
在追求技术先进性的路上,我们一度将目光投向 GraalVM Native Image,因为它标榜着启动快、内存低、镜像小的诱人特性。然而,当我们把实际的项目状况、团队协作效率和交付节奏摆到台前,冷静思考后,一个核心问题浮现出来:当前这个项目,真的值得为引入 Native Image 所带来的复杂性付出高昂代价吗?
答案是否定的。
因此,我们选择了一条看似更“笨”、但实践下来却更为稳妥的优化路径。最终的结果令人满意:
- 镜像体积:从接近 1GB 缩减至稳定的 200MB 左右。
- 启动时间:在仍基于 JVM 的前提下,获得了明显缩短。
- 团队负担:最关键的是,整个过程几乎没有给团队带来额外的心智负担。
这篇文章,并非介绍最前沿的方案,而是复盘我们如何通过一系列扎实的工程实践,一步步将镜像体积“打下来”的真实过程。
01 问题的起点:为何镜像接近1GB?
首先交代一下项目背景。这是一个典型的企业级 Spring Boot 服务:
- Spring Boot 3.x
- Java 17
- 微服务架构
- 日常运行于 Kubernetes 环境
项目对性能并非极端敏感,但部署却非常频繁。最初的 Dockerfile 非常“教科书”:
FROM openjdk:17-jdk
COPY target/app.jar /app.jar
ENTRYPOINT ["java","-jar","/app.jar"]
构建出的镜像体积令人咋舌:900MB+。
起初对这个数字有些麻木,但问题逐渐暴露:
- CI/CD 流程变慢:每次构建都需要推送和拉取如此庞大的镜像,集群节点的冷启动时间明显增加。
- K8s 调度成本上升:节点磁盘压力巨大,镜像缓存命中率极低。
- 最根本的质疑:一个普通的 Java 服务,为何要背负一个近 1GB 的“包袱”进行分发和部署?
02 第一件“笨事”:把 JDK 换成 JRE
问题很直接:生产环境真的需要完整的 JDK 吗?
答案显然是否定的。绝大多数 Spring Boot 应用在生产环境只需要 Java 运行时环境(JRE)。
改动1:JDK → JRE
我们将基础镜像从 JDK 更换为 JRE:
FROM eclipse-temurin:17-jre
效果立竿见影:镜像体积立即减少了 200~300MB。
这一步几乎没有技术风险,是我们认为性价比最高的优化,是所有 Java 应用容器化都应首先考虑的步骤。
进阶选择:jlink 定制运行时
在部分服务中,我们进一步使用了 jlink 工具,只打包应用实际所需的 Java 模块(如 java.base, java.logging 等),构建出最小的 Java 运行时。这还能再削减几十 MB 体积。
但坦白说,jlink 属于“锦上添花”。如果团队对 Java 模块系统不熟悉,不建议在优化初期引入,以免增加复杂度。
03 第二件“笨事”:拆分 Fat Jar
传统的“一个 Fat Jar 走天下”模式在 JVM 运行时没问题,但在镜像层级上却造成了浪费。关键矛盾在于:
然而,每次 Docker 构建都将整个 Fat Jar 视为一个新文件,导致即使依赖未变,也无法有效利用 Docker 的镜像层缓存。
改动2:按变更频率拆分层级
我们改用了经典的分层复制结构,将依赖、资源和应用类分开:
COPY lib/ /app/lib/
COPY resources/ /app/resources/
COPY classes/ /app/classes/
启动命令也随之调整:
java -cp "/app/classes:/app/resources:/app/lib/*" com.xxx.Application
