在嵌入式开发中,你是否常常被以下场景困扰?
- 调试时,打印日志数据耗费的时间过长,甚至超过了被测代码本身对实时性的要求。
- 进行协议解析,需要高速接收大量数据时,偶尔会发现丢失了一两个字节,排查起来令人头疼。
如果你也遇到了类似问题,不妨试试 ZERO_STRM。它是一个专为嵌入式系统设计的高性能、高吞吐率且使用简单的串行数据收发工具。更重要的是,它基于 CMSIS-Pack 标准,在 Keil MDK 环境下,直接安装一个 Pack 包就能快速集成使用。
它能做什么?
ZERO_STRM 的用途非常广泛,包括但不限于:
- 日志(Log)输出
- 传感器数据流输出
- 指令接收与解析
- 协议解析
- 对接
shell
- 重定向
printf 输出
对接 printf 示例:
在 MDK 环境下使用 printf() 有一种非常通用的方法,你需要先安装对应的 pack 包(具体可参考相关文章)。安装完毕并完成必要的硬件初始化后,核心工作就是在代码中实现 stdout_putchar(int ch) 函数。
完成后,你就能愉快地使用 printf() 了。下面是一个简单的示例:
#include <stdio.h>
int stdout_putchar(int ch)
{
uint8_t chByte = 0;
chByte = (uint8_t)(0x000000ff & ch);
if ( zero_strm_write(&g_tZStrmWrite, chByte) ) {
return ch;
}
}
int main(void)
{
while(1) {
printf("hello world \r\n");
perfc_delay_ms(10);
}
}

为什么选择它?
高性能:空间换时间的策略
