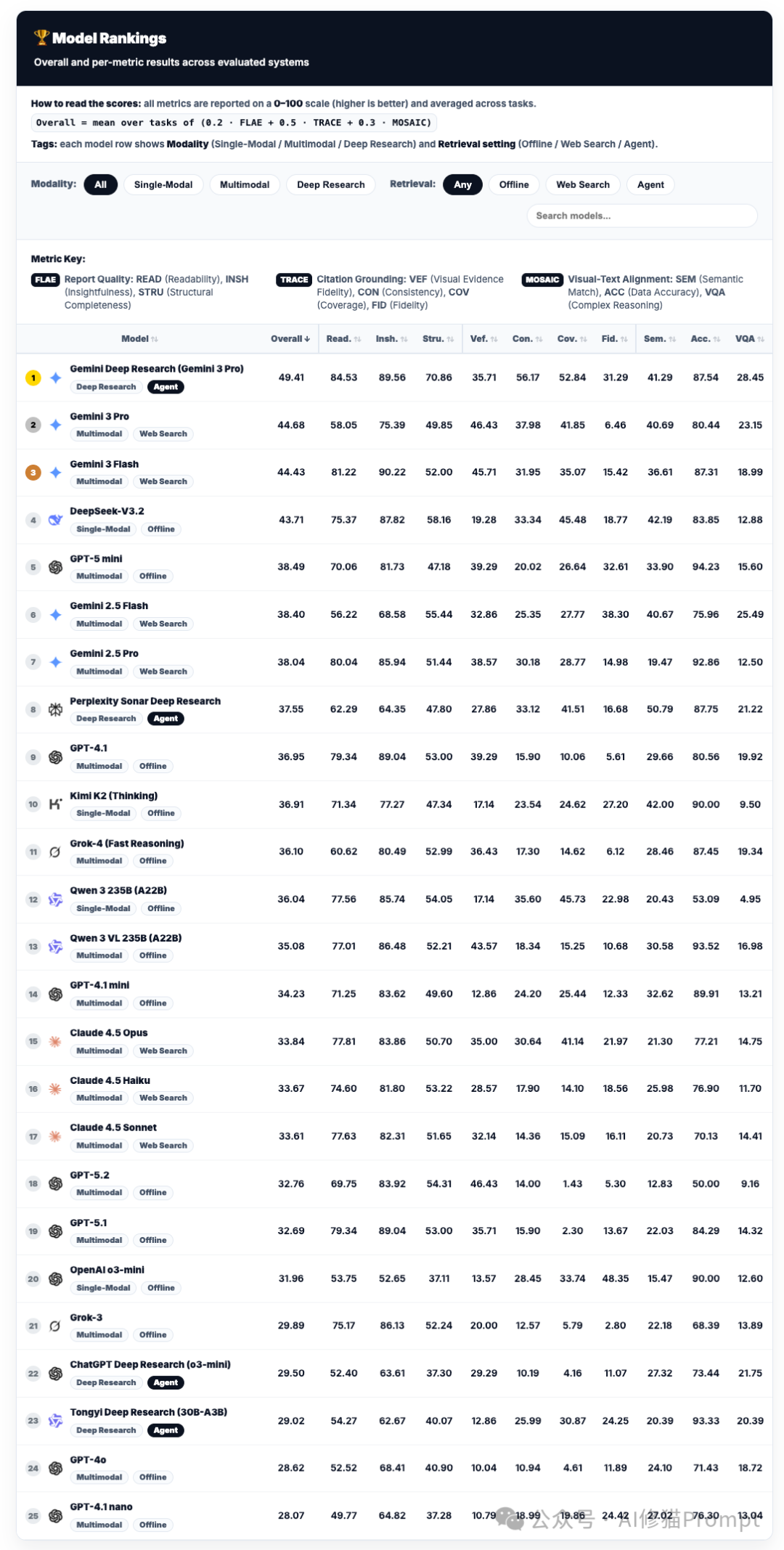
如何读懂排名?理解三大核心权重
在看具体名次之前,你需要理解决定最终分数的三个核心评估模块及其权重,这直接决定了模型的胜负手:
- FLAE (权重 20%):评估 “写作”能力。看报告写得是否漂亮、深刻、结构完整。
- TRACE (权重 50%):评估 “实锤”能力。这是重头戏,考察引用是否真实存在以及是否忠实于原文。其中的 VEF (视觉证据保真度) 是专门针对多模态的“测谎仪”,如果模型对着图表胡说八道,此项得分会极低。
- MOSAIC (权重 30%):评估 “图文对齐”能力。考察文本描述与插入的图表、数据是否在逻辑和语义上严丝合缝。
榜单梯队分析:谁在领跑?谁被高估?
