你还在为部署ViT模型的高昂算力成本发愁吗?传统的剪枝方法动辄需要300个epoch的漫长重训练,而Token压缩又对FFN层60%的计算冗余束手无策。今天,一个名为ToaSt的解耦压缩框架,用“外科手术式”的精准剪枝,不仅砍掉了大量计算,甚至让模型精度不降反升!

视觉Transformer(ViT)的强大有目共睹,但它的“胃口”也大得惊人。想在移动端或边缘设备上跑起来?高昂的计算成本(FLOPs)和内存占用常常让你望而却步。你试过剪枝,但漫长的重训练周期(动辄300个epoch)让你耗不起;你也试过压缩Token,却发现它只解决了不到40%的问题,对贡献了超过60%计算量的FFN层冗余无能为力。
有没有一种方法,既能实现硬件级的直接加速,又无需漫长重训练,还能精准打击FFN层的计算冗余?
今天要解读的ToaSt论文,就给出了一个惊艳的答案:在DeiT-Small模型上,它实现了2.07倍吞吐量提升,同时Top-1精度竟然提升了3.58%! 更夸张的是,在ViT-MAE-Huge这样的巨无霸模型上,它砍掉39.4%的计算量后,精度反而提升了1.64%,且性能恢复仅需约15个epoch。
这背后到底隐藏着怎样的设计哲学和技术魔法?它如何颠覆我们对模型压缩的认知?让我们一探究竟。
❓ 核心痛点:为什么传统ViT压缩总是“按下葫芦浮起瓢”?
要理解ToaSt的价值,我们必须先看清当前ViT压缩的两大主流路径及其各自的“死穴”。
路径一:结构化权重剪枝。 思路很直接——整块地移除通道、注意力头甚至整个模块。但问题在于:
- “伤筋动骨”需“大补”:粗暴移除结构后,模型性能会严重受损,必须进行与原始训练时长相当(300+ epoch)的漫长重训练来恢复。这成本高到让压缩本身失去意义。
- “打偏了靶心”:现有方法大多只盯着占计算量约19% 的注意力模块猛攻,却对贡献了超过60% FLOPs的FFN层视而不见。这就像减肥只减掉了水分,没动脂肪。
路径二:Token压缩/合并。 通过丢弃或合并冗余的图像块Token,直接降低序列长度N,从而缓解注意力的复杂度。像DynamicViT、EViT等方法确实有效。
但它的局限同样致命:
- “治标不治本”:它只线性减少了FFN的计算量,却无法撼动FFN内部通道维度级别的核心计算。FFN的冗余依然存在。
- “牵一发而动全身”:Token的丢弃/合并决策会全局传播到所有后续层,形成了复杂的层间依赖,让优化过程变得异常棘手。
所以,我们陷入了一个两难困境:要么忍受漫长的重训练去剪枝(且剪不彻底),要么接受Token压缩对FFN冗余的无力。有没有第三条路?
