如何让模型“看懂”长达数十分钟的未剪辑视频,并精准定位其中发生的各种动作?传统的Transformer架构在处理长序列时面临巨大的计算负担。现在,一种名为MS-Temba的新型架构给出了答案,它作为首个专为密集时序动作检测设计的Mamba架构,凭借仅17M的参数量,不仅实现了卓越的性能,更将处理效率提升了一个台阶。
1. 基本信息

2. 核心创新点
- 首个面向密集时序动作检测的 Mamba 架构:提出了 MS-Temba,这是首个专为未剪辑视频中的密集标签时序动作检测(TAD)定制的Mamba架构,有效解决了长视频处理中的计算瓶颈。
- 多尺度空洞状态空间模型(Dilated SSMs):设计了 Temba 模块,引入空洞扫描机制,通过多分支不同步长的 SSM 并行处理,在同一框架内联合捕捉短时细粒度动作和长时依赖关系。
- 一致性对齐与尺度感知监督机制:提出了投影对齐机制和一致性损失,强制不同空洞分支间的语义连贯性,并结合尺度感知辅助损失强化特定时间尺度的特征学习。
- 轻量级多尺度 Mamba 融合器(MS-Fuser):开发了一种基于 SSM 的融合模块,能够聚合来自不同层级的互补时序特征,在极小参数量下实现了 SOTA 性能,并成功泛化至视频摘要任务。这项研究也为开源实战领域提供了新的高效模型选择。
3. 方法详解
整体结构概述
MS-Temba 的整体架构旨在处理长达数十分钟的未剪辑视频。模型首先通过冻结的视觉骨干网络(如 I3D 或 CLIP)提取视频片段的特征序列。随后,这些特征通过堆叠的 Temba 模块进行处理,每个模块采用逐渐增大的空洞率来捕捉从局部到全局的层级化时序依赖。最后,多尺度 Mamba 融合器将各层输出聚合,生成统一的时序嵌入,并通过分类头进行密集的动作预测。
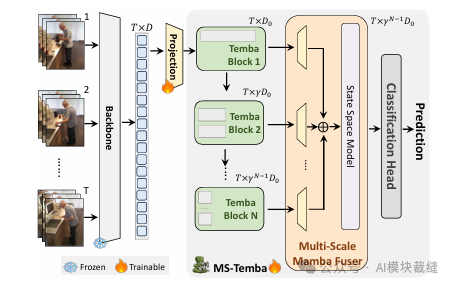
步骤分解
-
视觉特征提取与标记化
- 将未剪辑的长视频分割为 $T$ 个连续且不重叠的片段(Visual Tokens)。
- 使用预训练的 3D ConvNet(如 I3D)或基础模型(如 CLIP)提取特征,形成输入向量 $\mathbf{x} \in \mathbb{R}^{T \times d_{in}}$。
- 通过线性投影将特征映射到潜在空间 $\mathbf{h}_0 \in \mathbb{R}^{T \times D}$,作为后续模块的输入。
-
多尺度空洞 Temba 模块(Temba Blocks)
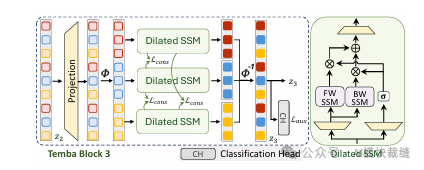
- 空洞扫描:为了捕捉不同时间跨度的依赖,引入非参数映射 $\phi_r$,将输入序列按步长 $r$ 划分为 $r$ 个不相交的子序列。对于第 $l$ 个模块,设置 $r=2^{l-1}$。
- 多分支 SSM 处理:每个子序列独立通过一个扩张 SSM 分支进行处理。第 $k$ 个分支的状态更新与输出如下所示:
$$\begin{aligned} \mathbf{h}_{t}^{(k)} &= \overline{\mathbf{A}} \mathbf{h}_{t-1}^{(k)} + \overline{\mathbf{B}} \mathbf{x}_{t}^{(k)} \\ \mathbf{y}_{t}^{(k)} &= \mathbf{C} \mathbf{h}_{t}^{(k)} + \mathbf{D} \mathbf{x}_{t}^{(k)} \end{aligned}$$
- 投影一致性对齐:为了确保不同空洞分支间的语义一致性,引入成对一致性损失 $\mathcal{L}_{\text{align}}$,最大化不同分支输出投影矩阵 $\mathbf{P}_i, \mathbf{P}_j$ 之间的余弦相似度:
$$\mathcal{L}_{\text{align}} = -\sum_{i \neq j} \frac{\mathbf{P}_i \cdot \mathbf{P}_j}{\|\mathbf{P}_i\| \|\mathbf{P}_j\|}$$
- 时序重组:处理后的子序列通过逆映射 $\phi_r^{-1}$ 恢复原始时序排列,保持时间保真度。
-
层级化堆叠与辅助监督
-
多尺度 Mamba 融合器(MS-Fuser)
-
联合训练目标
4. 即插即用模块作用
适用场景
- 时序动作检测(TAD):适用于包含密集、重叠动作的长视频(如 TSU, Charades 数据集)。
- 视频摘要(Video Summarization):用于从长视频中提取关键帧或片段(如 TVSum, SumMe 数据集)。
- 日常生活活动监测(ADL):适用于智能家居、患者监护等需要理解长时间连续行为的场景。
主要作用
- 高效处理超长序列:利用 Mamba 的线性复杂度优势,能够高效处理时长超过 40 分钟的未剪辑视频,相比 Transformer 方案大幅降低计算量。
- 兼顾短时与长时建模:通过多尺度空洞设计,既能精准捕捉瞬间发生的短动作(如“喝水”),又能理解持续较长的活动(如“使用电脑”)。
- 极高的参数效率:在保持 SOTA 性能的同时,参数量仅为 17M,比主流基于 Transformer 的方法(如 MS-TCT, 87M)减少了约 80% 的参数,且推理吞吐量提升 2 倍以上。
- 增强特征判别性:通过一致性损失和辅助监督,解决了 SSM 在视频任务中容易丢失细粒度时序结构的问题。
总结
MS-Temba 是一种高效、轻量级的长视频理解引擎,通过创新的多尺度空洞状态空间模型,在极低的计算成本下实现了对复杂、重叠时序动作的精准捕捉与全局建模。 |  发表于 2026-2-17 05:34:26
|
查看: 379|
回复: 0
发表于 2026-2-17 05:34:26
|
查看: 379|
回复: 0
