免责声明:本文所有内容仅用于交流学习,不构成任何投资建议!投资有风险,入市需谨慎!
策略介绍
什么是板块轮动策略?
板块轮动策略是金融市场中一种主动型投资方法,其核心在于通过系统性分析,识别并投资于即将进入上升周期的行业或主题板块,同时减持或避开预计将走弱的板块,从而实现超越市场平均水平的投资回报。
这一策略的立论基础源于宏观经济周期理论、产业生命周期理论以及市场行为金融学。从宏观视角看,经济的周期性波动(复苏、繁荣、衰退、萧条)会以不同方式和时序影响各个行业。例如,在经济复苏初期,对利率敏感的金融、房地产以及代表基础需求的周期性板块(如原材料、工业)通常率先反应;当经济进入繁荣期,科技、消费等成长性板块可能表现突出;而在经济下行或衰退时,公用事业、必需消费品等防御性板块则显现出相对的韧性。这一经典规律常被总结为如“美林投资时钟”等理论模型。
从市场微观结构看,投资者的情绪和偏好会随时间推移在不同板块间流转,形成“热点”的转换。这种轮动可能由多种因素驱动:产业政策(如国家对新能源、人工智能的扶持)、技术革命、社会趋势或事件冲击。板块的相对强弱本质上反映了市场对未来现金流预期的集体调整。
传统策略的挑战与量化思路
传统板块轮动策略主要依赖基本面分析(跟踪宏观经济指标、行业数据)和技术面分析(运用相对强度、动量指标等)。然而,这些方法面临显著挑战:宏观信号存在滞后性,技术指标容易产生“噪音”,且现代市场轮动节奏加快,依赖人工经验或单一维度的判断愈发困难。
因此,引入机器学习等量化方法,成为优化板块轮动策略、提高决策客观性和时效性的重要方向。它能够从海量历史数据中挖掘非线性规律和复杂模式,对经济逻辑、市场情绪和资金流向进行前瞻性、概率化把握。
基于机器学习的量化实现框架
一个完整的板块轮动量价策略,通常遵循以下步骤:
- 收集历史数据:获取所有股票的历史调整后收盘价,并按行业或概念分类为不同板块。同时收集市场基准数据。数据需涵盖多个市场周期,确保模型学习的全面性。
- 特征工程:对每个板块构建技术面特征,例如动量指标(过去N个月的收益率)、波动率指标(滚动标准差)以及板块间相对特征。所有特征需使用历史滚动计算,严格避免引入未来信息。
- 构建标签:定义未来一段时间(如未来20个交易日)板块收益率超越市场基准的板块为“强势板块”。这是防止信息泄露的关键,必须确保标签生成仅使用对应时间段前的数据。
- 训练模型:采用如随机森林分类器等模型进行训练。将数据集按时间顺序划分为训练集和测试集,输入板块技术特征,输出板块强势的概率。
- 回测验证:根据模型预测,定期调仓(如每月一次),选择预测概率最高的板块进行配置。回测中需考虑交易成本,并评估年化收益、夏普比率、最大回撤等关键绩效指标。
下面,我们来看看这个框架中的几个核心代码模块是如何具体实现的。
策略实现的关键代码模块
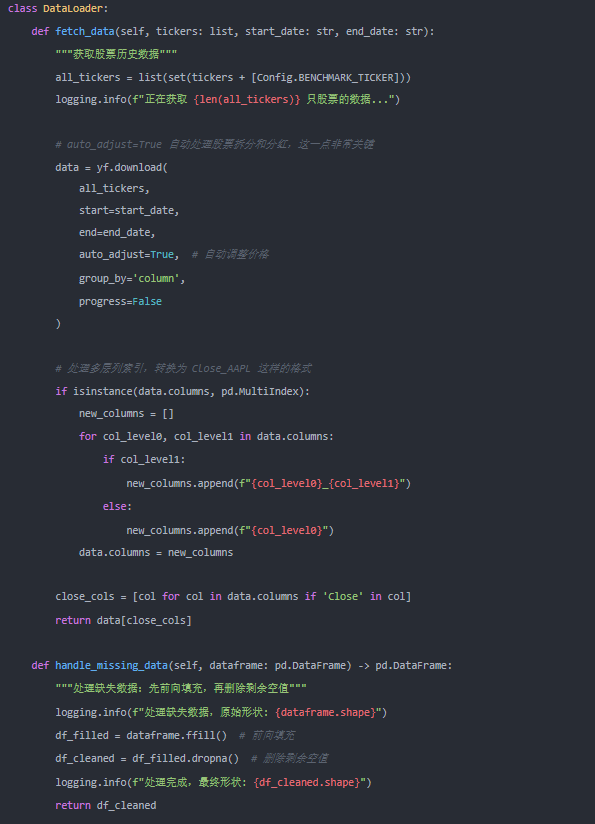
第一步:获取干净的金融数据
数据是量化策略的基石。我们需要一个健壮的 DataLoader 来获取并清洗数据,使用 auto_adjust=True 来自动处理股票拆分和分红是关键一步。
class DataLoader:
def fetch_data(self, tickers: list, start_date: str, end_date: str):
"""获取股票历史数据"""
all_tickers = list(set(tickers + [Config.BENCHMARK_TICKER]))
logging.info(f”正在获取 {len(all_tickers)} 只股票的数据...”)
