你相信光吗?在AI算力需求爆炸式增长的今天,数据中心内部的高速互连正面临带宽与功耗的严峻挑战。传统的电互连(铜线)似乎快走到物理极限,而光互连技术被普遍认为是下一代超大规模计算的必然选择。那么,我们为什么需要从“铜”转向“光”?
- 带宽与密度约束:芯片周围能布置的金属引脚数量受限于物理尺寸,高频铜线靠得太近会产生严重的电磁干扰。即使封装基板做得再复杂,也难以满足未来从10TB/s到100TB/s的外部通信带宽需求。
- 距离与功耗矛盾:为提高带宽需要提高数据传输速率,但速率越高,高频信号衰减越剧烈。为了让电信号传得更远,需要更多Retimer和DSP进行信号放大和补偿,这又带来了新的功耗墙。
近期,在ISSCC 2026(国际固态电路会议)上,三篇重要论文揭示了光互连的最新进展:
- Nvidia 公布了基于MRM(微环调制器)的DWDM(密集波分复用)CPO技术,单波传输速率32Gb/s,实现了单根光纤256Gb/s的传输速率。
- Broadcom (BRCM) 公布了基于MZM(马赫-曾德尔调制器)的6.4Tbps CPO,用于其交换机芯片,主要针对Scale-Out网络。
- Marvell 则针对跨园区(2~40km)场景,提出了基于Coherent-Lite(精简相干)的硅光收发器。
这三家公司采用了不同的调制方案,针对不同的应用场景。技术路线的选择充满取舍,不仅包括光与铜、NPO与CPO的权衡,甚至对“Scale-UP”和“Scale-Out”场景本身的定义也存在模糊地带。
本文将深入探讨光互连的技术现状、核心挑战与未来演进。
1. 光互连现状及挑战
1.1 光互连现状
当前主流的光互连方案采用可插拔光模块。如下图所示,ASIC生成高速电信号(如112G/224G PAM4),通过PCB板的铜走线连接到可插入光模块的笼子(Cage)。有时因距离过长,中间还需要Retimer来补偿信道损耗,消除信号抖动,提升信号完整性。
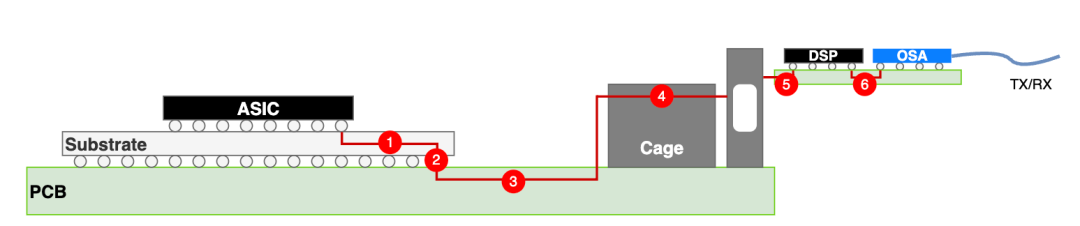
图1:基于光模块的光互连结构
展开看光模块的内部结构,它主要包含一个DSP(数字信号处理器)和一个OSA(光学次组装模块)。DSP负责复杂的信号处理,如均衡、时钟恢复等,这部分功耗通常占光模块总功耗的50%以上。OSA则负责光电/电光转换。