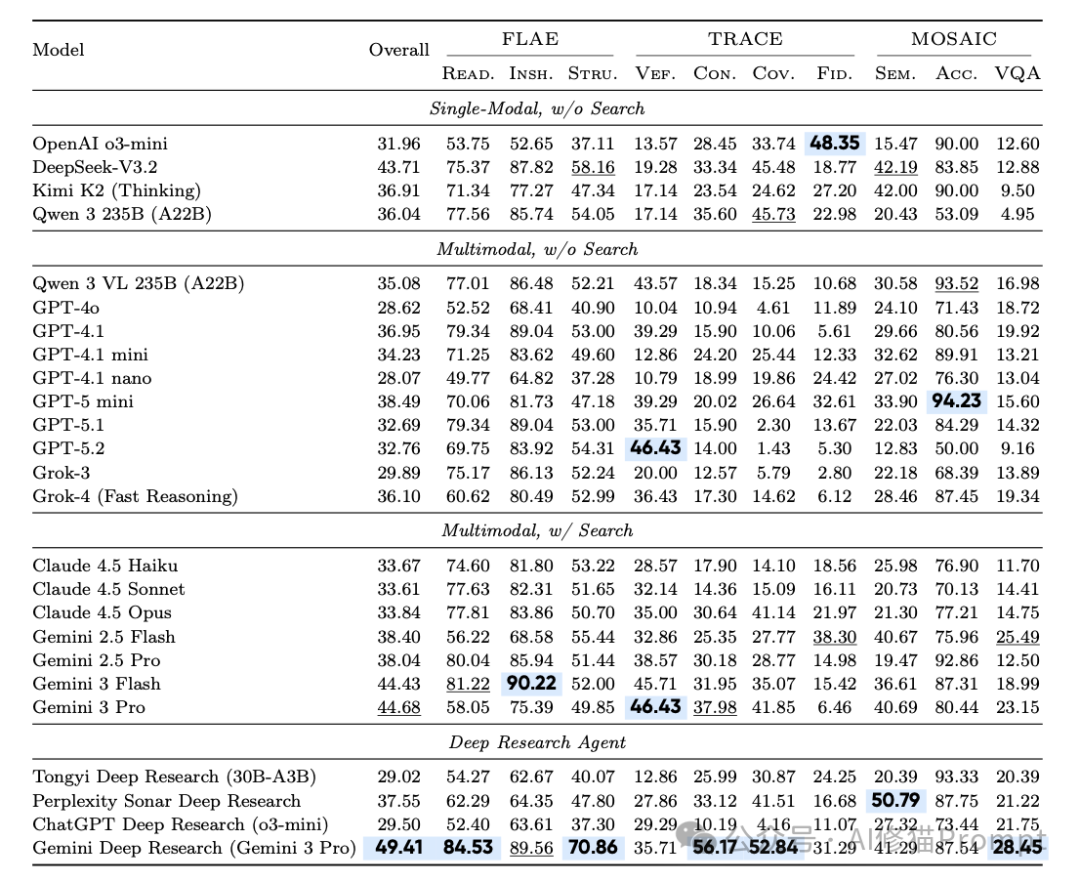
第一梯队:Gemini家族的统治级表现
榜单前三名被Google包揽,展现了其在长上下文理解与多模态深度整合上的深厚技术积累。
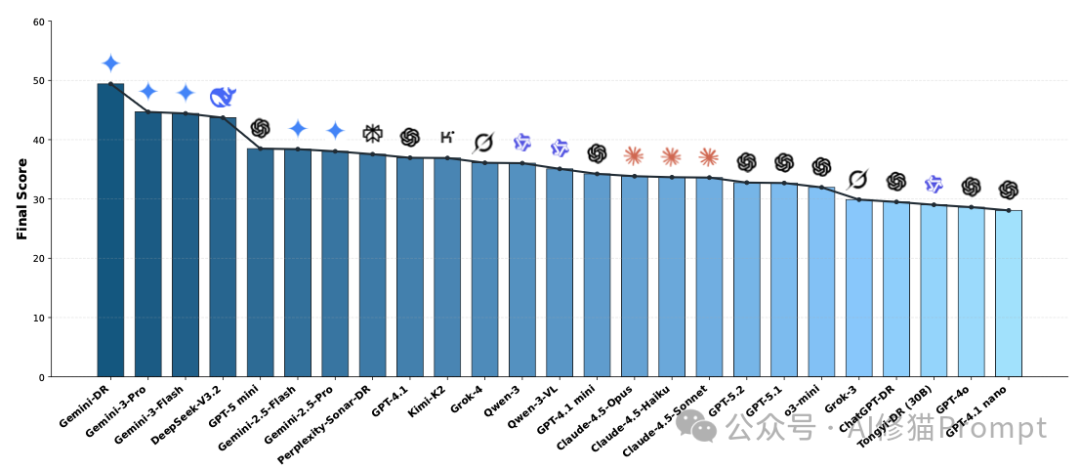
- Gemini Deep Research (智能体) 以 49.41 的高分断层第一。作为专门设计的智能体,它在 Cov. (证据覆盖率) 上拿到了惊人的52.84分,意味着它搜得最广、查得最全。
- Gemini 3 Pro 作为非智能体的单体模型,拿到了 44.68 分。它是目前最强的“即插即用”型模型,如果你没有资源或需求去搭建复杂的智能体框架,它就是闭源模型中的首选。
最大的黑马:DeepSeek-V3.2的“盲打”奇迹
请注意榜单的第4名:DeepSeek-V3.2(43.71分)。这是一个极具冲击力的结果。关键在于它的标签:Single-Modal (单模态) 和 Offline (离线)。
- 这意味着什么? 它是在“看不见任务图片”(仅提供文本描述)且 “不能上网” 的情况下,仅凭模型内部庞大的知识库和强大的推理能力,击败了几乎所有能够联网搜索的GPT系列和Claude系列模型。
- 得分拆解:它依靠极高的 FLAE分数(写作与洞察力) 和扎实的逻辑推理,硬生生弥补了VEF(因看不见图)的低分。这证明了其基座模型本身的推理密度极高,堪称开源/低成本模型中的“推理之王”。
偏科的专家:GPT系列的滑铁卢与价值重估
你可能会惊讶地发现,GPT-5.2 在总榜上仅排第 18 名(32.76分),而 GPT-4o 甚至排在第24名。
- 为什么总分这么低? 看一眼其 Cov. (证据覆盖率) 数据:GPT-5.2只有 1.43。这说明在本次测试的严格设定下,它的联网搜索工具策略可能过于保守或失效,几乎没有成功检索到足够的外部网页来支持其报告,导致TRACE分数雪崩。
- 那它还有什么价值? 别被总分骗了。看它的 VEF (视觉证据保真度) 得分高达 46.43,位居所有模型前列;同时其 Acc. (数据准确性) 表现也很扎实。
- 结论:GPT系列(尤其是5.2)在本次评测的“广泛搜集资料”环节表现不佳,但在“精准阅读复杂图表”和“基于给定信息进行严谨推理、不胡说八道”方面,它依然是顶尖专家。如果你的核心需求是分析本地上传的复杂科研图表、技术图纸,并生成高质量的分析,而非进行开放式网络调研,它依然是极佳的选择。
智能体 vs. 单体模型:价值与代价
对比 第1名 (Gemini 智能体) 和 第2名 (Gemini 3 Pro 单体模型),我们可以看到专门设计智能体架构的真实价值与局限:
- 显著优势:智能体架构将证据覆盖率(Cov.)从41.85显著提升到了52.84,证明其多步搜索规划能力确实能搜集到更全面的信息。
- 未提升甚至下降的方面:智能体的复杂流程 并没有 显著提升核心的视觉理解准确率(VEF得分反而从46.43降到了35.71)。
- 启示:智能体能帮你找到更多、更广的资料,但并不能提高模型底层“读图”和“理解”的准确率。甚至,由于处理链路变长,可能引入新的错误或噪音。
深度洞察:光鲜报告背后的三大隐忧
除了排名,研究者通过深入的错误模式分析,挖掘出了三条发人深省、可能颠覆你认知的规律。
发现一:视觉能力是一把双刃剑
你可能天然认为,给模型加上“眼睛”(视觉能力),它的表现一定比纯文本模型好。但实验数据告诉我们:未必,有时反而更差。
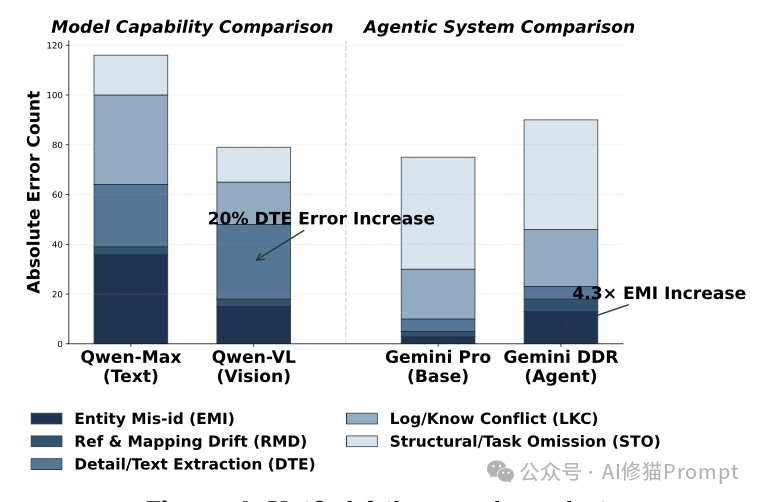
- 数据对比:对比同家族的Qwen 3(纯文本)和Qwen 3-VL(多模态),引入视觉模块后,综合分数并没有实现单调上涨。
- 原因分析:视觉模块本身成为了新的错误源。多模态模型在细节/文本提取上的错误率反而上升了。
- 典型失败模式:模型经常读错图表或图片中的细微文字、数字(Literals),比如把“2023”误读为“2025”,或者点错小数点位置。
- 严重后果:这种视觉上的微小误读,会被模型当作推理的“铁证”前提,进而通过后续的推理链条被不断放大,最终导致整篇报告的结论南辕北辙。只有当图片提供了不可替代的关键证据且模型恰好读对时,视觉才是加分项;否则,它就是引入噪音和错误的“拖累”。
发现二:端到端深度研究是系统级能力,与写作技巧脱钩
“优美的文笔并不能保证对证据的忠实使用。” 这是论文中的一句关键结论。许多模型(如GPT-5.2)能写出结构清晰、文笔流畅甚至颇具深度的文章,甚至在单纯的视觉识别(VEF)上也能拿高分,但在最体现研究严谨性的引用规范性(TRACE)上却表现平平。这说明,优秀的写作能力 与 严谨的循证研究能力 在当前的模型中是两套不同的能力。模型往往为了追求文章的通顺和结构的完整,而在不知不觉中牺牲了对证据源的严格追溯和准确关联。
发现三:智能体的“长链路信息漂移”效应
深度研究智能体通常被认为比单一模型更强,因为它们可以进行多轮迭代搜索、自我修正。但实验发现了一个反直觉的陷阱:
- 实体错配错误激增:相比于基础模型(Gemini Pro),其对应的智能体版本(Gemini Deep Research)在 实体识别错误 上竟然激增了 4.3倍。
- 为什么? 这是一个典型的“长电话传话”效应。智能体在进行多轮搜索、总结摘要、再整合搜索的过程中,信息经过了多次“转手”和重新编码。