# auto_adjust=True 自动处理股票拆分和分红,这一点非常关键
data = yf.download(
all_tickers,
start=start_date,
end=end_date,
auto_adjust=True, # 自动调整价格
group_by='column',
progress=False
)
# 处理多层列索引,转换为 Close_AAPL 这样的格式
if isinstance(data.columns, pd.MultiIndex):
new_columns = []
for col_level0, col_level1 in data.columns:
if col_level1:
new_columns.append(f”{col_level0}_{col_level1}”)
else:
new_columns.append(f”{col_level0}”)
data.columns = new_columns
close_cols = [col for col in data.columns if ‘Close‘ in col]
return data[close_cols]
def handle_missing_data(self, dataframe: pd.DataFrame) -> pd.DataFrame:
"""处理缺失数据:先向前填充,再删除剩余空值”
logging.info(f”处理缺失数据,原始形状: {dataframe.shape}”)
df_filled = dataframe.ffill() # 前向填充
df_cleaned = df_filled.dropna() # 删除剩余空值
logging.info(f”处理完成,最终形状: {df_cleaned.shape}”)
return df_cleaned
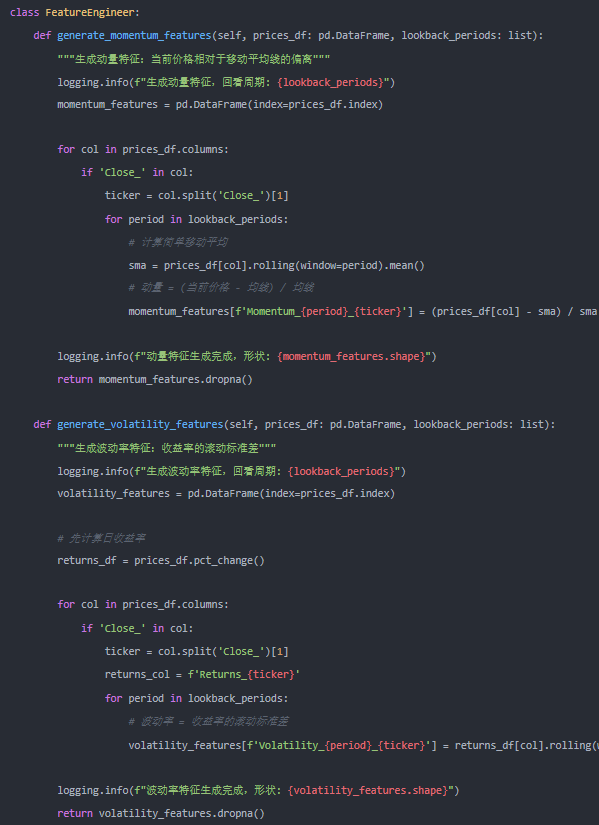
第二步:特征工程——提取市场信号
特征工程决定了模型能“看到”什么。这里我们生成动量和波动率两类经典技术特征。
class FeatureEngineer:
def generate_momentum_features(self, prices_df: pd.DataFrame, lookahead_periods: list):
"""生成动量特征:当前价格相对于移动平均线的偏离”
logging.info(f”生成动量特征,回看周期:{lookahead_periods}”)
momentum_features = pd.DataFrame(index=prices_df.index)
for col in prices_df.columns:
if ‘Close_‘ in col:
ticker = col.split(‘Close_‘)[1]
for period in lookahead_periods:
# 计算简单移动平均
sma = prices_df[col].rolling(window=period).mean()
# 动量 = (当前价格 - 均值) / 均值
momentum_features[f’Momentum_{period}_{ticker}’] = (prices_df[col] - sma) / sma
logging.info(f”动量特征生成完成,形状:{momentum_features.shape}”)
