前几天在上海参加了一个关于华为 Unified Bus 的会议。会上有个观点让我深有同感:这(大模型推理)是一次体系结构上的机会,有很多可以进入教科书的事情可以一起去做。 最近 Xiaoyu Ma 和 David Patterson 的论文《Challenges and Research Directions for Large Language Model Inference Hardware》也表达了类似的看法。随着推理业务规模今年起超越训练,并可能在年底达到 4:1 到 10:1 的比例,今年或许才是推理基础设施真正的元年。能与同行一起,在这个时代做些或许能载入教科书的工作,令人倍感振奋,这也应是一个技术团队的追求所在。
当前现状及挑战
1.1 计算芯片微架构
从计算维度看,现有处理器微架构已面临诸多瓶颈。以数据中心内三颗典型的 Socket(CPU、GPU、DPU)为例:
- CPU 的微架构在过去十年演进相对平缓,已趋于极致,但伴随 Agentic Infra 的商用化,也催生出新的机会。
- GPGPU 基于 SIMT 抽象和 TensorCore 的发展解决了大量问题,但在当前推理负载下逐渐遇到瓶颈。
- DPU 的微架构定义仍不清晰,用途不明,难以从体系结构上阐明其与 CPU、GPU 的本质区别。像 BlueField-4 这样集 Grace CPU、DSA、PSA 于一体的“缝合怪”,无论从功能还是 PPA(性能、功耗、面积)角度看,都难以体现其体系结构上的合理取舍。
1.2 互连架构
除微架构外,互连架构与协议也争议颇多。NVLink、UALink、SUE、ESUN,以及国内 OISA、UB、ETH-X 等多种协议并存。其中,有些设计甚至未能理清内存模型,仅仅将 ScaleUP 视为传输协议。
1.3 存储架构
HBM 产能受限、DDR 价格飞涨,加之 Agent 执行对 CPU 的大量需求,进一步加剧了内存供应的紧张局面。与此同时,HBF、3D-DRAM、3D-SRAM 等新介质的出现,也带来了新的挑战与机遇。另一个关键问题是,这些介质应以何种互连方式接入整个系统。
从推理Infra看微架构
数据中心所需的 CPU、GPU、DPU 究竟有何本质区别?这个问题在 Agentic Infra 场景下尤为突出。三者应如何协同?唯有先厘清这些问题,才能进一步探讨其微架构与互连设计。
2.1 CPU微架构
随着 Agent 今年开始大规模部署,对 CPU 核密度提出了更高要求。例如 Intel Clearwater Forest (CFR) 将拥有 288 核,AMD Venice 也有 256 核,预计到 2028 年,单芯片核数可能再次翻番,以满足高密度 Agent 沙箱执行环境的需求。