ZERO_STRM 的核心思想是利用 空间换时间 来释放 CPU,提升数据吞吐效率。这在串口通信中尤其有效,因为接收或发送一个字节数据的时间,往往远大于处理这个字节所消耗的 CPU 时间。
接收数据流程:
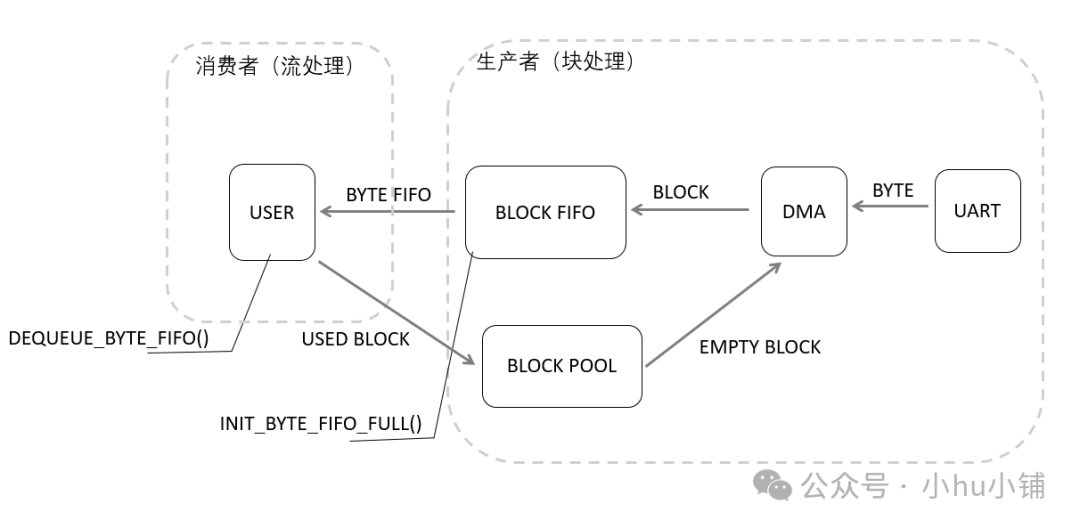
具体流程如下:
- 生产者(如 DMA)提供一个数据块(Block),将其作为字节流队列(Byte FIFO)的缓冲区,并将队列初始状态设为“满”。
- 消费者(用户程序)通过出队接口(如
zero_strm_read)从这个队列中读取数据。
- 当队列被读“空”后,这个缓冲区会被归还给生产者池(Block Pool)。
- DMA 持续将接收到的字节流打包成 Block,并存入 Block FIFO 等待处理。
发送数据流程:
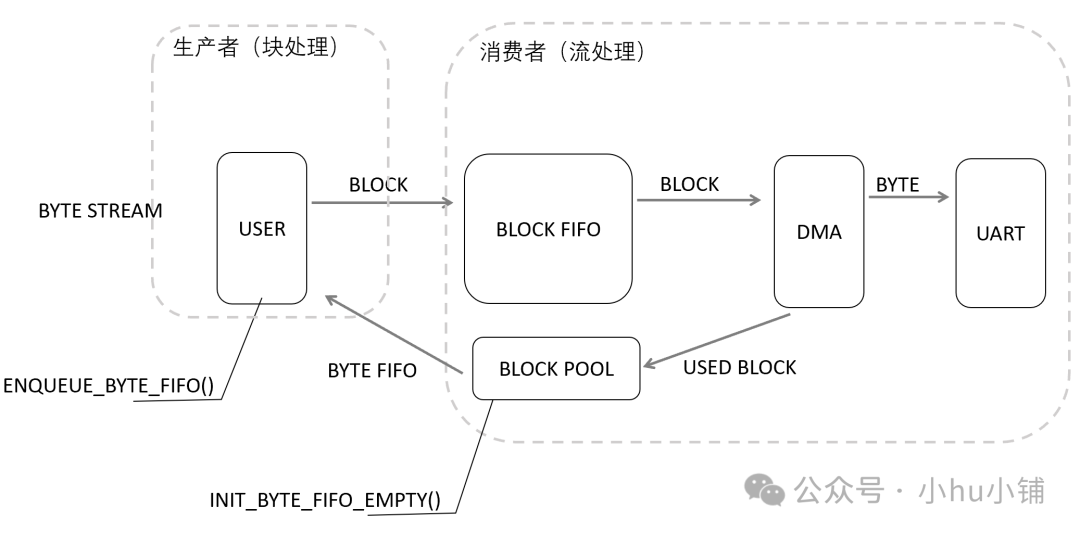
发送侧同样采用此策略:
- 消费者(DMA 发送逻辑)从空闲块池(Block Pool)取出一个空 Block,作为字节流队列的缓冲区,并将队列初始状态设为“空”。
- 生产者(用户程序)通过入队接口(如
zero_strm_write)向这个队列写入要发送的数据。
- 当队列被写“满”后,这个满载的缓冲区会被移交给消费者。
- DMA 从 Block FIFO 中依次获取 Block,并以其为源启动发送。发送完成后,继续处理下一个 Block,直至 FIFO 为空。
这种设计将零散的字节操作转换为批量的块操作,极大减少了 CPU 干预和上下文切换的开销。
高速率:巧妙规避数据丢失
为了实现高速率且不丢数据,ZERO_STRM 在接收端采用了 DMA 半满中断 机制。
对于大多数没有链式 DMA 的 Cortex-M 芯片,在接收大量数据时,当需要 CPU 介入切换接收缓冲区(Block)时,DMA 会暂时暂停。这是否必然导致丢数据呢?
