流量镜像(Traffic Mirroring)是一种将线上真实流量复制到影子环境(Shadow Environment)进行验证、对比或分析的技术。它的核心价值在于:用真实流量(而非合成流量)来验证新版本的正确性和性能表现,同时不影响线上用户的正常体验。
其应用场景广泛,包括全链路灰度验证、性能基准测试、安全审计与风控分析,以及搜索推荐等AI场景的数据采集。这些场景的共同特征是对流量真实性有较高要求,合成流量难以完全替代。

随着系统从十万QPS演进到百万、千万QPS,流量镜像的架构也经历了本质性的变化。一个直觉性的结论是:千万QPS系统即使只做1%的镜像抽样,镜像流量本身就有十万QPS;如果关键链路做10%-50%的镜像,镜像子系统需要承载百万级QPS,它自身已经是一个需要严肃对待的分布式系统。
本文将沿着规模演进路线,围绕镜像保真度与系统成本这一核心矛盾,阐述流量镜像在不同QPS量级下的架构差异。
01 十万 QPS:全量镜像,同步完成
在十万QPS阶段,流量镜像作为负载均衡器(如Envoy、Nginx)的内置功能即可实现。架构简单直接:
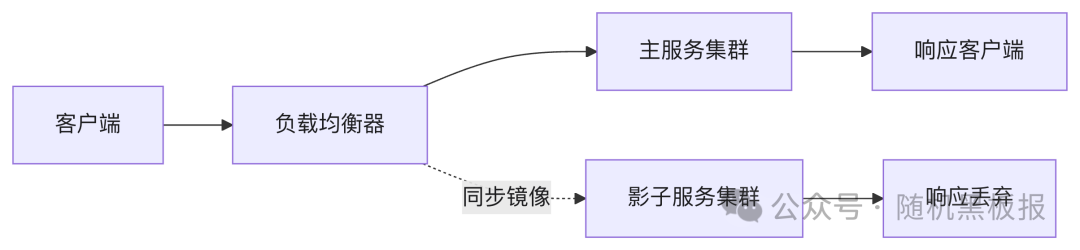
这一阶段的关键特征:全量镜像是默认选择,镜像操作在请求转发的主路径上同步完成。以单个请求平均1KB粗略估算,镜像带宽约100MB/s,在数据中心内部网络条件下完全可以承受。镜像的正确性验证也比较简单,逐请求对比主服务和影子服务的响应差异即可。
这个阶段的挑战主要在工程实践层面而非架构层面,比如如何隔离影子环境的写操作、如何处理响应中的非确定性字段(时间戳、随机ID等)。
02 百万 QPS:镜像成为独立的异步链路
