1. Lambda 架构:双管齐下的“老牌劲旅”
1.1 核心思想
专业性描述
Lambda 架构是一种经典的大数据处理范式,其核心思想是通过并行的批处理层和流处理层来分别处理历史数据和实时数据,最后在服务层合并结果,以同时满足大数据处理中对准确性和实时性的双重需求。
大白话类比
这就像一家公司做年度财务报告和每日收支快报。
- 年度财务报告(批处理层):财务部门在年底会对全年每一笔账目进行仔细、严谨的核算(高准确性,高延迟)。这份报告非常准确、全面,但出来得很慢。
- 每日收支快报(速度层/流处理层):出纳每天下班前会快速统计当天的流水(低延迟,但可能不全面)。这个快报能让你迅速了解当天的大致情况,但细节可能不如年终报告精准。
- 总经理(服务层):当需要了解公司最新的财务状况时,总经理会结合“年度报告”的准确基础和“每日快报”的最新动态,得出一个既全面又及时的整体判断。
1.2 架构组成
Lambda 架构由三个明确分工的层级构成:
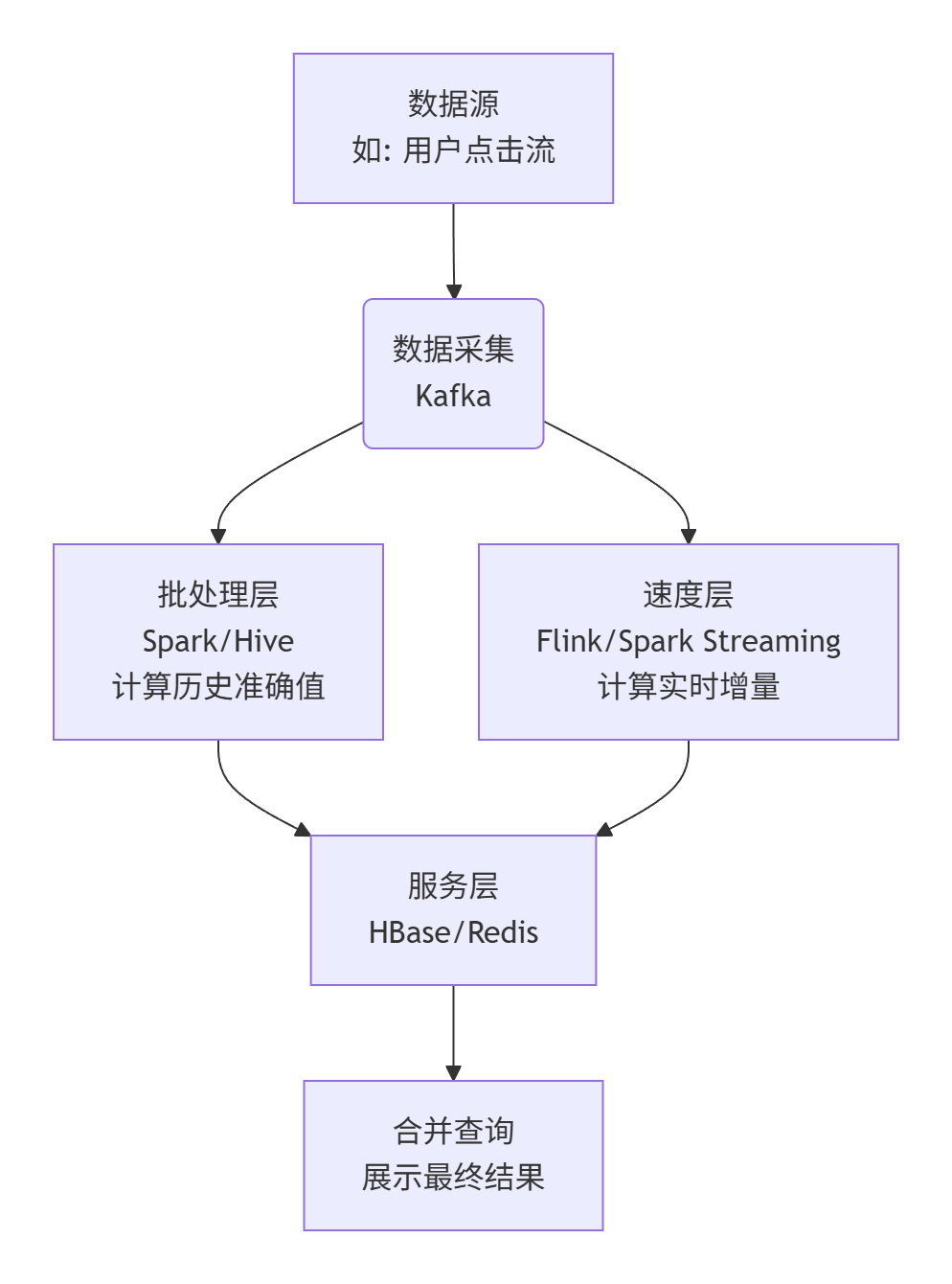
批处理层(Batch Layer):“历史学家”。负责处理所有积压的历史数据,生成一个“唯一且准确”的真相来源。它追求的是准确性和全面性,但速度很慢(通常是 T+1,即今天处理昨天的数据)。
电商示例:每天凌晨,系统会用 Hive 或 Spark SQL 任务,离线计算过去一天所有商品的历史总点击量。这个数字是非常准确的。
速度层/加速层(Speed Layer):“前线哨兵”。负责处理源源不断涌入的实时数据,对最新的信息做出快速响应。它追求的是速度,计算结果可能是一个近似值或基于最新数据的增量。
电商示例:用户每一次点击商品,Flink 或 Spark Streaming 都会实时捕获这个事件,并立刻为这个商品的实时点击计数器加 1。这个数字能立刻反映最新情况,但可能因为网络抖动等原因有微小误差。
服务层(Serving Layer):“总指挥室”。它存储批处理层产生的“准确结果”,并接收速度层传来的“实时增量”。当外界需要查询数据时,服务层负责将两者合并,返回一个既准确又最新的结果。