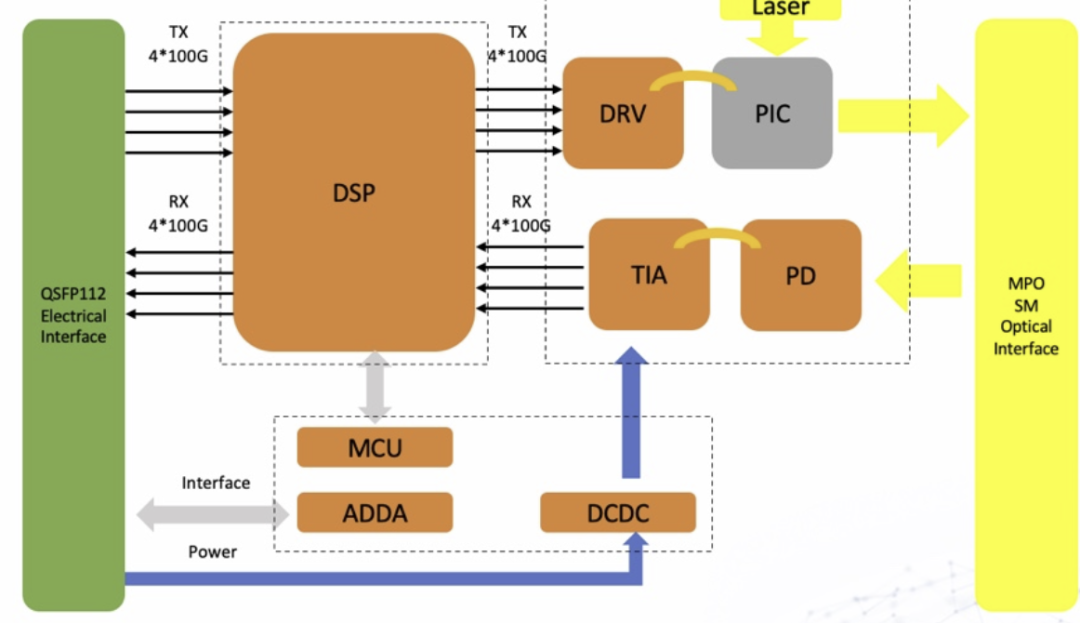
图2:光模块的内部结构
OSA通常分为发送端(TOSA)和接收端(ROSA)。
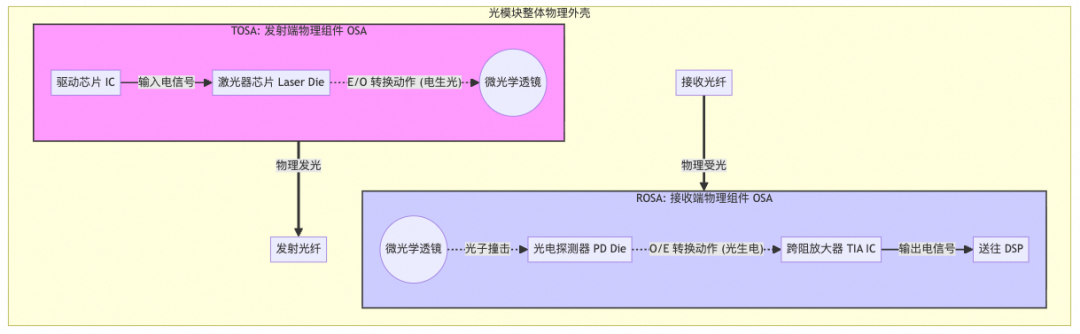
图3:TOSA与ROSA的功能划分
发送端 (TOSA):
来自DSP的高速电信号首先由驱动芯片(Driver)放大,然后送入光子集成电路(PIC)。PIC接收来自激光器的连续光源,在Driver输入的电信号控制下,通过光学调制器将电信号转换为高速闪烁的光信号。
接收端 (ROSA):
光纤接收到的光信号由光电探测器(PD)转换为微弱的电信号,再经过跨阻放大器(TIA)放大后,输出电信号给DSP。
在实际芯片设计中,通常将TIA、Driver、DSP等电路部分集成到电集成电路(EIC)中,而将调制器、PD等光学器件集成到光集成电路(PIC)中。
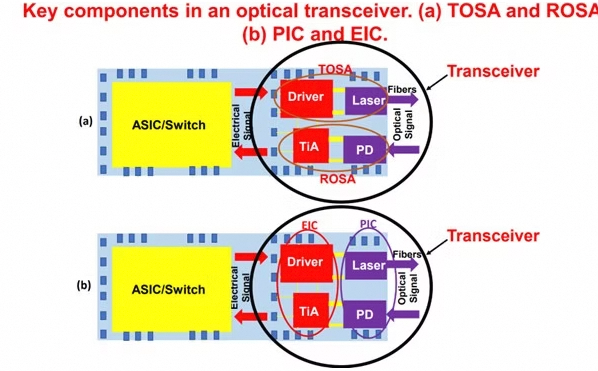
图4:OSA功能划分和EIC/PIC划分对比
1.2 光互连的挑战
从图1可以看到,从ASIC到光模块的路径长、连接点多。随着信号速率(如迈向448G SerDes)的提升,路径损耗急剧增加,需要更强的DSP进行补偿,导致功耗飙升。因此,产业界开始探索各种优化方案。
第一步:去掉功耗最大的DSP -> LPO
随着ASIC工艺进入5nm/3nm,其边缘的SerDes本身已集成强大的DSP。因此,诞生了线性驱动可插拔光学器件(LPO),其光模块内部的EIC只保留Driver和TIA,去掉独立的DSP。这可以降低约40%~50%的功耗和15%~20%的成本,并减少延迟。但LPO严重依赖ASIC SerDes的性能,存在互操作性和调试难题。

图5:LPO架构
第二步:将光器件靠近芯片 -> NPO
为了进一步避免PCB长距离走线和接插件的损耗,出现了近封装光学(NPO),将光器件放置在离ASIC更近的封装基板上。
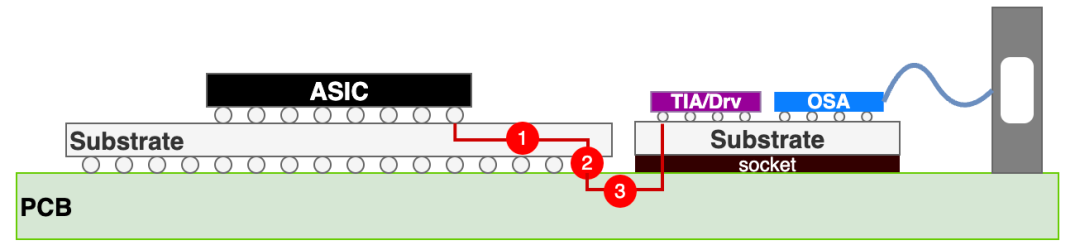
图6:NPO架构
但激光器在高温下易老化。解决方案是将激光器作为可插拔光源(PLS)放在前面板冷区,这能大幅提升平均无故障时间(MTBF)。故障恢复时,也只需更换模块,维修简便。