高密度部署的实际挑战来自内存子系统和片上网络(NOC),以及高密度下的中断处理等细节。公开可说的是,平均每核的内存带宽受“内存墙”限制正在快速下降。这种情况下,是否会出现类似 CXL 的总线扩展,或统一到 ScaleUP 协议下进行内存池化?
另一个视角涉及 GPU 互连。NVLink C2C 真的是最佳方案吗?还是应统一将 CPU 直接接入 ScaleUP 总线?这触及内存模型等深层问题。
2.2 GPU微架构
这方面的分析在之前的文章《Inside Nvidia GPU: 谈谈Blackwell的不足并预测一下Rubin的微架构》中已有较深入探讨。核心问题在于,当 TensorCore 和 TMA 都能被单线程发起后,用 SIMT Warp Specialization 来处理 Mbarrier 的代价和延迟非常高,代码也显得臃肿。为 SM 引入一个超标量核心来辅助 Warp 调度和这些特定领域架构(DSA)的调用,或许是更好的权衡。
近期 NVIDIA 收购 Groq 也反映了其在推理方面面临的挑战。后续对 Groq 微架构的分析(如《谈谈那个被NV看上值20B的Groq》及《Nvidia如何整合吸收Groq的技术》)可作参考。
在 3D-DRAM 和 HBF 等技术路径之外,如先前文章分析的,集成 PNM(近内存计算)能力的 3D-SRAM 或许是更好的选择。
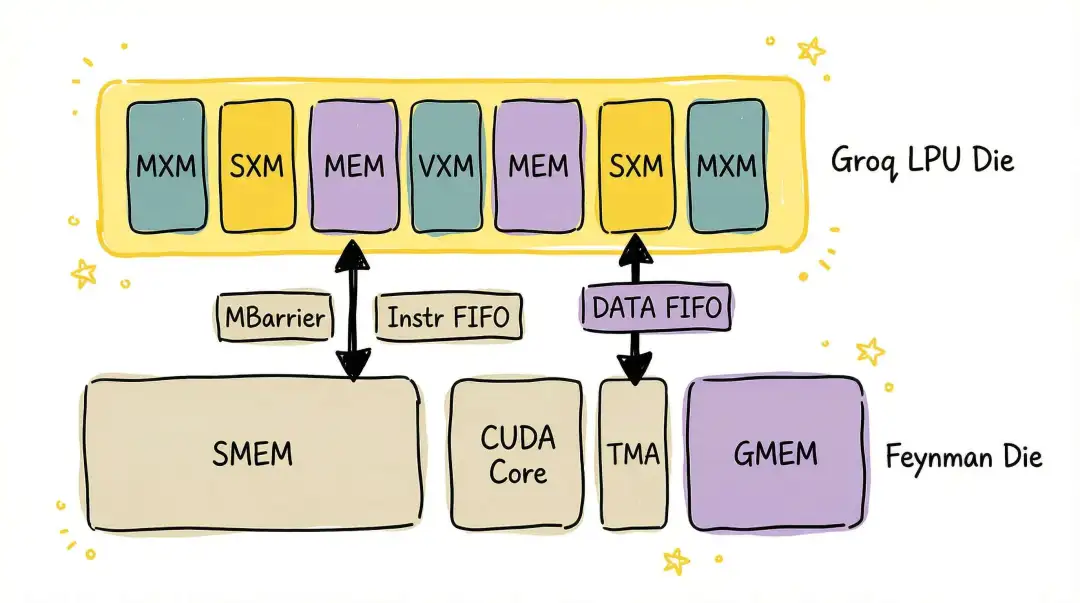
当然,3D-SRAM 路径仍需更多分析。例如,在基于 3D-SRAM 的架构下,全局内存(Global MEM)拥有更大容量来承载带宽延迟积(BDP)时,延迟约束的放宽对 GPU 解决内存墙问题,乃至实现内存池化,都有显而易见的好处。
2.3 DPU微架构
根本问题在于:什么是 DPU?在什么场景下需要 DPU?很多人只看到了算力卸载(Offload),却沉迷于此。这里引用夏 Core 在《要做一个政治正确的DPU哦》[1] 中的一段话:
换位思考一下,你如果是cloud的运营者,扪心自问,面对稳定大于一切的KPI,你想不想要中国政府对街道办级的把控力? 某些US的XPU经常性升级一些patch,你真的不想稍微防备一下吗? 如果某天触发它疯狂对外DDOS怎么拷住它?
一个合格的cloud运营者,一定要通过能把控的DPU获得对整个cloud深入到毛细血管的把控力。
题外话:如果购买的第三方DPU出了问题,cloud的运营者大概率得背锅吧。但如果是自家的DPU出问题,还可以选择要不要干掉不听话的DPU芯片负责人,换个自己人……