return momentum_features.dropna()
def generate_volatility_features(self, prices_df: pd.DataFrame, lookahead_periods: list):
"""生成波动率特征:收益率的滚动标准差”
logging.info(f”生成波动率特征,回看周期:{lookahead_periods}”)
volatility_features = pd.DataFrame(index=prices_df.index)
# 先计算日收益率
returns_df = prices_df.pct_change()
for col in prices_df.columns:
if ‘Close_‘ in col:
ticker = col.split(‘Close_‘)[1]
returns_col = f’Returns_{ticker}’
for period in lookahead_periods:
# 波动率 = 收益率的滚动标准差
volatility_features[f’Volatility_{period}_{ticker}’] = returns_df[col].rolling(window=period).std()
logging.info(f”波动率特征生成完成,形状:{volatility_features.shape}”)
return volatility_features.dropna()
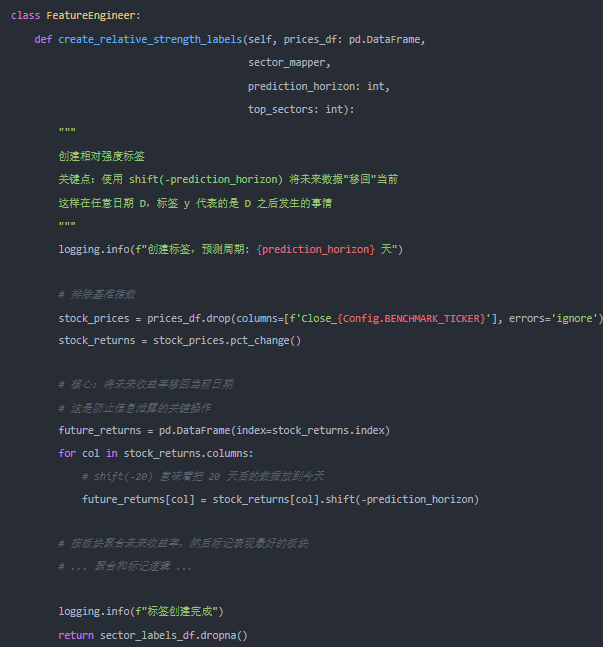
第三步:构建标签——避免未来信息泄露
这是整个流程中最易出错也最关键的环节。我们必须使用 shift(-prediction_horizon) 将未来收益“移回”当前,才能用当前特征预测未来表现。
class FeatureEngineer:
def create_relative_strength_labels(self, prices_df: pd.DataFrame, sector_mapper, prediction_horizon: int, top_sectors: int):
"""
创建相对强度标签
关键点:使用 shift(-prediction_horizon) 将未来数据“移回”当前
这样在任意日期 D,标签 y 代表的是 D 之后发生的事情
"""
logging.info(f”创建标签,预测周期:{prediction_horizon} 天”)
# 除掉基准指数
stock_prices = prices_df.drop(columns=[f‘Close_{Config.BENCHMARK_TICKER}’], errors='ignore')
stock_returns = stock_prices.pct_change()
# 核心:未来收益将移回当前日期
# 这是防止信息泄露的关键操作
future_returns = pd.DataFrame(index=stock_returns.index)
for col in stock_returns.columns:
# shift(-20) 意味着把 20 天后的数据放到今天
future_returns[col] = stock_returns[col].shift(-prediction_horizon)
