本文将求根溯源,从历史时间线发展的角度一起来看看 AI 是如何诞生的,以及在诞生后这几十年的发展过程中经历了哪些变革和演进。
在演进的过程中我会介绍大量涉及到的细分技术模块,希望大家对 AI 整体的技术模块及互相之间的关系都有系统化的了解。
01 前世:AI 出现前
1、唯一的高等智慧动物-人类
人类在地球上最早以人猿的方式出现,经历了几百万年的进化和发展,人类成为了地球食物链的顶端,也成为了唯一的高等智慧动物:具备了复杂的多语言、推理和抽象思维、创造、发明以及最重要的多文明体系。
而人类能发展成为这样,背后最重要的原因是:人类大脑的独特性,人类大脑能支撑抽象思维、推理思维、语言创造、知识学习和传承、发明和创造、文明建立和传承等多维度能力,而这些正是人类的“智能”能力。
 (人类大脑的简要结构图-图片来源于AI生成)
(人类大脑的简要结构图-图片来源于AI生成)
通过上图我们会发现除了左脑、右脑这些分区结构外,还有树突、轴突这些专业名词,而这些专业名词正是大脑里“神经元”的一部分,而人类大脑拥有将近860 亿个“神经元”,这些“神经元”承担了所有信息的处理和传递工作,所有大脑的活动都依赖其协同工作。
这也很显而易见的让人类具备了感知、思维、情绪、运动控制、语言交流等多维度的智能能力。
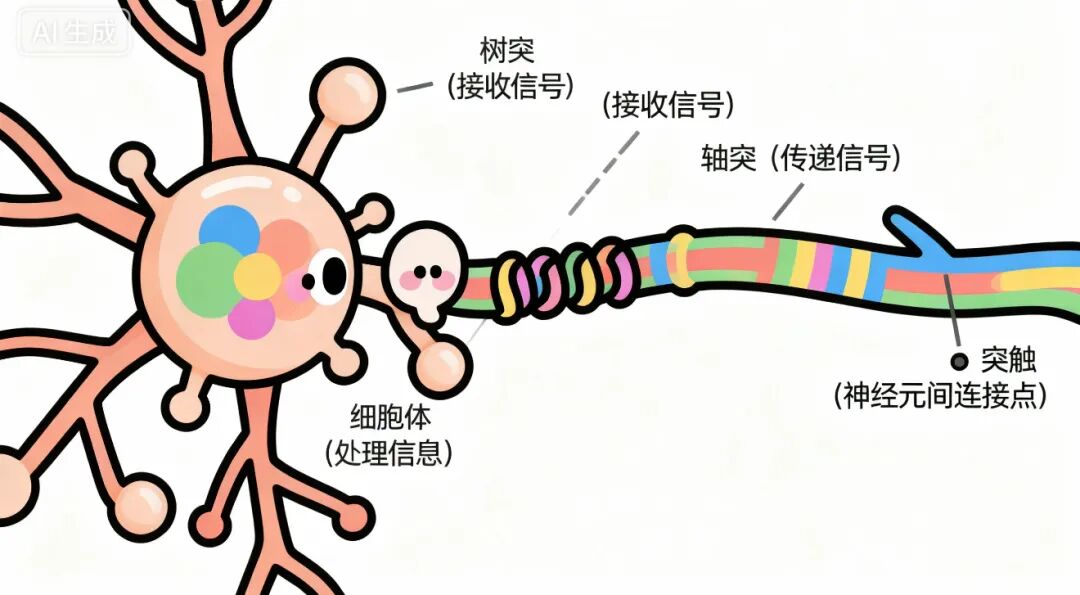 (人类大脑“神经元”的工作原理-图片来源于AI生成)
(人类大脑“神经元”的工作原理-图片来源于AI生成)
在人类几百万年的发展过程中,人类依靠大脑具备了非常强大的智能能力,这是地球上其他动物无法比及的。后来人类发现虽然大脑很强大,拥有几百亿的神经元,但记性和效率有待提升。于是便思考能否解放大脑、让机器代替人类去执行繁复计算?