实质上,DPU 是为满足云的特殊需求——解决弹性和多租户问题——而存在的。多租户进而引入了安全隔离需求。但商业 DPU 却在这方面捅过娄子(见《世界终究是属于草台班子的-2》)。
这些“草台班子”可能并未真正做过云,甚至其口中的“Neocloud”仍是 IDC 卖卡卖盒子的思路。
除了安全因素,DPU 还需适配 GPU 微架构,优化 I/O 处理,提供更适合 GPU 初始化的接口。显然,像 BF4 那样 Grace + DSA + PSA 的缝合架构是错误的,其微架构需要更多改变,尽管这部分内容无法对外详述。
从推理Infra看系统架构
从体系结构视角看,将 GPU 作为数据中心的一等公民,以 GPU 为中心重构服务器,并在 ScaleUP 总线上扩展内存、存储和 I/O,将成为未来几年体系结构演变的关键。
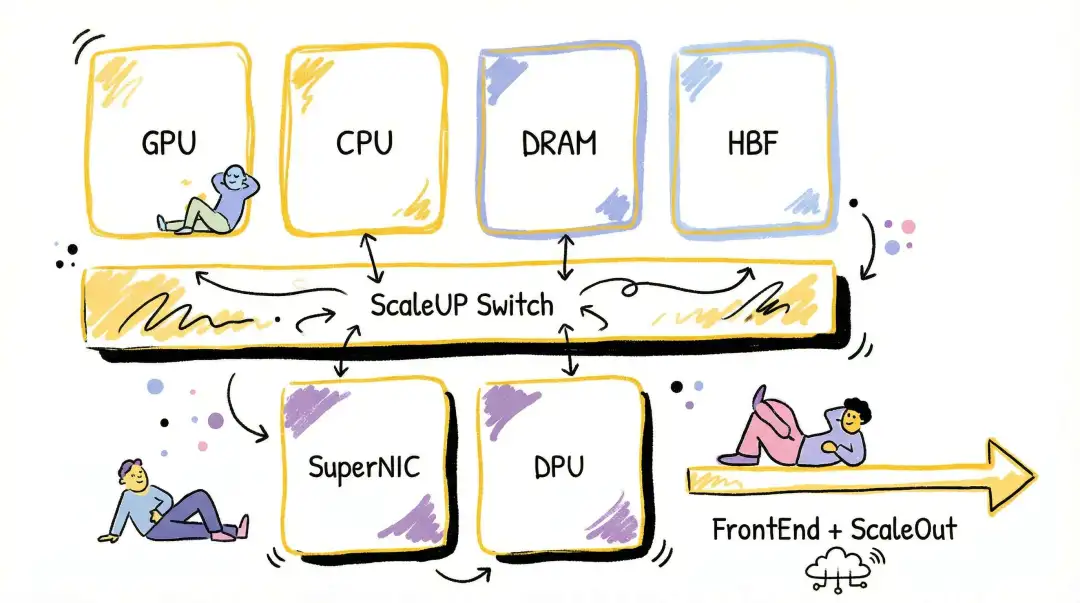
其背后原因及推理基础设施的详细分析,在《谈谈基于ScaleUP的存储扩展和三网融合》中有阐述。另一篇《大语言模型推理硬件的挑战与研究方向》也提供了很多分析。
但三网融合的目的究竟是什么?为什么要把存储拉入 ScaleUP,或让存储接入 ScaleOut? 这一点此前并未阐述清楚,下文将详细展开。
对于存储的需求,包含 KVCache、RAG Cache、Agent Memory 等多个场景,我们以 KVCache 为例进行分析。
3.1 从KVCache谈起
根本原因在于,Agentic 负载或代码任务等场景下,上下文(Context)越来越长。基于 HBM 扩展容量受限严重。即便到 Rubin 架构,每个 GPU 拥有 288GB HBM4,但对于近百万上下文长度的任务,GPU 的并发处理能力仍受极大制约。
当前主流模型通常每个 Token 需要 40KB ~ 70KB 的 KVCache。当然,算法层面如 Sparse Attention / Linear Attention 在进行优化。
- Linear Attention:假设采用 3:1 的 Linear:Full 混合注意力,Full 层为15层,head_dim=128,num_attn_head=64,GQA=8,FP4量化。单个 Token 约需 15KB(已是较小估计)。对于 Linear 层,通常每 500~1000 个 Token 存储一次状态快照,200K 上下文下,其存储需求远小于 Full 层。
- Sparse Attention:以 DeepSeek DSA 为例,Indexer 需存储
