深度学习编译器通过代数变换优化模型执行,符号计算则为这些变换提供了坚实的数学保障。本文将以 Python 生态中的强大符号计算库 SymPy 为例,带你一步步进行形式化推导。我们会先介绍 IndexedBase、Eq、subs 等核心工具,并通过矩阵乘法演示其基本用法和表达式树替换原理。随后,将重点展开卷积操作的 im2col 变换符号推导,详细展示如何用符号等式描述 im2col、卷积核 reshape、矩阵乘法及输出 reshape,并通过逐步代入消去中间变量,最终得到标准卷积定义。文章还会探讨这些技术如何在 深度学习编译器 中用于算子融合、模式匹配和维度推导,为编译器优化提供形式化基础。
1. 引言
深度学习编译器(如 TVM、XLA、Glow)的核心任务,是将高层模型描述(如 TensorFlow、PyTorch 的计算图)转换为针对特定硬件的优化代码。这一过程充满了代数变换:算子融合、常量折叠、内存布局优化等。这些变换的正确性至关重要,因为任何细微的错误都可能导致模型精度下降甚至完全错误。符号计算提供了一种形式化方法,可以精确地描述和推导这些变换,确保优化后的代码与原始模型在数学上严格等价。
为什么需要这种形式化方法呢?因为人脑推理容易出错,尤其是面对复杂的多维张量运算和嵌套循环时。SymPy 作为强大的符号计算库,提供了表示数学表达式、定义等式、执行替换和化简的工具。接下来,我们将从基础开始,通过一个简单的矩阵乘法例子建立直觉,然后攻克深度学习中最重要的算子优化之一——卷积的 im2col 变换符号推导。
2. SymPy符号计算基础
2.1 IndexedBase:带索引的符号
在符号计算中,我们经常需要表示带有下标的变量,如矩阵元素 $A_{ij}$ 或张量元素 $X_{i,j,k}$。SymPy 提供了 IndexedBase 类来创建这种带索引的符号基对象,再通过索引操作生成 Indexed 对象。例如:
from sympy import IndexedBase, symbols
A = IndexedBase(‘A’)
i, j = symbols(‘i j’)
A[i, j] # 表示 A_{ij}
IndexedBase 本身是一个符号,可以带有形状信息(可选),而 Indexed 是它的索引实例。这种表示非常适合于张量运算的符号推导,因为索引可以直观地对应到多维数组的坐标。
2.2 Eq:定义数学等式
Eq 类用于表示等式 $LHS = RHS$。它不是赋值语句,而是一个符号对象,可以被存储、代入或用于求解。例如:
from sympy import Eq
eq = Eq(A[i, j], B[i, j] + C[i, j])
在深度学习编译器中,我们常用 Eq 来定义中间变量的计算规则,如 $C_{ij} = \sum_k A_{ik} B_{kj}$(矩阵乘法)。每个 Eq 实例都包含左端 (lhs) 和右端 (rhs) 两个属性,可以分别访问。
2.3 subs:表达式替换
subs 是 SymPy 表达式的一个方法,用于执行符号替换。其基本语法为 expr.subs(old, new),它会遍历表达式树,将所有匹配 old 的子表达式替换为 new,并返回新表达式。subs 是符号推导的核心,因为它允许我们逐步代入定义,消去中间变量,最终得到仅含输入和输出的表达式。
subs 也支持多组替换的字典形式:expr.subs({old1: new1, old2: new2})。替换时还可以使用符号匹配的通配符,但基本用法已足够强大。
2.4 表达式树