- 典型案例:模型在第一轮正确识别并引用了A公司的财报数据,但在第三轮搜索整合B公司的市场份额时,在长上下文理解中混淆了信息主体,最终在报告里张冠李戴,把A公司的数据错误地归因给了B公司。
- 启示:智能体工具的使用虽然提升了证据的覆盖面,但如果不解决长链条、多步骤任务中的 信息锚定与溯源 问题,推理链越长,步骤越多,核心事实出错的概率反而可能越大。
领域分析:术业有专攻,没有全能冠军
在不同的任务领域,各家模型的表现也大相径庭,选择模型时必须考虑具体场景。

- 日常琐事场景:
- 面对屏幕截图、生活照等“充满噪声”的非正式图片,Gemini 2.5 Flash 和 GPT-5.2 表现最为稳定可靠。
- Claude 4.5 Opus 在需要给出具体建议、推荐和深入解释的类别上(如健康、购物建议)依然非常有竞争力。
- 硬核科研场景:
- 在环境科学、能源科学等需要大量解读复杂数据图表、示意图的领域,Qwen 3 VL 235B 展现出了惊人的实力,这很可能与其在科学图表阅读上的特化训练有关。
- 在计算机科学、数据科学等高度结构化、逻辑严谨的技术领域,GPT-5.2 达到了其性能顶峰,尽管其总分不高,但在这些特定领域内其精准的图表分析和推理能力得以充分发挥。
案例剖析:从“不及格”报告看严苛评分
为了更直观地理解MMDR-Bench的评分标准,我们来看论文附录中两个具体的 计算机与数学工程领域 的报告案例。它们清晰地展示了,在博士级难度的任务面前,模型是如何得分和失分的。
案例A:Grok-4 - 强推理,弱在引用把关
- 任务:边缘设备大模型部署的端到端延迟预算分析。要求根据提供的GPT架构图、注意力机制图和Amdahl定律图表,计算理论加速比并提出优化策略。
- 报告得分:82(属于中等偏下)。

- 表现亮点:
- 视觉识别精准:准确提取了架构图中的关键组件和注意力计算公式,没有产生幻觉。
- 硬核计算正确:正确应用Amdahl定律公式,并基于图表数据进行了准确的数学推导,得出了“即使将注意力部分加速8倍,总加速比也只有约1.54倍”的关键结论。
- 决策建议可行:基于计算,提出了采用INT4量化、优化KV缓存等切实的部署建议。
- 核心扣分点:
- 引用源质量瑕疵:评审发现,其参考文献列表中混入了“一小部分来自非授权或低质量来源的链接”。在MMDR-Bench的TRACE标准下,引用源的权威性和可信度是硬性指标,这直接导致了扣分。
案例B:Gemini-2.5-Pro - 教科书级的严谨
- 任务:类别不平衡下的二分类器校准。要求结合混淆矩阵和ROC曲线图,分析不同评估指标的变化。
