CPU(中央处理器)是计算机系统真正的“大脑”,它负责执行程序中的各类指令。无论是运行游戏、处理文档还是播放视频,这些看似简单的操作背后,都是CPU对数十亿条底层指令的高速处理。理解其内部结构与工作流程,是进行系统与应用级性能优化的基础。
一、核心组件
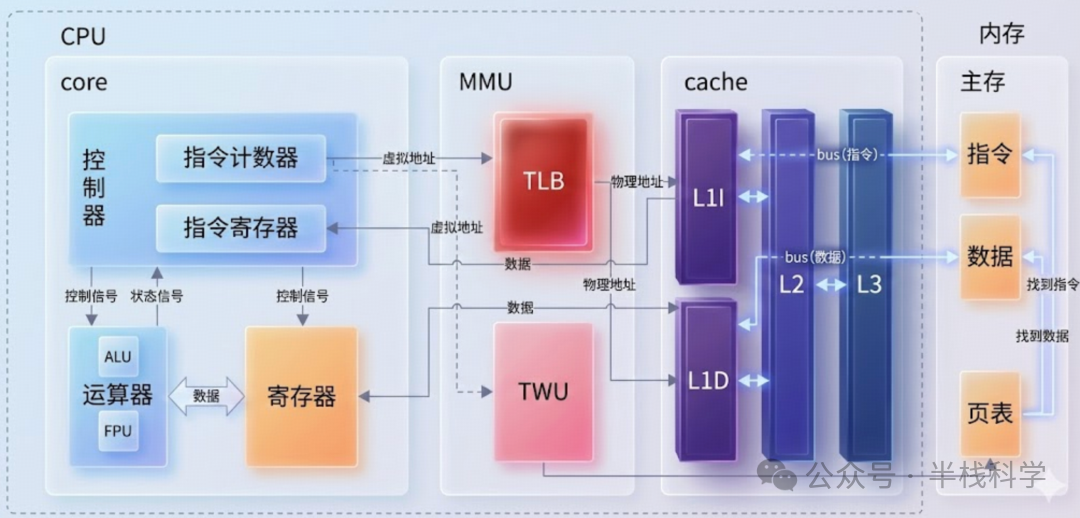
1. 算术逻辑单元(ALU)、浮点单元(FPU)与控制单元(CU)
- ALU(算术逻辑单元):负责执行基础的算术运算(加、减、乘、除)和逻辑运算(与、或、非、异或),以及移位操作。它通常接收两个操作数作为输入,并输出运算结果。
- FPU(浮点单元):专门用于处理浮点数运算和高精度整数运算,部分FPU还支持向量(SIMD)运算,是进行科学计算和图形处理的关键组件。
- CU(控制单元):作为CPU的指挥中枢,它负责协调内部所有部件有序工作,确保程序自动、连续地执行。
控制单元的工作流程就像一个精密的调度中心:
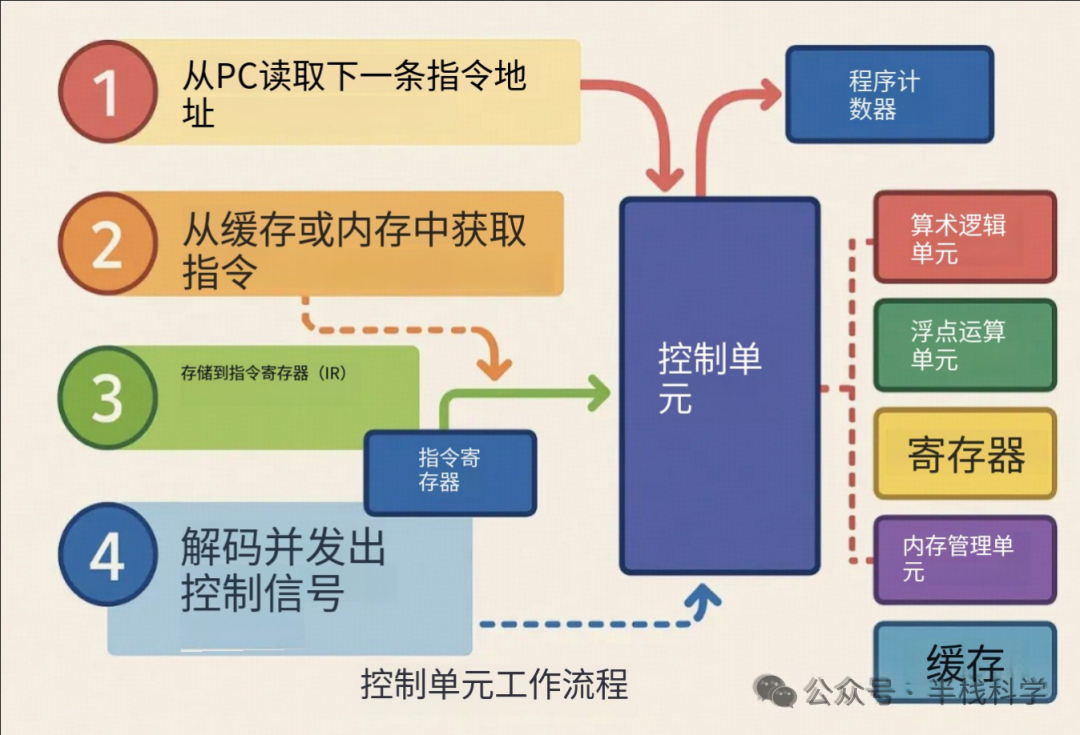
- 从程序计数器(PC)中获取下一条指令的地址。
- 根据地址,从高速缓存或主内存中抓取指令。
- 将指令存入指令寄存器(IR)。
- 对指令进行解码,并发出相应的控制信号,指挥ALU、FPU、寄存器等其他部件协同工作。
2. 寄存器、总线与时钟
2.1 寄存器(Registers)
寄存器是CPU内部速度最快的存储单元,容量极小但访问延迟极低。主要分为两类:
- 通用寄存器:用于临时存放操作数和中间结果。
- 特殊寄存器:
- PC(程序计数器):存储下一条待执行指令的地址。
- IR(指令寄存器):存放当前正在执行的指令。
- SR(状态寄存器):保存上一条指令执行后产生的状态标志,如零标志、进位标志、溢出标志等,常用于条件跳转判断。
2.2 总线接口(Bus Interface)
总线是CPU与内存、外设通信的“高速公路”,主要分为:
- 数据总线:负责搬运实际的数据。
- 地址总线:用于传递内存或I/O设备的地址信息。
- 控制总线:传输读写命令、中断信号等控制时序。
总线的宽度(位数)和时钟频率共同决定了CPU与外部数据交换的带宽。
2.3 时钟(Clock)
时钟为CPU所有操作提供统一的节拍,确保各部件同步工作。时钟频率(以GHz计)越高,理论上CPU在单位时间内能够处理的指令就越多。寄存器通常在时钟信号的上升沿或下降沿进行数据更新。
3. 三级高速缓存(Cache)
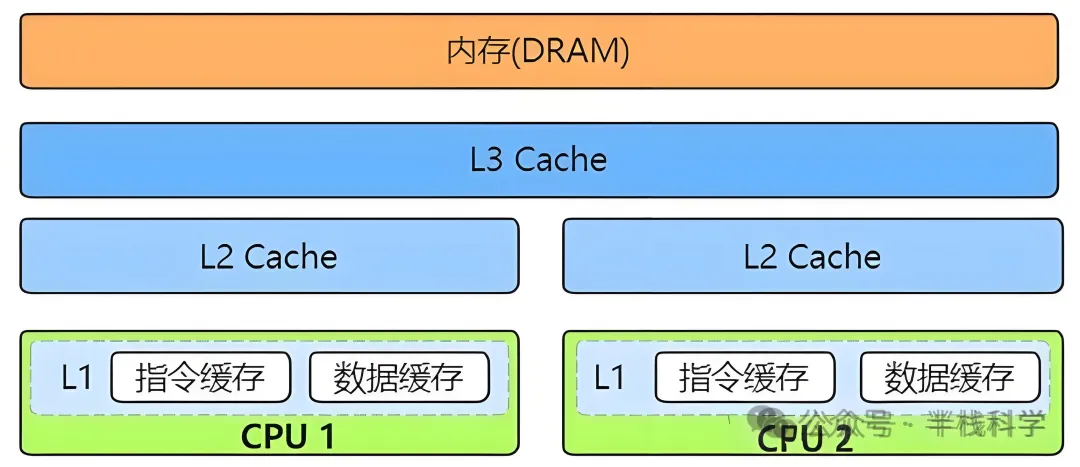
为了解决CPU与主内存(DRAM)之间的速度鸿沟,现代CPU普遍采用多级缓存结构。
- L1 Cache(一级缓存):速度最快,容量最小(通常几十KB),分为指令缓存和数据缓存,被单个核心独占,旨在存放最“热”的数据和指令。
- L2 Cache(二级缓存):速度与容量介于L1和L3之间,通常也是核心独享,作为L1缓存的补充,减少对L3缓存的访问压力。
- L3 Cache(三级缓存):容量最大(可达数十MB),速度相对较慢,通常由同一CPU芯片上的所有核心共享,其核心目标是减少对主内存的访问,这对提升多核并行计算性能至关重要。
| 对比项 |