seq_len x (1 + 1//block_size) * indexer_head_dim。设 seq_len=200K, block_size=128, indexer_head_dim=128,则开销约为 25,800KB。对于 MLA 部分,虽然 Sparse Attention 基于 indexer_top_k=2048 仅选择 2048 个 K 参与运算,但经计算,在 200K 上下文中,几乎每个 Token 的 Key 都会被选中至少一次。因此 KVCache 用量为 layers x seq_len x (kv_lora_rank + qk_rope_head_dim) = 61 * 200K * 576 ≈ 7027,200KB,即单个 Token 约需 35KB(若用 NVFP4 量化,则需 17.5KB)。对于 Sparse Attention,解码阶段的访存容量会小很多,仅需全量访问 Indexer 的 K Cache,计算出 TopK 后仅需访问 TopK 个 MLA 的 Key。
容量分析
按单卡 32 并发、Coding/Agent 类应用平均 200K 上下文、单个 Token 15KB 计算,约需 93GB。按当前主流模型则需 256GB~448GB 来存储 KVCache,显然 GPU HBM 容量不足。若未来上下文长度增至 400K~1M,则单卡需要超 1TB 容量。
应对容量约束,通常需要 HiCache 或 Mooncake 这类方案来充分利用主机 CPU 内存。
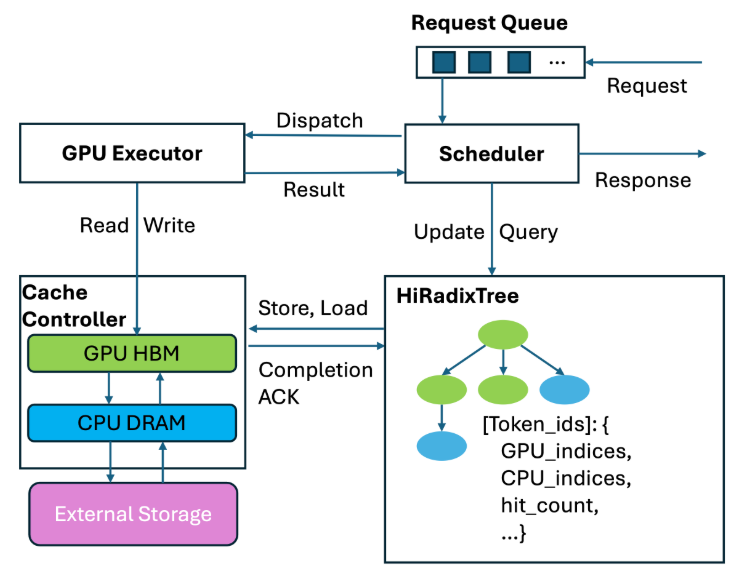
针对超长上下文,也有一些 Chunk Prefill 处理来降低显存 OOM 风险。按当前硬件架构,通常分为两种形态:
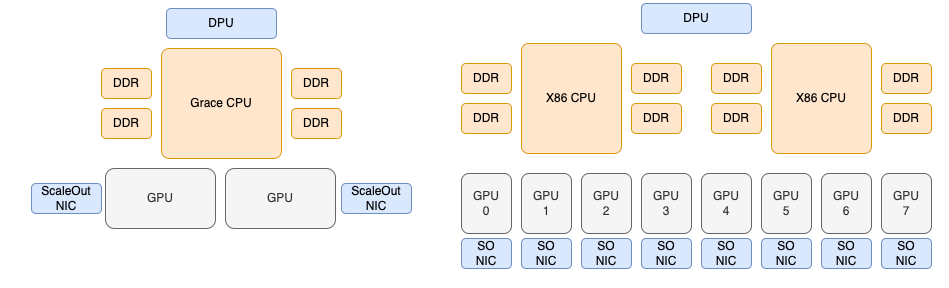
- 超节点(如NVL72):Blackwell 架构下 Grace CPU 的 DRAM 容量为 480GB,Rubin 架构下 Vera CPU DRAM 为 1.2TB。仅针对推理 Batch 所需的 KVCache,容量基本足够。
- 8卡服务器:通常这类服务器主机内存容量,以 Venice 这类 CPU 16通道、单条128GB DDR内存计算,双路平台可支持 4TB 内存。理论上,每个 GPU 卡分摊的内存也够用。
但考虑到推理过程中系统需要缓存更多用户请求,以及未来 DeepSeek 这类模型使用的 Engram 对主机内存的占用,容量仍可能不足。近期也出现了基于 CXL 进一步扩展主机内存容量的方案,例如阿里云的 Beluga。
