没想到吧,因为早期数据中心选址的“随性”,反而催生了一门独立的网络技术领域。
这就是DCI(Data Center Interconnect,数据中心互联)。你可以把它理解为大型互联网公司自建的城域网或广域网,谷歌的B4网络算是这个领域的开山鼻祖。

通常的故事线是这样的:先为最初的“胡乱选址”买单,等到实在背不动这个“锅”了,才会开始系统性地进行数据中心园区规划,并随之启动DCI网络的优化工作。这个规律在老牌、中生代乃至新生代的大厂里不断循环上演,几乎没有例外。
01 / 猥琐发育,别浪
最开始,每个公司规模都很小,生存是第一要务,也没有专业的网络工程师团队。为了节省成本,扩张路径往往是这样的:
- 从租用一个机位开始。
- 业务增长,变成分散在不同机柜的多个机位。
- 需要租用整个机柜了。
- 机柜分散到机房的不同列。
- 重复以上循环,从一整列机柜,到一个模块包间,再到一整层、一整栋楼,乃至整个园区。
- 通常还没扩张到一整层,原园区就没空间了。为了支持紧急的业务增长(比如关键促销活动),必须去其他园区租用机柜,且交付周期极短。
- 此时,公司可能有了不到10名背景各异的网络工程师。他们会采取最简单粗暴的方式(专线或裸光纤,取决于交付时效)把两个园区连接起来。
- 紧接着,第三个、第四个园区加入……互联关系开始蔓延。
最终,整个互联拓扑可能变得毫无规律可言,仅仅反映了当地数据中心产业的分布状况。

02 / 拓扑规范化
