就在今天凌晨,Kimi团队现身Reddit上最硬核的本地大模型社区 r/LocalLLaMA,进行了一场长达数小时的AMA(Ask Me Anything,有问必答)活动。

这场与全球开发者及AI爱好者的直接对话信息量巨大,既解答了诸多技术疑问,也让开发团队清晰地看到了用户对Kimi模型的期待与建议。

社区内普遍猜测,用户“ComfortableAsk4494”(在截图中被红框标出)极有可能就是月之暗面(Moonshot AI)的创始人杨植麟本人。虽然未获官方证实,但从其在回答中的排序位置以及对战略性问题回复的深度来看,这一猜测不无道理。
此次交流正值Kimi K2.5模型发布并取得一系列亮眼成绩之后。该模型在智能体(Agent)、代码、视觉理解及一系列通用任务上均展现了强大的性能。
在最新的Artificial Analysis榜单中,Kimi K2.5位列全球开源模型第一,总排名第五。
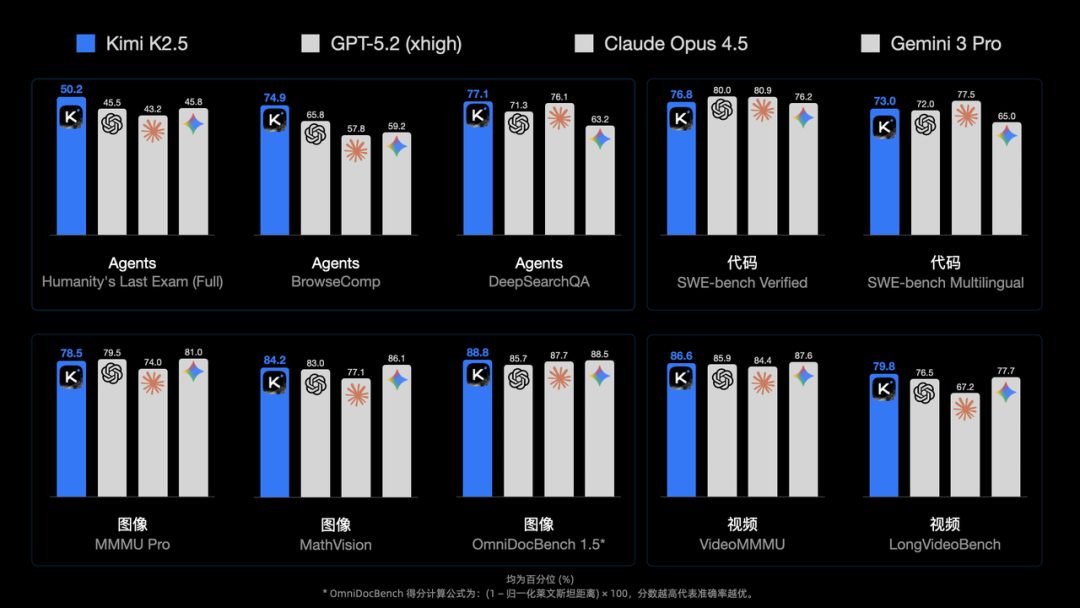
在大模型竞技场LMarena的编码能力排行榜上,Kimi K2.5同样摘得开源模型桂冠,总榜位列第七。

在社交媒体上,K2.5的发布也引发了广泛讨论。