ToaSt的答案响亮而清晰:有!将问题解耦,各个击破。 它通过一种“分而治之”的哲学,对MHSA和FFN这两个核心模块,分别施以量身定制的“外科手术”。
🚀 原理拆解:解耦的艺术,精准的外科手术
💡 MHSA剪枝:耦合的智慧
为什么传统的注意力头剪枝会损失严重?因为它破坏了注意力机制内在的数学对称性。ToaSt洞察到了关键:Q、K、V、Proj这些权重矩阵并非独立,而是耦合的。
具体来说,对于一个注意力头,其计算流程如下:
这里隐藏着两个必须遵守的同步约束:
- Q-K同步:如果你剪掉了 W_Q^h 的第 j 列,你必须同时剪掉 W_K^h 的第 j 列。否则,Q_h 和 K_h 的维度对不齐,点积无法计算。
- V-Proj同步:如果你剪掉了 W_V^h 的第 j 列,你必须同时剪掉 W_Proj 的第 j 行。这样才能保证经过投影后,输出的维度与原始输入保持一致。
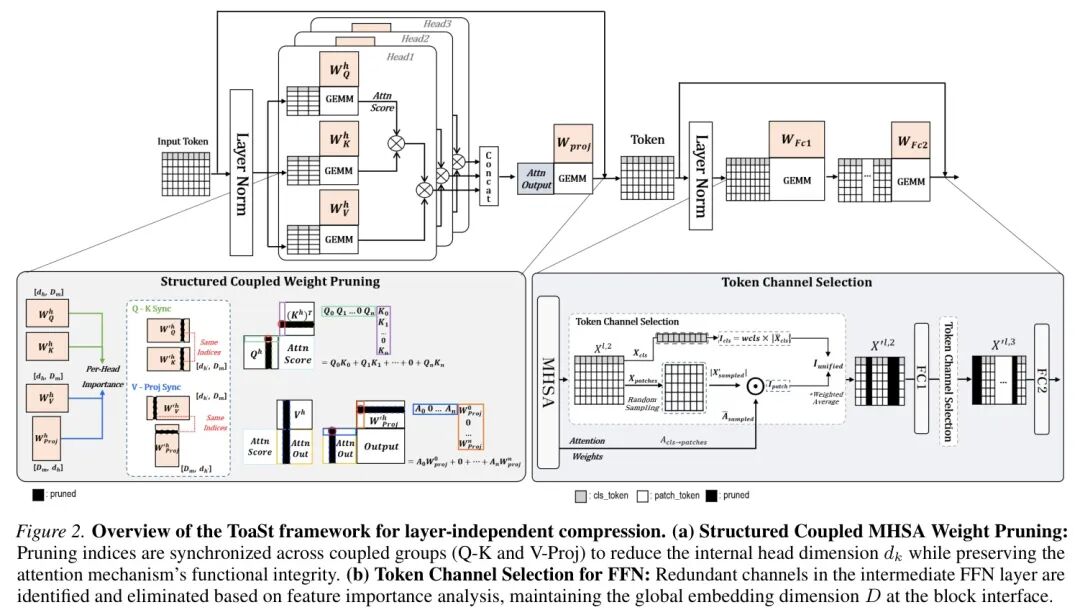
那么,如何判断哪个维度(列)是冗余的、可以剪掉的呢?ToaSt采用了一个优雅的准则:几何中位数(Geometric Median)。
想象一下,一个注意力头内所有维度的权重向量分布在一个高维空间中。几何中位数就是这个空间中的一个“中心点”,使得所有点到它的距离之和最小。离这个中心点最近的维度,其行为最容易被其他维度所替代,因此也就最冗余。 ToaSt正是计算每个权重向量到几何中位数的距离,距离越小,重要性得分越低,越优先被剪枝。
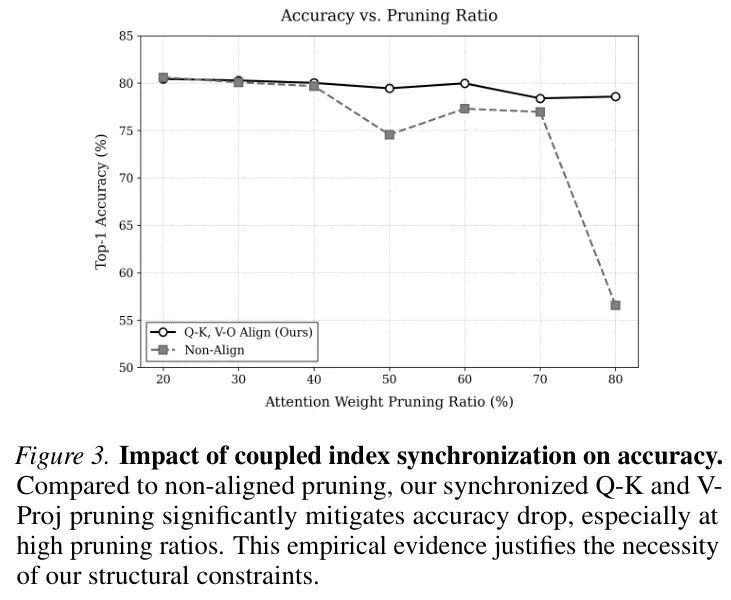
💡 实战思考:这种耦合剪枝的精妙之处在于,它只减少每个注意力头内部的维度,而不改变层与层之间传递的嵌入维度。这意味着残差连接可以无缝工作,下游层也无需做任何调整,实现了真正的“层独立”压缩。
💡 FFN压缩:免训练的通道选择