2、第一台计算机诞生
 (第一台计算机诞生-图片来源于AI生成)
(第一台计算机诞生-图片来源于AI生成)
这就催生了第一台计算机的出现,第一台计算机在 1946 年被发明,开创性地解决了“快速算、精准存”的问题。
但有一个问题是这台计算机只是听话但不会思考,比如你让他计算 1000 遍乘法可以迅速给你算出来,但他不会思考这些乘法之间的规则或关联以便下次更好的计算。
直到后来,科学家发现人类大脑的厉害之处不在于有 860 亿个神经元,而在于 860 亿个神经元像“亿级路由器”一样互相联通,形成了极其复杂的“神经网络”,而“神经网络”可以让大脑具备自我学习、提炼规律的智能能力。
于是他们想:能不能模仿神经网络,造一个“机器神经网络”?这便有了AI的雏形。
02 今生:AI 初生期(1956-1989)
1、AI 概念定义
在 1956 年达特茅斯会议上,科学家首次提出“人工智能(Artificial Intelligence 缩写为 AI)”的专业术语,明确提出了“让机器模拟人类智能”的研究目标,这是 AI 成为独立学科的起点。
那么,到底什么是“人工智能(AI)”?这里其实已经有明确定义:人工智能(AI)是让机器模拟人类智能的技术总称。
而“人类智能”可以简要概括为:让机器具备“感知、思考、决策、执行”的能力。
 (过马路示意-图片来源于AI生成)
(过马路示意-图片来源于AI生成)
我们通过一个“过马路”的例子来解释这四种能力:
- “感知”:用眼睛看到红绿灯变化,用耳朵听到汽车鸣笛。
- “思考”:看到红灯,分析得出应该停下的结论。
- “决策”:在“闯红灯”和“等待”之间,选择后者以确保安全。
- “执行”:绿灯亮起时,迈步走过人行道。
人类以上的“感知、思考、决策、执行”构成了“智能”能力。但如果要让机器具备这些“智能”能力,首要难点是机器不懂我们的自然语言。这时,另一个学科便可以很好地结合进来:自然语言处理(Natural Language Processing 缩写为 NLP)。
2、自然语言处理(NLP)
其实“自然语言处理(NLP)”并非AI出现后才诞生。1950年,图灵就提出“如果一台机器能通过文本对话让人类无法分辨它是人还是机器,那它就具有了智能”,这其实是NLP的早期目标。AI诞生后,NLP成为其早期发展最重要的相辅相成的模块。
那么什么是“自然语言处理(NLP)”?
- “自然语言”:人类在日常生活中自然而然发展和使用的语言(如汉语、英语),不包括编程语言。
- “自然语言处理(NLP)”:让计算机能够理解、解释、操纵和生成人类自然语言,即教计算机“听懂人话、说人话、看懂人写的字、写出人能看懂的内容”。
3、AI 初生期案例分析
在自然语言处理(NLP)的加持下,AI 初步在一些场景取得了应用,比如早期的机器翻译:
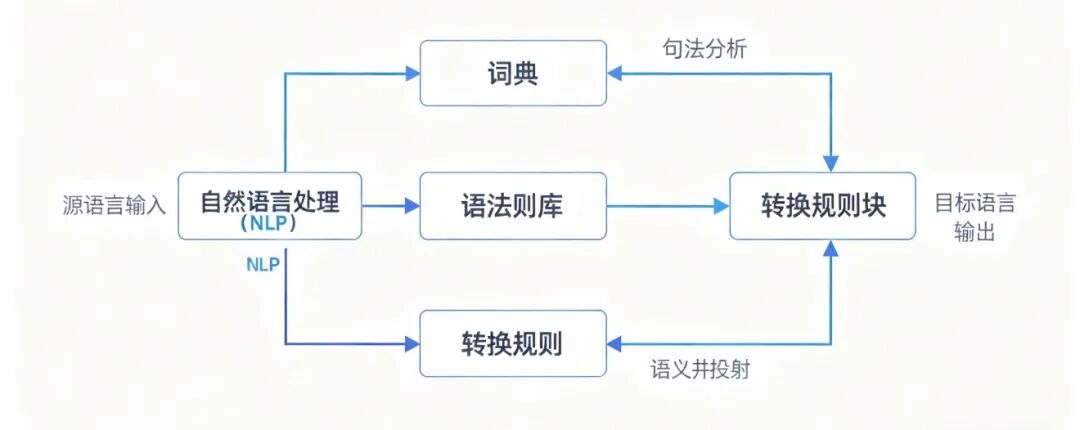 (早期机器翻译原理示意-图片来源于AI生成)
(早期机器翻译原理示意-图片来源于AI生成)
在早期机器翻译中,有词典、语法规则库、转换规则等等预先设定好的规则库,这些规则库决定了翻译功能的具体实现。
下面以翻译“The apple is red.”为例说明其原理与局限:
- 第一步:查词典。得到中文词:【这】【苹果】【是】【红色的】。
- 第二步:调整顺序。应用语法规则,将英文的
[主词] + [is] + [形容词] 对应为中文的 [主词] + [是] + [形容词] + 的,得到结果:这苹果是红色的。
问题暴露:虽然语法正确,但表达不够地道。在日常口语中,我们更常说“这个苹果是红的”或“苹果很红”。机器无法理解这种语言习惯和微妙差别。
这个简单例子揭示的根本缺陷:
- 缺乏灵活性:机器只会死板地应用规则,无法根据语境灵活调整。
- 没有“语感”:不知道什么样的表达听起来更地道自然。
4、AI 初生期小结
通过机器翻译的例子,我们会发现在AI 初生期(1956-1989),虽然有自然语言处理(NLP)的加持,但 AI 基本都是死板地按人类制定的规则去执行,不够灵活。
如果把 AI 比作一个人类,这一阶段的他,最多算是一个只会死记硬背的小学生,不懂变通。一旦遇到规则以外的内容,就无能为力。我们暂且把这一阶段的 AI 称作“规则式 AI”。
而这正是推动 AI 进一步发展的原因。
03 今生:AI 成长期(1990-2016)
在 AI 初生期,AI 基本依赖既定规则,这也催生了AI成长期的演进。
1、机器学习出现
这一阶段,一个很重要的概念出现:机器学习(Machine Learning 缩写为 ML)。
机器学习的定义是:让机器从数据中自己学习规律,而不是仅仅依靠人类为它编写固定的指令。
相比之前的“规则式 AI”,机器学习的方式会让机器通过分析大量数据,自行发现规律,然后再去应用,显得不再那么死板。
2、AI 成长期案例分析
我们以垃圾邮件过滤系统为例来说明:
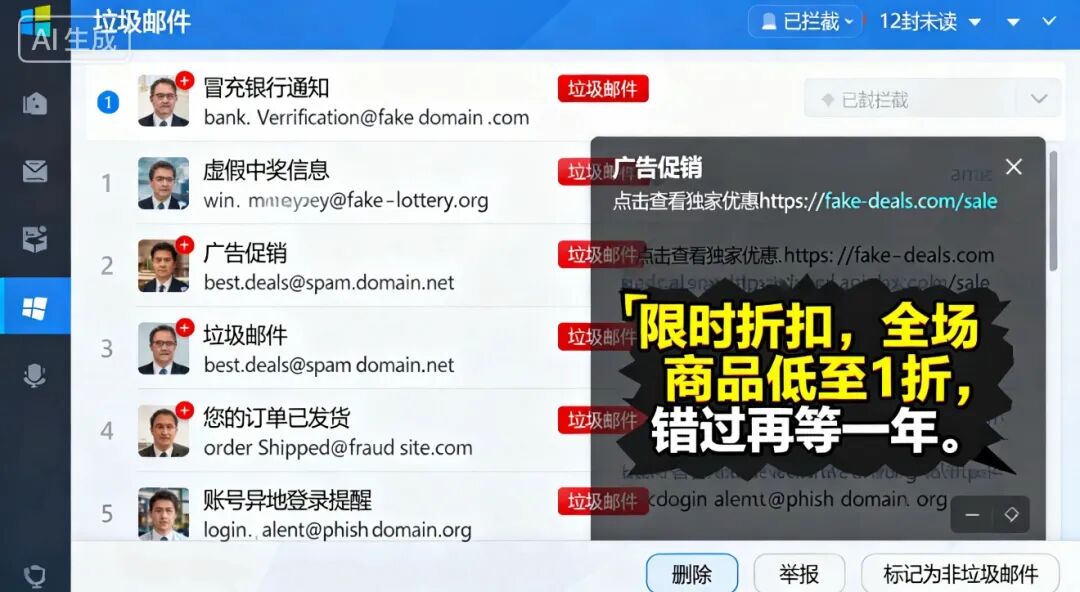 (垃圾邮件示意-图片来源于AI生成)
(垃圾邮件示意-图片来源于AI生成)
如果在 AI 初生期,只能按照既定规则来,比如:
- 如果邮件标题里出现 “免费” 这个词,就标记为垃圾邮件。
- 如果发件人地址包含 “spam” ,就标记为垃圾邮件。
这种方法的缺点非常明显:
- 变种很难防范:比如“免-费”或“Free”会让规则失效。
- 可能会误杀:正常邮件包含“免费”一词也可能被错误过滤。
那么,在 AI 成长期,我们可以怎么做?