# 按板块聚合未来收益率,然后标记表现最好的板块
# ... 聚合和标记逻辑 ...
logging.info(f”标签创建完成”)
return sector_labels_df.dropna()
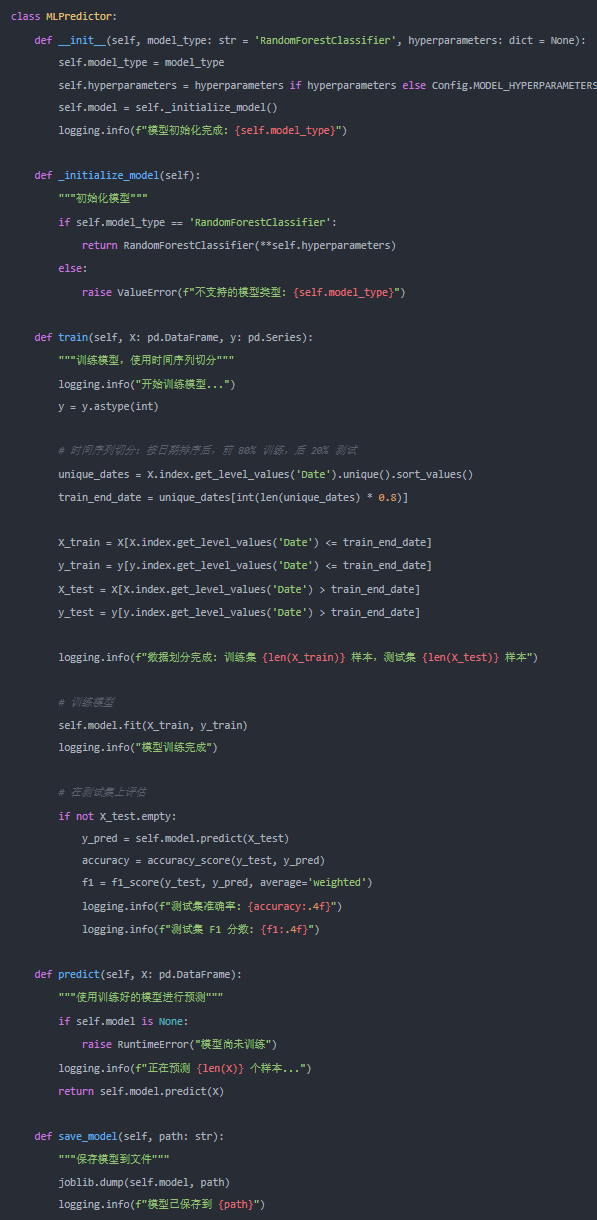
第四步:训练机器学习模型
我们使用随机森林分类器,并采用时间序列划分法(前80%训练,后20%测试)来模拟真实环境下的滚动预测。
class MLPredictor:
def __init__(self, model_type: str = ‘RandomForestClassifier’, hyperparameters: dict = None):
self.model_type = model_type
self.hyperparameters = hyperparameters if hyperparameters else Config.MODEL_HYPERPARAMETERS
self.model = self._initialize_model()
logging.info(f”模型初始化完成: {self.model_type}”)
def _initialize_model(self):
"""初始化模型”
if self.model_type == ‘RandomForestClassifier’:
return RandomForestClassifier(**self.hyperparameters)
else:
raise ValueError(f”不支持的模型类型: {self.model_type}”)
def train(self, X: pd.DataFrame, y: pd.Series):
"""训练模型。使用时间序列划分”
logging.info(”开始训练模型...”)
y = y.astype(int)
# 时间序列划分:按日期排序后,前80% 训练,后20% 测试
unique_dates = X.index.get_level_values(‘Date’).unique().sort_values()
train_end_date = unique_dates[int(len(unique_dates) * 0.8)]
X_train = X[X.index.get_level_values(‘Date’) <= train_end_date]
y_train = y[y.index.get_level_values(‘Date’) <= train_end_date]
X_test = X[X.index.get_level_values(‘Date’) > train_end_date]
y_test = y[y.index.get_level_values(‘Date’) > train_end_date]
logging.info(f”数据划分完成:训练集 {len(X_train)} 样本,测试集 {len(X_test)} 样本”)
# 训练模型
self.model.fit(X_train, y_train)
logging.info(”模型训练完成”)
# 在测试集上评估
if not X_test.empty:
y_pred = self.model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
f1 = f1_score(y_test, y_pred, average='weighted')
logging.info(f”测试集准确率: {accuracy:.4f}”)
logging.info(f”测试集 F1 分数: {f1:.4f}”)
def predict(self, X: pd.DataFrame):
"""使用训练好的模型进行预测”
if self.model is None:
raise RuntimeError(”模型尚未训练”)
logging.info(f”正在预测 {len(X)} 个样本...”)