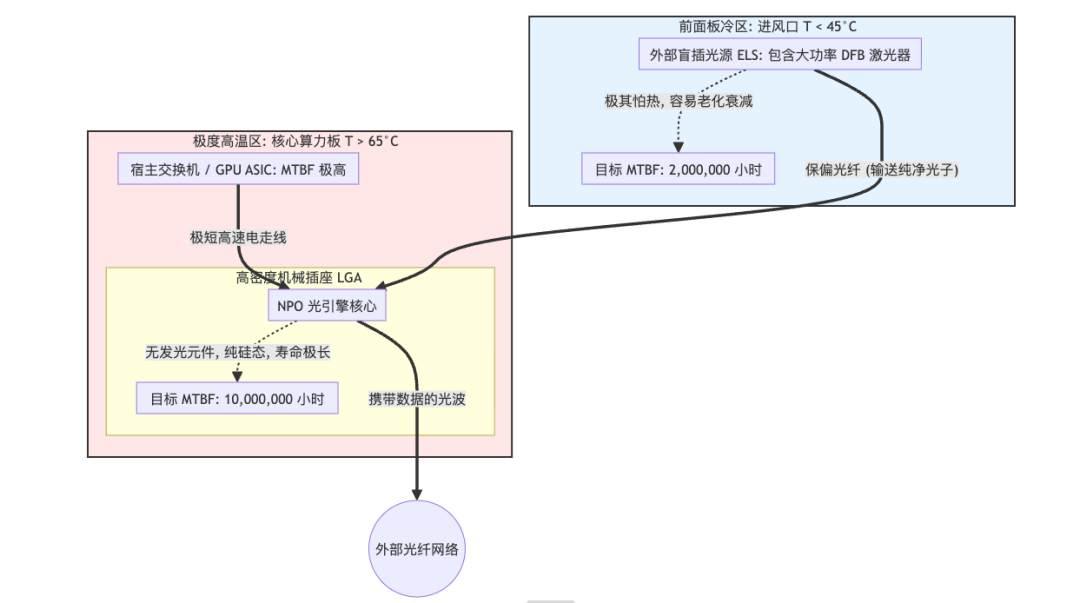
图7:NPO采用外置可插拔激光光源
终极一步:与芯片共封装 -> CPO
当SerDes速率迈向448Gbps时,PCB走线和NPO插座的损耗变得难以承受。同时,为了追求更高的Beachfront(芯片边缘)带宽密度,共封装光学(CPO)应运而生。它将光引擎(OE)通过先进封装技术(如2.5D/3D集成)与ASIC封装在同一基板上,距离仅几毫米,并可用超短距(USR)接口替代传统SerDes。

图8:Broadcom的CPO平台
CPO的优势在于彻底摒弃了PCB走线,极大减少了信号损耗和寄生效应。
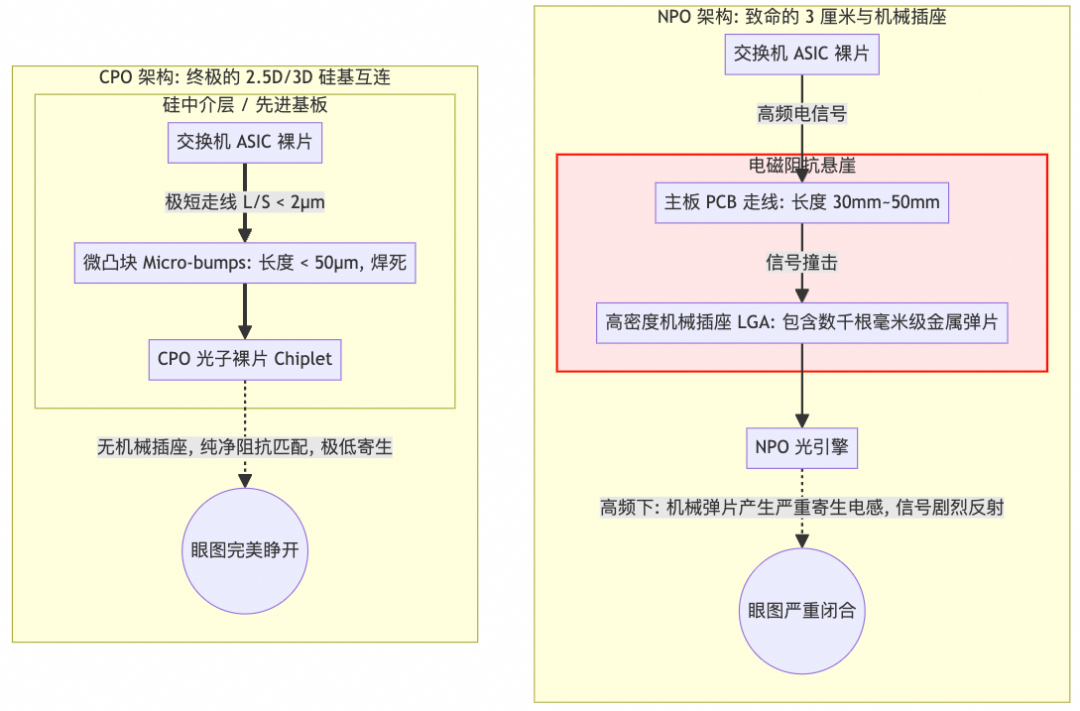
图9:CPO(左)与NPO(右)的信号路径及眼图对比,CPO眼图张开度更优
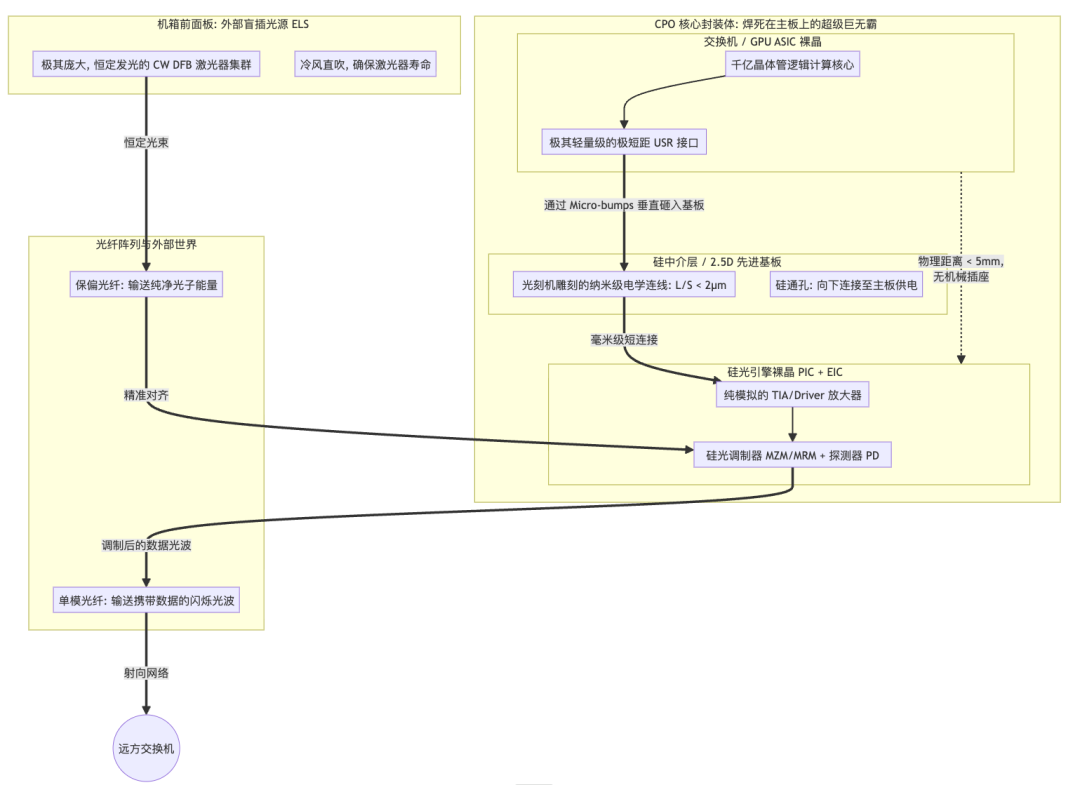
图10:CPO核心封装体结构
然而,CPO并非完美:
- 热管理:光引擎紧靠发热的ASIC,高温影响其寿命和性能。
- 可靠性与良率:单个光引擎故障可能导致整个昂贵芯片(如GPU)报废,对生产良率和运维都是巨大挑战。
- 可维护性:无法像可插拔模块那样单独更换。
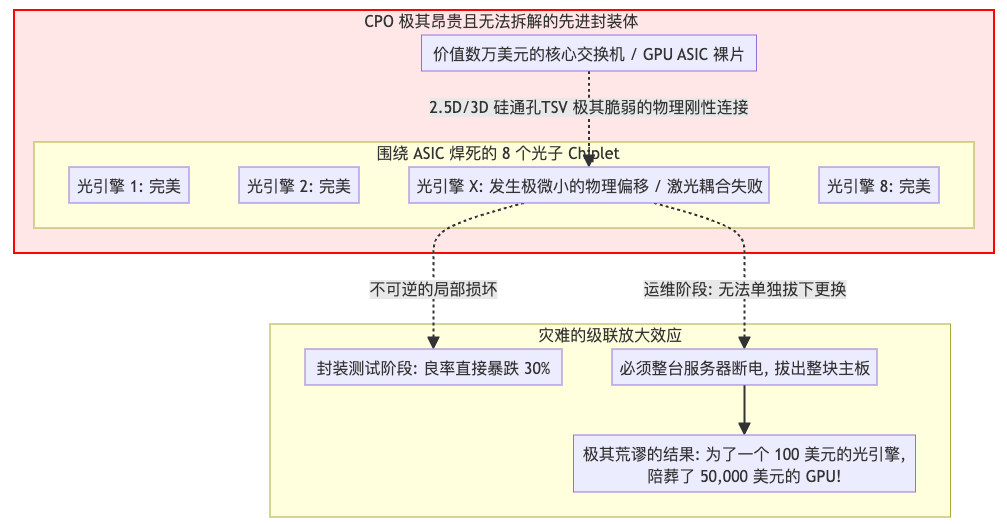
图11:CPO的缺陷:局部故障导致整个封装体失效
那么,为什么巨头们仍致力于CPO?关键在于它带来的带宽密度革命性提升,这是未来算力集群扩展的刚需。业界正在尝试解决上述挑战:
- 采用更高效的液冷方案。
- 选择热稳定性更好的调制器(如MZM)或为MRM设计精密温控。
- 设计可更换的光纤附着单元(FAU)。
- 对于稍短距离,探索基于铜的共封装(CPC)作为过渡。
在深入最新解决方案前,我们需要先理解核心器件——光调制器。
1.3 光调制器
光调制器是将电信号加载到光载波上的关键器件,主要有三种:MZM、MRM和EAM。
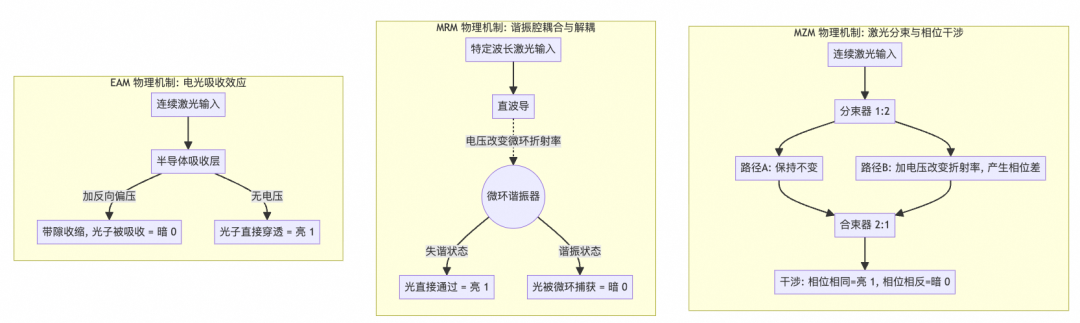
图12:EAM、MRM、MZM三种光调制器物理机制
1.3.1 MZM(马赫-曾德尔调制器)