整场AMA远不止于技术问答,更像是一场全球开源开发者的大型线上聚会。讨论内容从深度的模型架构探讨,到欧洲用户收不到验证码的“卑微”求助,覆盖了技术、产品与社区的方方面面。
以下是本次AMA交流中部分精华内容的梳理与解读。
一、关于模型蒸馏与身份的争议
Kimi K2.5发布后,有用户发现模型在特定情况下会自称为“Claude”,引发了关于其是否大量蒸馏自Claude模型的讨论。对此,团队核心成员(用户ComfortableAsk4494)给出了直接回应。
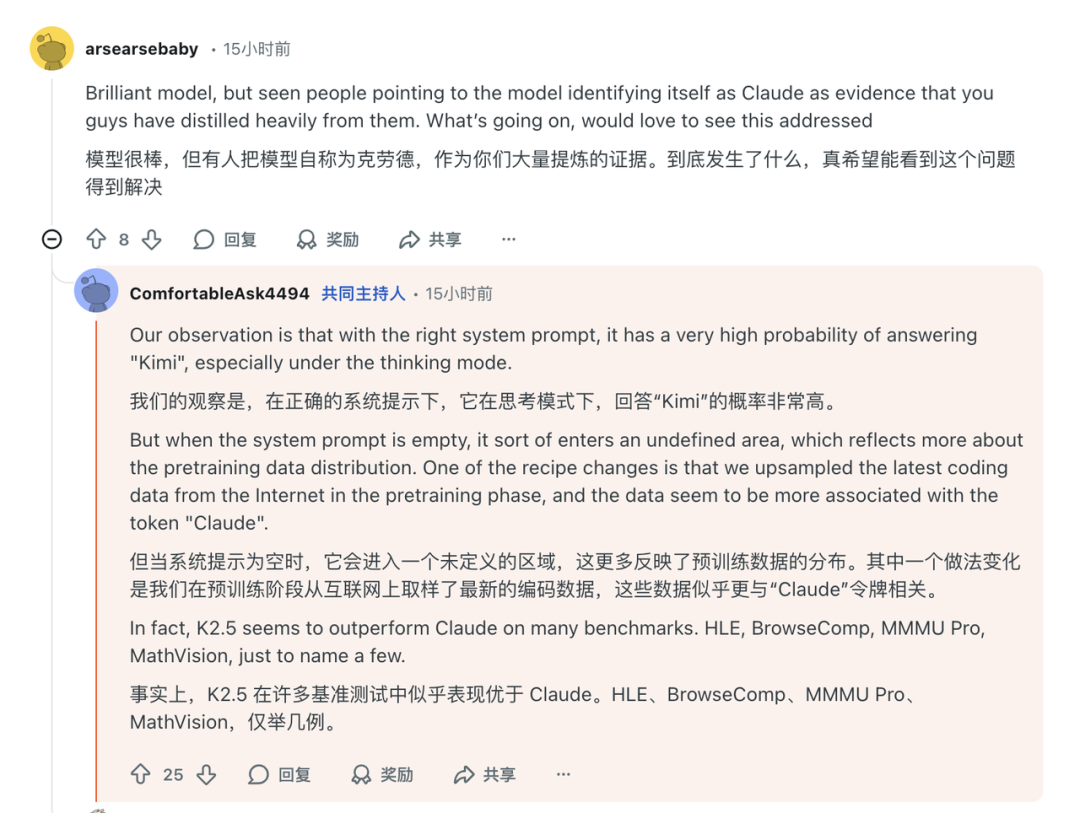
“我们的观察是,在正确的系统提示下,它在思考模式下,回答‘Kimi’的概率非常高。但当系统提示为空时,它会进入一个未定义的区域,这更多反映了预训练数据的分布。其中一个做法变化是我们在预训练阶段上采样了互联网上最新的编码数据,而这些数据似乎更与‘Claude’这个令牌相关联。”
他进一步补充道:“事实上,K2.5在许多基准测试中似乎表现优于Claude。HLE、BrowseComp、MMMU Pro、MathVision,仅举几例。”
二、编码能力与“写作风味”的权衡
有开发者提问,在增强模型编码能力的同时,如何保证像创意写作、情商这类“软实力”不退步。这恰恰呼应了近期业界关于大模型能力是“全面进化”还是“此消彼长”的讨论。
