随着人工智能技术的飞速发展,深度学习模型的规模呈现指数级增长。从早期的AlexNet到如今万亿参数级别的大模型,训练所需的算力已远超单张GPU的能力。大规模模型训练的核心挑战之一,在于多GPU、多节点间的数据通信效率。通信性能的好坏,直接制约着整个训练过程的效能与扩展性。
高性能通信库,正是支撑分布式AI训练的核心基础设施。它能够屏蔽底层复杂的硬件与网络细节,凭借其拓扑感知能力、高效的通信算法以及计算与通信的融合设计,最大限度地利用系统带宽、降低交互延迟。无论是PyTorch、TensorFlow的分布式训练,还是数据并行、模型并行等混合并行策略,其梯度同步、参数分片等核心操作,都依赖于底层的通信库。可以说,通信库的性能,直接决定了分布式训练的扩展效率与理论上限。如果没有高性能的通信库,万亿参数级别模型的规模化训练将无从落地。
NVIDIA集合通信库(NCCL,发音为“Nickel”),正是NVIDIA针对这一需求开发的、专门用于多GPU和多节点间通信的高性能库。与传统的MPI(消息传递接口)不同,NCCL专注于加速深度学习中最常用的集合通信原语,而非提供一个完整的通用并行编程框架。
一、NCCL分层架构
NCCL采用了清晰的分层架构设计,在人工智能框架与底层硬件之间扮演着承上启下的关键角色,是分布式GPU训练的核心通信支撑层,各层级职责明确且协同高效。
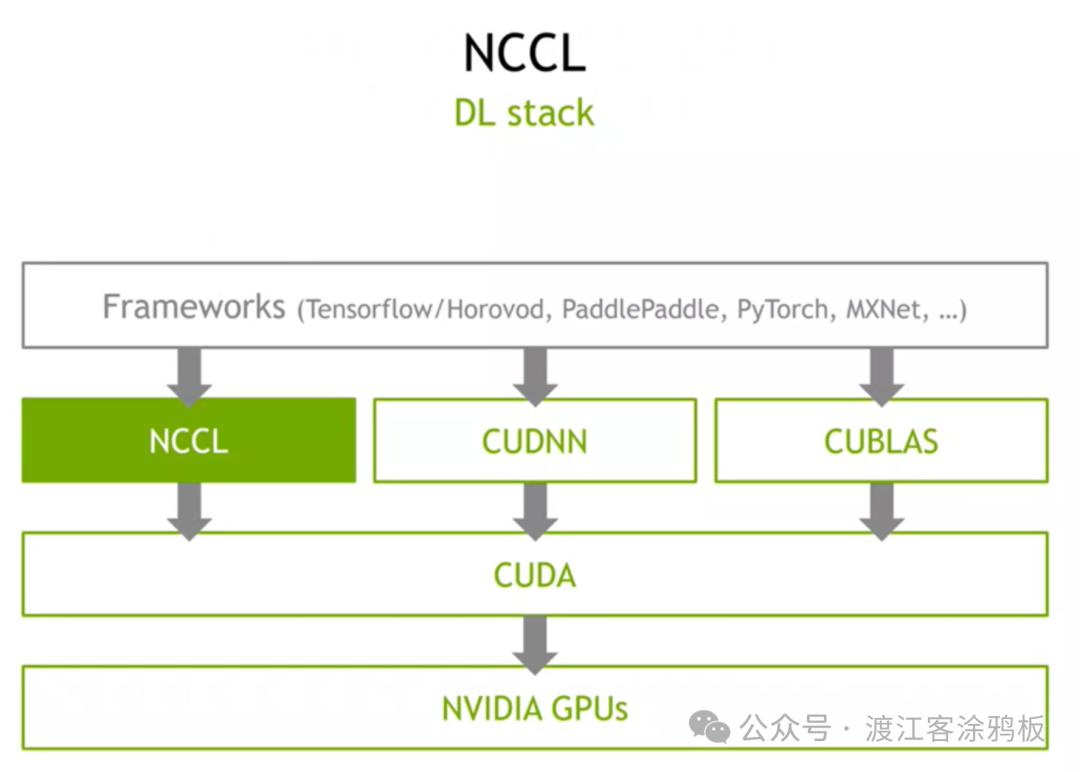
其北向接口是框架适配层,负责对接PyTorch、TensorFlow、PaddlePaddle等主流AI开发框架。它为上层提供了标准化的通信API,主要包括集合通信原语(如AllReduce、Broadcast)和点到点通信原语(如Send/Receive)。框架通过集成NCCL库,无需深入关注底层硬件细节,即可轻松实现跨多GPU的数据交互。
南向接口是硬件控制层,其核心基础是CUDA库。NCCL通过调用CUDA API来直接操控GPU的通信行为,确保与CUDA程序的无缝兼容和高性能。在跨节点通信场景下,NCCL还会调用RDMA(远程直接内存访问)API,利用GPUDirect RDMA技术,通过RDMA网络接口卡(RNIC)实现高效的跨节点数据直接传输,从而绕过CPU中转,大幅降低通信延迟和CPU开销。
二、NCCL工作流程
NCCL的核心工作流程可以概括为“拓扑感知 - 路径优化 - 链路构建 - 通信执行”四步闭环。通过这四步的协同,NCCL能够实现高效的跨GPU通信,最大化利用硬件资源并保障通信性能。
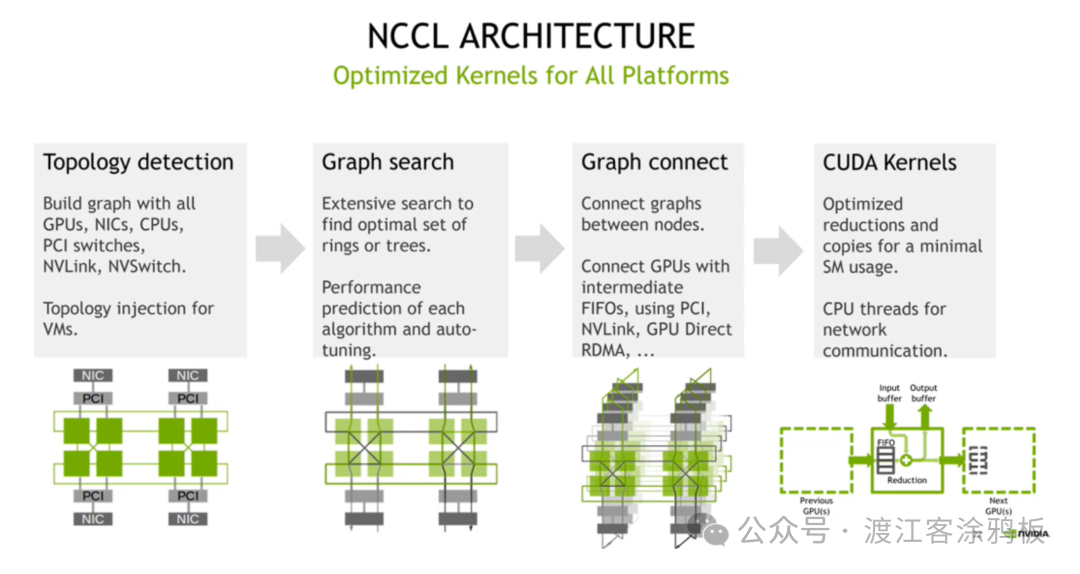
具体流程如下:
1. 拓扑发现阶段
NCCL在初始化时会自动探测整个分布式集群的硬件拓扑。它会全面扫描并构建一个包含所有GPU、NIC(网络接口卡)、CPU、PCIe交换机、NVLink、NVSwitch等组件的拓扑结构图,同时记录下各设备之间的连接关系、带宽、延迟等关键属性,为后续的路径优化提供完整的硬件数据基础。
