要让机器人或虚拟角色在复杂的真实场景中自如活动,首先需要为它们“喂食”大量高质量的人类动作数据。然而,获取这些数据一直是项成本高昂、流程繁琐的挑战。
传统的动作捕捉方案,无论是需要穿戴满身标记点的专业动捕服,还是依赖几十个摄像头阵列的专业工作室,不仅造价惊人,其使用场景也被严格限制在特定场地内。
近期,由香港大学等机构的研究团队提出的创新框架 EmbodMocap,为这一难题带来了突破性的低成本解决方案。该框架仅需两部普通的苹果手机,即可在非受控的野外环境下,实现高精度的4D人体与场景同步重建,将数据采集成本降至千元级别。它输出的度量级精度运动和场景数据,为低成本、高质量的具身智能数据采集树立了新标杆。

论文“EmboMocap: In-the-Wild 4D Human-Scene Reconstruction for Embodied Agents”展示了来自港大、坦佩雷大学、港中文和马克斯·普朗克信息学研究所的合作成果。
项目代码即将开源:https://github.com/WenjiaWang0312/EmbodMocap
具身智能的核心在于让智能体在真实物理世界中实现感知、理解与自主动作,而这一切的基石正是高质量、场景化的人体运动数据。传统方案各有局限:多视角相机阵列受限于工作室环境;穿戴式动捕设备会干扰自然动作并破坏视觉信息;激光雷达则价格昂贵且不便携。
EmbodMocap 的核心创新并非依赖昂贵的硬件,而是通过巧妙的算法设计,实现了对两部手机采集的 RGB-D 视频序列进行联合校准与优化。其完整流程分为四个紧密衔接的阶段,逐步将原始视频转化为精确的4D重建结果。
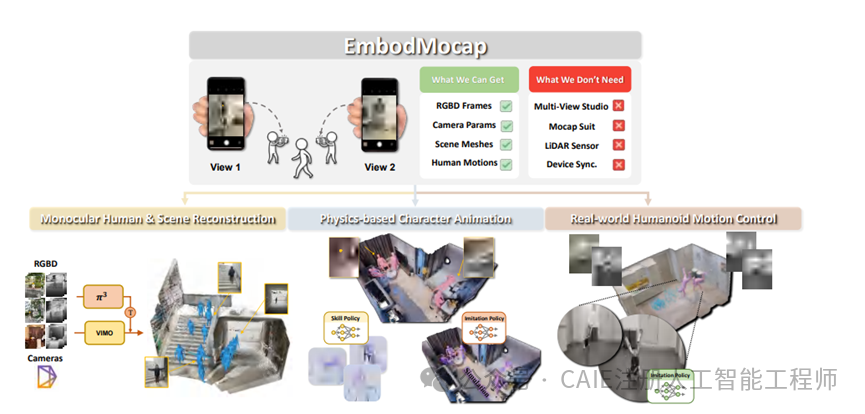
EmbodMocap系统架构,展示了从仅需的RGBD帧和相机参数输入,到最终输出场景网格与人体动作的完整流程。
技术流程详解
流程的第一步是场景预扫描,而非直接拍摄人物。研究者使用一部手机像扫地机器人一样在目标环境中移动一圈,采集环境的RGB图像和深度信息。
这一步借助 SpectacularAI 的 SDK 软件,能够智能地估计摄像头的位姿(位置和朝向),从而构建出一个带有真实尺度的静态场景地图。关键在于,该系统生成了 Z 轴对齐的世界坐标系,这意味着它建立了一个具备重力感知的真实物理空间,不仅能识别地面,还能将整体误差控制在厘米级别。
接下来进入主体拍摄阶段。两名摄影师分别手持两部手机,跟随表演者移动并进行双视角视频录制。这里解决了一个关键问题:如何确保两部手机录制的视频严格同步?研究团队采用了一个巧妙的低成本的“打板”方案——在拍摄开始时,用激光笔照射两个手机的摄像头,后期算法通过自动识别激光点消失的那一帧,即可极其精准地对齐两个视频流的时间轴。
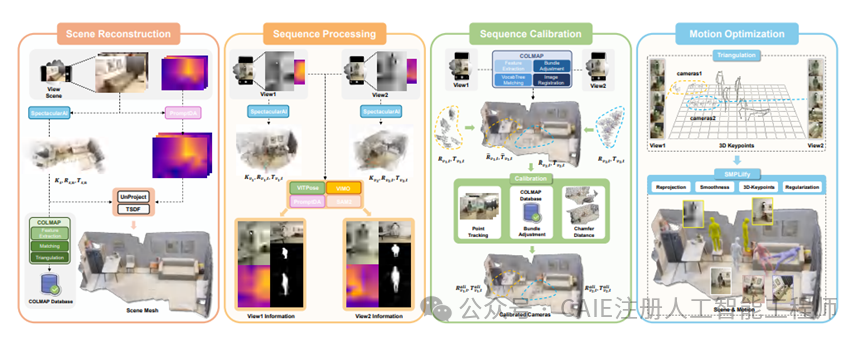
从场景重建、序列处理、序列校准到运动优化的四阶段技术流程图。
获取视频数据后,系统开始自动化处理。它会调用一系列成熟的 AI 模型流水线:使用 YOLO 进行人体检测,ViTPose 提取人体2D关键点,SAM2 分割人体轮廓,并使用 PromptDA 来修正深度图的误差。这套组合拳使得即使是从手机拍摄的视频中,也能提取出高质量的人物与场景信息。