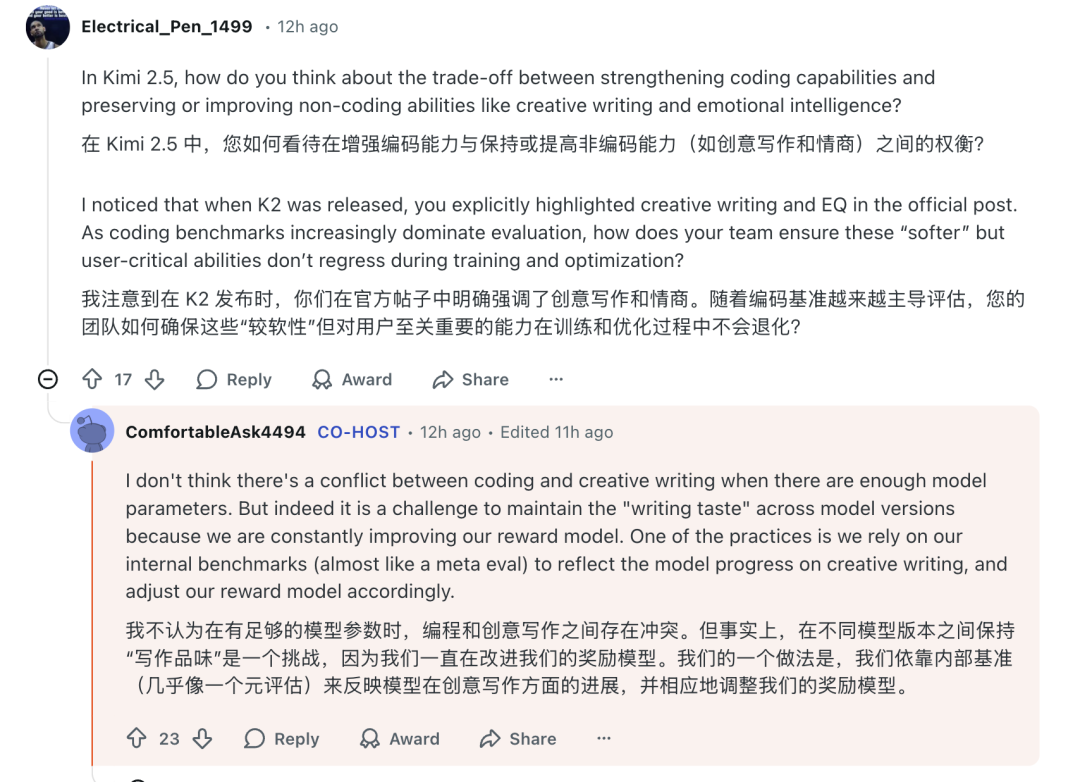
Kimi团队对此的看法显得颇为自信。“我不认为在有足够模型参数时,编程和创意写作之间存在冲突。但事实上,在不同模型版本之间保持‘写作风味’是一个挑战,因为我们一直在改进我们的奖励模型。我们的一个做法是,我们依靠内部基准来反映模型在创意写作方面的进展,并相应地调整我们的奖励模型。”
这一回应,可以被视为对所谓“能力牺牲论”的一种间接反驳。团队强调,通过精心的奖励模型设计和内部评估,目标是打造一个各项能力均衡发展的通用高素质模型。
三、社区呼声:能否推出参数更小的模型?
活动伊始,众多拥有有限计算资源的开发者便发出了强烈呼声:希望Kimi能推出参数规模更小、更适合本地部署的模型版本。
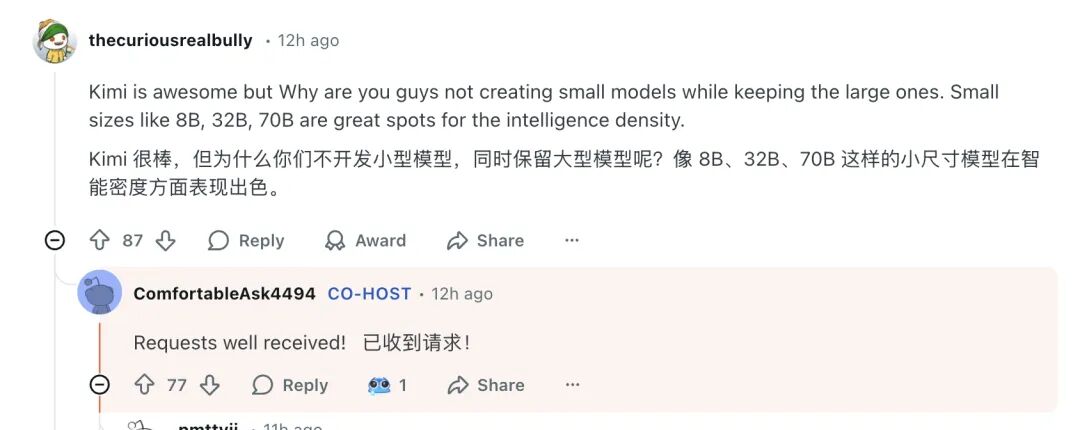
用户直接喊话:“Kimi很棒,但为什么你们不开发小型模型,同时保留大型模型呢?像 8B、32B、70B 这样的小尺寸模型在智能密度方面表现出色。”
对此,团队简洁地回应:“请求已收到!” 这表明社区对高效、轻量级开源模型的迫切需求已被团队记录在案。
四、缩放定律(Scaling Laws)的瓶颈与未来
有参与者提出了一个根本性问题:当前基于数据量和模型规模扩展的“缩放定律”是否已触及天花板?未来的突破点在哪里?