当系统进入百万QPS,流量镜像面临的第一个根本性变化是:镜像操作必须从主链路中剥离,成为异步流程。
2.1 为什么必须异步化
在十万QPS下,负载均衡器同步复制请求对主链路延迟的影响通常可以忽略。但在百万QPS下,镜像目标(影子集群)的任何抖动,网络拥塞、影子服务过载、GC停顿,都会通过同步调用链传导回主服务,造成主链路延迟毛刺。
异步化的核心思想是:主链路只负责将请求元数据写入本地缓冲区,由独立的镜像代理(Mirror Agent)异步消费并转发。
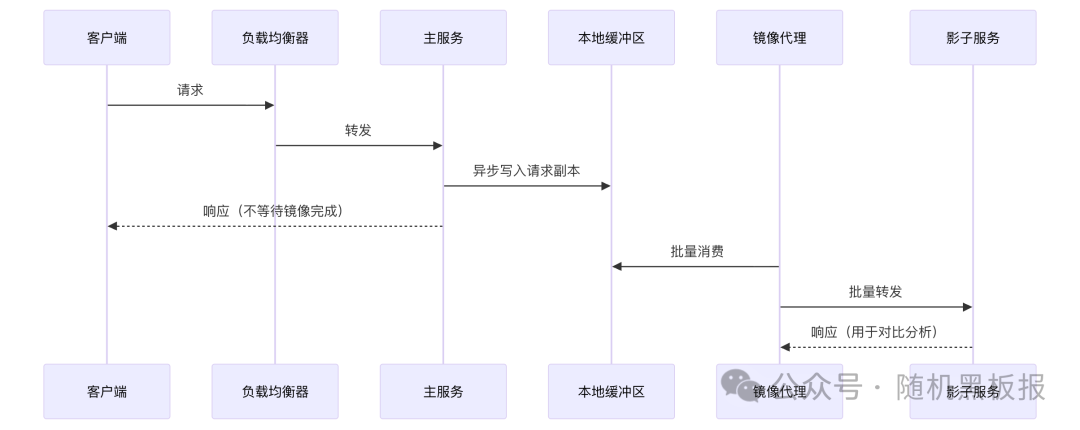
异步化带来两个重要的架构属性:
- 第一,主链路与镜像链路的故障域完全隔离,影子集群宕机或过载不会影响线上服务。
- 第二,镜像代理可以对请求做批量聚合,减少网络往返次数。
2.2 从全量到抽样
百万QPS全量镜像的资源开销不容忽视。粗略估算(按1KB/请求),镜像带宽约1GB/s,影子集群需要可观的计算资源。全量镜像在成本上可能不经济,但在技术上通常仍然可行,这是百万QPS与千万QPS的一个重要区别。
实际决策中,百万QPS阶段最常见的策略是按接口重要性分级镜像:
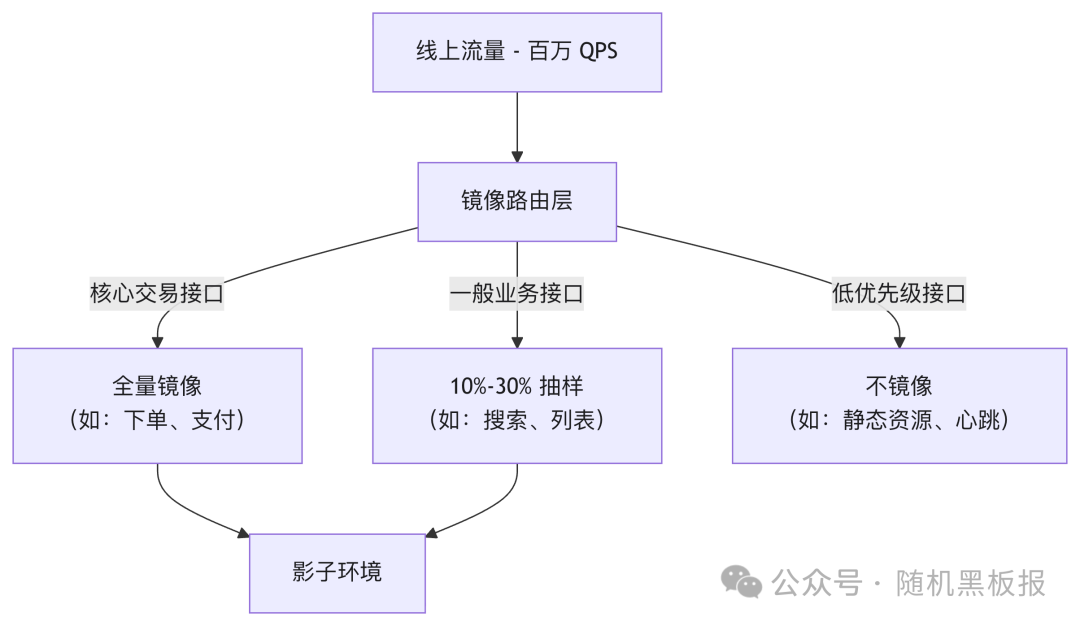
这种分级策略在保证关键路径验证覆盖的同时,将总体镜像流量控制在可接受的范围。
2.3 写请求的镜像隔离
值得单独讨论的是写请求的镜像问题。读请求的镜像相对简单,影子服务处理后丢弃响应即可。但写请求(如下单、扣款)一旦被镜像到影子环境,如果影子环境没有做好数据隔离,可能会造成真实的数据变更。
百万QPS阶段处理写请求镜像的常见策略是读写分离镜像:只镜像读请求和写请求的意图(请求参数),不在影子环境中真正执行写操作;或者影子环境使用完全独立的数据存储,与生产环境物理隔离。