return self.model.predict(X)
def save_model(self, path: str):
"""保存模型到文件”
joblib.dump(self.model, path)
logging.info(f”模型已保存到 {path}”)
第五步:回测策略
策略引擎模拟真实的交易过程,包括初始资金设定、按调仓频率执行再平衡逻辑。
class StrategyEngine:
def __init__(self, initial_capital: float, rebalance_frequency: int):
self.initial_capital = initial_capital
self.rebalance_frequency = rebalance_frequency
self.portfolio_value = pd.Series(dtype=float)
self.holdings = {}
self.capital = initial_capital
logging.info(f”策略引擎初始化完成,初始资金:${initial_capital}”)
def run_backtest(self, prices_df: pd.DataFrame, sector_predictions_df: pd.DataFrame, sector_mapper: dict):
logging.info(”开始回测模拟...”)
dates = prices_df.index
self.portfolio_value = pd.Series(index=dates, dtype=float)
self.benchmark_value = pd.Series(index=dates, dtype=float)
# 初始化基准价格
initial_spy_price = prices_df.loc[dates[0], f“Close_{Config.BENCHMARK_TICKER}”]
benchmark_shares = self.initial_capital / initial_spy_price
self.benchmark_value.loc[dates[0]] = self.initial_capital
for i, current_date in enumerate(dates):
if i > 0:
# 每天更新最新净值
if self.benchmark_value.loc[current_date] == 0:
# 计算当前日净值(现金 + 股票价值)
current_portfolio_value = self.portfolio_value.iloc[i-1]
for ticker, shares in self.holdings.items():
if f‘Close_{ticker}’ in prices_df.columns:
current_portfolio_value += shares * prices_df.loc[current_date, f‘Close_{ticker}’]
self.portfolio_value.loc[current_date] = current_portfolio_value
# 调整再平衡周期:每rebalance_frequency天执行一次
if i % self.rebalance_frequency == 0:
logging.info(f”调整日期:{current_date.strftime(‘%Y-%m-%d’)}”)
# 获取当日的市场预测数据
if current_date in sector_predictions_df.index.get_level_values(‘Date’):
daily_preds = sector_predictions_df.loc[current_date, ‘Predicted_label’]