答案是否定的。关键在于保证 DMA 暂停的时间小于接收一个字节数据的时间。
让我们从物理层面看一个字节的旅程:IO 引脚 -> 移位寄存器 -> 数据寄存器 -> 内存(MEM)。以 10M 波特率为例,接收一个字节的时间约为 1微秒。
CPU 的时钟通常远高于外设。例如,STM32F103 主频为 72MHz,我们实测暂停并重新配置 DMA 所消耗的时间约为 38 个时钟周期,即 0.528 微秒。
0.528 < 1 这个不等式成立,意味着即使在 10M 波特率下,STM32F103 也有足够的时间在下一个字节到来前完成 DMA 切换,从而保证数据不丢失。
测试代码如下:
static void uart_dma_data_get(zero_strm_mem_blk_t *ptThis)
{
if ( NULL == ptThis ) {
return ;
}
DMA_Cmd(DMA1_Channel5, DISABLE);
DMA1_Channel5->CMAR = (uint32_t)(this.chMemory);
DMA1_Channel5->CNDTR = this.tSizeInByte;
DMA_Cmd(DMA1_Channel5, ENABLE);
}
int main(void)
{
zero_strm_mem_blk_t tFifo;
while(1) {
__cycleof__("dma exchange") {
uart_dma_data_get(&tFifo);
}
}
}

使用简单
对于应用开发者而言,接口极其简洁:
- 发送数据只需调用
zero_strm_write()。
- 接收数据只需调用
zero_strm_read()。
所有复杂的内存块管理、队列调度和 DMA 协调工作都由 ZERO_STRM 在后台自动完成,用户无需关心。
如何安装?
安装过程非常便捷,完全遵循 MDK 的 CMSIS-Pack 生态:
-
下载 Pack 文件:从 GitHub 项目仓库的 Releases 页面下载最新的 .pack 文件。
👉 https://github.com/hoooooz/zero_strm/releases
-
安装 Pack:双击下载的 .pack 文件,按照安装向导提示完成安装。
-
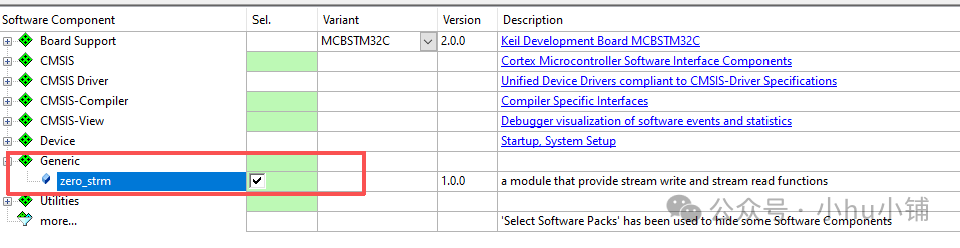
在 MDK 工程中启用:
- 打开你的 MDK 工程,点击工具栏上的 RTE(Runtime Environment)管理图标。

- 在 RTE 配置窗口中,找到
Generic 分类,勾选 zero_strm 组件,然后点击 OK。
-
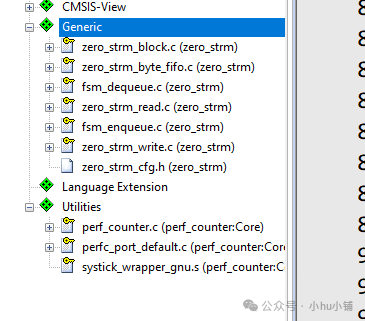
查看添加的文件:组件添加成功后,你可以在工程管理器中看到 zero_strm 模块下的相关源文件已经加入。
-
编译器设置(如果使用 Arm Compiler 6):确保项目的 C 语言模式设置为 gnu11。
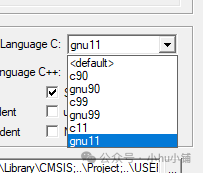
-
安装依赖(可选):为了使用文中提到的性能测试功能,你可能需要安装最新版的 perf_counter 性能分析工具包。同样,为了更好的代码结构,也可以考虑安装 PLOOC(Protected Low-overhead Object-Oriented Programming in C)包。这两个包也以 CMSIS-Pack 形式提供。
如何使用?