2. 路径选择阶段
基于已构建的拓扑图,NCCL通过其内置的智能算法搜索最优的通信路径。算法会综合考虑通信场景(单节点内还是多节点间)、数据量大小、硬件连接特性等因素,自动决策是采用Ring(环形)拓扑还是Tree(树形)拓扑,确保选定的通信路径能够最大程度地规避带宽瓶颈,平衡带宽利用率和通信延迟。
3. GPU建联阶段
依据上一步选定的最优路径,NCCL开始搭建跨设备的物理通信链路。在单节点内部,主要通过PCIe总线或更高速的NVLink接口实现GPU间的直连通信。在多节点场景下,则借助GPUDirect RDMA技术,通过RNIC建立起无需CPU中转的直接通信链路,最终完成整个集群内所有GPU的高效互联。
4. 通信操作执行阶段
在搭建好的稳定链路上,NCCL开始执行由上层框架调用的具体通信任务。它支持点到点通信(Send/Receive)和各种集合通信(AllReduce、Broadcast等)原语。同时,NCCL会优化通信与计算的重叠执行(Overlap),确保数据传输能够高效、稳定地在后台完成,尽可能不阻塞前向计算和反向传播。
三、NCCL拓扑感知
NCCL强大的拓扑感知能力是其实现高性能通信的基石。它能够自动发现并充分利用系统的硬件拓扑结构,从而选择最优的通信路径和算法,这对于现代复杂的异构计算集群至关重要。
NCCL的自动优化策略体现在多个层面。首先,它会根据实时的硬件环境,包括GPU数量、NVLink域大小、NVLink速度、网络卡(HCA)速度以及PCIe拓扑结构等因素,自动选择最优的通信算法参数。
其次,NCCL支持动态拓扑感知。当系统拓扑发生变化时(例如在支持热插拔GPU的环境中,或是在动态资源分配的云平台上),NCCL能够重新检测硬件状态并动态调整其通信策略,以适应新的环境。
第三,NCCL的拓扑优化是多层次的。它不仅能够感知GPU之间的直接物理连接,还能识别更复杂的层次化结构,例如由NVLink构成的GPU小团体(NVLink Domain)、NUMA(非统一内存访问)节点、以及InfiniBand子网等。基于这些多层次的拓扑信息,NCCL能够构建分层的、高效的通信策略,充分利用不同层级连接所带来的带宽优势。
四、集合通信原语的高效实现
NCCL完整支持八种核心的集合通信原语,包括:AllReduce、Broadcast、Reduce、AllGather、ReduceScatter、AlltoAll、Gather和Scatter。这些原语是构建分布式深度学习训练逻辑的基础模块。
NCCL对每一种集合通信原语的实现都进行了深度优化。其中最重要的创新之一是,它使用单一的内核(Kernel)来实现每个集合操作,同时处理通信和必要的计算(如Reduce操作中的求和)。这种设计避免了传统方法中需要多次启动内核和进行内存拷贝所带来的开销,显著提高了执行效率。