解决了MHSA,我们来啃最硬的骨头——FFN。FFN通常先将维度从 D 扩展到 4D(FC1层),经过GELU激活,再压缩回 D(FC2层)。这 4D 量级的计算是主要负担。
ToaSt提出了一种颠覆性的思路:既然FFN层存在大量冗余,我们能否不经过训练,直接在推理时动态选择重要的通道? 答案是肯定的,但这需要坚实的证据。
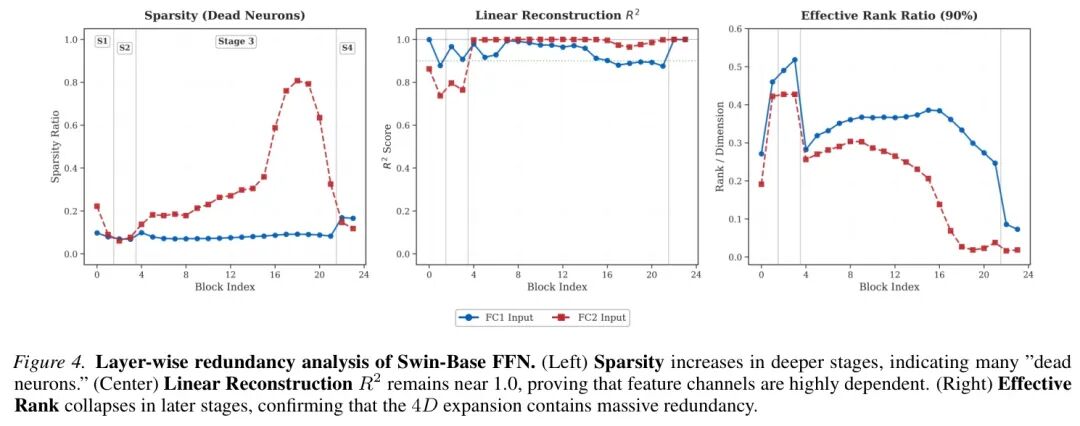
作者对FFN激活进行了深入“体检”,发现了三大特征,这就像发现了冗余的“指纹”:
- 高稀疏性:越深的层,激活值接近零的神经元比例越高。很多神经元根本不干活。
- 高线性相关性(R² 接近1):用一个通道的激活值,几乎可以完美地由其他通道的线性组合重构出来。这说明通道间信息高度冗余。
- 有效秩坍缩:尽管维度扩展到了4D,但有效表征信息所需的维度(秩)在深层急剧下降。空间很大,但真正有用的“物品”很少。
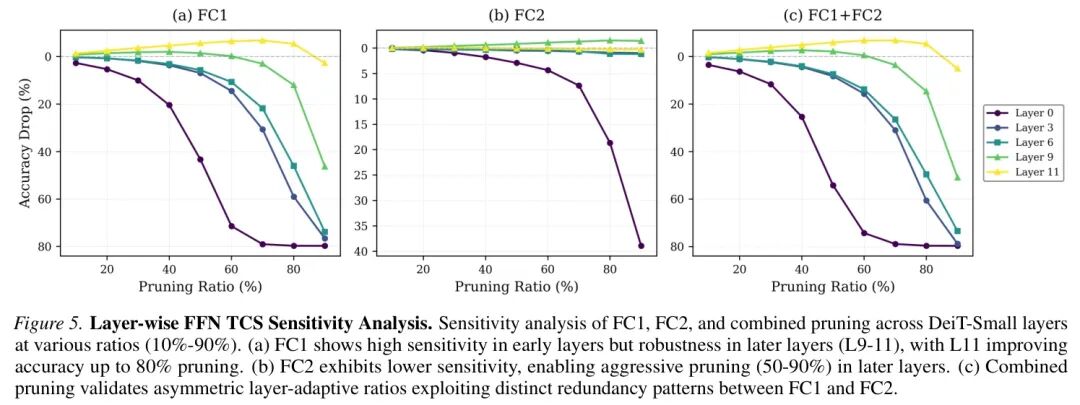
基于这些发现,ToaSt设计了 Token通道选择(TCS) 方法。它的核心思想是:在推理时,针对每一个输入样本,动态地选出FFN层中最重要的那些通道。
具体如何选择呢?这里有一个巧妙的“注意力引导”策略。对于有关注类别(CLS)Token的模型(如DeiT),通道 c 的重要性得分 s_c 由两部分构成:
- 第一项 (|a_{c, cls}|):衡量该通道在全局语义Token(CLS)上的激活强度。这抓住了通道对整体分类决策的贡献。
- 第二项:衡量该通道在所有图像块Token上的加权激活强度,权重来自CLS Token对各个图像块的注意力 α_cls,i。这抓住了通道在关键局部区域上的响应。
通过给全局项(|a_{c, cls}|)更高的权重,TCS能够优先选择那些编码全局语义信息的通道,而不是仅仅在某些局部区域激活很高的“噪声”通道。
