在时间序列预测的实战中,当你面对一堆历史数据,选择模型时往往会陷入纠结:是用老当益壮的XGBoost(极致梯度提升树),还是选择在序列问题上名声赫赫的LSTM(长短期记忆网络)?
很多同学在从传统机器学习转向深度学习时,遇到的第一个拦路虎就是:为什么同样的数据,丢给XGBoost能跑得飞快,喂给LSTM却频频报错?
问题的核心,往往不在于模型本身,而在于你给它们的数据“形态”错了。今天,我们就来彻底讲清楚,在时序预测中,XGBoost和LSTM的输入数据究竟有何天壤之别。
一、 维度之争:2D 表格 vs 3D 张量
这是两者最根本、最直观的区别,理解了维度,就解开了大半疑惑。
1. XGBoost:平铺直叙的二维表格
XGBoost本质上是基于树的集成模型,它接收的是标准的 二维矩阵(Tabular Data) ,形状为:
[样本量 (Samples), 特征数 (Features)]
- 每一行:代表一个独立的观测样本(例如,某个时间点的数据快照)。
- 每一列:代表一个特征(例如,历史价格、温度、星期几的One-hot编码等)。
- 核心逻辑:模型默认每一行数据是独立同分布的。它并不知道第N行和第N+1行在时间上谁先谁后。为了让模型感知时间,我们必须通过特征工程,手动把“过去”的信息变成新的列(特征)塞进去。
2. LSTM:立体嵌套的三维张量
LSTM是为序列数据量身定制的,它要求输入必须是 三维张量(3D Tensor) ,形状为:
[样本量 (Samples), 时间步 (Time Steps), 特征数 (Features)]
- 时间步 (Time Steps):这是LSTM的灵魂参数。它定义了模型在做出一次预测时,需要回顾过去多少个连续的时间点。
- 核心逻辑:LSTM拥有内部状态(记忆细胞),能够学习并记住跨越多个时间步的依赖关系。它不把时间点当作独立行,而是视作一个连续的序列块。
数据结构对比示意图:
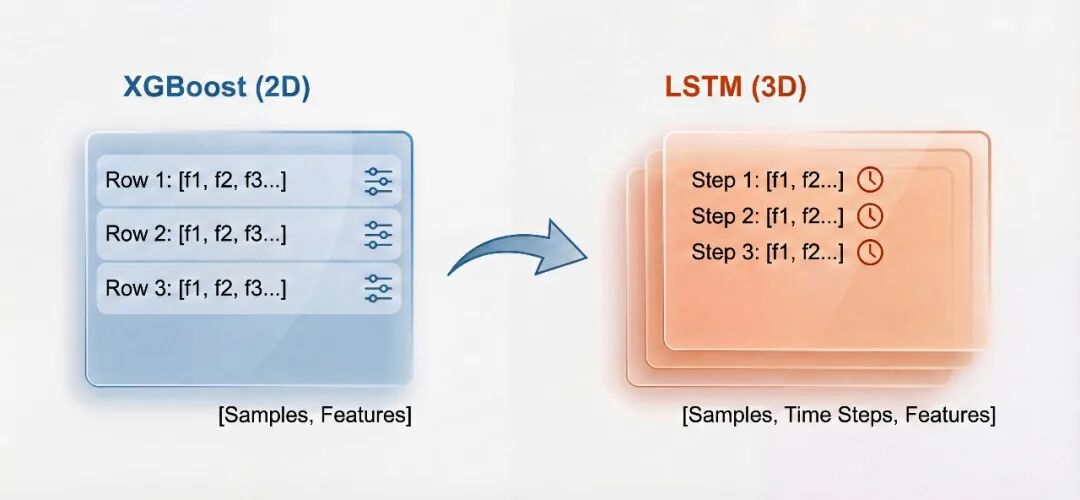
上图清晰地展示了差异:XGBoost处理的是一个“平面”表格,而LSTM处理的是一个有“深度”(时间步)的数据块。
二、 特征工程:手动构建 vs. 滑窗自动
数据维度的不同,直接导致了特征工程策略的迥异。
1. XGBoost:靠“人脑”把时间变成特征
既然XGBoost“看不见”时间顺序,我们就得当它的“眼睛”,显式地把时序信息编码成静态特征。这是建模中最耗时但也最关键的一环,常用技巧包括:
- 滞后特征 (Lag Features):把t-1, t-7, t-30时刻的值作为新特征列。
- 滚动统计量 (Rolling Statistics):计算过去一个窗口期的均值、标准差、最大值等作为新特征。
- 时间属性编码:提取“小时”、“星期几”、“是否节假日”等类别特征并进行编码。
- 平稳化处理:手动进行差分、对数变换等,以消除趋势和季节性。
关键点:所有时序模式的理解和转换,都依赖于数据科学家的先验知识和手动操作。
2. LSTM:靠“滑窗”保留原始序列
LSTM的设计让它对繁重的手工特征工程依赖度较低。
- 滑动窗口 (Sliding Window):你只需要定义一个窗口大小(即时间步数)。模型会接收一个窗口内的原始(或归一化后)序列,并自动学习这些连续点之间的演变模式和依赖关系。