发送数据示例
以下是配置和使用 ZERO_STRM 进行数据发送的完整示例代码:
#include “zero_strm.h”
zero_strm_write_t g_tZStrmWrite;
__attribute__((aligned(32)))
static uint8_t s_chWriteBuffer[1024 * 5];
static zero_strm_write_cfg_t s_tZStrmWriteCfg = {
.pchBuffer = s_chWriteBuffer,
.hwSize = sizeof(s_chWriteBuffer),
.fnDmaSendData = uart_dma_data_send,
};
/* 配置 DMA 发送函数 */
static void uart_dma_data_send(zero_strm_mem_blk_t *ptThis)
{
if (NULL == ptThis) return;
DMA_Cmd(DMA1_Channel4, DISABLE);
DMA1_Channel4->CMAR = (uint32_t)(ptThis->chMemory);
DMA1_Channel4->CNDTR = ptThis->tSizeInByte;
DMA_Cmd(DMA1_Channel4, ENABLE);
}
/* DMA 发送完成中断 */
void DMA1_Channel4_IRQHandler(void)
{
if ( RESET != DMA_GetITStatus(DMA1_IT_TC4) ) {
DMA_Cmd(DMA1_Channel4, DISABLE);
DMA_ClearITPendingBit(DMA1_IT_TC4);
zero_strm_dma_send_data_cpl_event_handler(&g_tZStrmWrite);
}
}
int main(void)
{
zero_strm_write_init(&g_tZStrmWrite, &s_tZStrmWriteCfg);
while(1) {
uint8_t chByte;
zero_strm_write(&g_tZStrmWrite, chByte);
}
}
接收数据示例
以下是配置和使用 ZERO_STRM 进行数据接收的完整示例代码,它结合了 DMA 半满中断、串口空闲中断和超时定时器:
#include “zero_strm.h”
zero_strm_read_t g_tZStrmRead;
__attribute__((aligned(32)))
static uint8_t s_chReadBuffer[1024 * 5];
/* 配置 DMA 读取函数 */
static void uart_dma_data_get(zero_strm_mem_blk_t *ptThis)
{
if ( NULL == ptThis ) {
return ;
}
DMA_Cmd(DMA1_Channel5, DISABLE);
DMA1_Channel5->CMAR = (uint32_t)(this.chMemory);
DMA1_Channel5->CNDTR = this.tSizeInByte;
DMA_Cmd(DMA1_Channel5, ENABLE);
}
/* 获取 DMA 剩余数据计数函数 */
static uint16_t get_dma_cnt(void)
{
return DMA_GetCurrDataCounter(DMA1_Channel5);
}
static zero_strm_read_cfg_t s_tZStrmReadCfg = {
.pchBuffer = s_chReadBuffer,
.hwSize = sizeof(s_chReadBuffer),
.wTimeOutMs = 4000,
.fnDmaStartRx = uart_dma_data_get,
.fnDmaCntGet = get_dma_cnt,
};
/* DMA 半满中断 */
void DMA1_Channel5_IRQHandler(void)
{
if ( RESET != DMA_GetITStatus(DMA1_IT_HT5) ) {
DMA_ClearITPendingBit(DMA1_IT_HT5);
zero_strm_uart_dma_get_data_insert_to_dma_irq_event_handler(&g_tZStrmRead);
}
}
/* 串口空闲中断 */
void USART1_IRQHandler(void)
{
if ( RESET != USART_GetITStatus(USART1, USART_IT_IDLE) ) {
uint32_t temp = USART1->SR;
temp = USART1->DR;
(void)temp;
zero_strm_uart_idle_insert_to_uart_irq_event_handler(&g_tZStrmRead);
}
}
/* 定时器中断 (周期1ms), 配合 wTimeOutMs (4000ms) 超时自动取回DMA中剩余数据 */
void TIM5_IRQHandler(void)
{
uint32_t timesr;
uint16_t itstatus = 0x0, itenable = 0x0;
TIM_TypeDef *TIMx = TIM5;
timesr = TIMx->SR;
if (timesr & TIM_IT_Update) {
TIMx->SR = (uint16_t)~TIM_IT_Update;
zero_strm_uart_wait_time_out_insert_to_hard_timer_irq_event_handler(&g_tZStrmRead)
}
}
int main(void)
{
zero_strm_read_init(&g_tZStrmRead, &s_tZStrmReadCfg);
while(1) {
uint8_t chByte = 0;
zero_strm_read(&g_tZStrmRead, &chByte)
}
}
注意:单个 FIFO 队列的默认大小是 64 字节。如果你需要调整缓冲区大小,可以打开 zero_strm_cfg.h 文件,修改以下对应的宏定义:
#define READ_BUFF_CNT (64*2)
#define WRITE_BUFF_CNT (64)
性能如何?