- 第一步:准备“学习资料”。提供已分类的邮件数据:1000封垃圾邮件(标“垃圾”),1000封正常邮件(标“正常”)。
- 第二步:让机器自己“找规律”。机器通过统计分析发现:“垃圾邮件”中“免费”、“优惠”等词出现概率高;“正常邮件”中“会议”、“项目”等词出现概率高。最终形成自己的判断标准。
- 第三步:实际运作。新邮件“关于国庆放假的通知”到达。机器分析发现“放假”、“通知”等词与“正常邮件”关联度高,且未出现垃圾邮件高频词,于是判断为正常邮件。
 (垃圾邮件技术原理-图片来源于 AI 生成)
(垃圾邮件技术原理-图片来源于 AI 生成)
通过这个案例,我们会发现有了机器学习的加持,AI 从“规则式”的死板应用,进阶为能让机器自己学习、总结规律的“模型分析”模式。
3、AI 模型出现
那么机器通过自己学习,总结出的规律,就是AI 模型(Model)!
AI 模型的定义是:一个通过大量数据训练出来的、能够识别特定模式或规律的数学函数或程序。通俗讲就是从数据中提炼出的“规律”或“经验”本身。
AI 模型的三大核心要素:
- 输入:接收新的数据(如收到一封邮件)。
- 处理:运用学到的规律进行计算或判断。
- 输出:产生结果(判断邮件是否为垃圾邮件)。
4、机器学习方法:监督学习
在上述案例中,我们给了机器2000个已分类(标注好“正常”或“垃圾”)的邮件,让机器根据标注结果去学习。这便是机器学习的方法之一——“监督学习”。
监督学习即:给机器学习的训练数据都带有明确的“标签”。当然,还有其他机器学习方法,后续会介绍。
5、AI 成长期小结
如果还是把 AI 比作一个人类,这一阶段,他可以算是一个靠刷题总结规律的中学生了:针对某一学科(领域),刷了大量带答案的题,能自己总结出规律和方法,再遇到同类题时能得心应手。
通过统计大量数据然后总结规律,我们可以把这阶段的 AI 称为“统计式 AI”。
但是,有一个很重要的问题:这位中学生可能偏科。如果没做过物理题,遇到全新的物理问题,他可能还是无法解决。
回到AI成长期,虽然AI通过机器学习变得强大了,但一旦遇到训练数据以外的领域,它就无能为力。这也是该阶段AI发展面临的核心问题,而这个问题在接下来的AI爆发期中得到了突破性解决。
04 今生:AI 爆发期(2017 年至今)
在AI成长期,我们发现AI模型存在“偏科”问题。如何解决?
1、AI 模型架构演进
我们仍以“垃圾邮件过滤系统”来回顾和延展分析模型架构的演进:
- AI 初生期:按既定规则执行,无模型概念。
- AI 成长期:通过机器学习(监督学习)训练出AI 模型(如“朴素贝叶斯模型”)。但它是“拆词专家”,不关心词序和句子整体意思,无法理解上下文。
- RNN 架构(循环神经网络):尝试逐词阅读并记忆前文,有了初步“上下文”概念。但存在“健忘症”,处理长文本时易遗忘开头信息。
- CNN 架构(卷积神经网络):每次关注相邻的几个词,擅长捕捉局部短语特征,效率高。但缺乏全局观,难以理解文本整体逻辑和核心意图。
简单总结:以上模型架构通过优化,能力逐步提升,但仍有明显缺陷:“不懂语法”、“认真但健忘”、“眼光狭隘”。
2017年,Google研究团队发表论文《Attention Is All You Need》,正式提出Transformer 架构。这成为了引爆AI爆发期最关键的技术基石。
我们看看 Transformer 架构如何工作(仍以垃圾邮件过滤为例,邮件内容:“尊敬的客户,恭喜您获得10W奖金!请点击唯一链接 http://xxx.com 领取”):
- 第一步:同时查看所有关键信息(并行处理)。一瞬间看到所有词。
- 第二步:划重点并分析(自注意力机制)。给词与词之间建立“关联线”,发现“奖金”与“链接”、“领取”关联紧密,识别出“诈骗三件套”模式。
- 第三步:全局推理,看穿意图。理解整封邮件的逻辑:用虚假好消息诱导点击可疑链接。
- 第四步:做出最终决定。有把握地判定为钓鱼诈骗邮件。
Transformer 架构通过“自注意力机制”实现了革命性突破。自注意力机制通俗理解是:模型在处理信息时,能瞬间关注所有部分,并智能判断哪些部分之间的关系更重要。
3、AI 大模型出现
有了Transformer架构,AI模型得到革命性改进。基于此,OpenAI在2018年推出生成式模型GPT-1(1.17亿参数)。这里的“参数”类似于大脑神经网络中的“神经元”。
随后快速发展:2019年GPT-2(15亿参数)、2020年GPT-3(1750亿参数)。参数规模不断扩大,正是为了解决AI模型“偏科”问题,使其具备更通用、更强大的知识储备。
基于此,大模型(Large Model, LM)由此而生!