- 报告得分:85(优于Grok-4)。

- 表现亮点:
- 专业定义无幻觉:对ROC曲线和精确率-召回率曲线给出了教科书般准确、科学的定义。
- 深刻的数据洞察:不仅读图,还通过数学公式推导(如 Precision = TP/(TP+FP)
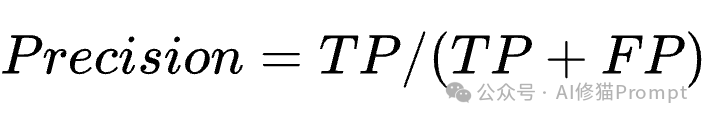 ),深刻指出了ROC曲线在类别不平衡下的局限性,并进行了数据演示。
),深刻指出了ROC曲线在类别不平衡下的局限性,并进行了数据演示。
- 完美的引用实践:提供的参考文献列表被标记为“权威且可访问”,所有引用均指向谷歌官方开发者文档、NIH(美国国立卫生研究院)论文库、Scikit-learn官方文档等高质量可信源,且严格、清晰地对应文中的每一个技术声明。
总结与选型建议
这篇严谨的论文告诉我们,评价一个AI是否真的“智能”,不能只看它聊天是否风趣,更要看它面对真实研究任务时是否足够 严谨、诚实、可靠。
基于以上分析,我们可以得出更精细的选型策略:
- 追求综合最优,需要写带引用的深度报告:首选 Google Gemini Deep Research(智能体版)。它在信息覆盖率和报告完整性上优势明显。
- 即开即用,处理一般性多模态研究问题:选择 Google Gemini 3 Pro。它是单体模型中的王者,省去了配置智能体的复杂度。
- 预算有限,或任务以强逻辑推理为主,视觉为辅:强烈考虑 DeepSeek-V3.2。其离线状态下展现出的强大推理能力令人惊叹,性价比极高。
- 核心需求是精准分析本地的复杂科学/技术图表:GPT-5.2 或 GPT-4.1 系列依然是专家。尽管它们搜得不多,但看得准、想得深。
- 处理生活类截图、寻求建议和解释:Gemini 2.5 Flash 或 Claude 4.5 Opus 是稳健的选择。
- 针对特定领域的科学图表分析:在环境、能源等领域,可以尝试 Qwen 3 VL;在计算机科学领域,GPT-5.2 有独特优势。
最后需要强调的是,在AI能够完美通过MMDR-Bench这种级别考验之前,当我们阅读一份由AI生成的、包含复杂图表分析的“深度报告”时,务必保持一份技术人的审慎。记得去点开那些引用链接,交叉验证一下,看看这位“AI研究员”是不是真的读懂了那张图,还是只是在完成一次华丽的“看图说话”。
技术的发展日新月异,评测标准也在不断演进。希望这份基于前沿研究的解读,能帮助你在云栈社区的技术探索之路上,做出更明智的工具选择。
 发表于 2026-1-27 01:21:00
|
查看: 188|
回复: 0
发表于 2026-1-27 01:21:00
|
查看: 188|
回复: 0