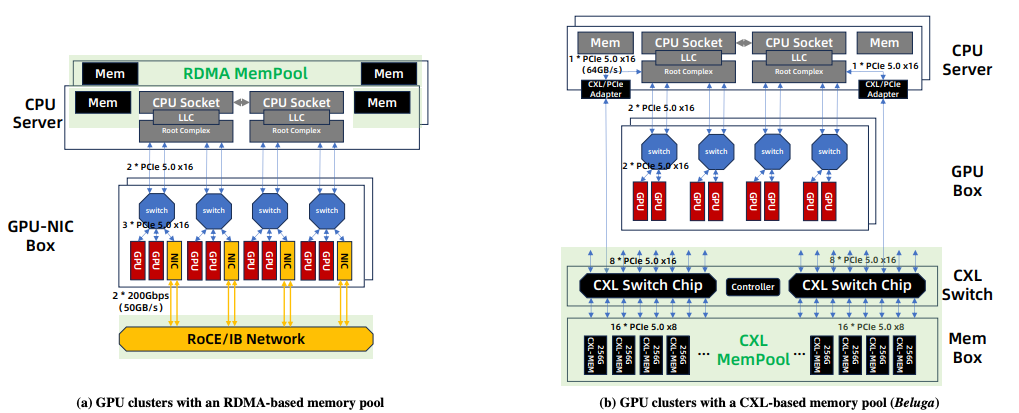
具体可参考论文《Beluga: A CXL-Based Memory Architecture for Scalable and Efficient LLM KVCache Management》[2]。这样就构成了一个多层级存储系统。
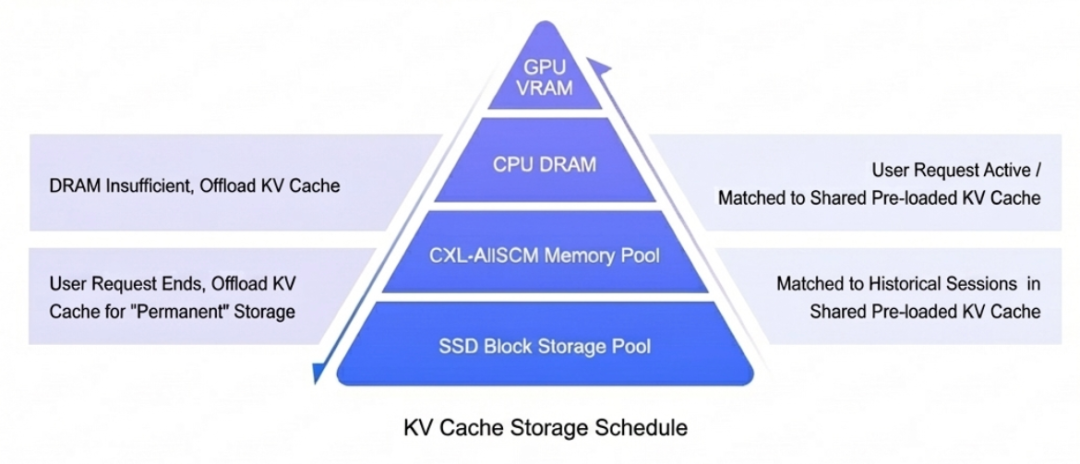
对于容量的需求有一个大致的结论
对于活跃请求(Active Request),由于显存不足,很大程度上需要与 CPU DRAM 快速置换,并需要外置的内存池和外部的 SSD 存储池来保存历史会话。历史会话的保存时长需根据业务差异考虑(简单 QA、多轮对话、Agent/Coding 场景各有不同)。
例如,在 Coding 场景中,处理大型开源项目可能耗时数周,上下文前缀匹配的概率较高,这些内容宜拥有更长生命周期。而在 Agent 执行场景中,不同用户的执行序列前缀匹配概率极低,可能只需维持数分钟到数十分钟的生命周期,用于 Active Session 的 KVCache 存储。对于企业内团队协作的研究项目,则可能需要在租户粒度上维持更长的生命周期。
带宽分析
带宽需求主要来自两方面:
- Prefill 阶段:超长上下文易导致 GPU 显存 OOM,需要 Chunk Prefill 或 CP 并行处理,这对 KVCache 命中部分的加载和写出有带宽需求。
- PD分离场景:Prefill 节点的 KVCache 向 Decode 节点传输的带宽约束。Prefill 到 Decode 的传输很大程度上可通过 Layerwise 传输进行重叠。
具体带宽需求需与计算重叠设计,并与模型架构强相关。假设按前文计算,200K Tokens 每个 Token 15KB,BatchSize=32,Layerwise 传输单层约需 6.4GB。使用 800Gbps 前端网络传输约需 60ms;使用 6.4Tbps ScaleOut 网络传输仅需 7.5ms。
从物理服务器看,带宽约束分两种情况:
- 超节点:连接 GPU 的 NVLink C2C 带宽足够。若使用主机自带 NVMe 盘,带宽也足够。若使用外部存储集群,潜在瓶颈在前端的 DPU。
- 8卡服务器:通常受限于主机内存子系统带宽以及 CPU 到 GPU 的 PCIe 带宽。
从外部存储获取 KVCache 的带宽需求,与实际请求负载、缓存命中率、负载均衡调度方式有关。此外还需考虑缓存集群内的热点偏斜问题:KVCache 本身是否需要副本以降低单点热点?或单点是否需要更大带宽来避免负载偏斜导致的长尾延迟?
