研究人员开发了一种新技术,可以将大型语言模型(LLM)在推理时的内存成本降低最多8倍。这项被称为动态内存稀疏化(Dynamic Memory Sparsification, DMS) 的方法可以压缩 KV缓存——即在处理提示与生成回复过程中,模型临时存储的中间状态数据。
虽然此前已有很多方法尝试压缩这个缓存,但大多数会损害模型的推理能力。英伟达的新方法能够丢弃大部分缓存内容,同时保持甚至在某些情况下提升模型的智能和推理能力。
实验结果显示,DMS使LLM能够在不增加速度和内存开销的前提下“思考”更久、探索更多解决方案。
推理中的核心瓶颈是什么?
LLM在处理复杂任务时,经常会生成所谓的 “思维链(chain-of-thought)” 令牌——这实际上是模型在得出最终答案前自行写出的推理步骤。让模型生成更多这样的令牌,或同时探索多条可能的推理路径,确实能提升其表现,但代价也极高。
随着模型生成更多令牌,它的 KV缓存会线性增长,占用大量 GPU 内存。为了处理这些数据,GPU花在读写内存上的时间远多于实际计算时间——这不仅增加延迟,还限制了同一时间能服务的推理请求数量。当显存耗尽时,系统会崩溃或变得极其缓慢。
因此,对企业而言,这已不仅仅是技术问题,更是经济成本问题。正如英伟达高级深度学习工程师 Piotr Nawrot 所说:“问题不只是你有多少硬件,而是以同样的成本你是在处理100个推理线程还是800个。”
动态内存稀疏化(DMS)的原理是什么?
DMS方法的思路与以往不同,它让已有的模型学会智能管理自身内存。不同于传统上依据固定规则(如最近最少使用)删除缓存,DMS会通过训练,让模型自己去判断哪些令牌对未来推理是关键的,哪些是可以丢弃的。
关键在于,DMS过程不会从头训练模型——这类训练成本往往极高。它通过微调模型内部注意力层的一部分神经元,让它们学习并输出每个令牌是“保留”还是“丢弃”的信号。这种方法本质上是一种轻量级改造,类似于我们熟知的 LoRA(低秩适应)。正如Nawrot所说,将像 Qwen3-8B 这样的模型加上DMS改造,可以只用一台DGX H100在几个小时内完成。
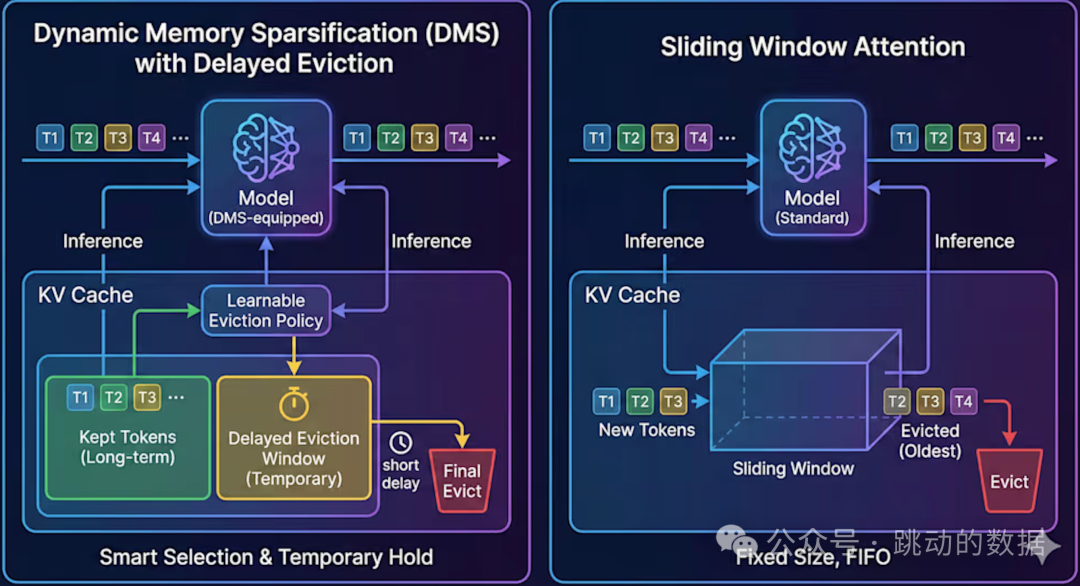
动态内存稀疏化(DMS)(左)与标准滑动窗口注意力(右)的机制对比。DMS引入可学习的淘汰策略和延迟淘汰机制,实现对KV缓存的智能管理。
关键创新:延迟删除机制
传统的缓存稀疏化策略在判断某个令牌不重要时,通常会立即删除它。但这存在风险——模型可能在极短时间内仍然需要该令牌的上下文信息。为此,DMS引入了一个核心机制:
延迟剔除(Delayed Eviction)
- 当令牌被初步判定为“不太重要”时,它不会被立即删除;
- 而是会在一个短暂的“观察期”(例如几百个推理步)内继续保留;
- 模型有机会在这段时间内,从其身上提取剩余的有用信息,并将其整合进当前的上下文表示中;