top_sectors = daily_preds[daily_preds == 1].index.tolist()
else:
continue
# 选出最值得买入的股票
selected_tickers = []
for sector in top_sectors:
for ticker, s in sector_mapper.items():
if s == sector:
selected_tickers.extend(ticker) # 注意:此处逻辑需根据实际数据结构调整
selected_tickers = list(set(selected_tickers))
# 执行再平衡
self.rebalance_portfolio(current_date, prices_df, selected_tickers)
logging.info(f”回测完成,共执行 {len(self.portfolio_value)} 天/{len(self.portfolio_value)//self.rebalance_frequency} 次调仓”)
logging.info(f”最终组合价值:${self.portfolio_value.iloc[-1]}”)
logging.info(f”最终基准价值:${self.benchmark_value.iloc[-1]}”)
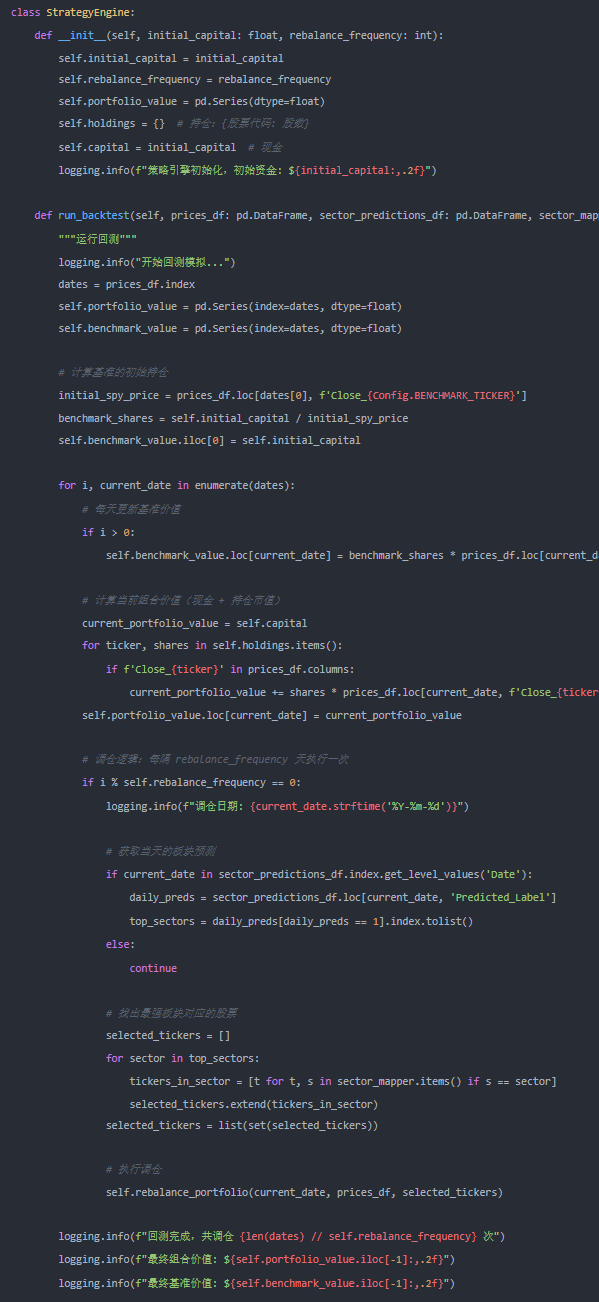
再平衡函数清空现有持仓,并将资金等权分配到新选出的股票中。
def rebalance_portfolio(self, date, prices_df, selected_tickers):
“”“执行调仓:先清仓,再等权买入目标股票”””
# 清仓:卖出所有持仓,全部转为现金
for ticker, shares in self.holdings.items():
if f’Close_{ticker}‘ in prices_df.columns:
self.capital += shares * prices_df.loc[date, f’Close_{ticker}‘]
self.holdings = {}
# 如果有目标股票,等权分配资金买入
if selected_tickers:
allocation_per_stock = self.capital / len(selected_tickers)
for ticker in selected_tickers:
if f’Close_{ticker}‘ in prices_df.columns:
price = prices_df.loc[date, f’Close_{ticker}‘]
shares = allocation_per_stock / price
self.holdings[ticker] = shares
self.capital = 0 # 全部资金买入
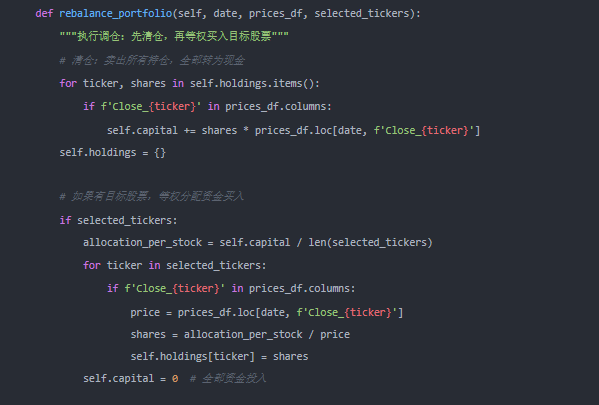
第六步:性能分析
回测结束后,我们需要一个专业的绩效分析器来计算各项关键指标,评估策略的优劣。
class PerformanceAnalyzer:
def calculate_metrics(self, portfolio_returns: pd.Series, benchmark_returns: pd.Series, risk_free_rate: float = 0.02) -> dict:
“”“计算关键绩效指标”””
# 累计收益
cumulative_portfolio = (1 + portfolio_returns).prod() - 1
cumulative_benchmark = (1 + benchmark_returns).prod() - 1