这就引出一个讨论:能否通过 ScaleOut 网络直接接入存储? 优点是数据无需经前端网络通过 CPU 节点中转,但也带来挑战,特别是对 8 卡服务器而言,需要极高的拥塞控制技巧,并避免影响端到端(EP)流量。
3.2 从服务调度的视角
从调度视角看,虽然许多活跃请求需要卸载到主机 CPU 内存,但将历史会话存放到本地 NVMe 盘也存在问题。即 NVIDIA 定义的 G3 存储层的处理。
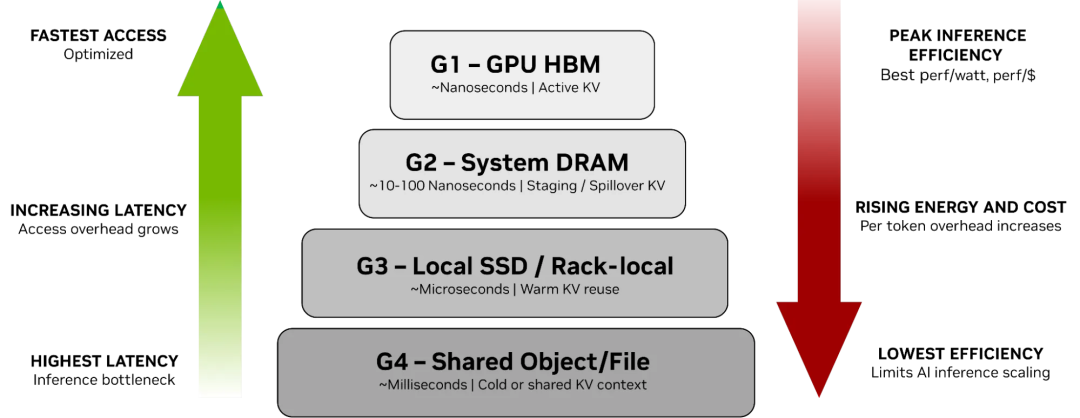
对于一个大规模、多模型的 MaaS 推理平台,使用本地 SSD 在资源弹性伸缩场景下面临挑战。例如,在夜间需要释放实例并售卖给其他租户时,通常需将本地 SSD 中的内容备份到 G4 共享存储,并擦除本地内容再售卖。又如在高峰时期需要分钟级扩容,将运行 A 模型的实例快速切换至运行 B 模型时,A 模型在本地 SSD 中的 KV Cache 需快速备份到 G4 共享存储。针对此类场景,NVIDIA 也在构建 Rack/Pod Level 的存储,但当前技术限制使其仅能实现 Rack Level。真正能实现数百 PB 容量、数百 TB/s 带宽的存储系统,仍需云服务提供商级别的系统能力。
从调度视角看,实质问题是:针对温数据 KV 复用场景,G3 层所需的微秒级延迟,能否通过集中池化的可用区(AZ)级共享存储来提供?
3.3 Warm KV存储选择: 集中式? 分布式?
关于 G3 和 G4 存储的构建选择,让人联想到 IBM DB2 的 PureScale 和 Oracle RAC 的 CacheFusion 之间的区别。
PureScale
在 IBM 大型机中,有一个独立的耦合设施(CF)。任何成员需要数据块时都向这个集中式的 CF 发送请求,CF 内部有全局锁管理器和组缓冲池。
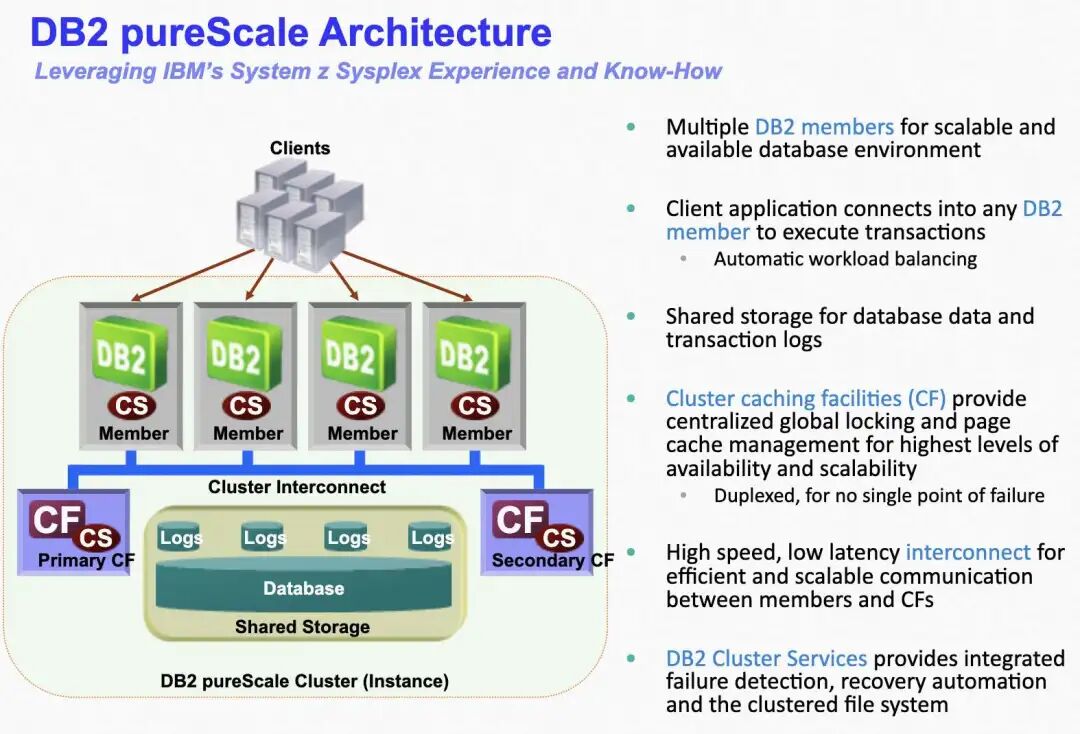
CacheFusion
Oracle CacheFusion 采用分布式锁和分布式全局资源目录(GRD)机制。例如节点 B 请求一个数据块:
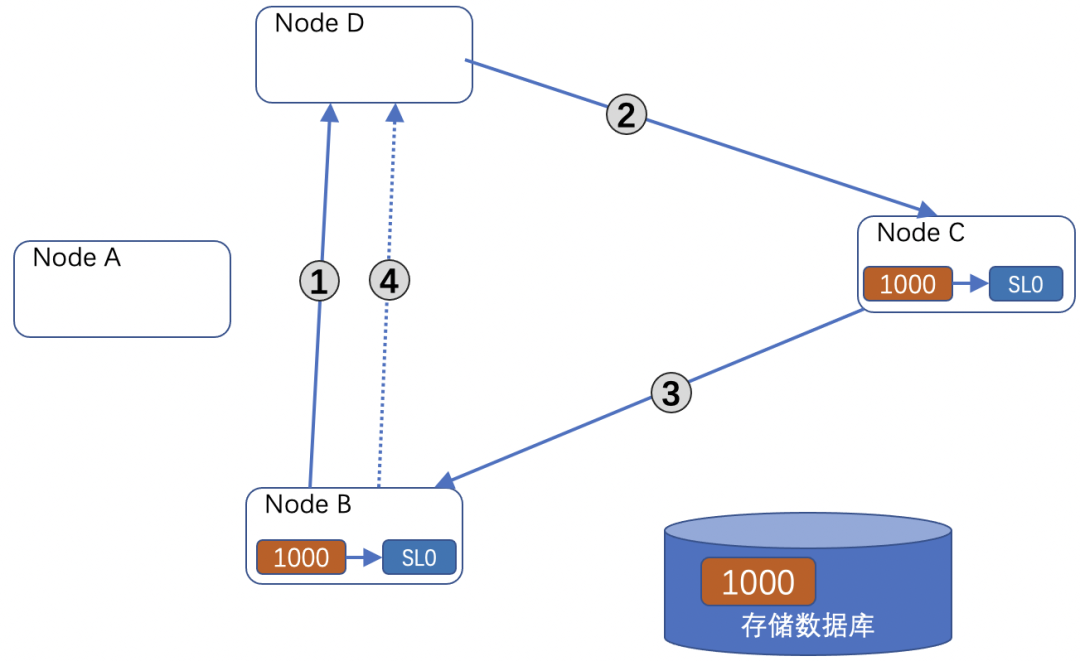
- 节点 B 通过数据块哈希找到主节点 D,发起读取请求。
- 主节点 D 检查资源锁授权队列,发现节点 C 持有该块,且锁属性(SL0)与 B 的读取请求兼容,直接向 B 授予锁,并通知 C 发送数据给 B。
- C 发送数据给 B。
- B 收到数据后,异步通知主节点 D 更新资源锁信息。
具体分布式集群管理和锁机制可参考前文《大模型推理系统(1)--先从分布式系统DEC VAXCluster谈起》。两种方案对比如下:
| 特性 |
Db2 pureScale |
Oracle RAC (with Cache Fusion) |
| 核心架构 |
中央集权式协调 |
分布式对等协调 |
| 缓存一致性机制 |
中央锁管理器 (in CF) + 组缓冲池 (GBP) |
Cache Fusion 技术 + 全局资源目录 (GRD) |
| 关键组件 |
成员 (Members) + 集群缓存设施 (CF) |
数据库实例 (Nodes) + 私有高速互联网络 |
| 数据块传输路径 |
成员 ↔ CF ↔ 成员 (通常不直接点对点传数据) |
成员 ↔ 成员 (通过高速互联网络直接传输) |
| 锁管理 |
集中式:所有锁信息由 CF 统一管理 |
分布式:锁信息分布在所有节点上,每个节点“主宰”一部分资源 |
PureScale 方案的优点:
- 极低的协调开销和出色的扩展性:锁管理集中,成员间无需直接“交谈”,只需与高效的 CF 通信。这使得扩展到非常多节点时,仍能保持低开销和近线性性能增长。
- 应用透明性:对应用而言,集群就像一个超大的、永不停机的单机数据库,无需修改应用。
- 快速的故障恢复:成员宕机时,CF 保留了其所有“脏”数据和锁信息,其他成员可迅速接管,实现秒级故障切换。
PureScale 的缺点(相对于CacheFusion):
- 中央组件的瓶颈和单点风险:CF 可能成为性能瓶颈和单点故障。生产环境需部署双活 CF,增加了复杂性和成本。