随着园区数量进一步增加,就会面临拓扑学中著名的N²复杂度问题。完全的全互联(Full-Mesh)成本过高,因此网络工程师首先想到的优化方案是:设立两个POP(Point of Presence)点,作为所有园区互联的中转枢纽。
所有园区都需要与这两个POP点互联,同时可以保留部分园区间的直连链路,这种直连通常被称为“直通车”。
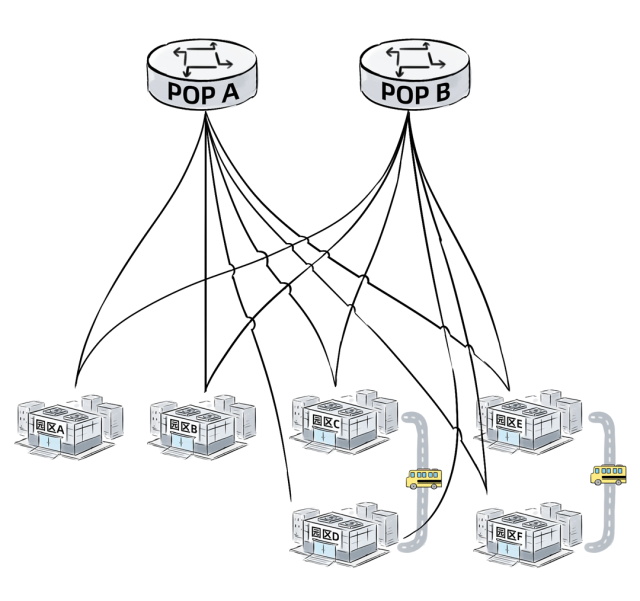
如上图所示,这种方案需要14条连接。熟悉网络拓扑的人都知道,网状组网的复杂度是O(N²),这里的N是园区和POP点的总数。因此,减少N值能大幅降低所需租用的链路数量。
最直接的方案是,选择两个长期合作、资源充足的核心园区来承担POP功能,例如下图中的园区C和E。
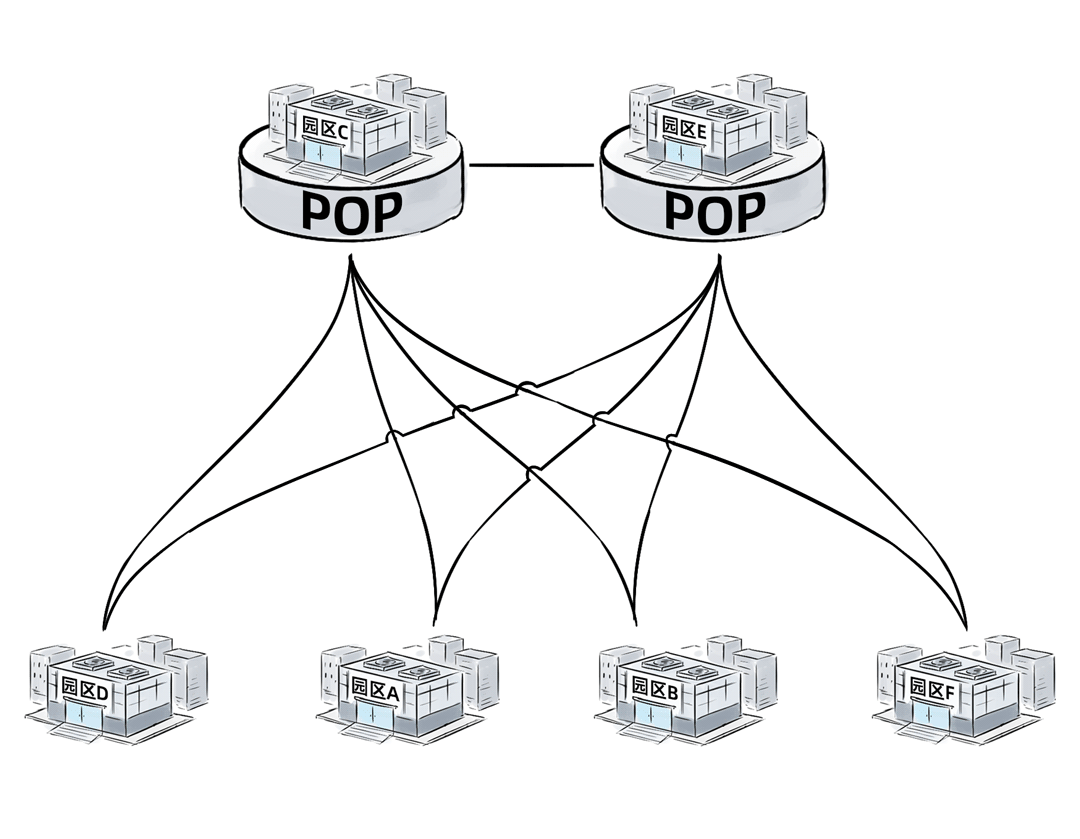
这个方案只需要9条连接,比原方案减少了5条。将POP功能与既有园区合并,本身就是降低成本趋势下的产物。
在此基础上,可以进一步设计跨地域(Region)的互联方案。以国内典型的华南-华东-华北三地域格局为例:
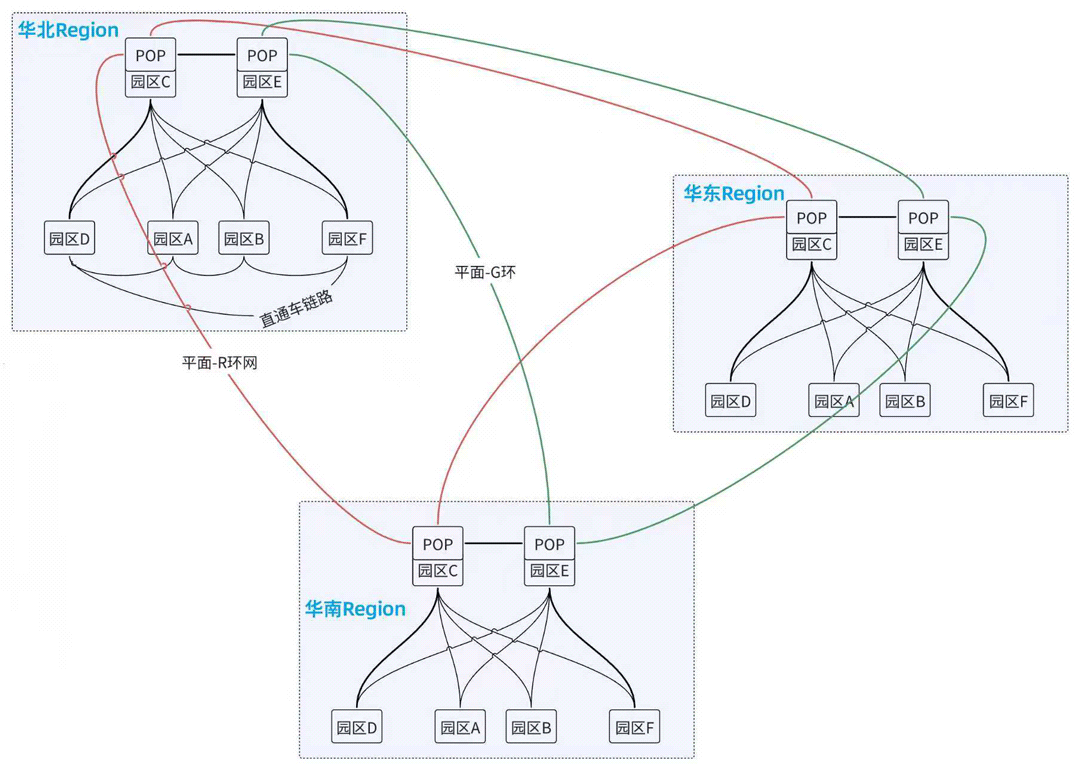
这基本上就是大厂覆盖全国的“红-绿”双平面环网骨干网的雏形。在这个架构中,每个Region内的园区除了与POP互联外,还可以根据业务需求组建“直通车”链路,主要出于两个目的:
- 减轻POP园区的转发负担。
- 降低有强耦合关系的业务园区之间的时延,保障业务性能。
“直通车”链路的起源通常来自业务部署需求,而非最初的网络规划:
- 新业务初期“猥琐发育”,哪里有资源就部署在哪里。