单目视觉最著名的难题是深度歧义,即无法准确判断物体与摄像机的距离。EmbodMocap 通过其设计的双目校准模块巧妙地解决了这一问题。其原理类似于人类的双眼视觉:利用两个视角之间的视差来精确定位。
系统首先从两个视频序列中分别提取特征点,并尝试将这些点匹配到第一阶段构建的静态场景地图中。然而,在手机移动拍摄时,仅靠特征点匹配容易产生较大漂移。为此,研究者引入了包含多重约束的联合优化过程。
优化不仅要使两个视角下重建出的人体表面点云尽可能重合,还要让背景点云与预扫描的场景地图对齐。算法在此过程中不断调整参数,以平滑抖动并避免不合理的“穿模”现象。这就像是将两张拼图碎片拼合,不仅人物的形状要对上,背景中的家具等元素也需严丝合缝,最终将所有坐标系统一到真实的世界尺度下。
数据校准完成后,最后一步是优化动作本身的自然度。直接由双视角2D关键点三角测量得到的3D骨架动作可能仍显僵硬,存在滑步或身体扭曲。
系统利用三角测量将2D关键点提升至3D空间,生成初步的3D骨架。随后,进一步结合参数化人体模型 SMPL,对人物的形状、姿态和全局位置进行联合优化。这个过程如同调整一个木偶的姿势,既要保证关节角度自然,又要确保其位于已重建的场景中。
最终的损失函数综合了重投影误差、3D关键点误差、运动平滑性约束以及人体姿态先验。经过这番精细化调整,得到的结果既保证了动作的流畅性,也确保了人物能够稳定地“站立”在地面上,避免了脚部穿透地面或悬浮等不真实的现象。

(a)(b)(c)(d)四组动作对比,左侧为EmbodMocap的模拟结果,右侧为参考动作。
性能验证
为验证 EmbodMocap 的性能,研究团队进行了多组严格测试。在损失函数消融实验中,五大核心损失函数(跟踪、Chamfer距离、重投影、平滑性、3D关键点)协同作用时,系统实现了73%的IoU(交并比)和仅9.3的重投影误差,各项指标达到最优组合。
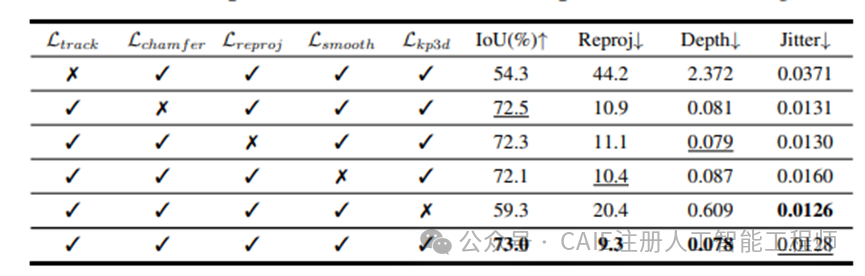
不同损失函数组合下的性能对比表格,展示了IoU、重投影误差等关键指标。
更硬核的对比在专业的Vicon光学动捕工作室中进行。结果显示,EmbodMocap的双视角方案在精度上显著优于单视角方案和经典的单目模型GVHMR。在100帧长度时,其WA-MPJPE(加权平均每关节位置误差)仅为56.61,即使在长序列中精度衰减也非常缓慢。实地测量显示,其场景校准误差仅约5厘米,远优于单视角方案的30厘米误差。
这种双视角设计的优势显而易见:它不仅通过视角互补有效解决了人体关节遮挡问题,还能通过像素级的稠密匹配,实现人体运动轨迹在场景坐标系中的精准锚定。
EmbodMocap的出现,显著降低了高质量计算机视觉与运动数据采集的门槛,为机器人学、虚拟现实、影视制作等领域的人工智能应用开发提供了新的可能性。其将算法创新与消费级硬件结合的思路,值得广大开发者和研究者深入探讨。对这类前沿技术感兴趣的读者,欢迎到云栈社区交流分享。
 发表于 2026-3-3 03:43:09
|
查看: 164|
回复: 0
发表于 2026-3-3 03:43:09
|
查看: 164|
回复: 0