这一步的核心价值并非直接大幅缩减体积,而在于显著提升镜像缓存的命中率。
实际收益:
- 依赖层几乎不会被重复构建。
- CI/CD 构建速度因缓存复用而明显提升。
- K8s 节点间的镜像复用率更高,提升了调度效率。
04 第三件“笨事:彻底清理项目依赖
说句实话:大部分 Spring Boot 项目都存在依赖过度的问题。我们也不例外。
我们的清理步骤:
- 使用
mvn dependency:tree 命令分析全量依赖树。
- 重点标注并审查:
- 仅用于测试的依赖(
scope=test)。
- 通过传递依赖引入的、非必需的“全家桶”式库。
- 项目中已不再实际使用的
starter 或工具库。
真实案例:
- 一个 Excel 解析库,传递依赖引入了完整的 Apache POI 套件。
- 某个监控 SDK 附带引入了 30+ 个间接依赖。
- 某个
starter 仅为了使用其中的一个工具类。
改动3:依赖瘦身
- 将测试依赖(
scope=test)坚决排除在生产镜像之外。
- 在
pom.xml 中,能 exclude 的非必要传递依赖全部排除。
- 改变“为了省事直接引入完整
starter”的习惯,按需引入最小依赖集。
效果:应用 Jar 包体积和最终的镜像体积都得到了持续的、可见的下降。
05 第四件“笨事:审慎选择基础镜像
我们最初使用 openjdk:17-jdk,但经过对比测试,评估了多种选择:
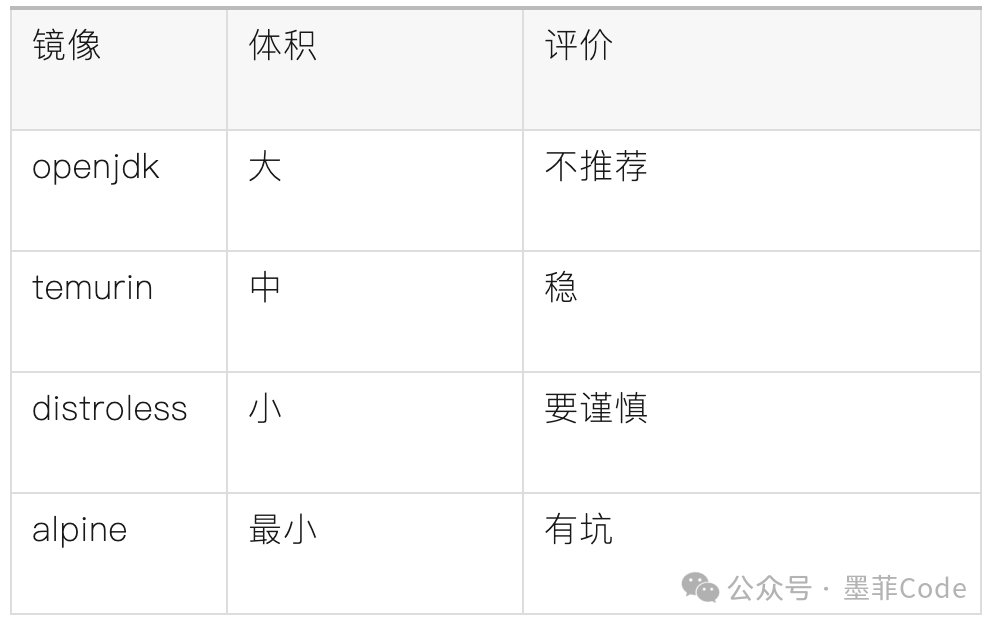
我们的最终选择:Temurin JRE + 非 Alpine 基础镜像
选择的原因很现实:
- Alpine 使用
musl libc,可能导致部分第三方原生库出现兼容性问题。
- 此类问题排查成本较高,可能抵消掉镜像体积减小带来的收益。
因此我们得出一个结论:基础镜像选型是一个需要权衡稳定性和效率的工程问题,而非一味追求极限的体积挑战。
06 最终结果:步步为营的优化轨迹
整个优化过程没有魔法,只有对每个环节的细致审视:
- 原始镜像:≈ 950MB
- 更换基础镜像为 JRE:≈ 650MB
- 拆分 Fat Jar 利用层缓存:≈ 450MB
- 彻底清理项目依赖:≈ 300MB
- 选用更精简的基础镜像:≈ 200MB
这一切的核心,在于对工程细节保持足够的诚实,并愿意为长期稳定而多做几步“笨功夫”。
07 为什么我们没有选择 Native Image?
这并非否定 Native Image 技术的价值。相反,我们很清楚它的优势。但我们放弃的原因在于其引入的复杂性与当前项目需求的匹配度:
- 构建复杂度高:需要额外的配置和更长的构建时间。
- 动态特性支持成本:对反射、AOP、动态代理等需要额外处理或配置。
- 第三方库兼容性:并非所有常用库都能稳定支持 Native 编译。
- 团队学习成本:需要团队成员掌握新的工具链和排错思路。
对于我们的项目而言,在已有的 JVM 体系内进行优化,已经达到了“足够好”的状态,无需引入更高的复杂度。
写在最后
这次优化带来的最大感悟是:工程实践中的“最优解”,往往不是最炫酷的那一个,而是在满足需求的前提下,最稳定、最可持续的那一个。
有时候,愿意回头多做几件扎实的“笨事”,反而更能构筑起长期的稳定基石。
思考题:如果是你的 微服务 项目,你会为了追求极致的镜像体积和启动速度,而主动拥抱 Native Image 吗?还是更倾向于在成熟的 JVM 生态内,将优化做到极致?欢迎在 云栈社区 的相关板块分享你的实践和踩坑经历。
 发表于 2026-2-5 04:10:01
|
查看: 170|
回复: 0
发表于 2026-2-5 04:10:01
|
查看: 170|
回复: 0