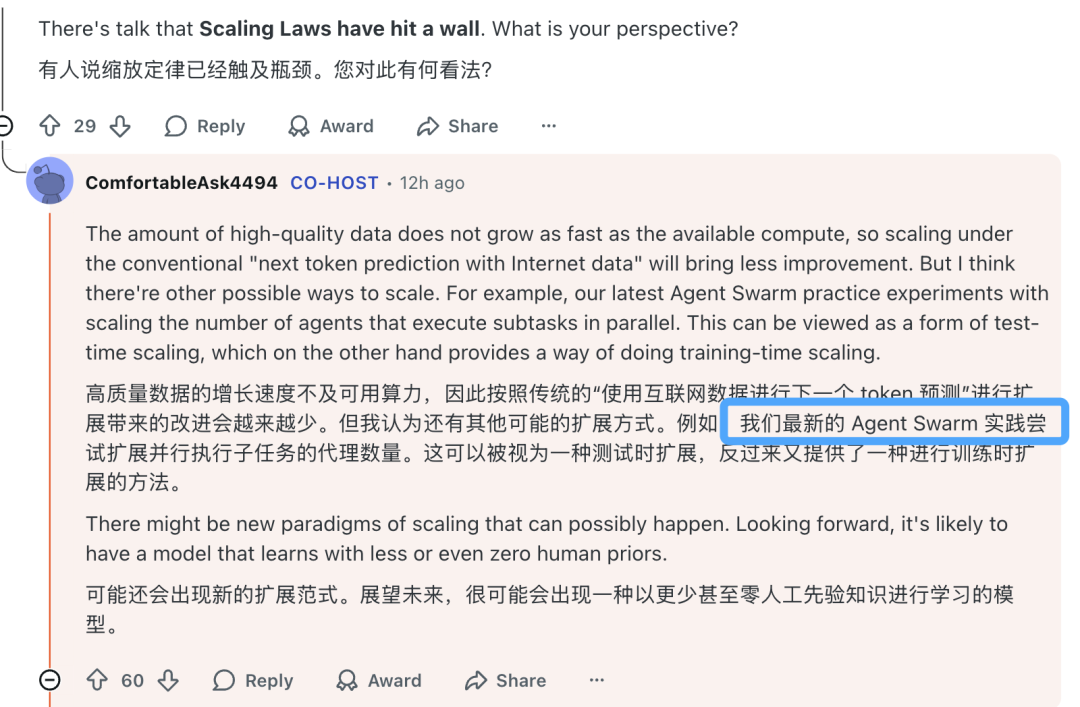
Kimi团队分享了他们的思考:“高质量数据的增长速度不及可用算力,因此按照传统的‘使用互联网数据进行下一个 token 预测’进行扩展带来的改进会越来越少。但我认为还有其他可能的扩展方式。”
他们提出了一个有趣的方向:“例如,我们最新的 Agent Swarm 实践尝试扩展并行执行子任务的代理数量。这可以被视为一种测试时扩展,反过来又可能为训练时扩展提供新思路。” 这暗示了未来AI能力的提升,可能不仅来自于模型本身的放大,也来自于多智能体协同范式的创新。
目前,Kimi已在官方平台提供了Agent集群模式的Beta测试。
五、视觉语言模型(VLM)的挑战与布局
当被问及训练视觉语言模型的主要挑战以及为何致力于此时,团队的回答揭示了多模态协同训练的重要性。