电商示例:当你在下午 3 点查询某个商品的点击量时,系统会从服务层(如 HBase)取出“截至昨日 24 点的历史总点击量”(来自批处理层),再加上“从今天 0 点到下午 3 点的实时点击量”(来自速度层),相加后返回给你。
1.3 优点
- 容错性高:批处理层和速度层相互独立,一旦速度层因数据波动出现短暂异常,最终数据仍可由批处理层修正,保证最终准确性。
- 平衡准确性与延迟:兼顾了批处理对复杂计算的准确性和流处理的低延迟。
- 支持复杂计算:批处理层非常适合运行复杂、耗时长的计算任务(如机器学习模型训练)。
- 可扩展性强:批处理和流处理都可以采用分布式架构,方便水平扩展。
1.4 缺点
- 代码维护成本高:同一套业务逻辑(如点击量统计)需要开发两套代码,一套用于批处理(Hive SQL),另一套用于流处理(Flink 代码)。这不仅双倍工作量,还极易导致两套逻辑不一致。
- 系统复杂度高:需要同时维护两套技术栈(如 Hadoop/Spark 用于批处理,Flink 用于流处理)和三条数据管道,运维挑战大。
- 逻辑一致性难保证:正是由于两套代码,很难确保批处理和流处理的计算规则百分百相同,容易产生“数据打架”的情况。
下图清晰地展示了 Lambda 架构中数据的流动路径与核心组成。
2. Kappa 架构:化繁为简的“革新者”
2.1 核心思想
专业性描述
Kappa 架构是针对 Lambda 架构复杂性的一个革新。其核心思想是只保留流处理层,将所有数据(无论是历史数据还是实时数据)都视为流,通过流处理系统来统一处理,从而简化架构。
大白话类比
这就像用录音笔的“回放”功能来复盘整个事件。
Lambda 架构是派两个人同时记录,一个记详尽的笔记(批处理),一个做实时口播(流处理)。而 Kappa 架构只用一个录音笔:需要了解全过程时,就从头播放录音(重播历史数据流);需要了解最新情况时,就听实时录音(处理实时数据流)。自始至终,只依赖“录音”这一种素材和“播放”这一种动作。
2.2 架构组成
Kappa 架构的组成非常简洁:
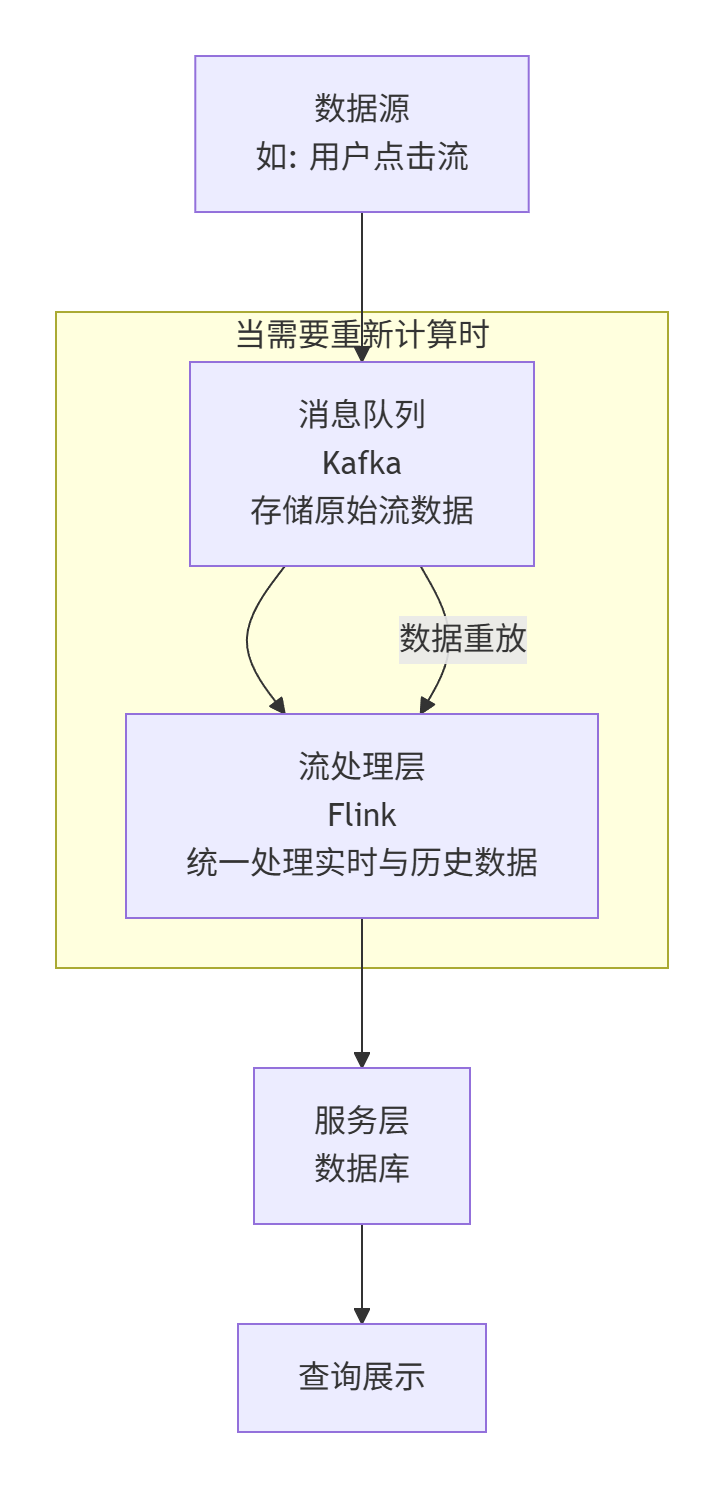
