在AI应用开发面试中,RAG(检索增强生成)是一个高频考点。面试官往往会从场景痛点出发,考察候选人对这一技术本质的理解。那么,RAG到底是什么,它又是如何工作的呢?
简要回答
RAG本质上是为了解决大模型“知识时效性差”和“容易产生幻觉”这两个核心痛点而提出的技术方案。
它的核心思路是不让模型完全依赖训练时学到的参数化知识,而是在回答问题之前,先去外部知识库里检索相关的文档片段,然后把检索到的实时内容作为上下文提供给模型,让模型基于这些真实资料来生成答案。
这样一来,模型既能回答最新的信息,又能大幅降低胡编乱造的概率。这个方案特别适合企业内部知识问答、文档分析这类对准确性要求很高的场景,是目前大模型在企业级人工智能应用落地中最成熟、最实用的技术路线之一。
详细回答
要理解RAG,首先得明白它为什么会出现。我们都清楚大模型能力虽强,但其知识其实是“冻结”在训练那个时间点的。例如,GPT-4的训练数据有截止日期,它无法获知之后发生的事件。
更棘手的是,模型有时会非常自信地给出一些看似合理但完全错误的答案,这就是所谓的“幻觉问题”。对于企业应用而言,这两点几乎是致命的。客户或员工询问的往往是实时的产品信息、内部的业务流程或政策,如果模型信口开河,后果不堪设想。
RAG就是为应对这些挑战而生的。它的全称是 Retrieval-Augmented Generation,直译为“检索增强生成”。其核心逻辑非常直观:在模型生成答案之前,先让它去“查资料”。
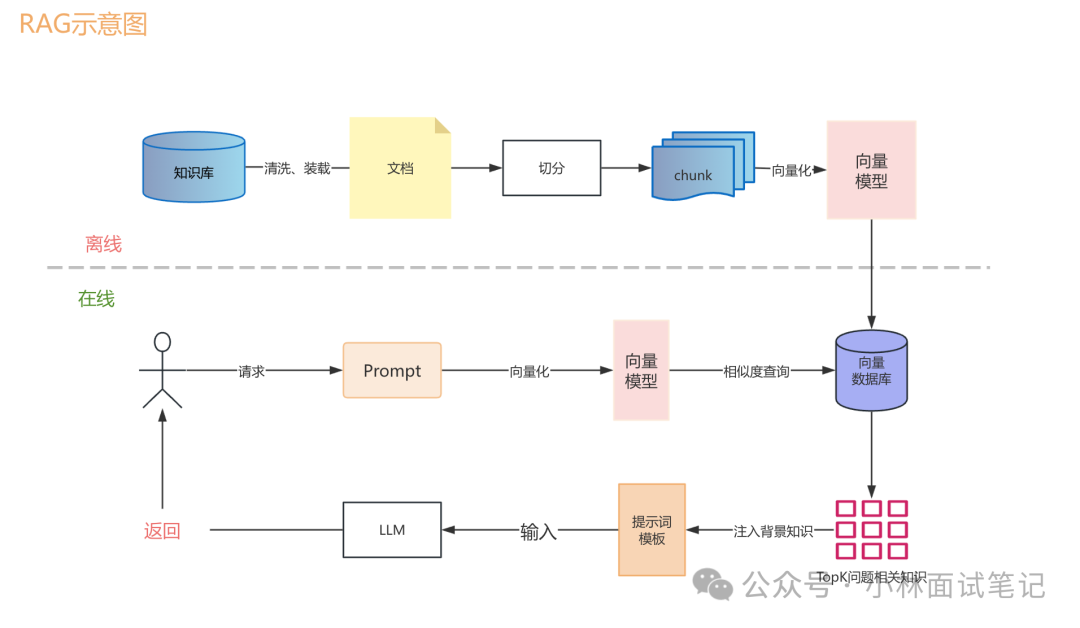
具体的工作流程可以分解为以下几个步骤:
- 用户提问:用户提出一个问题,例如“公司今年第三季度的销售额是多少?”
- 查询向量化:系统将这个问题通过Embedding模型转换成向量表示。
- 相似度检索:用问题向量去事先构建好的向量数据库中进行相似度搜索,找出最相关的若干段文档内容(chunks)。
- 构建提示(Prompt):将检索到的文档片段与用户的原始问题拼接成一个结构化的完整Prompt。
- 生成答案:将这个包含背景知识的Prompt喂给大模型(LLM),模型基于提供的真实参考资料生成最终回答。
我们可以通过一个实际项目例子来加深理解。假设要开发一个企业内部的智能客服系统,后台有海量的产品文档、FAQ和操作手册。第一步是文档预处理,也称为“离线索引构建”:
- 将原始资料切分成大小合适的片段。
- 使用Embedding模型将每个片段转换成向量。
- 将所有向量存储到专用的向量数据库中。
这个过程用代码实现,大致如下所示:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import Chroma
from langchain.text_splitter import RecursiveCharacterTextSplitter
# 文档切片
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=512,
chunk_overlap=50
)
chunks = text_splitter.split_documents(documents)
# 向量化并存储
embeddings = OpenAIEmbeddings()
vectorstore = Chroma.from_documents(
documents=chunks,
embedding=embeddings
)
离线索引构建好后,当用户真正提问时,线上流程便启动了:
# 用户提问
query = "如何重置账户密码?"
# 检索相关文档
relevant_docs = vectorstore.similarity_search(query, k=3)
# 构建完整的Prompt
context = "\n".join([doc.page_content for doc in relevant_docs])
prompt = f"根据以下参考资料回答问题:\n{context}\n\n问题:{query}"
# 调用大模型生成答案
response = llm.generate(prompt)
这里有一个关键点:为什么使用向量检索而不是传统的关键词搜索?因为向量检索能够理解语义。比如用户问“怎么改密码”,而文档中写的是“密码重置流程”,二者字面并不完全匹配,但在向量空间里它们的语义非常接近,因此能够被准确召回。这正是Embedding模型的价值所在。
当然,RAG并非银弹,它在实际应用中也面临一些挑战:
- 召回质量问题:如果检索出来的文档不相关或遗漏了关键信息,那么后续模型再强大也无能为力。这非常依赖索引构建的质量和检索算法的精度。
- 上下文长度限制:检索回来的文档如果太多、太长,可能会超出大模型的上下文窗口(Token限制)。这时就需要引入Rerank(重排序)模型进行精筛,或对文档进行进一步摘要和压缩。
- 性能与成本平衡:每次问答都要执行一次向量检索,对向量数据库的响应速度和并发能力有较高要求,同时也需要考虑由此产生的计算成本。
从实践经验来看,RAG特别适合知识密集型、对准确性要求高、且知识需要频繁更新的场景。例如法律咨询助手、企业内部知识库问答、医疗文献检索与分析等项目,RAG都展现出了显著优势。
它巧妙地结合了大模型强大的语言理解与生成能力,又通过外挂知识库的方式弥补了其在知识时效性与事实准确性上的短板。对于希望深入智能 & 数据 & 云应用领域,特别是处理技术文档和知识管理的开发者而言,掌握RAG是至关重要的。如果你想了解更多实战经验和行业讨论,欢迎来到云栈社区交流分享。
 发表于 2026-3-7 08:32:16
|
查看: 233|
回复: 0
发表于 2026-3-7 08:32:16
|
查看: 233|
回复: 0