大模型基础定义为:大规模人工智能模型。这里的“大规模”主要指参数规模巨大。通常参数规模在100亿以上可被视为大模型。
4、大模型、中模型、小模型
既然有大模型,当然也有中、小模型。它们在参数规模、能力特点和应用场景上各有侧重。对于大部分工作生活场景,大模型的应用最为广泛。
5、大语言模型
在AI初生期,AI就与“自然语言处理(NLP)”相辅相成。大模型最初的形式就是大语言模型(Large Language Model, LLM):
- Large(大):参数数量和训练数据量巨大。
- Language(语言):处理自然语言。
- Model(模型):能识别模式或规律的计算模型。
GPT-3是典型的大语言模型。2023年推出的GPT-4参数量更大,且从GPT-3的仅处理文本,演进为可处理文本和图像的多模态模型。
6、除了大语言模型还有哪些模型?
大语言模型是AI大模型最早期和核心的形式。如今大模型宇宙已远远不止于此,还包括文生图、图生视频等多种模态的模型。
7、机器学习方法:无监督学习
在AI成长期,我们通过监督学习训练模型。那么GPT等大模型是如何“预训练”出来的呢?
同样使用机器学习,但更“深度”。由于大模型参数和数据量巨大,无法人工标注所有数据。通用大模型需要学习互联网上的所有知识,让机器自己去总结规律。这种机器学习方法称为 “无监督学习”。
8、深度神经网络、深度学习与传统机器学习
由于大模型巨大的参数量和训练量,需要更复杂的网络结构。RNN、CNN、Transformer等都属于 “深度神经网络” 范畴。
基于深度神经网络对大模型进行预训练的机器学习范式,称为 “深度机器学习” 或 “深度学习”。而AI成长期的机器学习范式则称为 “传统机器学习”。
9、以 ChatGPT、SD 等案例分析
大模型不断完善,但直到2023年ChatGPT正式问世,普通用户才在应用层真切感受到大模型的强大。
 (ChatGPT 聊天界面-图片来源于 AI 生成)
(ChatGPT 聊天界面-图片来源于 AI 生成)
几乎同一时期,Stable Diffusion(SD) 面世。SD是一个文生图大模型,可以根据输入的文本生成图像。
 (Stable Diffusion 界面-图片来源于 AI 生成)
(Stable Diffusion 界面-图片来源于 AI 生成)
向SD、Midjourney等文生图模型输入的文本就是提示词(Prompt)。例如:
- Prompt:一只猫在吃饼干

- Prompt:写实风格,在一个阳光明媚的早晨,一只金渐层猫在草地上,用爪子拿着一块饼干往嘴里吃

10、提示词工程
提示词工程是一门与AI有效沟通的艺术。核心原则是:你给AI的提示词越清晰、越具体,得到的结果就越好。
但仅靠文本提示词,很难生成与特定对象(如自家宠物)完全一致的图片。这时,可以结合图片输入。例如,输入宠物照片和文本提示词,生成更符合预期的图片。这引出了多模态的概念。
11、多模态、单模态
多模态(Multimodal) 指AI模型在输入或输出端能同时处理、理解和关联多种不同类型信息(如文本、图像、视频、音频)。
单模态(Unimodal) 则指在输入和输出端分别专注于一种类型的信息处理(如仅文本)。GPT-3、GPT-4(指纯文本版本)等是单模态大模型。
12、开源、闭源
大模型还有“开源”与“闭源”之分,如SD是开源,Midjourney是闭源。两者在透明度、可控性、成本、社区支持和技术门槛上各有优劣,共同推动了AI领域发展。选择时需根据自身需求、技术能力和资源决定。
13、智能体的出现
无论是单模态对话还是多模态生图,都属于AI大模型在应用层的使用。但用户仍需不断发出指令来驱动整个过程。是否存在一种AI,你只需要告诉它一个目标,它就能自主规划、执行,直到交付结果?
