在构建基于检索增强生成(RAG)的AI问答系统时,你是否遇到过这样的尴尬局面?系统虽然接入了知识库,但大模型有时会对检索到的、其实并不相关的文档“全盘接受”,并据此开始“一本正经地胡说八道”。这种现象被称为RAG的“盲目信任”,也是影响RAG应用可靠性的核心挑战之一。
为了打破这一僵局,纠错型RAG应运而生。它在传统检索-生成的流程中加入了一层关键的“自我审查”机制,像一位严谨的审稿人,对获取的知识片段进行质量评估与筛选,从而有效提升最终答案的准确性。
一、核心:从“检索”到“检索-评估-修正”
与直接使用检索结果的传统RAG不同,纠错型RAG(Corrective RAG, CRAG)构建了一套更严密的逻辑闭环。我们通过下面这张流程图,可以清晰地看到其工作流:
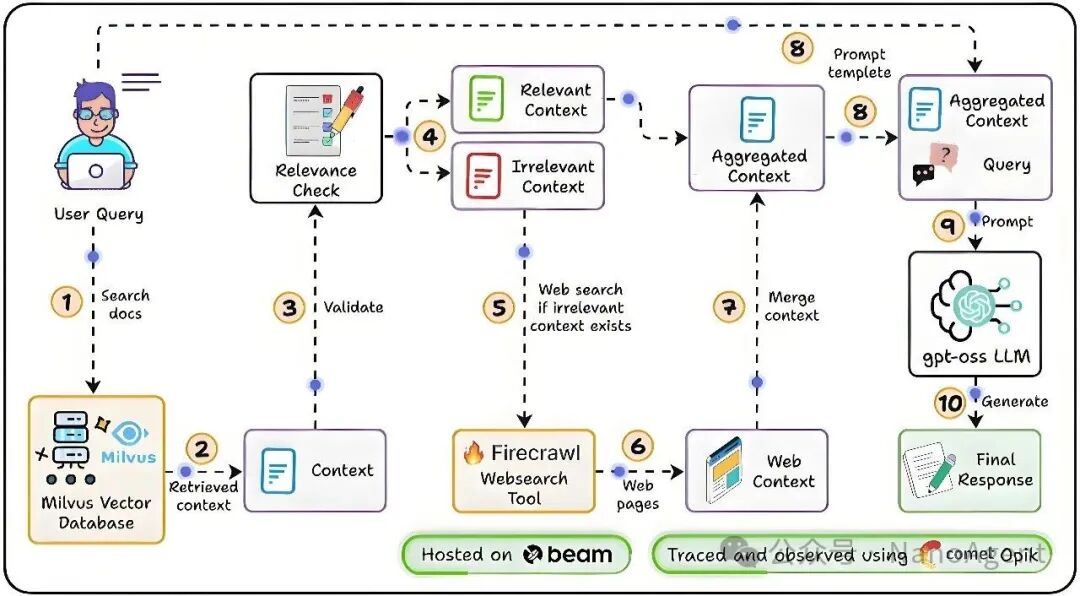
整个过程可以分解为几个关键步骤:
- 向量检索:根据用户查询,从本地向量数据库中检索出最相关的文档片段。
- 相关性评估:调用LLM对每个检索到的片段进行评分,判断其与问题的真实相关度。这一步是纠错能力的灵魂。
- 动态剪枝:果断剔除被判定为“不相关”的干扰信息,防止它们污染后续的生成过程。
- 网络搜索补充(可选):如果本地知识库检索结果的相关性整体较低,或为了获取最新信息,系统可以自动触发联网搜索,抓取外部高质量内容来弥补知识盲区。
- 答案生成:LLM综合经过筛选的本地文档和/或网络内容,生成最终精准、可靠的答案。
二、开源技术栈选择:全链路本地化
实现这样一套系统,完全可以采用成熟的开源工具链,在保障数据隐私的同时,获得高性能与高可控性。以下是一个参考方案:
- 大语言模型(LLM):使用 Ollama 在本地运行高性能开源模型,完全摆脱对商用API的依赖与费用顾虑。
- 向量数据库:采用 Milvus 作为企业级向量数据库,它能轻松应对海量文档的索引与存储,并提供毫秒级的相似性检索能力,是构建高效RAG系统的基石。
- 联网检索工具:Firecrawl 是一个强大的网页爬取与格式化工具,它能将复杂的网页实时信息,转换为结构清晰、便于LLM理解的Markdown格式。