- 业务爆发式增长,原园区资源不足,需要扩容到其他园区,流量通过POP中转。
- 跨这两个园区的业务流量(如对时延和抖动敏感的Redis流量)变得巨大,经过POP中转时延高,且带宽易被其他流量挤占,频繁扩容成本高。
- 最终,为这两个业务耦合度高的园区建设专用的“直通车”链路,实现低时延、高带宽的专有通道。
03 / 数通组网详解
❶ 园区内与DCN的衔接
通常,DCI网络在园区内与数据中心网络(DCN)有两种衔接模式:垂直模式与水平模式。
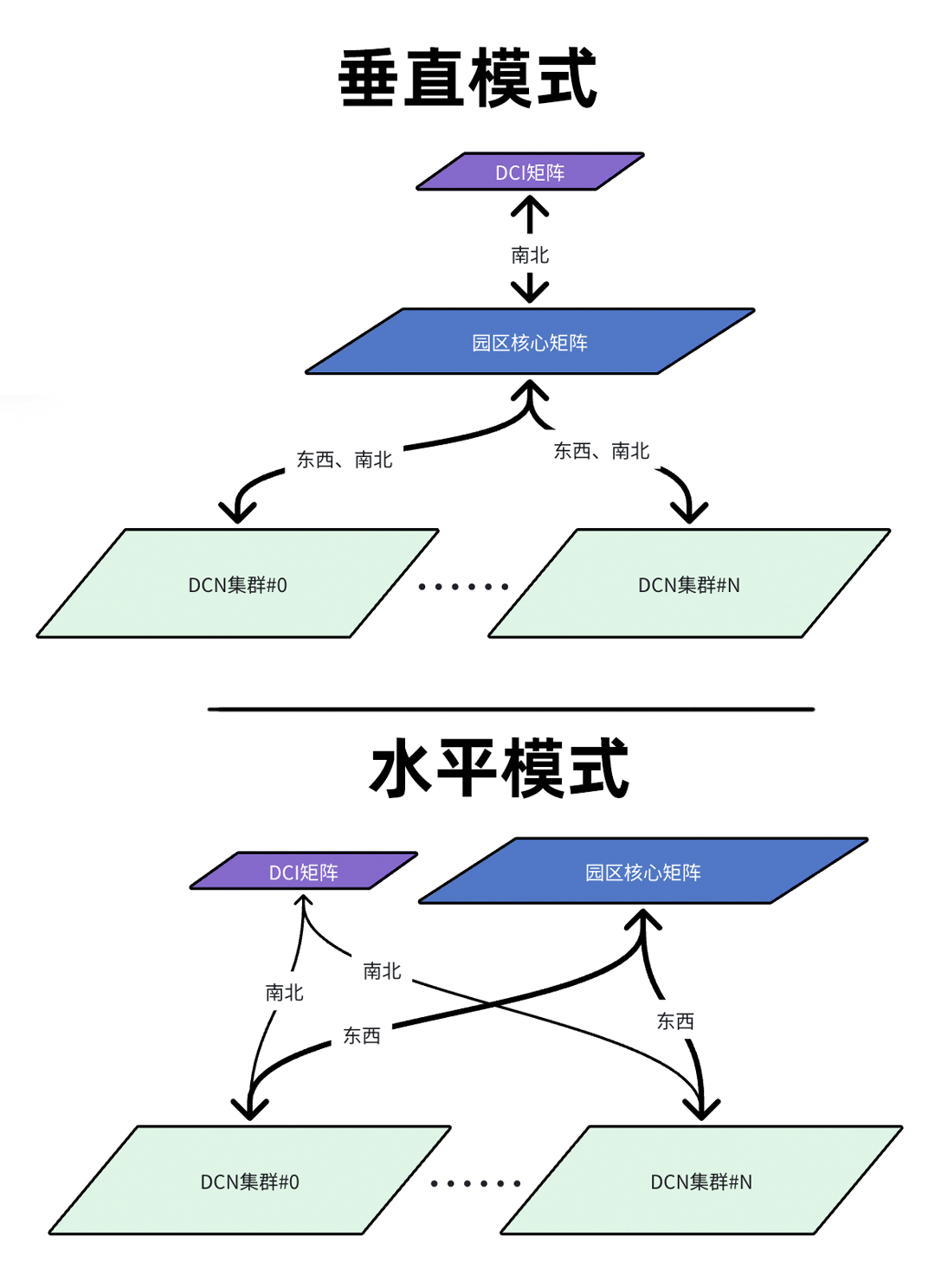
- 垂直模式 比较容易理解,DCI设备在拓扑上位于园区核心交换机的上一层,要求DCI设备与所有园区核心设备全互联(Full-Mesh)。
- 水平模式 中,DCI设备与园区核心属于同一层级,也可以视作一批功能特殊的园区核心。DCI设备专门用于跨园区互联,园区核心则专注于集群间的东西向高带宽互联。
这两种模式各有优劣,适用于不同的运营阶段和诉求。如果没有特殊需求,大多数网络团队会选择垂直模式,因其结构清晰,易于理解和运维。
如果存在以下精细化运维需求,则会考虑水平模式:
- 控制初期成本:不想一次性投建庞大的园区核心和DCI矩阵,而是根据实际流量水位分平面扩容。
- 精准容量运营:水平模式能清晰区分南北向(跨园区)和东西向(集群内)流量,实现精准扩容,避免“大水漫灌”。
- 减少转发层级:理论上可以缩减几微秒的转发时延。不过,与动辄数十、上百公里带来的传输时延(每10公里增加约100us RTT)相比,这点减少几乎可以忽略。