原理:将输入光等分到上下两臂波导,通过施加电压改变波导折射率,从而改变光速,产生相位差。两路光在出口处汇合发生干涉,相位相同时相长干涉(输出亮,代表1),相位相反时相消干涉(输出暗,代表0)。
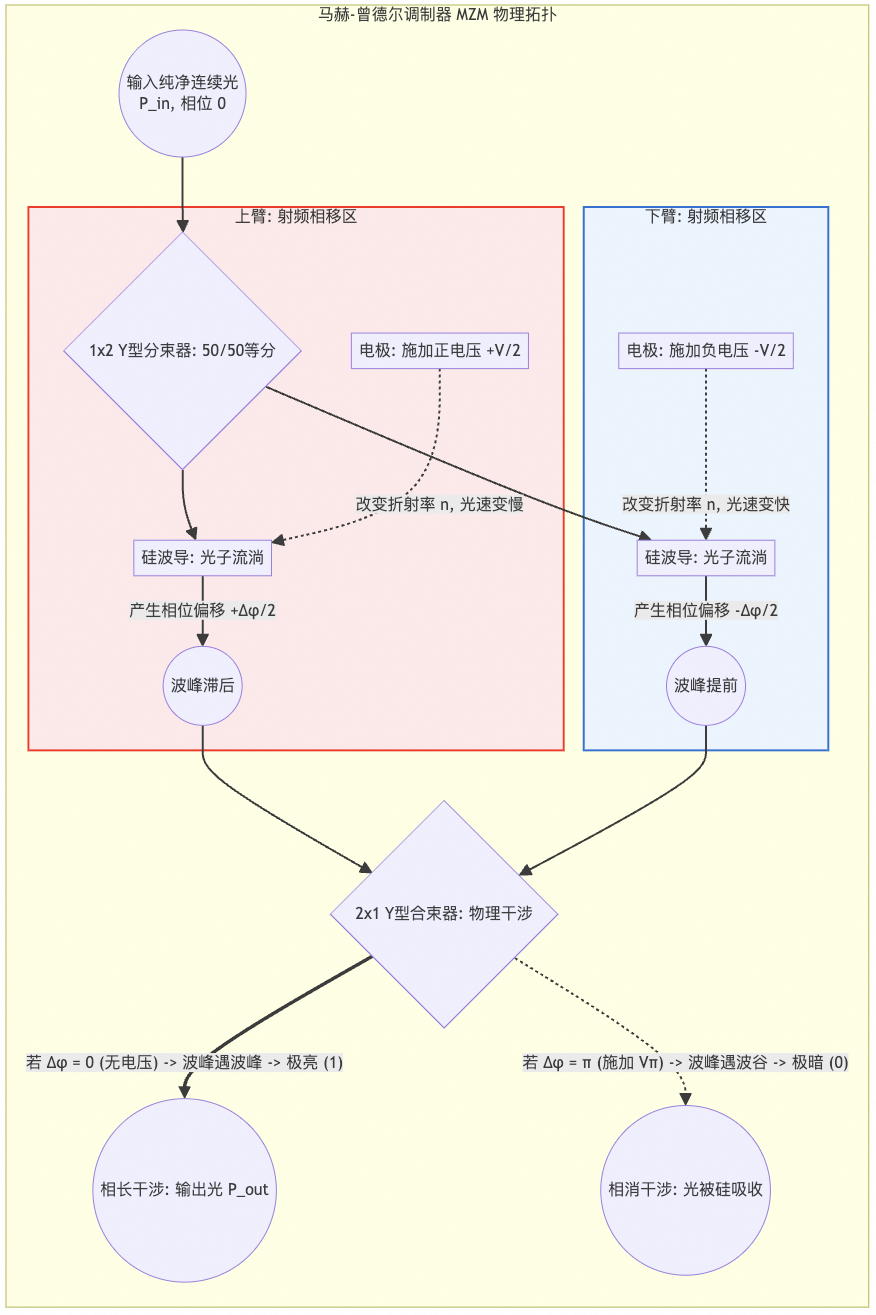
图13:MZM物理拓扑与工作原理
MZM线性度好,适合NRZ、PAM4等高阶调制格式。但缺点是半波电压(Vπ)与调制器长度(L)成反比,为了在低电压下工作,需要较长的调制区(毫米级),导致面积大,Beachfront密度受限,且通常不支持DWDM,需外接复用器。
1.3.2 MRM(微环调制器)
原理:利用微环谐振器的谐振效应。当连续激光的波长与微环谐振波长一致时,光被耦合进环内耗散,直波导输出为“0”;通过电压改变微环折射率,使谐振波长偏移,激光波长失谐,光直接通过直波导,输出为“1”。
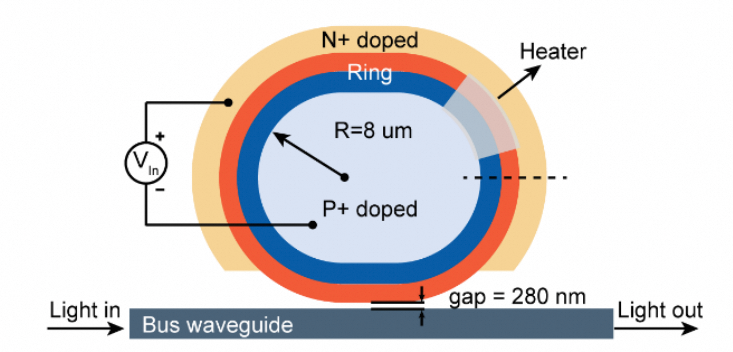
图14:微环调制器结构示意图
MRM尺寸极小(微米级),功耗低,且天然支持DWDM(通过多个半径略有差异的微环即可)。但其致命缺点是对温度极度敏感,温度变化0.5°C就可能导致失效,因此需要集成微型加热器和复杂的闭环温控电路。
1.3.3 EAM(电吸收调制器)
原理:通过在半导体材料上施加反向偏压,改变其能带结构,从而控制对特定波长光的吸收。不加压时光通过(1),加压时光被吸收(0)。
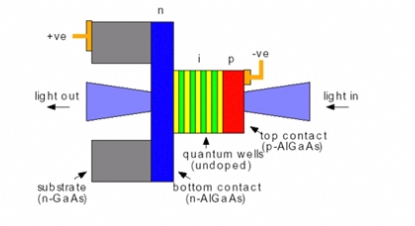
图15:电吸收调制器结构示意图
EAM尺寸较小,功耗低,热稳定性好于MRM。但存在啁啾效应,色散容限较低,且在纯硅平台上集成难度大。
1.3.4 三种光调制器对比
| 技术路线 |
核心调制机制 |
面积占用 |
信号特征与格式 |
能效与功耗表现 |
典型应用场景 |
| MZM |
相位干涉 |
大(毫米级) |
线性度高,适合PAM4等 |
中等,需要较高射频驱动电压 |
主流CPO,500m~2km互连 |
| MRM |
谐振腔耦合与解耦 |
极小(微米级) |
对波长敏感,带宽窄 |
RF功耗极低,但需额外加热调谐功耗 |
高密度CPO,下一代AI集群DWDM互连 |
| EAM |