这就是 “智能体(Agent)” 。其核心定义是:能够感知环境、进行决策,并自主采取行动以实现某种目标的系统或程序。
智能体的关键因素是:“感知”、“决策”、“目标”、“自主行动”。其中,“自主行动” 指“扔给它一个目标,它自己能变出一套计划、搞定过程、应对变化,最终给你结果”的能力。
那么,“大模型”和“智能体”是什么关系?
- 大模型像是无所不知、超级博学的大脑。
- 智能体则是拥有这个大脑,并具备了手和脚,能主动完成复杂任务的“全能机器人”。
简要总结:
- 大模型是智能体的“能力基础”:没有大模型,智能体就不会理解和思考。
- 智能体是大模型的“落地延伸”:让大模型的能力从“说”变成“做”。
- 两者“分工协作”:大模型负责“想清楚”,智能体负责“做到位”。
14、如何开发一个智能体应用?
开发一个智能体应用,大致流程如下:
- 需求确认及策划:明确要解决的问题或提升的体验。
- 技术选型及架构设计:选择大模型、智能体平台/框架、工具链。
- 核心开发。
- 智能体调优及测试:关键环节,决定AI效果。
- 项目上线运营与迭代。
在智能体调优中,除了提示词工程,还会涉及两个重要概念:“RAG”和“微调”。
15、检索增强生成(RAG)
检索增强生成(Retrieval-Augmented Generation, RAG):
- 检索:从外部知识库查找相关信息。
- 增强:用检索到的信息“补充”大模型的知识。
- 生成:大模型基于补充信息生成更准确可靠的答案。
通俗解释:让智能体的大脑(大模型)在输出前,先主动去知识库“查阅资料”,然后根据资料生成答案。
- 没有RAG:像闭卷考试,只能依靠记忆(预训练知识)答题,易出错或“胡编乱造”。
- 有了RAG:像开卷考试,遇到问题先查阅资料,再结合理解写出有据可查的答案。
16、微调:基于监督学习和强化学习
提示词工程、RAG主要优化输入阶段。要更好地优化输出,还需 “微调” 。微调本质上改变了AI模型本身(对开源模型是修改副本,对闭源模型是调整“适配层”)。
微调常用方法包括:
- 监督微调(SFT):使用高质量的“问题-答案”对,以监督学习的方式进一步训练模型,使其输出更符合特定格式或风格。
- 基于人类反馈的强化学习(RLHF):让模型通过试错,学习最大化长期奖励的“决策链”。例如,通过人工对模型输出进行评分(奖励模型),让AI学习生成高分答案,从而优化输出效果。
17、大模型的幻觉问题
在项目过程中,AI有时会输出看似合理实则错误的信息,这就是大模型的 “幻觉”问题:大模型生成事实上错误、荒谬或虚构信息的行为。
RAG、提示词工程、微调等方法的一个重要目标就是管理和减少幻觉,但无法完全消除。还可采用答案溯源、自我批判、固定高准确性信源等策略。对于AI的输出,我们应始终保持审慎态度。
18、AI 爆发期小结
AI爆发期,大模型百花齐放,智能体应用层出不穷。这阶段的AI,如同一个读遍天下书并拥有实习经验的大学生,下一阶段将走向更广阔的未来。我们可以把这阶段的AI称为 “深度学习/大模型 AI”。
05 未来
AI从历史长河看已有几十年,但真正爆发就在近几年,背后是数据、算力、算法三大支柱的成熟:
- 数据:生活、工作全面数字化积累的海量数据。
- 算力:云计算、GPU等提供的强大支撑。
- 算法:以Transformer为代表的深度学习架构。
在此支撑下,AI从自然语言处理扩展到多模态物理世界,应用形态从内容生成(AIGC)到辅助办公,再到各垂直行业的初步探索。AI从“规则式”演进到“统计式”,再到今天的“深度学习/大模型 AI”。
如果把AI比作人类,他已从小学生成长为大学生。未来,AI将深入各行各业,成为我们重要的“伙伴”,而不仅仅是工具。这要求我们更深入地思考:为什么要用AI?AI能做什么?用了会改变什么?如果不用会怎样?
 发表于 2025-12-7 22:34:00
|
查看: 179|
回复: 0
发表于 2025-12-7 22:34:00
|
查看: 179|
回复: 0