通常,只有到了极致追求成本优化(且有能力将成本优势转化为市场竞争力)的阶段,才会考虑这种更复杂的模式。当然,这也要求网络团队具备极致的运营能力。

❷ 跨园区的协议选择
在Region内部,由于连接关系由业务需求驱动,相对DCN缺乏规律性。因此,协议设计可以回归互联网最初的样子——将每个园区视为一个独立自治系统(AS):
- 园区与园区之间通过EBGP(外部边界网关协议)的方式交换路由。
- 经过POP园区或其他园区中转的路径,就相当于通过其他“自治系统”进行路由传递。
这样做的好处是,可以天然地利用BGP简洁的路由策略(如AS_PATH、Local-Preference)来控制流量的主用路径和确定的备用路径,实现灵活的流量调度。
在跨Region(骨干网)场景下,设计则会借鉴运营商骨干网的经验:采用 ISIS(中间系统到中间系统协议)作为底层IGP,并结合带RR(路由反射器)的IBGP(内部边界网关协议),再叠加各种SDN(软件定义网络)流量工程能力。
这样做的目的是:
- 将整个骨干网视为一个统一的、提供跨地域带宽服务的整体,即一个大的IBGP域。
- ISIS相比OSPF具备更简化的链路状态数据库结构、天然的双栈支持能力,对复杂拓扑的适应性更强,更适合大规模严肃运营的场景。
- 通过流量工程,可以对不同服务等级(基于DSCP值)的流量进行灵活的带宽水位控制和调度。
业务流量通常被分为多个等级进行调度:
- a类:最高优先级,通常预留给协议控制流量,占比极低。