💡 实战思考:TCS最厉害的地方在于 “免训练” 和 “结构化”。它不需要任何反向传播和权重更新,仅凭前向传播的统计信息做决策。同时,它裁剪的是整个通道(移除FC1的一列和FC2的一行),保持了密集矩阵结构,因此能在标准GPU上获得即时的、可预测的加速,无需任何稀疏计算库。
📊 实验验证:数据说话,全面碾压
🏆 ImageNet分类:效率与精度的双赢
理论再美,也需要实验的检验。ToaSt在ImageNet-1K上对DeiT、ViT-MAE、Swin Transformer三大系列共9个模型进行了全面测试,结果令人震撼。
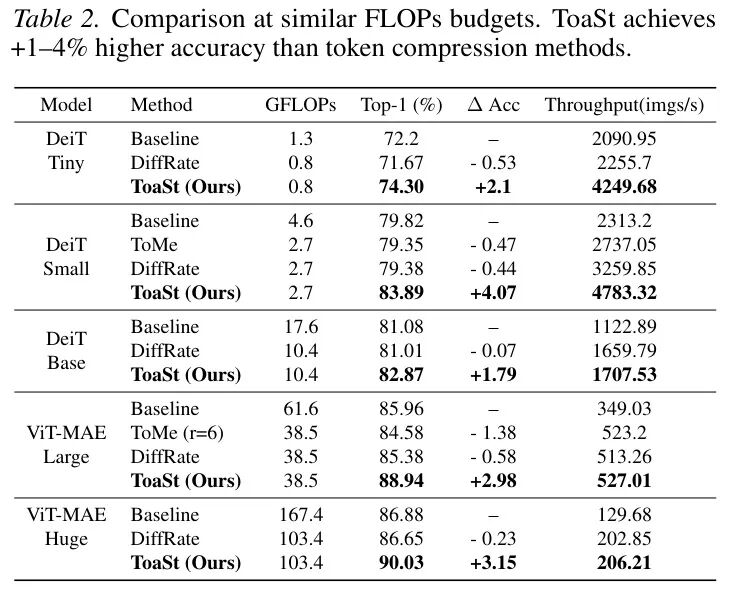
我们来看几个亮点数据:
- 精度不降反升:在减少39.4% FLOPs的情况下,ViT-MAE-Huge的精度从86.88%提升至88.52%(+1.64%);DeiT-Base精度提升+3.02%。TCS起到了强大的隐式正则化作用,过滤掉了冗余噪声。
- 硬件加速实实在在:在NVIDIA H100上,DeiT-Small的吞吐量达到4783.3 img/s,是原始模型的2.07倍,同时精度提升3.58%。这证明了结构化剪枝对硬件极其友好。
- 大模型恢复极快:一个反直觉但至关重要的发现:模型越大,压缩后恢复所需时间越短。ViT-MAE-Huge仅需约15个epoch微调即可超越原模型,而Base版本需要297个epoch。这说明大模型的内在冗余度更高,ToaSt的精细修剪恰好移除了这些冗余。
🔬 消融实验:组件缺一不可
ToaSt的两个组件是互补的吗?消融实验给出了肯定的答案。
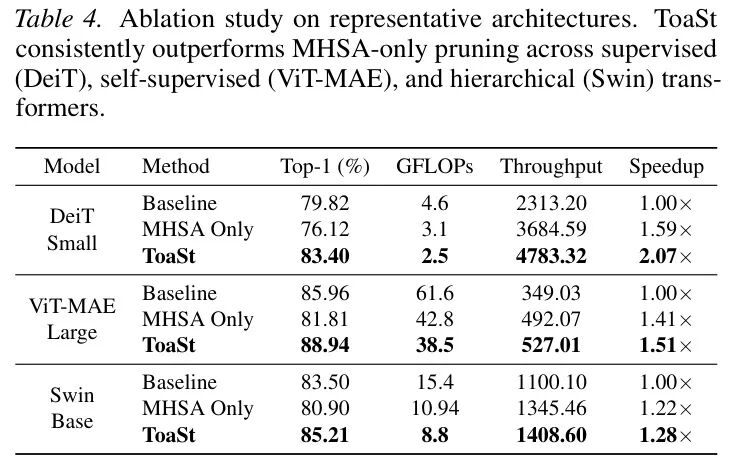
- 仅用MHSA剪枝:可以获得1.22-1.59倍的加速,但会导致2.6%-4.2% 的精度下降。
- 结合TCS后:不仅能进一步加速,更能将精度恢复并反超Baseline 1.7%-3.6%。
这清晰地验证了作者的解耦设计:MHSA剪枝负责削减注意力计算,而TCS负责清除FFN中的噪声通道,两者协同,效果倍增。