- 内在机制:其门控结构(遗忘门、输入门、输出门)能够自主决定记住哪些历史信息、忘记哪些信息,从而捕捉长期依赖。
从这个角度看,LSTM将一部分特征工程的工作“内化”到了模型结构之中。关于更复杂的特征工程策略,可以在 云栈社区 的算法板块找到更多深入的讨论和实战案例。
三、 数据缩放:不在乎 vs. 极度敏感
这是实战中极易踩坑的一点,直接关系到模型能否正常训练。
-
XGBoost (树模型):对数值缩放不敏感。
- 树模型的分裂依据是特征值的排序(Order),而非绝对值大小。特征值是0.01还是10000,不影响其分裂点的选择。
- 因此,通常不需要进行归一化或标准化。但有时为了加速收敛,对特征进行缩放可能仍有微弱好处。
-
LSTM (神经网络):对数值缩放极度敏感。
- LSTM内部使用
tanh 或 sigmoid 等激活函数。如果输入特征的尺度差异巨大或绝对值过大,会导致梯度消失或爆炸,模型根本无法有效学习。
- 强制要求:输入数据必须被缩放到一个较小的固定区间,如
[0, 1](MinMaxScaler)或均值为0、方差为1(StandardScaler)。
四、 平稳性要求:能否外推“趋势”
时间序列的平稳性(均值和方差不随时间变化)是许多模型的基础假设。
五、 总结与选型指南
为了方便快速对比和决策,我们将核心差异总结如下:
| 特性 |
XGBoost |
LSTM |
| 数据形状 |
2D [Samples, Features] |
3D [Samples, Timesteps, Features] |
| 特征工程 |
重度依赖(需手动构建滞后、统计等特征) |
低度依赖(主要靠定义滑动窗口) |
| 数据缩放 |
不需要 |
必须归一化/标准化 |
| 计算资源 |
较低,CPU即可快速训练 |
较高,长序列/复杂网络需要GPU加速 |
| 平稳性 |
要求高,常需差分处理 |
要求相对灵活,但平稳化有益 |
| 核心优势 |
表格数据、混合特征、可解释性、训练预测速度快 |
纯序列数据、自动捕捉长程依赖、端到端学习 |
性能对比雷达图:
一句话总结:XGBoost 把时间 “空间化” (变成一列列特征),而 LSTM 把时间 “序列化” (变成一个连续的数据块)。
实战选型建议:
-
优先考虑 XGBoost 的场景:
- 你拥有丰富的特征(不仅是历史值,还有外部变量如天气、营销活动、事件标识等)。
- 数据量中等,且需要模型具备较好的可解释性(特征重要性)。
- 追求快速迭代和部署,计算资源有限。
-
优先考虑 LSTM 的场景:
- 处理单一或少数几个变量的纯时间序列(如股票价格、传感器读数、音频波形)。
- 序列中存在复杂的长期依赖关系,且数据量充足。
- 愿意投入更多计算资源(GPU)进行训练,并希望减少手工特征工程的工作量。
在当今的 人工智能 应用浪潮中,理解不同模型的数据需求是构建高效预测系统的第一步。无论是选择传统的树模型还是现代的深度网络,正确的数据准备都是成功的一半。希望这篇对比能帮助你厘清思路,在实际项目中做出更合适的技术选型。

欢迎在 云栈社区 的 开源实战 板块分享你的时序预测项目经验,或者探讨更多模型细节! |  发表于 2026-3-5 14:48:46
|
查看: 259|
回复: 0
发表于 2026-3-5 14:48:46
|
查看: 259|
回复: 0