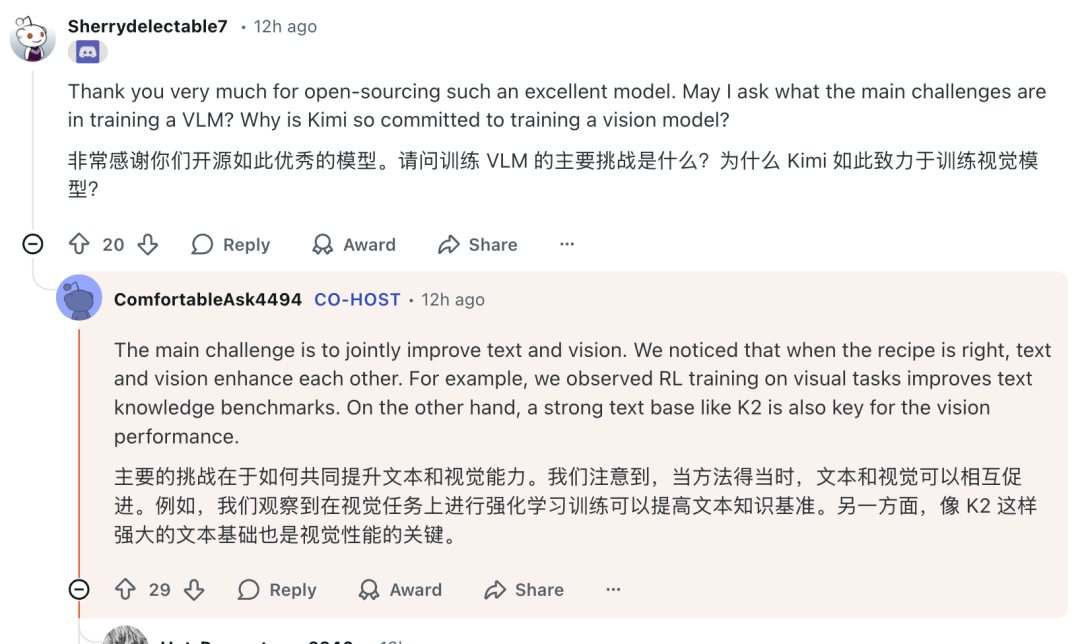
“主要的挑战在于如何共同提升文本和视觉能力。我们注意到,当方法得当时,文本和视觉可以相互促进。例如,我们观察到在视觉任务上进行强化学习训练可以提高文本知识基准。另一方面,像K2这样强大的文本基座也是视觉性能的关键。”
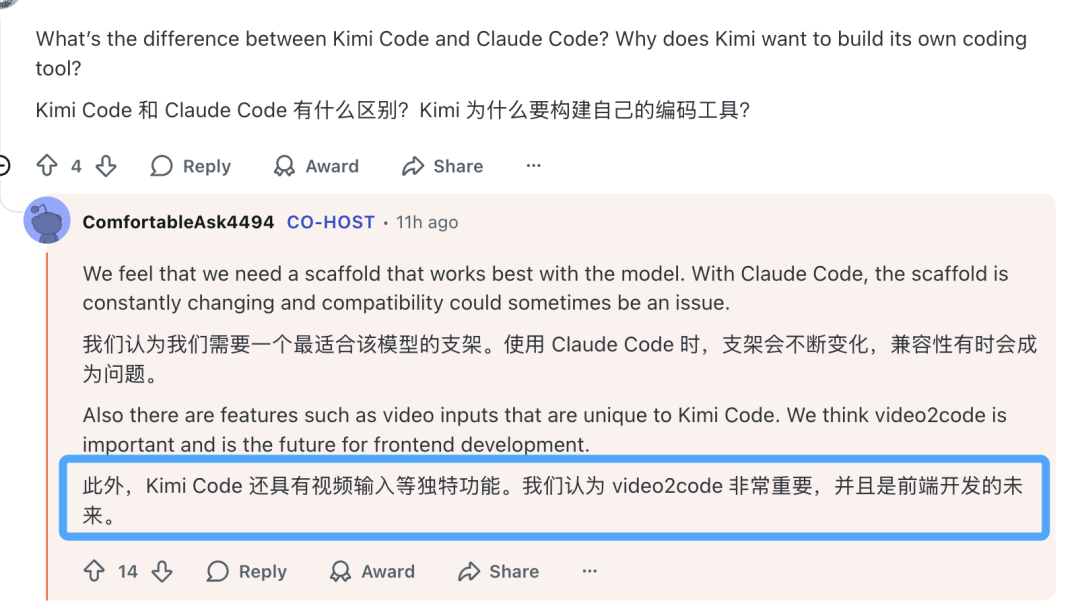
团队尤其强调了 video2code (视频转代码)能力的重要性,并将其视为前端开发的未来方向之一。
六、模型“性格”与个性化
随着用户与AI交互的深入,模型的“性格”或“品味”逐渐成为用户体验的重要部分。有用户反映K2.5的个性相比K2显得更为通用,失去了些许特色。
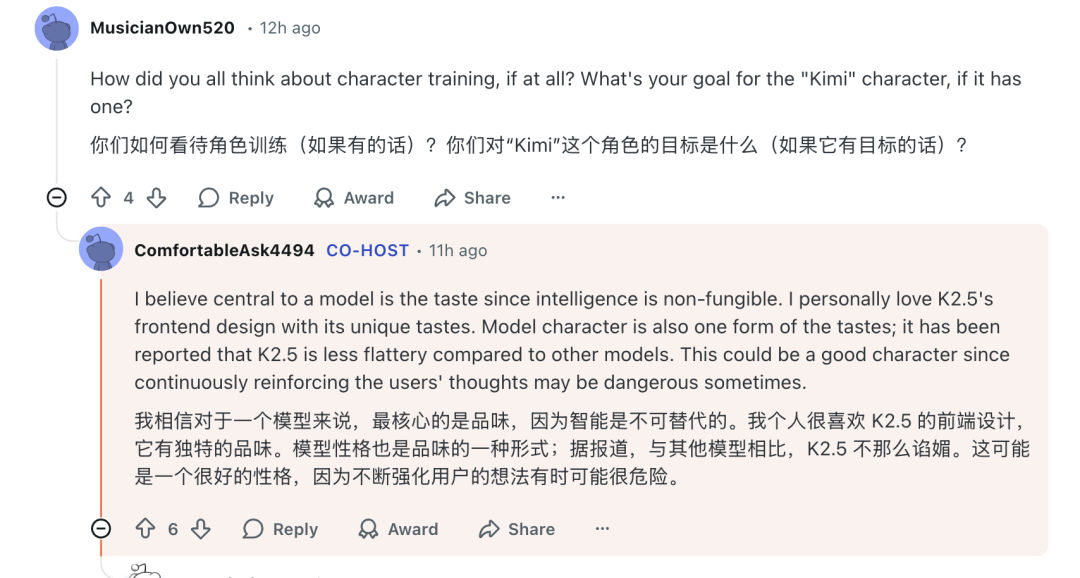
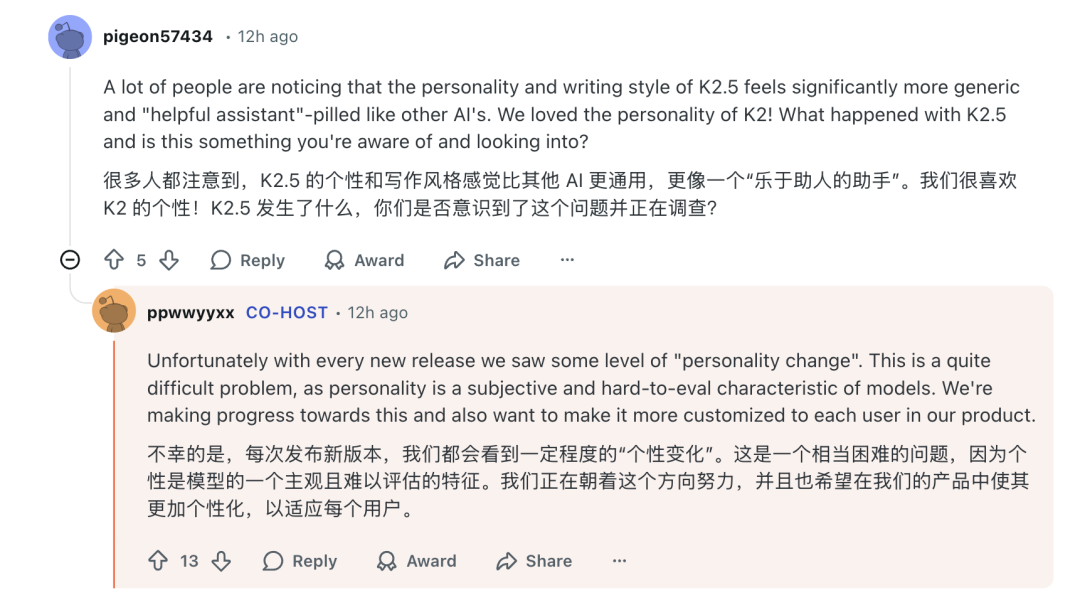