电致吸收效应 |
较小 |
存在啁啾,色散容限低 |
较低,但在纯硅基底集成难 |
EML可插拔模块,机架内短距互连 |
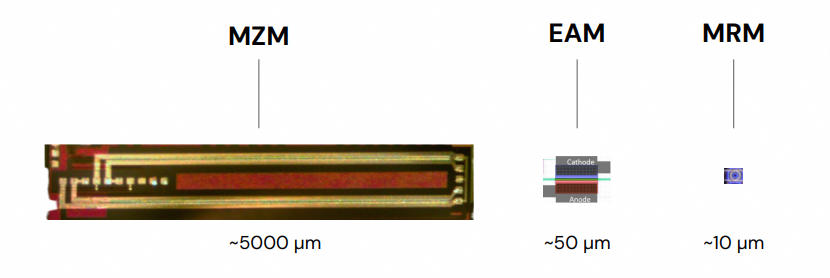
图16:MZM、EAM、MRM尺寸对比(毫米级 vs. 微米级)
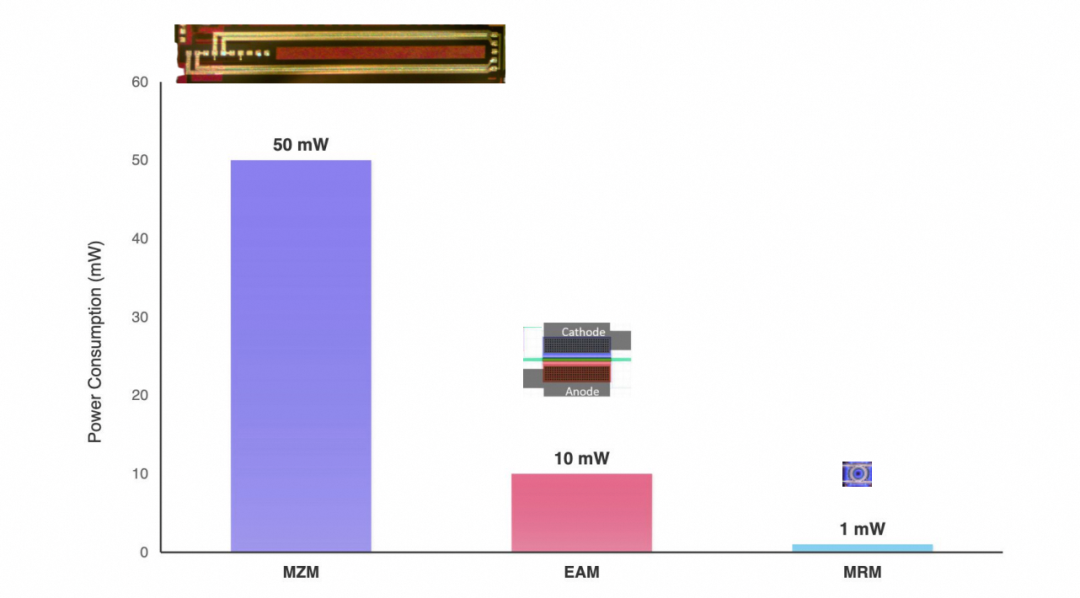
图17:MZM、EAM、MRM功耗对比
在ISSCC 2026上,Broadcom选择了MZM,Nvidia选择了MRM,而Celestial AI等公司则看好EAM。不同的选择反映了对性能、密度、功耗和热管理的不同权衡。

图18:Celestial AI阐述EAM在热稳定性、尺寸和集成度上的优势

图19:学术界对MZM、EAM、MRM的详细对比
驱动CPO发展的根本动力是带宽需求。以NVIDIA B200为例,其两个Die间通过NVLink-C2C的带宽已达10TB/s,而芯片边缘(Beachfront)通过电互连或可插拔光模块能达到的带宽密度远低于此。CPO有望将Beachfront带宽密度提升一个数量级。
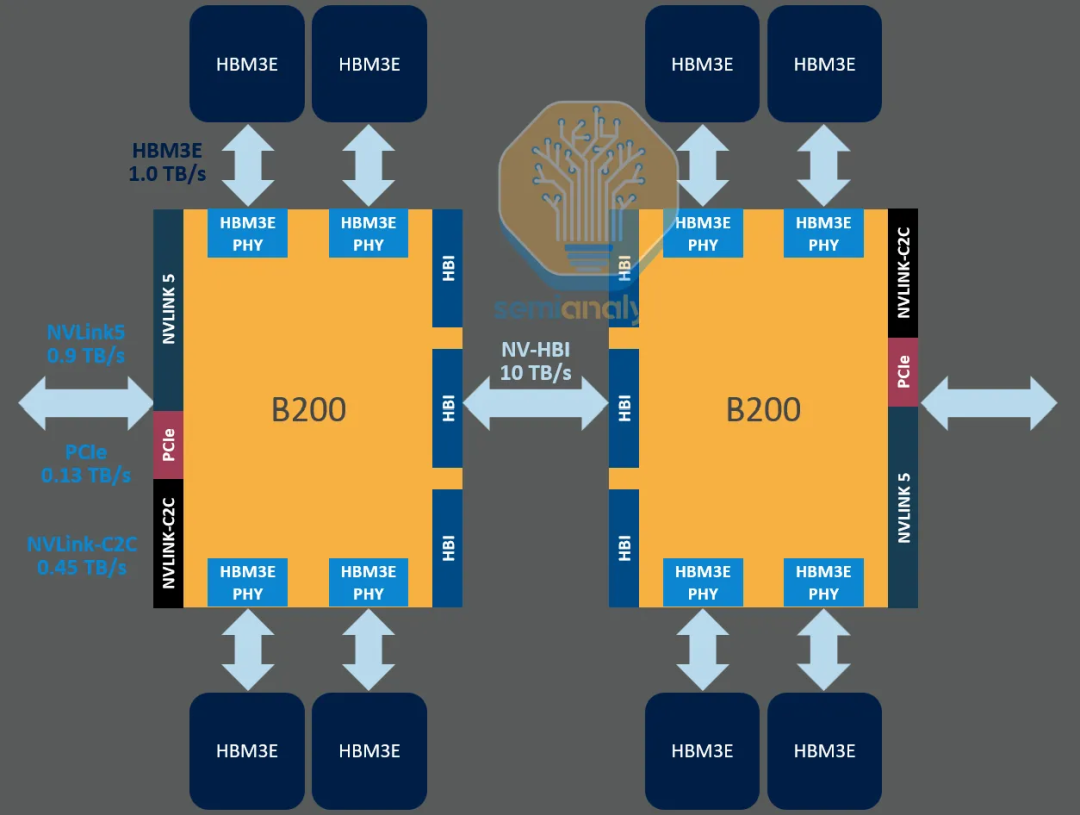
图20:NVIDIA B200芯片互连架构
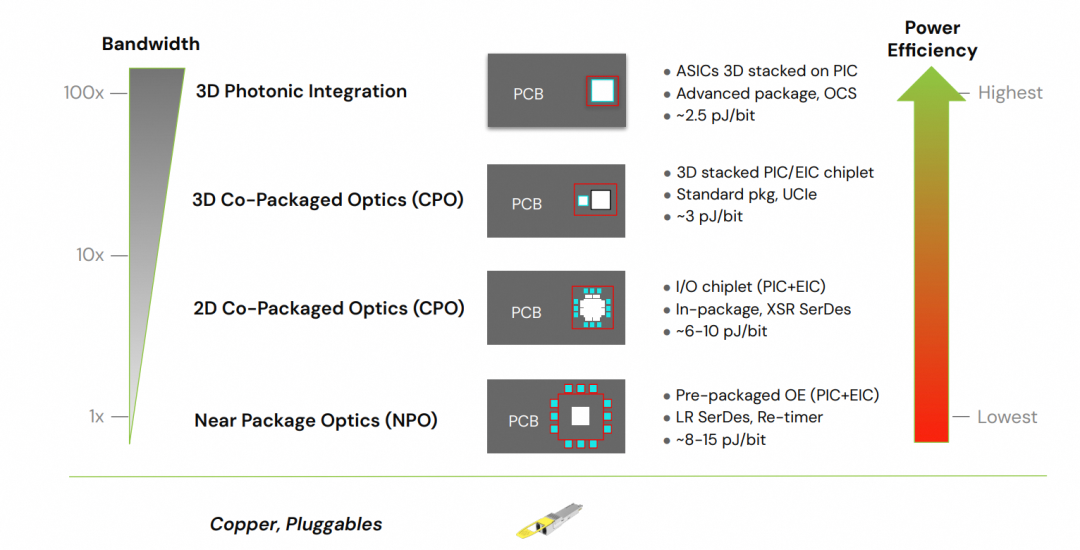
图21:从NPO、2D/3D CPO到3D光子集成的带宽与能效演进
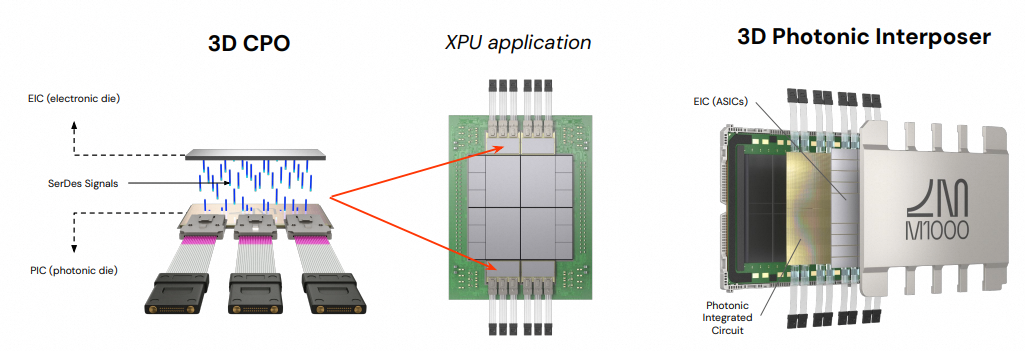
图22:3D CPO与3D光子中介层集成示意图
CPO的商业化道路虽长,但方向明确。接下来,我们剖析ISSCC 2026上的三项关键工作。
2. ISSCC 2026 Session解析
2.1 Nvidia:256Gbps高能效3D堆叠DWDM硅光互连芯片
Nvidia的论文核心在于利用MRM天然支持DWDM的特性,避开复杂的高速PAM4 SerDes,转而采用8个低速32Gb/s NRZ通道,结合1个传输时钟的通道,在单根光纤上实现256Gbps聚合带宽。EIC采用7nm工艺,PIC采用65nm硅光工艺,通过3D堆叠混合键合实现。
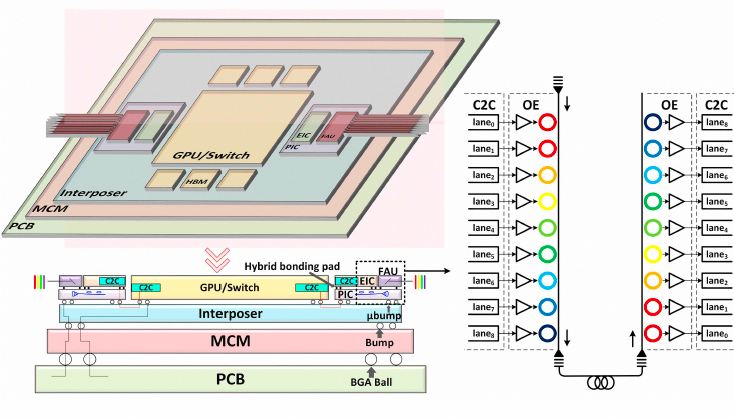