- 之后,再将其最终删除。
Nawrot解释道:“并非所有令牌要么极其重要要么完全无用。有些属于介于两者之间——它们含有一些信息,但不值得继续占用宝贵的内存。”延迟剔除正是为了妥善处理这种冗余信息而设计的关键步骤。
DMS的实际性能表现如何?
研究团队将DMS应用于多个先进的推理模型,如 Qwen-R1系列 和 Llama 3.2,并在多个高难度基准测试上进行了评估,例如:
- AIME 24(数学推理)
- GPQA Diamond(科学问答)
- LiveCodeBench(编程能力)
评估结果令人印象深刻:
- 在相同的内存带宽限制下,Qwen-R1 32B加上DMS在AIME 24上的得分比标准模型高出12分。这意味着模型能在同一硬件预算下进行更深、更广的“思考”。
- DMS打破了“压缩必然会损害长上下文理解能力”的固有认知。在评估模型从长文本中精准定位信息的“大海捞针”测试中,DMS模型的表现甚至超过了未经修改的标准模型。这是因为主动、智能地管理内存,比被动地积累所有信息(包括噪音)效果更好。
- 在企业级吞吐量测试中,Qwen3-8B加装DMS后,在保持准确率不变的前提下,实现了高达5倍的吞吐量提升——这意味着能以更低的成本处理更多的用户请求。
技术突破将利好哪些产业链环节?
这项底层技术优化,预计将从软件到硬件,对整个AI推理产业链产生涟漪效应。以下环节的公司可能因此受益:
1. 服务器整机与AI机柜厂商
核心逻辑:推理效率的优化并不会减少服务器需求,反而会显著提升企业的部署意愿与投资回报率(ROI)。GPU利用率提高意味着单卡能创造更多价值,这会促使企业更敢于进行规模化扩容。企业的决策逻辑将转变为:“如果单卡效率大幅提升,那我投资100张卡的ROI会变得更高。”这将直接转化为服务器厂商的新增订单和业绩增长。服务器作为典型的订单驱动型行业,利润兑现的节奏相对较快。
2. 高端存储与内存接口芯片
核心逻辑:DMS优化的是KV缓存的内存占用,但推理总规模的扩大将导致内存系统的总需求不降反升。不过,半导体产业链的订单确认和业绩兑现周期通常慢于服务器整机,因此相关公司的受益节奏会略有滞后。
3. 国产AI推理芯片
核心逻辑:这是弹性最大,但业绩兑现可能最慢的环节。推理优化属于软件栈进步,不会立即改变下游客户的芯片采购结构,其效益的完全释放需要整个软件生态的成熟与适配。因此,这个方向目前更多是预期驱动大于即时的业绩驱动,但长期来看,生态的完善将为其打开广阔空间。
技术的每一次飞跃,都离不开社区的交流与思想的碰撞。对 深度学习 优化和AI硬件感兴趣的朋友,欢迎来云栈社区一起探讨前沿趋势与实战经验。
 发表于 2026-2-15 07:26:58
|
查看: 271|
回复: 0
发表于 2026-2-15 07:26:58
|
查看: 271|
回复: 0