流处理层(Streaming Layer):“全能处理器”。这是唯一的数据处理引擎。它需要一个具备“数据重放”能力的消息队列(如 Apache Kafka)作为核心支撑。Kafka 可以保存所有原始数据流(例如保存 7 天),当业务逻辑变更或需要重新计算时,就可以从 Kafka 中从头读取数据流,再次处理。
在线服务层(Serving Layer):“结果展示台”。用于存储流处理引擎计算后的结果,并提供查询服务。
电商示例:在 Kappa 架构下,所有用户点击数据都发送到 Kafka。一个 Flink 作业实时消费这些数据,计算每个商品的点击量。
- 正常运行时:Flink 实时处理数据,将结果写入数据库。
- 当发现代码有 Bug 需要重新计算时:
- 启动一个新的 Flink 作业,并编写修复后的代码。
- 让这个新作业从 Kafka 中该话题的最开始位置(Offset=0)重新消费所有历史数据。
- 新作业会快速“重放”历史,计算出全新、正确的结果,并写入一个新的结果表。
- 当新作业的处理进度追上实时数据时,将前端的查询切换到新的结果表上。
- 停掉旧的、有 Bug 的 Flink 作业。
2.3 优点
- 架构简洁,维护成本低:只需维护一套流处理代码和管道,极大降低了开发和运维复杂度。
- 逻辑一致性高:由于只有一套代码,从根本上杜绝了 Lambda 架构中批处理和流处理结果不一致的问题。
- 强大的回溯和重算能力:数据重放机制使得历史数据的重新计算变得天然和简单。
- 技术栈统一:团队只需专注于流处理技术栈,降低学习成本。
2.4 缺点
- 严重依赖消息队列的数据保留能力:Kafka 等消息队列长期存储数据的成本较高。
- 全量重算效率较低:当需要重算很长的历史数据时,速度可能不如批处理作业高效。
- 对复杂计算的支持有限:对于一些需要全量数据扫描的复杂分析查询,流处理引擎可能不如批处理引擎得心应手。
下图直观展示了 Kappa 架构简洁的数据流。
3. Lambda架构 vs. Kappa架构:终极对决
| 对比维度 |
Lambda 架构 |
Kappa 架构 |
| 核心思想 |
批流并行,结果合并 |
一切皆流,统一处理 |
| 架构复杂度 |
高(两套系统,三条链路) |
低(一套流系统) |
| 维护成本 |