团队对此坦言:“不幸的是,每次发布新版本,我们都会看到一定程度的‘个性变化’。这是一个相当困难的问题,因为个性是模型的一个主观且难以评估的特征。我们正在朝着这个方向努力,并且也希望在我们的产品中使其更加个性化,以适应每个用户。”
七、产品体验与全球化的挑战
在硬核的技术讨论中,一位德国用户的提问带来了些许幽默与现实的碰撞,也反映了中国AI产品走向全球时遇到的实际障碍。
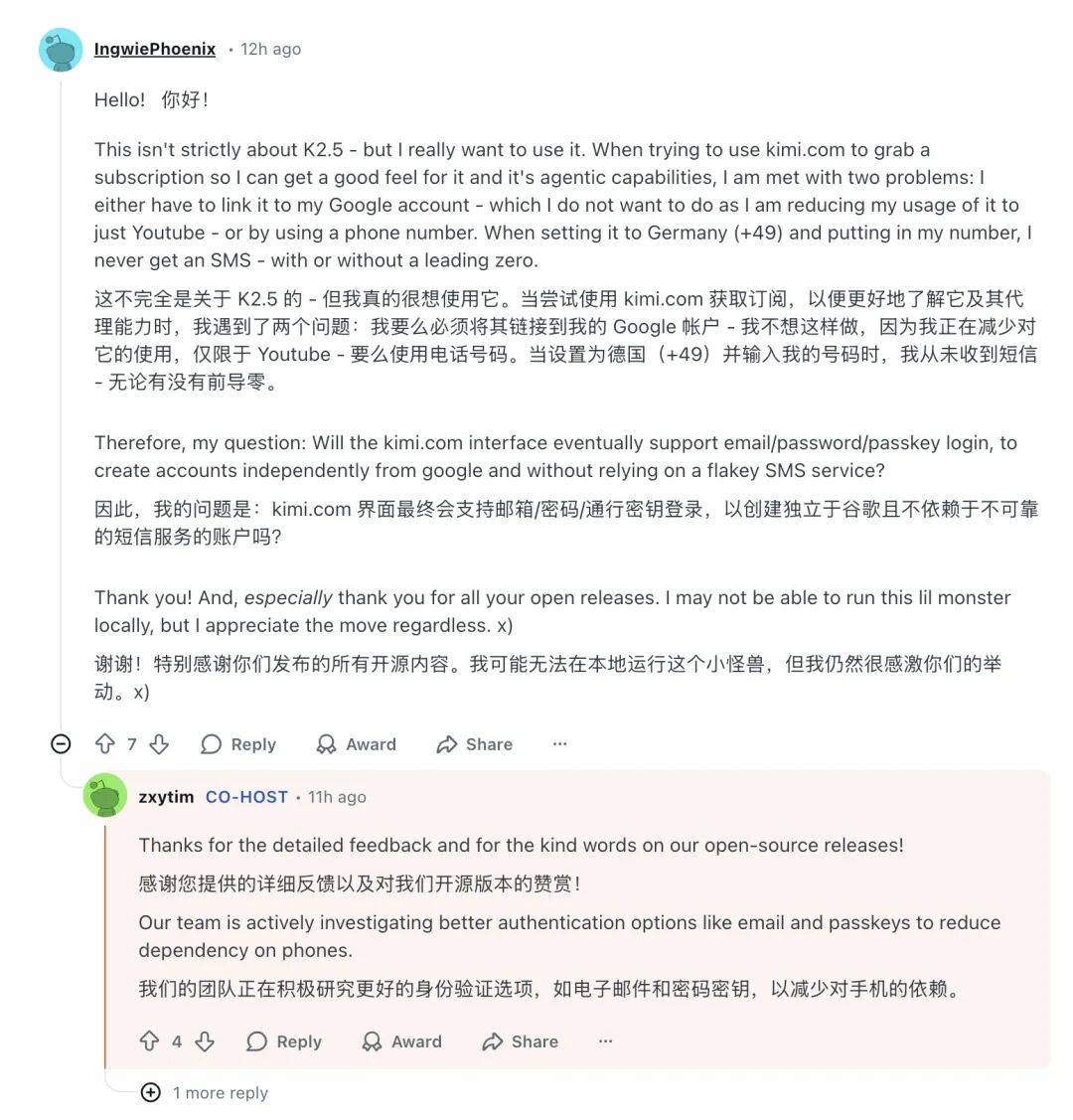
用户表示因为不想绑定Google账户,而德国手机号又收不到验证码短信,导致无法注册使用网页版服务。团队另一位成员 zxytim 回复称,团队正在积极研究如电子邮件、通行密钥等替代身份验证方案,以减少对手机的依赖。
技术亮点回顾:Kimi K2.5 模型架构