- 数据传输路径可能更长:某些场景下数据需经 CF 中转,路径长于 RAC 的直接点对点传输,但 PureScale 认为其高效协调的总体收益大于路径开销。
3.4 推理存储Infra架构
承接前一节,温 KV 构造实际分为两种方案:
第一种方案类似 CacheFusion,复用 GPU 实例的主机内存和本地 SSD 资源构建分布式 KV Cache 层,即构成 NVIDIA 定义的 G3 层存储。
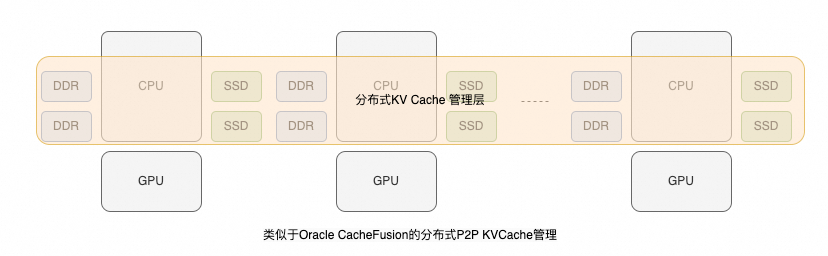
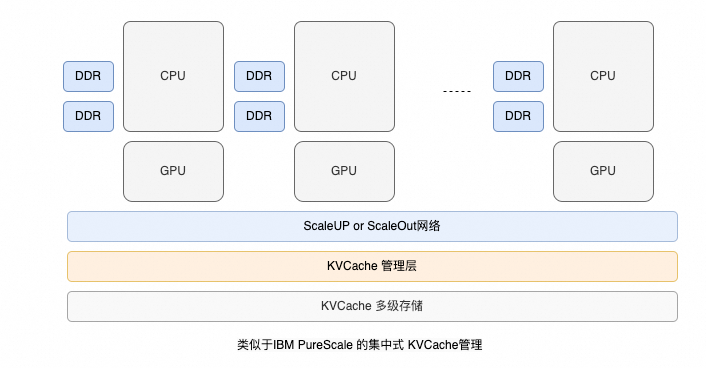
由于推理业务有极致的弹性需求,从云服务提供商视角看,我个人更倾向于类似 PureScale 的方案:
- 对 GPU 实例做更好的存算分离部署,尽量不使用其本地 SSD。这样 GPU 实例可以更灵活地分配给不同租户、运行不同模型。
- 类似 PureScale 的方案,集群的弹性扩缩容会更方便。
- 即使在此方案下,本地主机内存仍可作为 KVCache 的第一级缓存,但需写回(Write Back)到全局的 KV Cache 内存池。
- KVCache 管理层负责管理全局的基数树(Radix Tree)、更新相关的锁资源以及制定换出(Evict)到存储池的策略。
当然,具体实现和架构就不展开了。仅从体系结构视角看,通过 ScaleUP 或 ScaleOut 接入存储的需求很可能会发生。如果你对这类深度技术探讨感兴趣,欢迎来云栈社区交流。
参考资料
[1] 要做一个政治正确的DPU哦: https://zhuanlan.zhihu.com/p/550599378
[2] Beluga: A CXL-Based Memory Architecture for Scalable and Efficient LLM KVCache Management: https://arxiv.org/pdf/2511.20172
 发表于 2026-2-10 07:45:39
|
查看: 188|
回复: 0
发表于 2026-2-10 07:45:39
|
查看: 188|
回复: 0