L1 Cache |
L2 Cache |
L3 Cache |
| 位置 |
单核心独享 |
单核心独享 |
多个核心共享 |
| 速度 |
最快 |
中等 |
较慢 |
| 容量 |
最小 |
中等 |
最大 |
| 主要作用 |
直接服务执行单元 |
缓解L1缺失,减轻L3负担 |
减少访问主内存的延迟 |
4. 内存管理单元(MMU)
MMU(内存管理单元)负责将程序使用的虚拟地址转换为物理内存的物理地址,这是现代操作系统实现内存隔离、分页机制和保护的核心硬件支持。
- TLB(转换后备缓冲区):一个专用于缓存地址转换结果的高速缓存。TLB命中可以几乎零延迟地完成地址翻译。
- 页表遍历(Page Table Walk):如果TLB未命中,MMU则需要根据保存在主内存中的多级页表,一步步查找对应的物理地址,这个过程耗时较长。高效的MMU设计是保证系统内存性能的关键。
二、指令执行流程
经典五级指令流水线
取指(IF) -> 译码(ID) -> 执行(EX) -> 访存(MA) -> 写回(WB)
这是经典的RISC架构指令执行模型。每条指令都被分解为这五个阶段,并且像工厂流水线一样,多条指令的不同阶段可以并行执行,从而极大提升了CPU的指令吞吐率(IPC)。
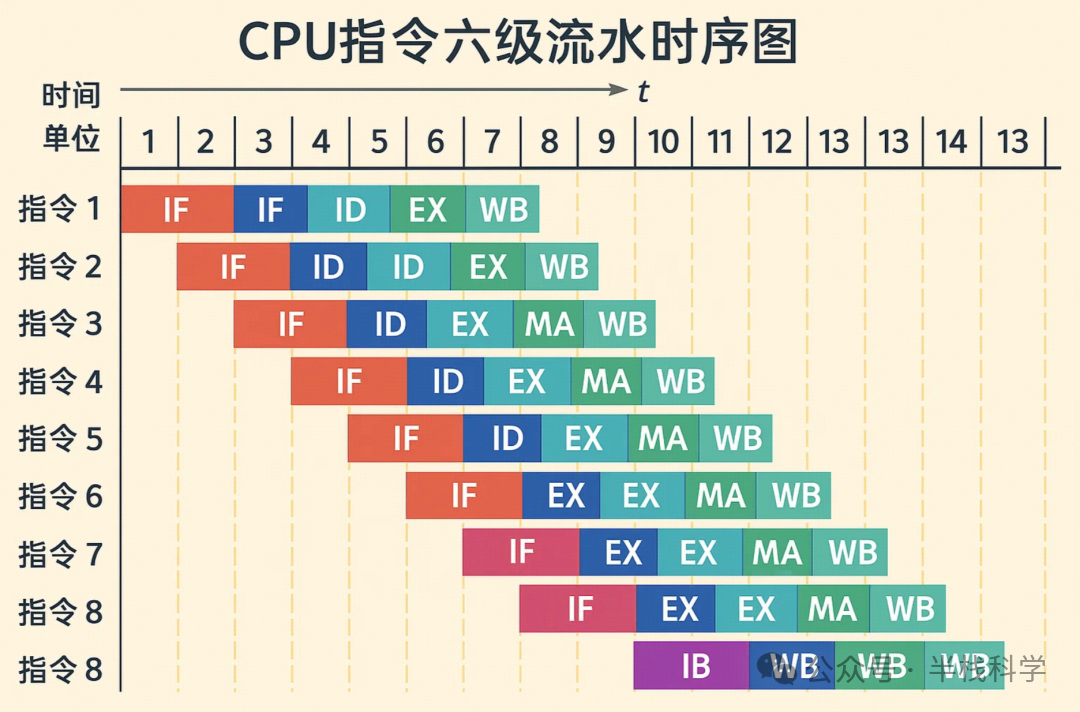
1. 取指(Instruction Fetch)
控制单元根据程序计数器(PC)中的地址,从指令缓存或内存中读取下一条指令,并将其存入指令寄存器(IR)。同时,PC值自动更新(如PC+4),指向再下一条指令。