在具体实现上,NCCL与CUDA编程模型深度集成。它使用CUDA流(Stream)来支持异步操作,每个集合操作都可以在指定的CUDA流中执行。这使得GPU上的计算任务和NCCL的通信任务可以方便地重叠进行,进一步提升了整体性能。开发者可以很容易地将NCCL操作集成到现有的基于CUDA流的任务管理体系中。
此外,NCCL还实现了智能的内存管理策略。对于训练过程中频繁使用的、形状固定的通信缓冲区(例如梯度张量),NCCL会对其进行缓存复用,避免频繁的内存分配与释放操作,从而减少内存管理开销并提升性能。
五、计算通信融合与硬件加速
计算与通信的融合是NCCL实现高性能的核心支撑,它有效破解了传统分布式训练中通信与计算串行执行导致的GPU空闲问题。NCCL通过将大张量分割成多个数据块进行独立通信,完美适配了梯度同步这类流水线场景。借助异步操作和CUDA流调度,通信得以在后台与计算并行执行。
在硬件层面,NCCL充分发挥了NVIDIA硬件生态的潜力。在节点内,它优先利用高带宽的NVLink进行GPU间通信;在跨节点时,则依靠GPUDirect技术族(如GPUDirect RDMA)来避免通过CPU中转数据,从而降低延迟。同时,NCCL持续优化对InfiniBand等高速网络的支持,提升多流并行通信的效率。
NCCL的版本迭代不断引入新的硬件加速特性。例如,NCCL 2.28版本引入的GIN(GPUDirect Integrated Network)技术,允许GPU直接控制网络操作,进一步消除了CPU干预带来的瓶颈。而NCCL 2.27版本则增强了对Direct NIC配置的支持。
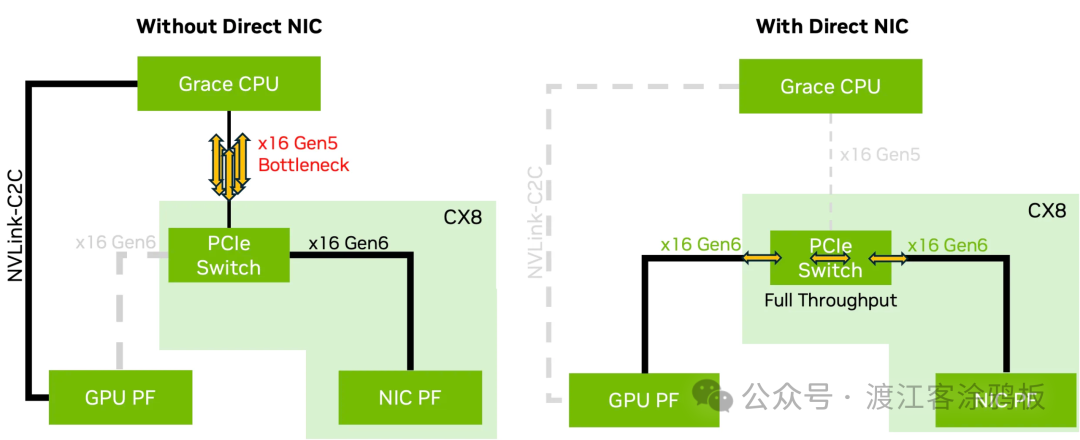
Direct NIC架构允许GPU和网络接口卡(NIC)之间通过PCIe Gen6等高速总线直接连接,从而绕过了经由CPU的传统路径,解决了可能存在的CPU瓶颈,实现了满带宽吞吐。
总结
NVIDIA集合通信库(NCCL)作为现代大规模深度学习训练的关键基础设施,已成为从单机多卡到万卡集群不可或缺的核心组件。通过本文的剖析,我们可以看到,NCCL通过其智能的拓扑感知机制,实现了对复杂异构硬件环境的自动适配;其对于集合通信原语的高效实现,特别是单内核融合计算与通信的设计,奠定了高性能的坚实基础;而对计算通信重叠的优化及对NVLink、GPUDirect等硬件特性的深度利用,则将其性能推向了极致。
对于从事AI大模型研发和分布式系统优化的工程师而言,深入理解NCCL的工作原理并熟练运用其API,无疑是提升训练效率、攻克规模化挑战的关键技能。如果你对分布式训练、高性能计算等领域有更多兴趣,欢迎到云栈社区与更多的开发者一起交流探讨。
参考资料:
 发表于 2026-2-8 06:17:08
|
查看: 247|
回复: 0
发表于 2026-2-8 06:17:08
|
查看: 247|
回复: 0