图23:3D堆叠的GPU/交换机与光引擎集成示意图
该设计实现了约 2 pJ/bit 的出色能效和 1.33 Tb/s/mm² 的高面积效率,且在误码率(BER) <1e-11 时眼图张开度达0.46 UI。
核心创新点:
- 时钟方案:采用带通滤波的半速率前向时钟(FWDCLK)。在接收端,对FWDCLK进行1-2GHz带宽的带通滤波,既能跟踪低频相关抖动(如电源噪声),又能有效滤除TIA引入的高频非相关抖动,解决了DWDM链路的时钟抖动难题。
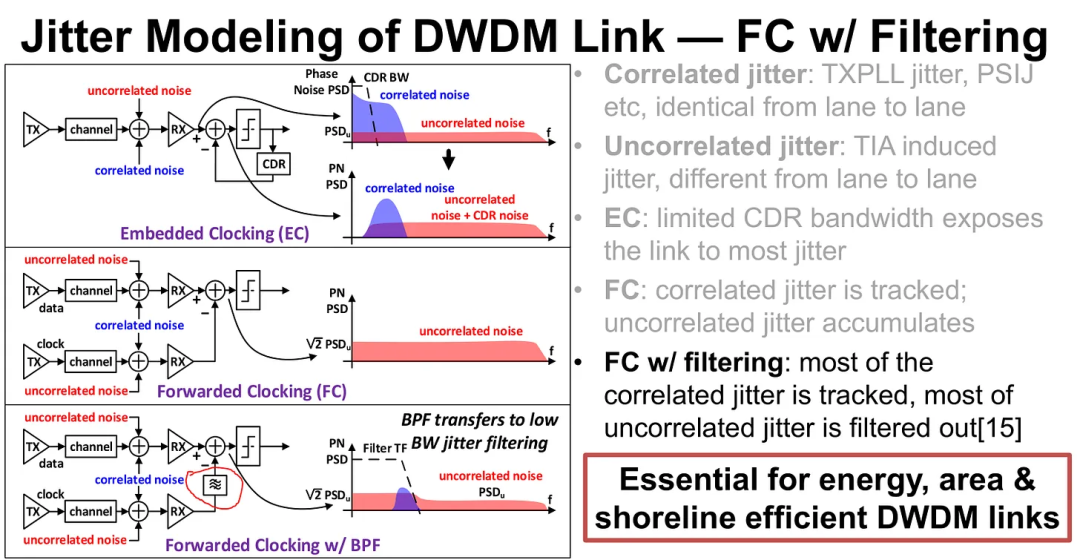
图24:嵌入式时钟(EC)、前向时钟(FC)及带滤波FC的抖动处理机制对比
- 注入锁定振荡器(ILO):在RX时钟分配网络中嵌入ILO,形成有效的带通滤波器,几乎不增加额外功耗。
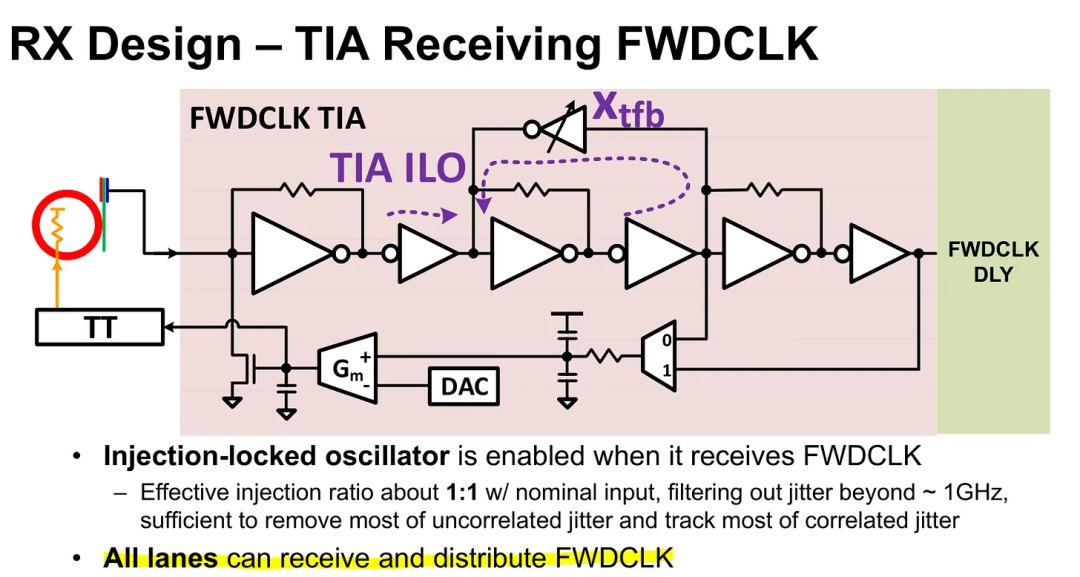
图25:RX端TIA接收FWDCLK的ILO设计
- 热调谐(TT)环路:为每个MRM集成微型加热器和混合信号控制环路,实时锁定谐振波长,克服了MRM的温度敏感性。
- 工艺集成:采用TSMC的COUPE等先进封装技术,实现EIC与PIC的高密度、低寄生互连。
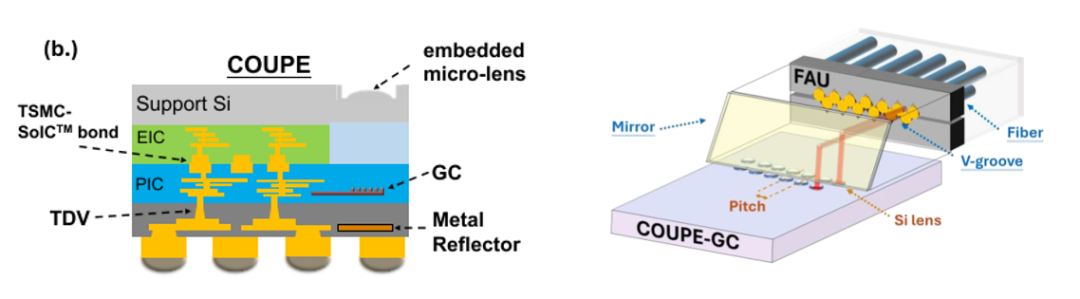
图26:COUPE嵌入式微透镜与光纤附着单元(FAU)结构
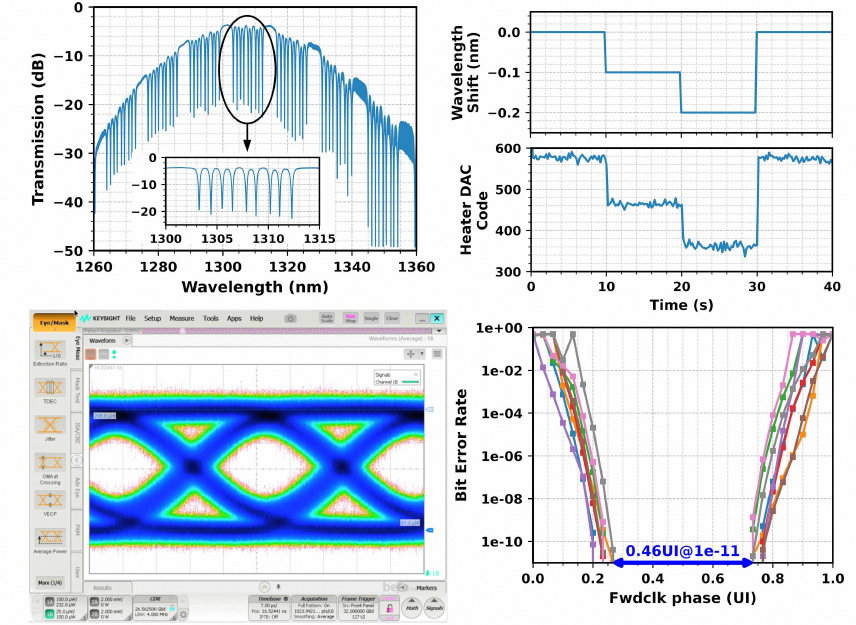
图27:芯片显微照片、测试频谱及眼图结果
这项研究表明,通过“多波长并行+纯模拟前端+精巧时钟架构”的路径,可以在避免复杂DSP的前提下,实现高能效、高密度的光互连,为国内相关技术发展提供了有价值的参考。
2.2 Broadcom:6.4Tbps CPO
Broadcom的设计针对Scale-Out网络交换机对高端口密度(Radix)的需求。其单片CPO引擎提供64个112G PAM4通道(6.4Tbps双向带宽),多个这样的引擎可以围绕一颗交换芯片(如Tomahawk 6)布置,实现极高的总端口数。

图28:Broadcom 6.4Tbps CPO引擎
技术特点:
- 发送端:采用Retimer架构,接收主机数据后,利用DSP处理和分段式MZM驱动器,通过Thermometer编码直接在光域生成PAM4信号。
- 接收端:创新性地采用“直接驱动”TIA,光电转换放大后,直接通过短距基板通道驱动主机ASIC,省去了接收端DSP和CDR,大幅降低功耗和延迟。
- 系统集成:芯片集成了大量监控PD和加热器DAC,具备完善的光功率监控和热管理闭环系统。
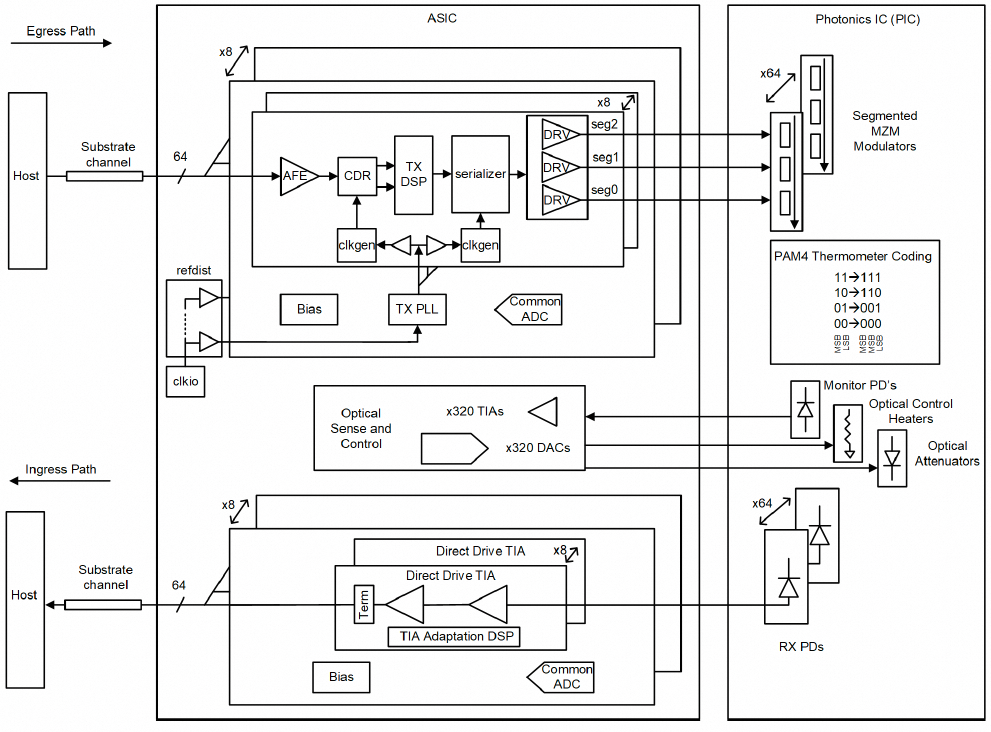
图29:6.4Tbps CPO芯片系统架构图
2.3 Marvell:双通道800Gb/s 300ns延迟Coherent-Lite硅光收发器
Marvell瞄准的是园区间(2-40km)的数据中心互连(DCI)场景。传统强度调制直接检测(IMDD)技术在此距离和速率下遇到瓶颈,而传统相干技术功耗和延迟过高。Coherent-Lite是一种折中方案。
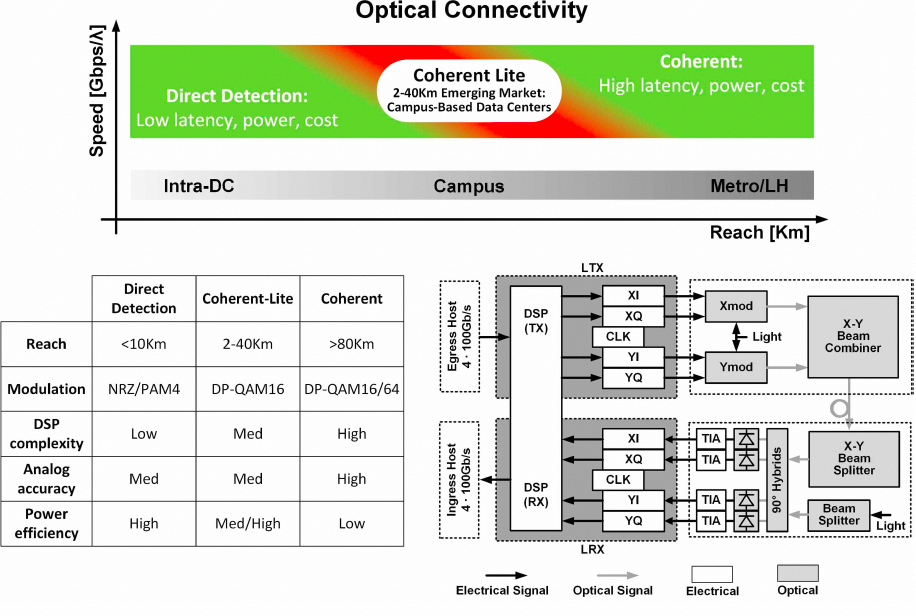
图30:直接检测、Coherent-Lite与全相干技术的应用场景与特性对比
核心思路:
- 使用O波段:传统长距相干使用C波段,色散严重,需要复杂的数字色散补偿(DDC),导致高延迟和功耗。O波段色散近乎为零,虽然光衰减略大,但在40km内可以依靠提高光功率来克服,从而可以砍掉庞大的DDC矩阵。
- 轻量级DSP:采用DP-16QAM调制,但使用简化的DSP算法,在保证性能的前提下,将延迟降低至300ns级别,能效提升约2倍。
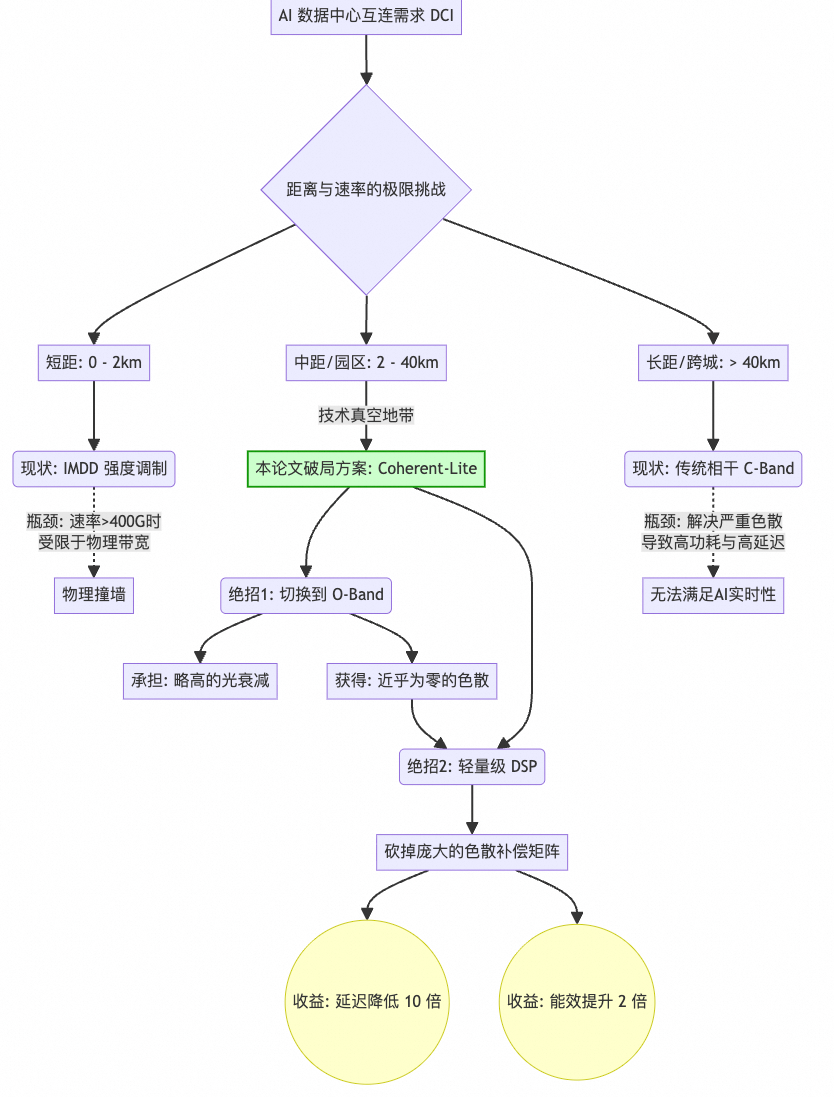
图31:Coherent-Lite通过切换到O波段和轻量级DSP解决园区互连瓶颈
3. 分场景谈谈光互连
3.1 Scale-Across(跨园区互连)
对于2-40km的跨园区场景,Marvell的Coherent-Lite技术在降低延迟方面有显著优势,对业务端到端延迟有积极影响。更远距离(>40km)则因光衰减要求极高的激光器功率和信噪比,仍将以可插拔相干光模块为主。CPO主要针对数据中心内部(<500m)的极高带宽密度场景。
3.2 Scale-Out(横向扩展网络)
Nvidia和Broadcom均已发布CPO交换机产品。国内也有厂商尝试LPO或NPO。在这个场景下如何选择?