2. 译码(Instruction Decode)
控制单元解析IR中的指令操作码,确定指令类型(如加法、跳转)以及所需操作数的来源(来自哪个寄存器或立即数)。同时,从寄存器文件中读取操作数,并准备好执行阶段所需的控制信号。
3. 执行(Execute)
算术逻辑单元(ALU)或浮点单元(FPU)根据译码结果执行实际的运算。此阶段可能设置状态寄存器(SR)中的相关标志位。
4. 访存(Memory Access)
如果指令需要读写内存(如加载Load、存储Store指令),CPU会通过MMU将虚拟地址转换为物理地址,然后访问数据缓存或主内存来完成数据读写。
5. 写回(Write Back)
将执行或访存阶段得到的最终结果写回到目标寄存器中,更新处理器的状态。至此,一条指令执行完毕。
三、多任务与CPU中断切换机制
即使在多核CPU出现之前,计算机也能“同时”运行多个程序,这得益于中断机制和上下文切换。单个CPU核心通过极短时间片(纳秒/微秒级)的快速轮转,在多个进程间切换,制造了并行执行的假象。
中断机制的核心在于上下文切换,即保存当前执行流的状态,以便后续能准确恢复。其核心过程如下:
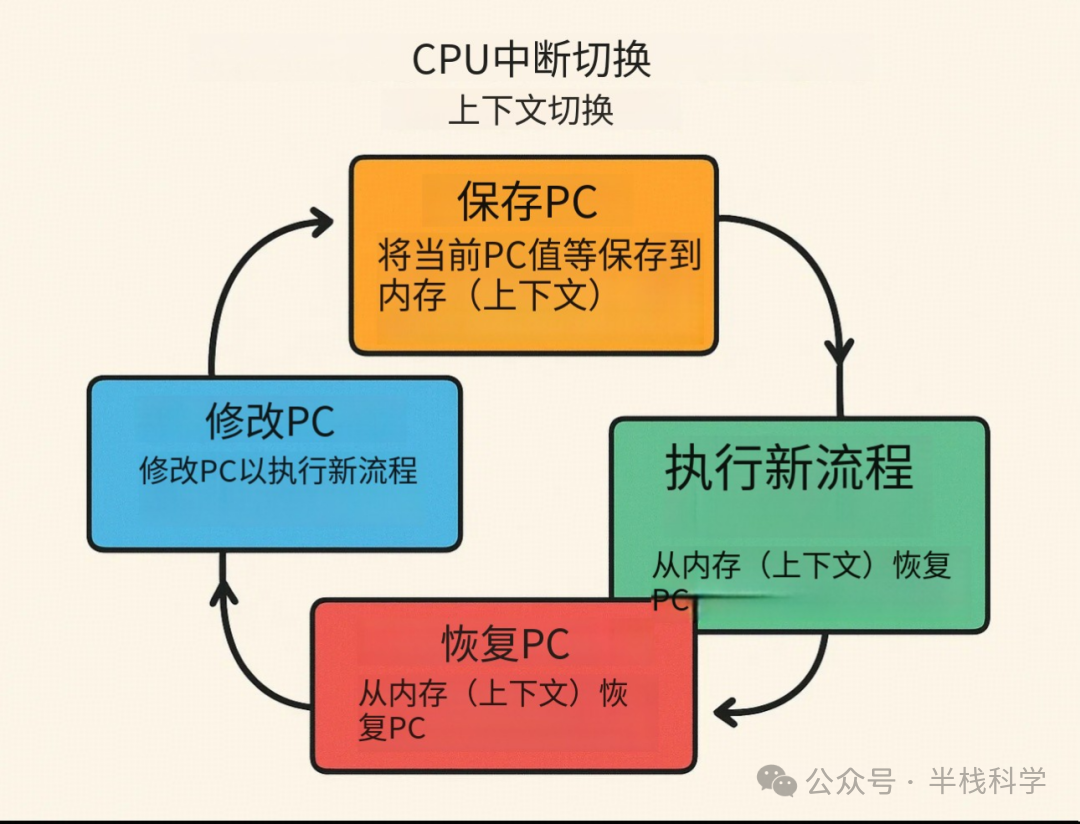
- 保存现场:当发生中断或时间片用完时,CPU将当前进程的PC值、通用寄存器内容等关键状态保存到内核栈或进程控制块(PCB)中。
- 加载新现场:修改PC值,使其指向待运行进程(或中断服务程序)的入口地址,并从其保存的上下文中恢复寄存器状态。
- 执行新流程:CPU开始执行新的指令流。