- b类:高优先级,确保带宽和低丢包率,通常分配给实时同步类业务(如金融交易、游戏同步)。
- c类:次高优先级,承诺带宽但不保证绝对低丢包(拥塞时可能被绕行),通常用于非实时在线同步业务。
- d类:默认优先级,不承诺带宽(拥塞时优先丢弃),通常分配给离线计算、备份类业务。
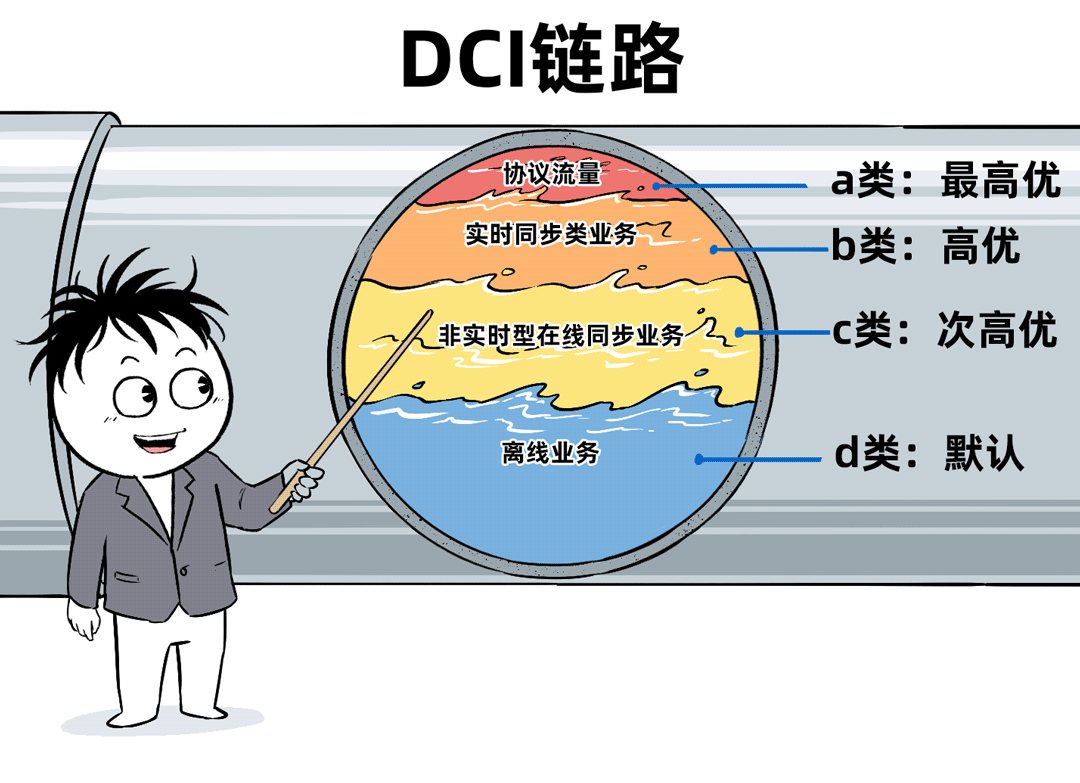
在这种策略下,a类流量优先级最高但基本不用。水位控制的核心在b类流量,其阈值通常设定在链路总带宽的40%左右,一旦超过就需要考虑扩容。剩余的60%带宽,大部分作为c类流量的配额,而任何闲置带宽都可以被d类流量充分利用。
不同等级流量的“收费”或成本分摊策略差异巨大,这能从商业层面倒逼业务部门准确标识自身流量,避免资源浪费。这种精细化的调度策略,旨在保障关键业务(b类)的前提下,最大限度地提升昂贵骨干带宽的利用率——这也是被谷歌B4网络高达90%以上的利用率“卷”出来的行业游戏。
具体的流量工程技术,则经历了从老一辈的MPLS TE,到中生代的SR-TE,再到新生代SRv6的演进,并普遍结合SDN控制器进行全局优化调度。
评价流量工程好坏的核心标准始终是:能否在保障b类关键业务流量的前提下,尽可能高地提升c类和d类流量的带宽利用率。
❸ 一个常被忽视的关键点:稳定性
前面讨论的所有优点都基于“一切正常”的前提。实际上,DCI网络无论是城域部分还是骨干部分,都高度依赖于底层的光传输OTN网络。光传输网络的标准SLA(服务等级协议)通常是50毫秒内的故障保护倒换,但这50毫秒的中断对于许多对时延敏感的内存数据库应用来说,是能够被感知甚至影响业务的。