3.2.1 TCO和功耗分析
根据SemiAnalysis等机构分析,CPO在交换机层面确实能节省可观的功耗和成本(光模块DSP功耗占比大)。但将其放到整个AI集群的TCO中看,节省比例相对有限(约4%能耗,7%成本)。同时,CPO引入了维护性、可靠性和供应链弹性的新担忧。因此,短期内超大规模数据中心对Scale-Out CPO的采纳可能会比较谨慎。
3.2.2 可靠性分析
可靠性是CPO的核心争议点。据Broadcom与Meta的测试数据,CPO模块的MTBF约为100万小时,而铜缆(DAC)的MTBF可达5000万小时。
对于一个搭载16个CPO模块(每个64通道)的交换机,整机MTBF会急剧下降。假设平均修复时间(MTTR)不同:
- 可插拔模块:MTTR约10分钟,可用性极高。
- NPO:MTTR约20分钟(开箱更换),可用性仍很高。
- CPO:MTTR可能需要数周(整机返修),可用性会大幅降低。
缓解措施包括:
- 采用外部激光源(ELS),使激光器可独立更换。
- 在CPO内部设计冗余通道,通过软件切换绕过故障通道。
- 在网络架构上,将CPO用于骨干(Spine/Leaf),而TOR到服务器仍用高可靠性的DAC,利用网络多路径冗余容忍单链路故障。
3.2.3 结论
个人认为,在Scale-Out网络中,采用NPO进行尝试是可行路径。CPO在此场景的大规模部署,可能需等待Nvidia等公司在特定生态内先行验证。短期内,CSP(云服务提供商)可能不会大规模采用。CPO的终极价值在448G SerDes时代,但当下的Scale-Out网络更关注用更多112G端口提升Radix,而非单一端口速率。
3.3 Scale-UP(纵向扩展,如GPU集群)
对于GPU间互连,CPO能带来近10倍的Beachfront带宽密度提升,诱惑巨大。但可靠性问题同样被放大。以一个NVL72机柜为例,使用CPO与使用铜互连的系统MTBF差异巨大。若进一步扩大Scale-UP规模至512卡,CPO系统的理论MTBF可能仅数百小时,可用性无法接受。这正是Nvidia在其下一代Rubin Ultra架构中仍坚持使用铜互连(NVLink)的原因。
铜互连也有极限,224G SerDes的铜缆有效距离已缩至约2米。产业界正在探索共封装铜(CPC)作为448G时代的过渡方案,它通过飞越电缆(Flyover Cable)直接连接基板,避免PCB损耗。

图32:共封装铜互连(CPC)示例
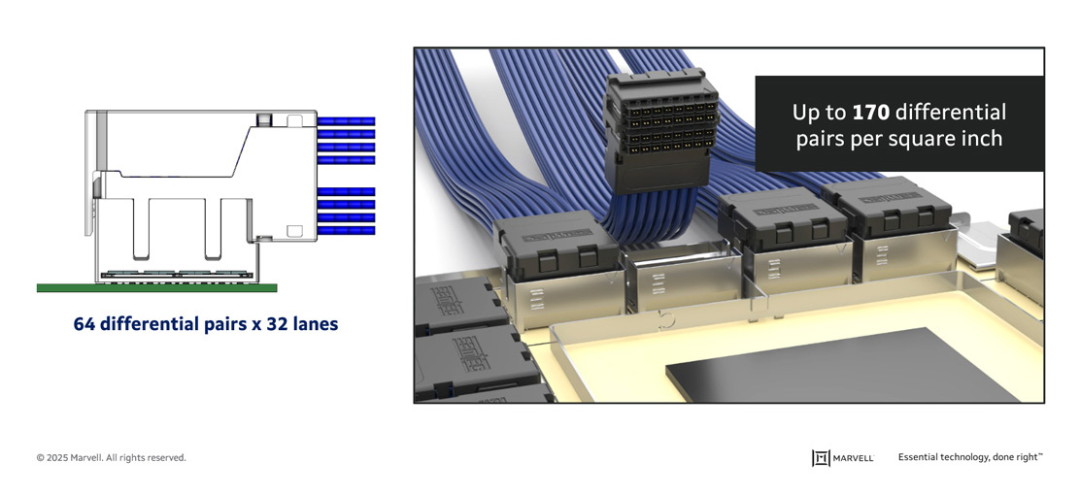
图33:高密度差分对连接器支持CPC
长远看,光互连的带宽密度优势不可替代。Nvidia在ISSCC 2026上展示的基于32G NRZ的DWDM CPO方案提供了一条新思路:避开先进工艺下的高速PAM4 SerDes,利用成熟工艺的并行多波长实现高带宽。随着MRM温控等关键技术成熟,CPO可能在2027-2028年取得实质性突破。

图34:光子织物(Photonic Fabric)技术展现无Beachfront限制的带宽密度
此外,光互连也可能重塑内存架构,例如通过CPO连接的外部光内存池,或如Celestial AI方案所示,用光互连扩展GPU内存容量。

图35:基于光子织物的内存模块与设备
结论
- 技术路径:CPO是突破带宽密度瓶颈的终极方向,但NPO是当前更稳健的过渡选择。MRM(DWDM)、MZM(高线性度)、EAM(热稳定)三种调制器路线将并存,服务于不同场景。
- 落地节奏:CPO可能在2027-2028年随着关键可靠性问题的解决而逐步成熟。Nvidia的DWDM CPO方案(7nm EIC + 65nm PIC)为国内避开尖端SerDes工艺限制提供了可参考的路径。
- 场景选择:在Scale-UP场景,未解决可靠性前,盲目扩大光互连集群规模并不可行。考虑到当前AI推理业务对弹性的需求,未来两年内,工业界在Scale-UP上可能仍将主要依靠铜互连,直至CPO能提供压倒性的带宽密度优势(如4倍于铜,即使有冗余也远超当前)。
光互连的浪潮已至,但航道上仍有暗礁。技术的演进不仅是器件的革新,更是对整个计算机系统架构的重新思考。关于网络协议如何适应这种超低延迟、超高带宽的物理层变化,将是另一个值得深入探讨的话题。对于工程师和架构师而言,理解这些底层技术的权衡与趋势,是在云栈社区等平台进行高质量技术交流与决策的基础。
参考资料
[1] Co-Packaged Optics (CPO) Book – Scaling with Light for the Next Wave of Interconnect: https://newsletter.semianalysis.com/p/co-packaged-optics-cpo-book-scaling
 发表于 2026-2-27 05:44:49
|
查看: 293|
回复: 0
发表于 2026-2-27 05:44:49
|
查看: 293|
回复: 0