# 年化收益率
years = len(portfolio_returns) / 252 # 假设每年 252 个交易日
cagr_portfolio = (1 + cumulative_portfolio) ** (1 / years) - 1
cagr_benchmark = (1 + cumulative_benchmark) ** (1 / years) - 1
# 年化波动率
vol_portfolio = portfolio_returns.std() * np.sqrt(252)
vol_benchmark = benchmark_returns.std() * np.sqrt(252)
# 夏普比率(年化收益 - 无风险利率)/ 年化波动率
sharpe_portfolio = (cagr_portfolio - risk_free_rate) / vol_portfolio
sharpe_benchmark = (cagr_benchmark - risk_free_rate) / vol_benchmark
# 最大回撤
cumulative = (1 + portfolio_returns).cumprod()
running_max = cumulative.cummax()
drawdown = (cumulative - running_max) / running_max
max_drawdown = drawdown.min()
metrics = {
‘累计收益(策略)’: f‘{cumulative_portfolio:.2%}’,
‘累计收益(基准)’: f‘{cumulative_benchmark:.2%}’,
‘年化收益率(策略)’: f‘{cagr_portfolio:.2%}’,
‘年化收益率(基准)’: f‘{cagr_benchmark:.2%}’,
‘夏普比率(策略)’: f‘{sharpe_portfolio:.2f}’,
‘夏普比率(基准)’: f‘{sharpe_benchmark:.2f}’,
‘最大回撤(策略)’: f‘{max_drawdown:.2%}’
}
for k, v in metrics.items():
logging.info(f‘{k}: {v}’)
return metrics
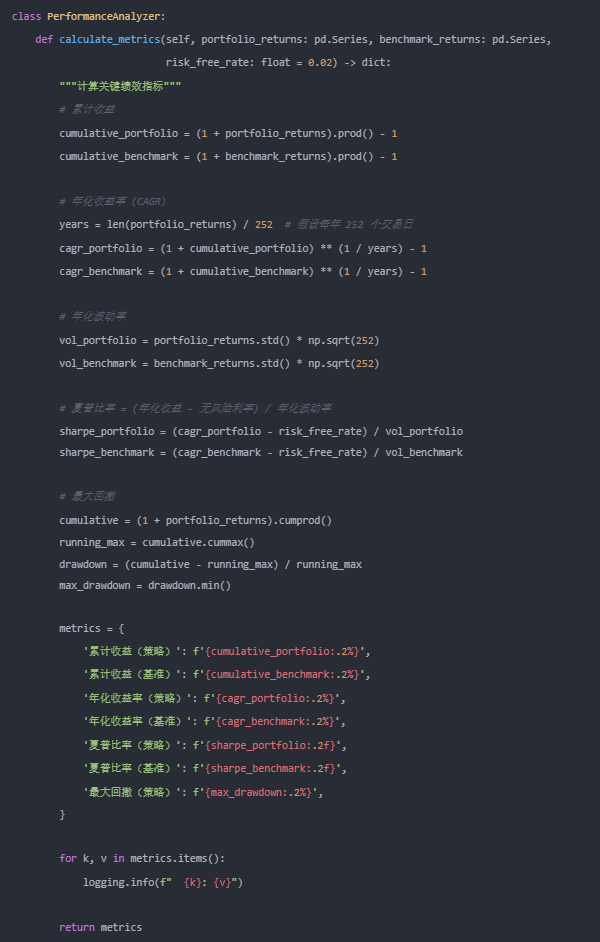
回测效果
经过完整的回测流程后,我们可以得到一份详细的绩效对比报告。以下为模拟回测结果(仅供参考,不代表实际收益):
| 指标 |
策略 |
基准(SPY) |
| 累计收益 |
33.19 倍 |
1.45 倍 |
| 年化收益率 |
65.86% |
13.70% |
| 夏普比率 |
2.39 |
0.66 |
| 最大回撤 |
-27.09% |
-33.72% |
| Alpha |
39.46% |
— |
总结与思考
通过上述模块化的代码实现,我们完成了一个基于机器学习的板块轮动策略从数据到回测的全流程。关键在于三点:一是构建严谨、无信息泄露的特征与标签体系;二是选用适合处理金融时间序列非线性关系的模型(如随机森林);三是采用符合现实的时间序列划分方法进行回测。
当然,这只是一个基础的框架示例。在实际应用中,还需要考虑更多因素,例如:加入更多元的基本面与另类数据特征、使用更复杂的集成模型或深度学习模型、优化调仓逻辑与风险管理、进行更严格的过拟合检验等。量化策略的开发是一个不断迭代和优化的过程。
希望这个基于 Python 的完整实现思路能为你带来启发。如果你对量化交易、机器学习在金融领域的应用有更多想法,欢迎在云栈社区与其他开发者交流探讨。
 发表于 2026-1-27 03:57:01
|
查看: 279|
回复: 0
发表于 2026-1-27 03:57:01
|
查看: 279|
回复: 0