我们使用 STM32F103(72MHz 主频) 进行了实测。
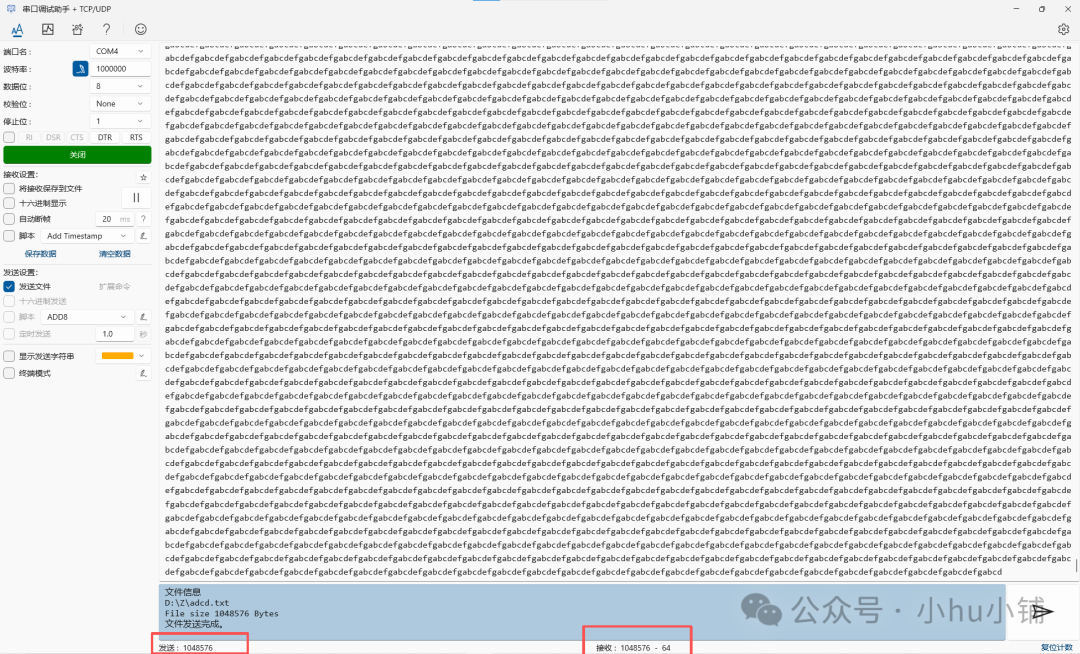
- 稳定性测试:在 1M 波特率下,进行 1MBytes 数据的全速收发测试,结果 一点数据都没丢!
- 极限测试:尝试 3M 波特率时,接收到的数据中出现了大量额外的
0x00 字符。初步判断问题可能出在上位机软件无法稳定支持如此高的波特率进行大数据量发送。仍在寻找合适的上位机进行进一步验证。
- 核心操作耗时(理论值):
- 发送一个字节(入队操作)仅需约 85 个时钟周期(1.18us)。
- 接收一个字节(出队操作)仅需约 66 个时钟周期(0.916us)。
这些时间是纯粹的队列操作耗时。在实际流程中,当一个队列写满或读空,进行队列切换时会消耗额外时间。
如果在实际应用中出现数据丢失,可以首先尝试适当增大单个队列缓冲区的大小。如果问题依旧,则需要从系统设计的角度,调整生产者和消费者之间的速率匹配策略。关于这方面的深入探讨,可以参考生产者-消费者模型相关的文章。
希望这篇关于 ZERO_STRM 的介绍能帮助你解决嵌入式开发中的串口通信痛点。如果你在 C/C++ 开发或实际的网络/系统通信应用中遇到任何问题,或者对这个开源实战项目有改进想法,欢迎在技术社区进行交流探讨。
 发表于 2026-2-3 11:50:13
|
查看: 251|
回复: 0
发表于 2026-2-3 11:50:13
|
查看: 251|
回复: 0