高(需维护两套代码和逻辑) |
低(只需维护一套代码) |
| 数据一致性 |
可能不一致(需精心维护两套逻辑) |
天然一致(只有一套逻辑) |
| 实时性 |
实时部分延迟低,全量结果延迟高 |
全链路低延迟 |
| 历史数据处理 |
批处理层天然支持,高效 |
通过流重放支持,可能较慢 |
| 技术栈 |
Hadoop/Spark(批) + Flink/Storm(流) |
Kafka + Flink/Spark Streaming |
| 适用场景 |
对历史数据准确性要求极高,且业务逻辑非常复杂的离线分析、数据仓库等 |
以实时性为首要需求,业务逻辑相对清晰的,如实时监控、实时风控、实时推荐 |
4. 记忆与实战技巧
核心口诀:
Lambda 俩通路,批流分开再合并。准确可靠但复杂,历史分析是强项。
Kappa 一条流,化繁为简是核心。实时敏捷又一致,实时场景它称王。
实战选型技巧
5.1 看业务需求
如果你的业务是“以天为单位的报表为主,实时看板为辅”(如经营分析系统),Lambda 架构更稳妥。如果你的业务是“秒级响应,实时决策”(如实时反欺诈系统),Kappa 架构更优。
5.2 看团队能力
Lambda 架构需要团队掌握批处理和流处理两套技术栈。Kappa 架构要求团队对流处理技术(特别是 Flink/Kafka)有深度掌握。
5.3 看数据特性
如果需要对全量历史数据进行非常复杂的关联和挖掘,Lambda 的批处理层更有优势。如果数据主要是时序事件流,且需要频繁重新计算,Kappa 架构更合适。
5.4 趋势所向
目前,随着 Flink 等流批一体引擎的成熟,Kappa 架构和流批一体架构正成为主流趋势。很多公司在新系统中会优先考虑 Kappa 架构,或者在 Lambda 架构的基础上积极探索向流批一体演进。无论选择哪种模式,清晰的需求分析和面向未来的架构思维都至关重要。如果你想与更多开发者探讨类似 大数据处理 与 复杂的系统设计 问题,欢迎来 云栈社区 交流分享。
 发表于 2026-2-4 08:29:58
|
查看: 217|
回复: 0
发表于 2026-2-4 08:29:58
|
查看: 217|
回复: 0