03 千万 QPS:镜像系统成为分布式数据管道
千万QPS阶段,流量镜像在架构上产生了根本性变化。引言中提到的直觉得到了验证,镜像子系统自身的规模和复杂度,已经等同于一个独立的大规模业务系统。
3.1 扇入问题与分层聚合
百万QPS阶段,每个业务节点的镜像代理可以直接将流量发往影子集群,这种扁平的多对一模型在节点数量有限时可以工作。但在千万QPS下,业务节点通常数以千计甚至上万,如果每个节点都直接向影子集群建立连接并发送数据,影子集群的接入层会面临严重的扇入压力。
假设有5000个业务节点,每个节点向影子集群建立2-4条连接,仅连接数就达到1-2万。更重要的是,这些连接上的流量模式是高度突发的,某个时刻的流量峰值可能远超平均值。
千万QPS的镜像架构需要引入分层聚合来化解扇入问题:
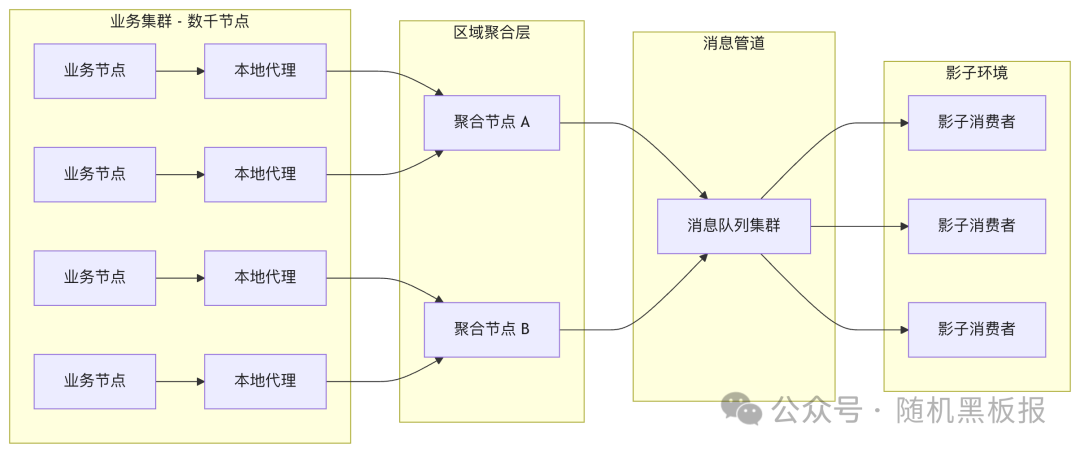
分层聚合将数千对一的网络拓扑转化为数千对数十、数十对一的分层结构。每一层都可以做缓冲和流控:本地代理负责节点级的抽样和缓冲,区域聚合节点负责批量合并和二次流控,消息队列集群提供全局的削峰填谷和持久化能力。
引入消息队列后,镜像流量从准实时变为近实时(延迟从毫秒级增加到秒级甚至分钟级)。这对于单请求正确性验证影响不大,但对于时间序相关的业务逻辑验证(如限流、频控等依赖请求到达时间的场景),需要在影子环境中做时间补偿处理。
3.2 智能抽样策略体系
十万QPS不需要抽样,百万QPS通常按接口分级做固定比例抽样。到了千万QPS,固定比例抽样的主要问题暴露出来:它无法同时满足覆盖率和资源约束。
例如,某个高频接口占总流量的80%,如果按统一5%的比例抽样,这个接口仍然会占据镜像资源的80%,而众多长尾接口可能完全采集不到有效样本。千万QPS阶段需要更精细的抽样策略体系:
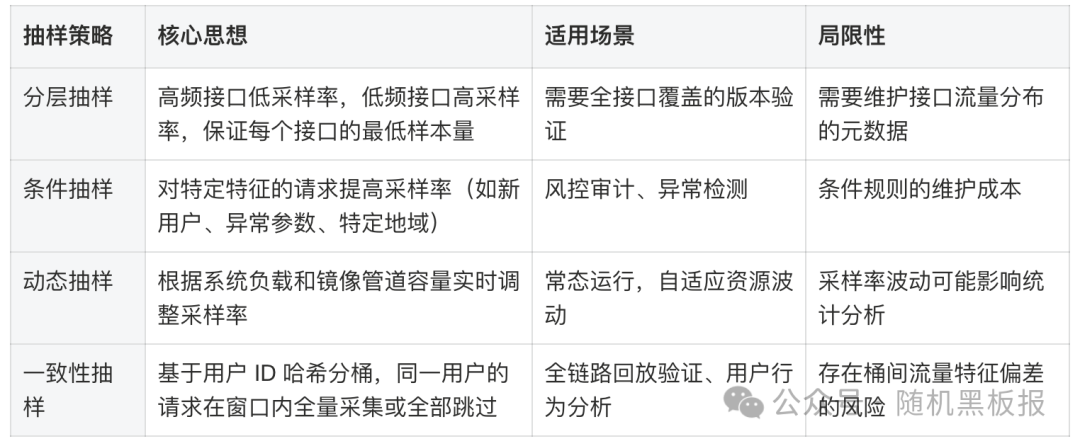
其中,一致性抽样在千万QPS阶段尤为关键。很多验证场景需要还原用户的完整行为序列,例如一次完整的浏览→加购→下单→支付流程。如果对同一用户的请求做独立随机抽样,采集到的数据是碎片化的,无法用于全链路回放。
一致性抽样的实现思路:基于用户ID做哈希,将用户划分到N个桶中,选定的桶内用户的所有请求在时间窗口内全量采集,其余用户完全跳过。采样率约等于选中桶数 / 总桶数。
需要注意的一个陷阱是:哈希分桶可能引入采样偏差。如果用户ID的分布不均匀,或者某些桶中恰好集中了特定类型的用户(如高活跃度用户),采集到的数据可能不具备对整体流量的代表性。实际工程中,通常需要定期轮换桶的选择,或者对采集数据做分布校验。
3.3 反压与降级:镜像不能反噬主链路
在百万QPS阶段,如果影子环境处理不过来,最简单的做法是丢弃溢出的镜像请求。这种尽力而为的策略在大多数场景下足够。
但在千万QPS下,镜像系统与主系统共享底层基础设施,网络带宽、交换机缓冲、甚至物理服务器上的CPU和内存(当镜像代理与业务进程部署在同一台机器上时)。如果镜像流量失控(例如影子集群故障导致镜像代理重试风暴),压力会通过共享资源传导到主链路。
千万QPS的镜像系统需要多级降级保护策略:
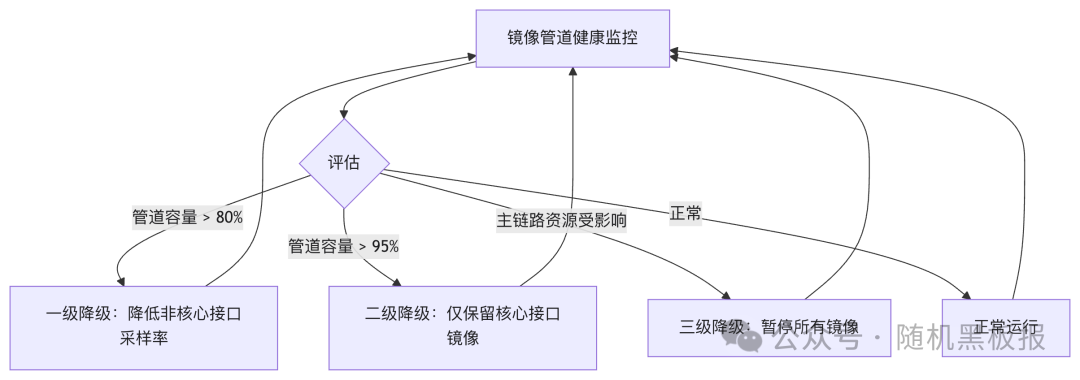
这里的关键设计原则是:镜像代理的限流和熔断机制必须独立于主服务的限流体系。如果镜像代理复用了主服务的限流配额,当镜像流量激增时,可能会挤占主服务的可用配额。反之,如果主服务限流生效,镜像代理应该感知到这个信号并主动降级,而不是继续按原有采样率工作。