- 编排与工作流框架:LlamaIndex 不仅是一个优秀的RAG框架,其最新的事件驱动工作流(Event-driven Workflow)功能,能让我们以高度灵活的方式编排上述“检索-评估-搜索”的复杂逻辑。
- 可观测性工具:Opik 可以无缝集成到LlamaIndex中,追踪每一次LLM调用、检索步骤的输入输出,让整个RAG链路的运行情况变得透明、可量化、可调试。
三、动手搭建:关键步骤与代码
基于上述技术栈,我们可以一步步构建起纠错型RAG系统。
1. 初始化LLM与知识库索引
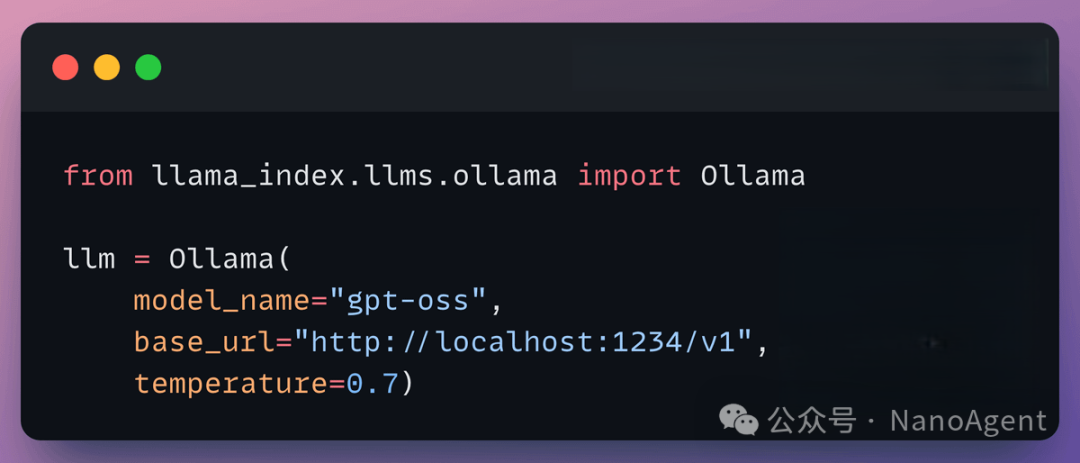
首先,在本地通过Ollama拉起一个LLM服务,例如gpt-oss模型,并将您的文档数据索引到Milvus向量数据库中。初始化LLM的代码如下所示:
from llama_index.llms.ollama import Ollama
llm = Ollama(
model_name="gpt-oss",
base_url="http://localhost:1234/v1",
temperature=0.7)
2. 构建事件驱动的工作流
利用LlamaIndex的工作流功能,定义智能体(Agent)。核心逻辑是:让LLM先评估检索结果的相关性得分,如果得分高于阈值,则直接用筛选后的内容生成答案;如果得分过低,则触发Firecrawl进行网络搜索,将搜索得到的新内容与原有相关片段合并,再生成最终答案。这种“IF-ELSE”的逻辑分支,非常适合用工作流来编排。
3. 集成Firecrawl实现动态搜索
在LlamaIndex工作流的“低分分支”中,集成Firecrawl。当Milvus返回的片段相关性评估不达标时,自动调用Firecrawl API,让它根据用户查询去抓取指定的网页或进行通用搜索,并对爬取到的网页内容进行清洗和格式化,确保输入给LLM的是高质量、无噪音的文本。
4. 引入Opik实现观测与评估
