简介
QAnything 是一款专注于文档问答与检索增强生成(RAG)的开源系统。本文将从入口脚本 run.sh 入手,逐步拆解其在本地模式下的启动流程,分析各个核心组件(如 etcd、minio、OCR、Embedding、Rerank、Milvus、MySQL、qanything_local)的职责、调用时机,并分享一些排障与性能优化的思路,旨在帮助进行二次开发或运维的伙伴能快速定位问题与优化系统。
入口脚本(run.sh)
启动通常从一个简单的命令开始。例如,在一台配备单张 A40 显卡(该卡不支持默认的 Triton 推理后端)的虚拟机上,我们可能执行如下命令:
bash run.sh -c local -i 0 -b vllm -m Qwen-7B-QAnything -t qwen-7b-qanything -p 1 -r 0.85
这条命令的含义是:在本地运行模式下,使用第 0 号 GPU 设备,选择 vLLM 作为大模型推理后端,加载名为 Qwen-7B-QAnything 的模型,使用对应的对话模板,并设置张量并行数为 1,GPU 显存利用率为 85%。
脚本的核心逻辑是:根据你提供的参数,生成并写入一个 .env 环境变量文件,然后通过 docker-compose 拉起名为 qanything_local 的容器。真正的启动流程,是在容器内部执行的另一个脚本中完成的。
容器内启动脚本(关键)
容器启动后,会根据运行模式执行不同的内部脚本:
run_for_local_option.sh(本地模式):当 LLM 在本地运行时调用。它负责按顺序启动 Triton(用于 Embedding 和 Rerank 模型)、LLM 推理服务(当使用 Hugging Face 或 vLLM 后端时)、Rerank 业务服务、OCR 服务以及 Sanic 后端,并执行健康检查与日志跟踪。run_for_cloud_option.sh(云模式):当 LLM 使用外部云服务(如 OpenAI)时调用。此脚本会启动 Embedding/Rerank 的 Triton 服务、Rerank 服务、OCR 服务和 Sanic 后端,但不会启动本地的 FastChat(LLM)模块。
这些脚本会读取 .env 文件中的配置,例如:
LLM_API=local
MODEL_NAME=Qwen-7B-QAnything
DEVICE_ID=0
RUNTIME_BACKEND=vllm
CONV_TEMPLATE=qwen-7b-qanything
TP=1
GPU_MEM_UTILI=0.85
OCR_USE_GPU=True
OFFCUT_TOKEN=0
RERANK_PORT=9001
EMBED_PORT=9001
MODEL_SIZE=7B
GPUID1=0
GPUID2=0
USER_IP=localhost
LLM_API_SERVE_PORT=7802
LLM_API_SERVE_MODEL=Qwen-7B-QAnything
LLM_API_SERVE_CONV_TEMPLATE=qwen-7b-qanything
Step1:运行环境检查
脚本首先会对运行环境进行诊断:
- 查询 GPU 型号与算力,检查并计算可用显存,判断是否足以部署所选的
MODEL_SIZE(如 7B 模型)。
- 根据 GPU 的算力和显存情况,尝试自动调整推理后端。例如,如果默认后端不支持当前 GPU,理论上应自动切换到 vllm 或 hf 后端(有时自动切换可能不生效,需要手动指定)。
Step2:加载 Embedding 和 Rerank 模型
这一步启动 Triton Inference Server。需要明确的是,Triton 是一个高性能的模型推理服务器,它通过 gRPC/HTTP 接口提供模型推理服务。它的职责是高效地加载并执行模型(如 Embedding 模型、Rerank 模型),但它不负责业务级的流程编排、检索或请求处理逻辑。
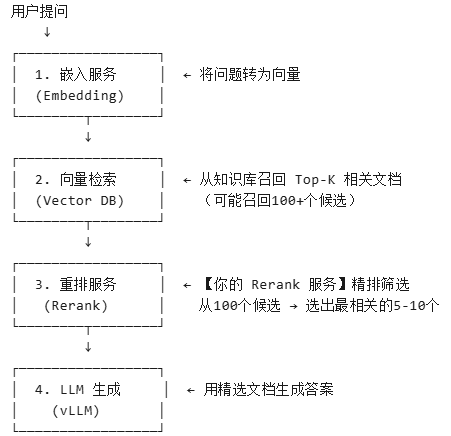
Rerank(重排) 是 RAG 系统中至关重要的“精筛器”。在检索出大量相关文档后,Rerank 模型会对它们进行精细排序,筛选出最相关的几条,从而显著提升大模型生成答案的准确性和相关性。下图清晰地展示了其在 RAG 流程中的位置:
Step3:启动 LLM 推理后端(以 vLLM Worker 为例)
对于本地运行,这是启动流程的核心步骤之一。QAnything 使用 FastChat 框架来管理 LLM 服务,并结合 vLLM 引擎以实现高性能推理。下面是一个启动 vLLM Worker 的典型命令:
CUDA_VISIBLE_DEVICES=0 python3 -m fastchat.serve.vllm_worker \
--host 0.0.0.0 --port 7801 \
--controller-address http://0.0.0.0:7800 \
--worker-address http://0.0.0.0:7801 \
--model-path /model_repos/CustomLLM/Qwen-7B-QAnything \
--trust-remote-code \
--block-size 32 \
--tensor-parallel-size 1 \
--max-model-len 4096 \
--gpu-memory-utilization 0.85 \
--dtype bfloat16 \
--conv-template qwen-7b-qanything
这个服务主要做三件事:
- 模型加载:从指定路径加载
Qwen-7B-QAnything 模型,使用 vLLM 引擎(采用 PagedAttention 等技术)初始化,并按配置分配 GPU 显存。
- 推理服务:在端口 7801 上提供 HTTP API,接收
text_generation 或 chat_completion 请求,并利用 vLLM 进行高性能的批量推理。
- 与 Controller 通信:向 FastChat Controller(运行在端口 7800)注册自己,并接收任务调度、上报负载状态。

Step4:启动 Rerank 本地服务
注意,这里启动的 Rerank “服务”与 Step2 中 Triton 加载的 Rerank “模型”是不同的。Triton 只负责运行模型计算,而 Rerank 服务是一个业务逻辑处理单元。它的职责包括:接收请求 -> 调用 Embedding 模型 -> 进行向量检索(访问 Milvus 或 FAISS)-> 收集候选文档 -> 调用 Triton 中的 Rerank 模型进行评分 -> 合并分数并返回重排结果。它是串联整个检索精排流程的业务枢纽。
Step5:启动 OCR 服务
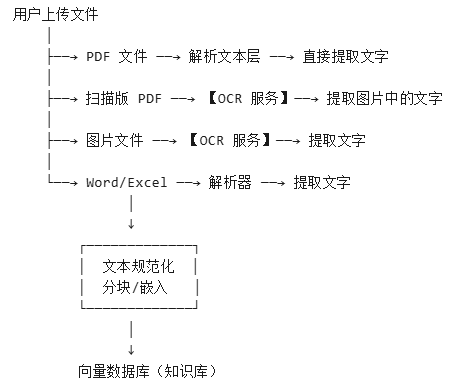
OCR(光学字符识别)是 QAnything 能够处理非纯文本文档(如扫描版 PDF、图片)的关键。它将这些文件中的视觉文字信息转换为可被检索和理解的文本数据。其在文档处理流程中的位置如下:
Step6:启动 QAnything 后端服务(Sanic)
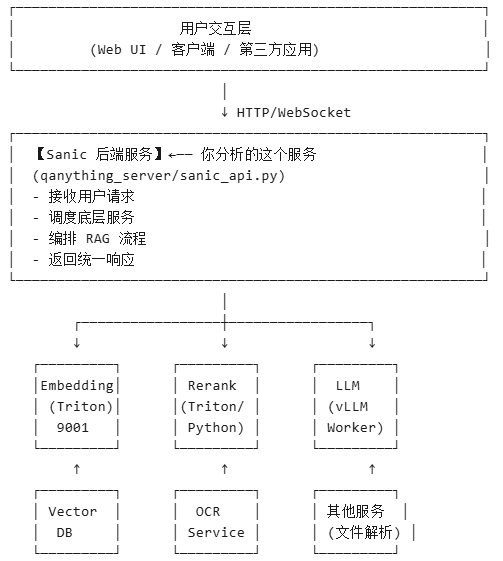
这是整个系统的“大脑”和指挥中心,一个基于 Sanic 框架构建的 Web 后端服务。它负责接收用户请求(通过 HTTP/WebSocket),然后协调调度上述所有组件(Embedding、向量数据库、Rerank、LLM、OCR 等),完整地编排整个 RAG 流程,最后将统一的响应返回给前端或客户端。
Step7:启动后检查
所有组件启动完毕后,脚本会执行最终的健康检查,确认 Rerank 服务、OCR 服务、Sanic 后端等关键组件是否都已正常监听端口并准备就绪。
结语
本文以 run.sh 启动脚本为线索,详细梳理了 QAnything 在本地模式下各组件的启动顺序与协作关系。理解这套启动流程,就像是拿到了一份系统的“启动蓝图”,对于后续深入学习各组件源码、梳理项目整体架构,以及在技术文档层面进行问题排查和性能调优都至关重要。
 发表于 2026-1-27 02:03:25
|
查看: 199|
回复: 0
发表于 2026-1-27 02:03:25
|
查看: 199|
回复: 0