- 恢复原现场:当新流程执行完毕(或中断返回),CPU将之前保存的原进程上下文重新加载,PC跳转回原地址,继续执行。
这种机制是操作系统实现多任务并发、响应外部事件的基础。
四、现代CPU架构的高级优化特性
为了进一步提升性能与能效,现代CPU集成了多种复杂的高级特性:
- 超标量(Superscalar):允许CPU在一个时钟周期内,从指令缓存中取出并发射多条指令到多个不同的执行单元中并行执行。
- 超线程(Hyper-Threading):将一个物理核心虚拟为两个逻辑核心,共享ALU、缓存等执行资源,通过填补流水线空闲,提升单核的多线程处理能力。
- 乱序执行(Out-of-Order Execution):硬件动态分析指令间的依赖关系,在不影响最终结果的前提下,重新排列指令的执行顺序,以充分利用空闲的执行单元,提高吞吐量。
- 向量指令集(SIMD):如Intel的SSE/AVX,ARM的NEON。单条指令可同时对一组数据(如8个浮点数)执行相同操作,极大地加速了多媒体处理、科学计算和人工智能中的矩阵运算。
- 分支预测(Branch Prediction):在条件跳转指令(如if-else)的结果确定之前,CPU预先猜测其跳转方向并提前取指执行,以减轻流水线因等待而“停滞”的风险。
- 动态电压频率调整(DVFS):根据CPU的实时负载,动态调节其工作电压和频率,在满足性能需求的同时实现能效优化。
|  发表于 2025-12-5 16:16:36
|
查看: 234|
回复: 0
发表于 2025-12-5 16:16:36
|
查看: 234|
回复: 0