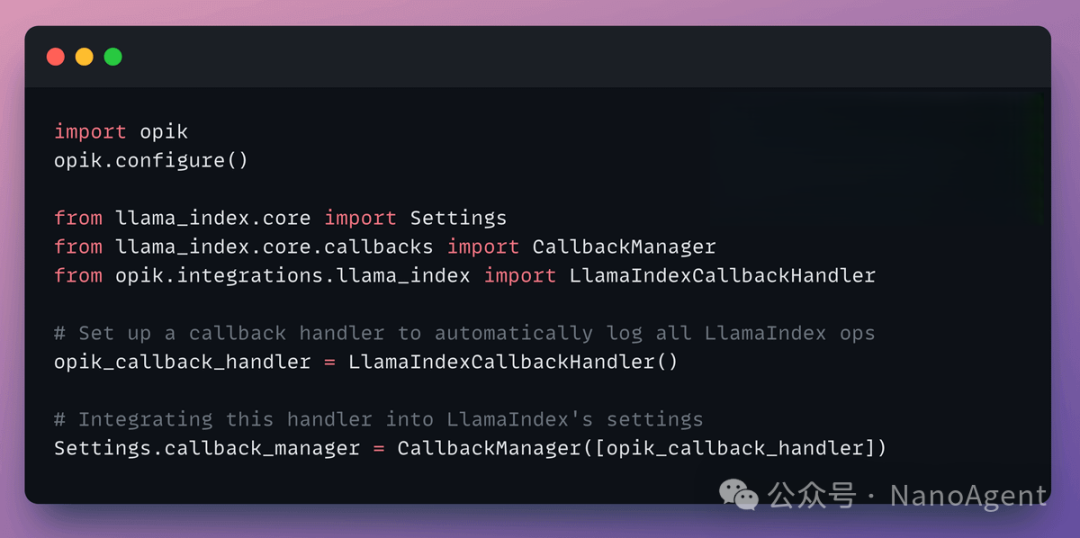
在整个系统搭建完成后,引入Opik进行观测。你只需要进行简单配置,即可将所有LLM调用和关键步骤记录并可视化。
import opik
opik.configure()
from llama_index.core import Settings
from llama_index.core.callbacks import CallbackManager
from opik.integrations.llama_index import LlamaIndexCallbackHandler
# 设置回调处理器,自动记录所有LlamaIndex操作
opik_callback_handler = LlamaIndexCallbackHandler()
# 将该处理器集成到LlamaIndex的设置中
Settings.callback_manager = CallbackManager([opik_callback_handler])
配置完成后,你可以在Opik的界面中直观地看到:一次查询到底检索到了哪些文档片段,它们的相关性得分是多少,系统为何判定需要启动网络搜索,以及搜索补充了哪些关键信息。这对于分析和优化你的RAG系统至关重要。
四、总结:让RAG具备“判断力”
通过引入自评估和动态搜索修正机制,纠错型RAG将系统从被动的“信息复读机”升级为具备初步判断力的“智能分析师”。在这个架构下,AI不再因为本地知识库的缺失或检索偏差而被迫“幻觉”出答案,而是能够主动寻求更优的信息源,或者坦诚地告知用户能力的边界。
这种“检索-审查-修正”的范式,代表了RAG系统向更可靠、更智能方向演进的重要一步。对于希望深入探索AI应用落地的开发者而言,掌握并实践这样的方案,无疑能为你构建的智能应用增添更多可信度与价值。云栈社区也提供了丰富的相关技术讨论与资源,欢迎进一步交流。
 发表于 2026-2-12 20:08:16
|
查看: 183|
回复: 0
发表于 2026-2-12 20:08:16
|
查看: 183|
回复: 0