3.4 多通道并行:不同目标,不同管道
在十万和百万QPS阶段,通常只有一条镜像通道,服务于所有的验证需求。千万QPS阶段,不同的验证目标对镜像数据有截然不同的要求:
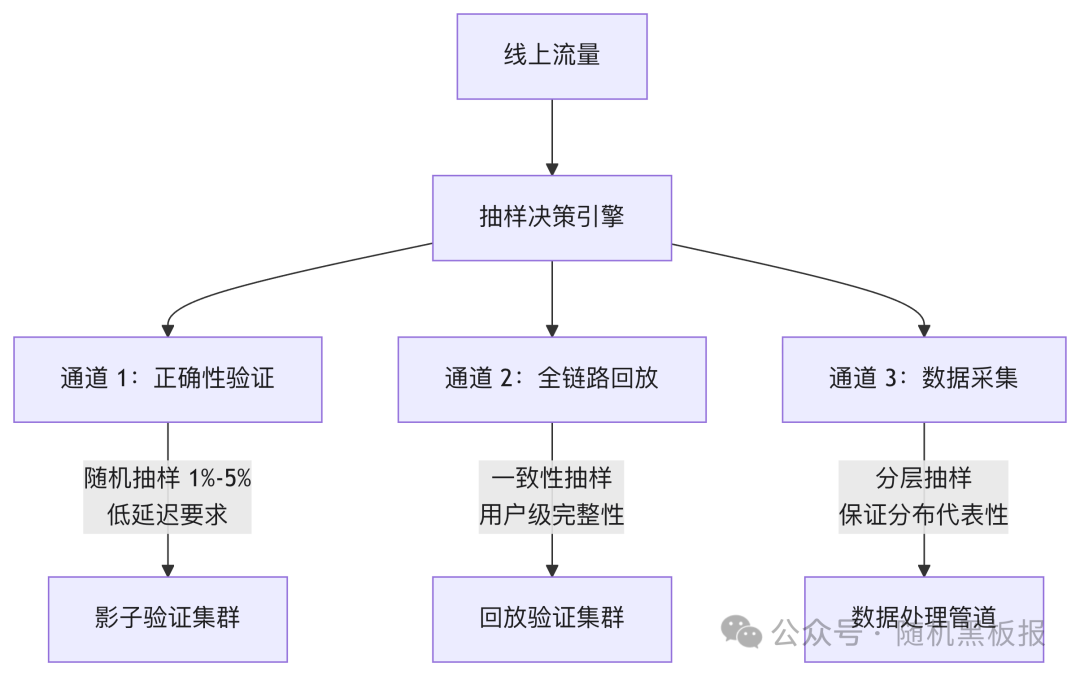
单请求正确性验证需要低延迟的随机抽样,全链路回放需要用户级一致性抽样,数据采集需要保证统计分布的分层抽样,这三者对抽样策略、传输时效性、数据格式的要求各不相同。
将它们放在同一条管道中,要么需要向上对齐到最严格的要求(成本过高),要么只能向下妥协到最低要求(无法满足部分场景)。因此,千万QPS的镜像系统通常演化为多条并行的独立管道,每条管道有自己的抽样逻辑、传输通道和消费集群。
04 演进总结
下表从多个维度总结了流量镜像在三个QPS量级下的架构差异:
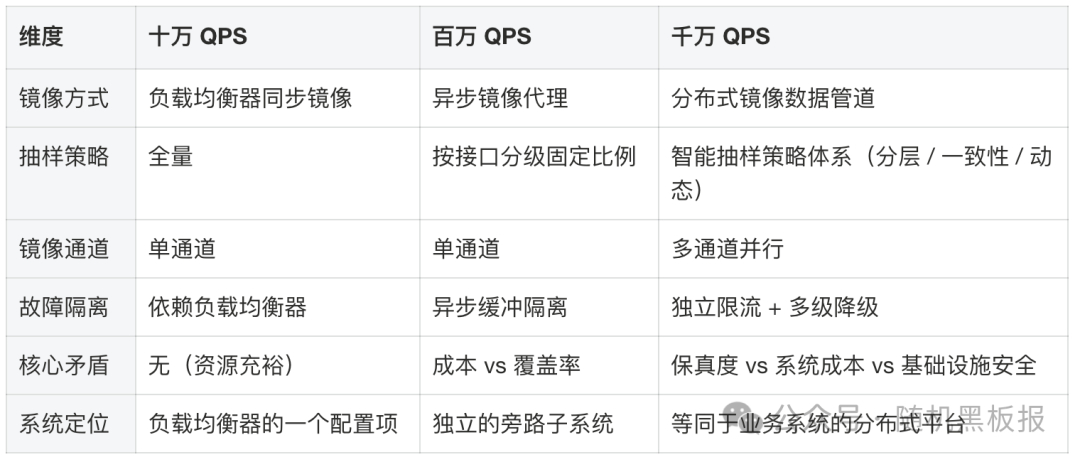
流量镜像的架构演进,体现了大规模系统设计中一个反复出现的规律:当辅助子系统的规模增长到一定量级,它就不再是辅助子系统,而是一个需要同等架构重视度的独立系统。千万QPS系统的镜像子系统本身需要承载百万级QPS,它有自己的采集层、聚合层、消息管道和消费集群,有自己的抽样策略引擎、反压机制和降级策略,你实际上是在用建设百万QPS系统的方法论去建设一个附属功能。这正是千万QPS不是百万QPS简单乘以10的又一个例证。
希望本文对你理解高并发场景下的流量镜像技术演进有所帮助。如果你对分布式系统的其它架构话题感兴趣,欢迎在云栈社区进行更深入的交流与探讨。
 发表于 2026-2-16 05:15:13
|
查看: 351|
回复: 0
发表于 2026-2-16 05:15:13
|
查看: 351|
回复: 0