根据官方信息,K2.5 采用 MoE 架构,总参数量达 1T,运行时激活参数为 32B。网络包含 61 层,支持高达 256K 的上下文长度,并内置了拥有 4 亿参数的 MoonViT 视觉编码器。
其主要亮点包括:
- 原生多模态能力:能直接处理文本、图片和视频输入,支持像素级视觉理解和基于视觉反馈的代码生成与修正。
- Agent 集群系统:可将复杂任务拆解,调度多个智能体并行工作,据称最高可协调100个节点处理超1500个步骤。
- 强大的前端代码实现:特别强化了视觉还原和交互动效的编程能力,可根据手稿、截图或视频生成高度还原且具备交互性的网页代码。
总结
这场深夜的跨洋AMA,是一次中国顶尖大模型团队与全球开源社区深度连接的尝试。它不仅展示了Kimi K2.5的技术实力,更传递了团队对开源、对产品、对未来的思考。
正如团队在交流中引用的那句“Innovation loves constraints”(创新源于限制),在算力、数据等多重约束下,Kimi的突破显得尤为珍贵。这场对话也让外界看到,大模型的竞争维度正在变得愈发丰富:从纯粹的benchmark分数,扩展到开发者生态、产品共情力乃至全球化落地能力。
对于关注 人工智能 和 开源实战 的开发者而言,这样的直接交流无疑极具价值。最后,分享一个AMA之外的小趣闻:当被问及“我帅还是吴彦祖帅”时,Kimi经过一番思考,最终给出了“你帅”的答案。
这或许也从另一个侧面说明,让AI变得更“智能”和更“讨喜”,仍然是一条需要持续探索的长路。想要了解更多此类前沿技术动态和深度讨论,欢迎来 云栈社区 的开发者广场逛逛。
 发表于 2026-1-31 03:18:44
|
查看: 148|
回复: 0
发表于 2026-1-31 03:18:44
|
查看: 148|
回复: 0