同时,DCI设备之间通过数通协议(如IP/MPLS)互联,中间可能经过多层二层和一层设备。数通协议层面无法快速感知这些底层物理链路的细微异常(如光功率劣化、误码率提升)。因此,必须在每条物理链路上部署BFD(双向转发检测)会话,以实现端到端的快速故障探测。
传统BFD工作在3层,无法为每一条物理链路单独部署。此外,BFD的探测灵敏度取决于发包频率,高频BFD会严重消耗设备主控CPU资源。在DCI这种端口密集的场景下,CPU很容易不堪重负。因此,支持硬件级BFD处理成为了DCI设备的一项关键低开销特性。
看到以太网上层堆砌如此多的复杂协议来实现可靠性和快速收敛,有时不禁会想:为什么以太网的链路层协议不能在DCI场景中,像过去的SDH/SONET网络那样,原生集成一个具备物理层连接状态探测能力的协议呢?如果芯片层面能解决这个问题,也许就不再需要BFD这样的补丁式方案了。
结语
关于DCI网络从无到有、从混乱到规范的演进历程,以及其中的关键架构设计和技术选型思考,就先聊到这里。希望这些分享能对面临类似挑战的工程师有所启发。最后,祝各位在复杂网络系统的建设和运维中,既能应对挑战,也能找到乐趣。

本文旨在分享数据中心互联网络的技术演进与设计思路,更多关于网络架构与运维的深度讨论,欢迎访问云栈社区进行交流。
 发表于 2026-2-27 05:40:06
|
查看: 256|
回复: 0
发表于 2026-2-27 05:40:06
|
查看: 256|
回复: 0