⚖️ 客观评价与未来展望
优势总结:
- 解耦设计,精准高效:针对MHSA和FFN的不同特性设计专属策略,直击痛点。
- 免训练压缩:TCS组件无需重训练,极大降低了应用门槛和成本。
- 精度提升:通过去除冗余噪声,模型泛化能力反而增强。
- 硬件友好:保持结构化稀疏,实现即时的端到端加速。
- 泛化性强:在分类、检测等多个任务和多种ViT变体上均验证有效。
局限性:
目前,每层的剪枝比例需要根据经验或分析手动设置。未来的一个方向是让模型自动学习最优的层间剪枝调度策略。
未来展望:
- 自动化:引入可学习的剪枝比例优化器。
- 扩展性:将这套解耦思想扩展到更庞大的视觉语言模型(VLM)。
- 组合技:与模型量化等技术结合,追求极致的部署效率。
🌟 价值升华
ToaSt为我们打开了一扇新窗:模型压缩不是简单的“做减法”,而可以是“做优化”。它告诉我们:
- 理解结构比暴力剪枝更重要:耦合剪枝揭示了模块内部的结构化约束。
- 激活分析是指南针:基于数据的冗余分析能指引无监督的压缩方向。
- 大模型可能更“耐剪”:丰富的表征能力使其在去除冗余后能快速恢复甚至提升。
这项技术最有可能在移动端AI应用、实时视频分析、边缘计算设备等对计算效率和精度都有苛刻要求的场景率先落地,催生更强大的端侧视觉模型。
这个解耦压缩的框架思路非常清晰,其技术细节和实验结果也颇具说服力,值得在技术社区深入探讨。如果你对这个高效的开源实战方案感兴趣,或者想了解更多前沿的模型压缩技术,不妨来云栈社区交流分享你的见解。
参考
ToaSt: Token Channel Selection and Structured Pruning for Efficient ViT
 发表于 2026-3-2 07:35:02
|
查看: 163|
回复: 0
发表于 2026-3-2 07:35:02
|
查看: 163|
回复: 0