SymPy 将所有表达式存储为树形结构,每个节点对应一个操作(如加法、乘法、求和)或原子(如符号、整数)。通过 srepr(expr) 可以查看表达式的精确内部表示。例如,$A_{ij} + B_{ij}$ 的 srepr 可能类似于:
Add(Indexed(IndexedBase(Symbol('A')), Symbol('i'), Symbol('j')),
Indexed(IndexedBase(Symbol('B')), Symbol('i'), Symbol('j')))
理解表达式树对于调试和高级操作(如自定义模式匹配)非常重要。subs 正是通过递归遍历这棵树来定位匹配的子树并进行替换。
3. 从矩阵乘法开始
为了建立直觉,我们先从一个简单的矩阵乘法链开始。这个例子将展示如何定义符号矩阵乘法,如何用 Eq 记录中间结果,以及如何用 subs 合并表达式。
3.1 构建矩阵乘法表达式
假设我们有两个矩阵乘法:$C = A B$ 和 $E = C D$,其中 $A, B, C, D$ 均为矩阵,维度适当。我们定义维度符号 $n$ 和索引 $i, j, k, l$:
from sympy import symbols, IndexedBase, Sum, Eq
n = symbols(‘n’, integer=True, positive=True)
i, j, k, l = symbols(‘i j k l’, integer=True, positive=True)
A = IndexedBase(‘A’)
B = IndexedBase(‘B’)
C = IndexedBase(‘C’)
D = IndexedBase(‘D’)
E = IndexedBase(‘E’)
# C = A B
C_expr = Sum(A[i, k] * B[k, j], (k, 1, n))
eq1 = Eq(C[i, j], C_expr)
# E = C D
E_expr = Sum(C[i, j] * D[j, l], (j, 1, n))
eq2 = Eq(E[i, l], E_expr)
数学形式:
$C_{ij} = \sum_{k=1}^{n} A_{ik} B_{kj}$
$E_{il} = \sum_{j=1}^{n} C_{ij} D_{jl}$
3.2 合并表达式:C=AB与E=CD
我们希望消去中间变量 $C_{ij}$,得到 $E_{il}$ 直接用 $A, B, D$ 表示的表达式。使用 subs 将 $C_{ij}$ 替换为它的定义:
E_combined = eq2.rhs.subs(C[i, j], eq1.rhs)
结果:
$E_{il} = \sum_{j=1}^{n} \left( \sum_{k=1}^{n} A_{ik} B_{kj} \right) D_{jl}$
这正是矩阵乘法的结合律 $(AB)D$ 的体现。我们还可以进一步将其写成三重求和:
$E_{il} = \sum_{j=1}^{n} \sum_{k=1}^{n} A_{ik} B_{kj} D_{jl}$
3.3 subs替换的逐步可视化
subs 的工作原理可以通过表达式树来理解。考虑 eq2.rhs 的树结构,它对应于 $\sum_j C_{ij} D_{jl}$。
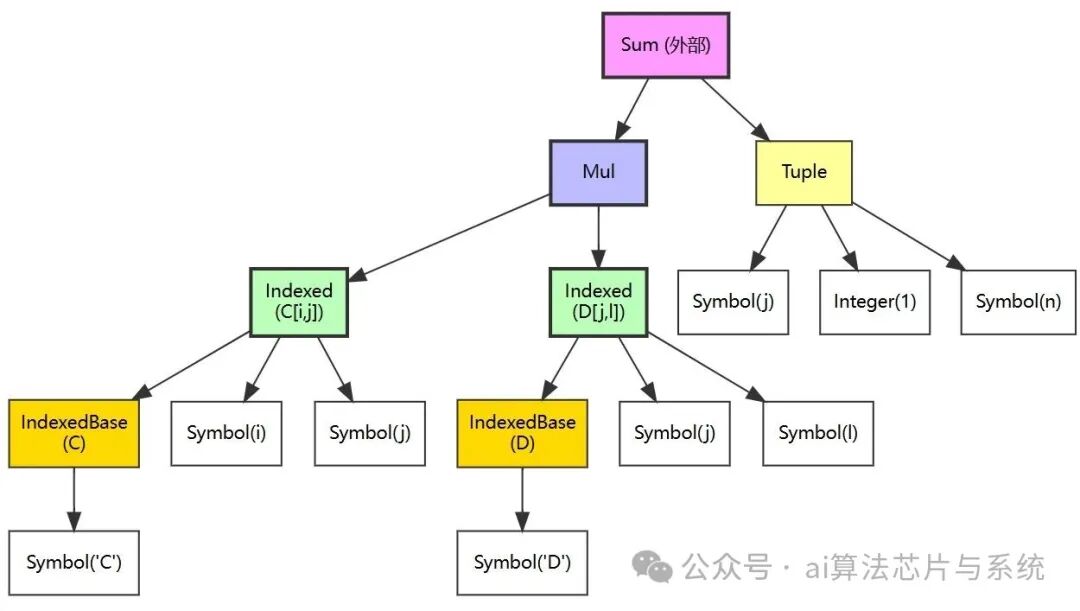
待替换的模式是 $C_{ij}$,对应图中的 C_idx 子树。替换对象 eq1.rhs 的树结构为 $\sum_k A_{ik} B_{kj}$:
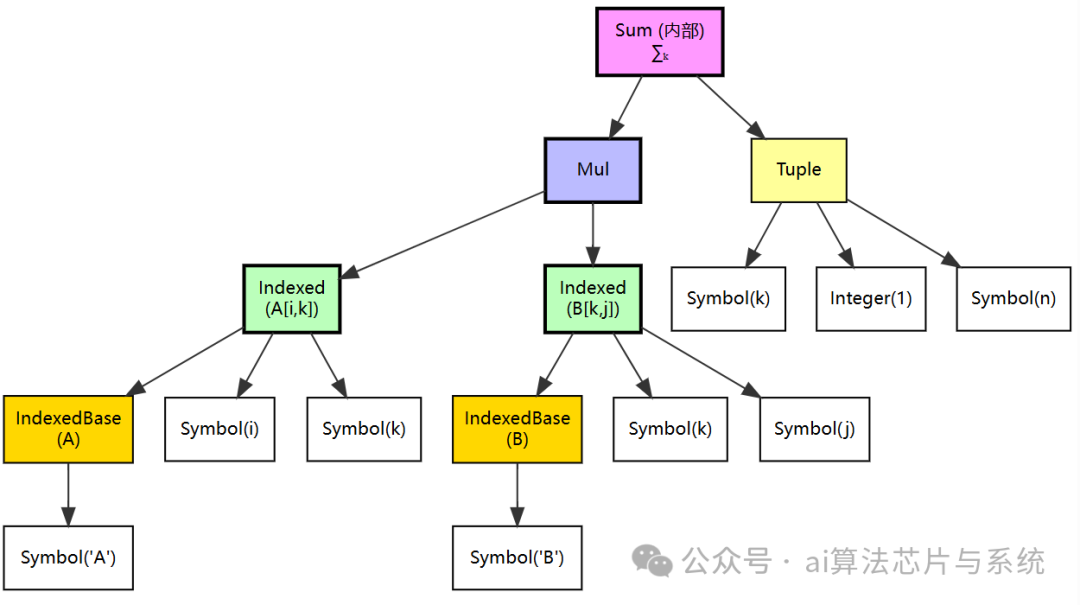
subs 遍历原始树,当访问到 C_idx 节点时,发现匹配,将其替换为整个内部 Sum 子树,得到新树(图中省略部分重复节点):
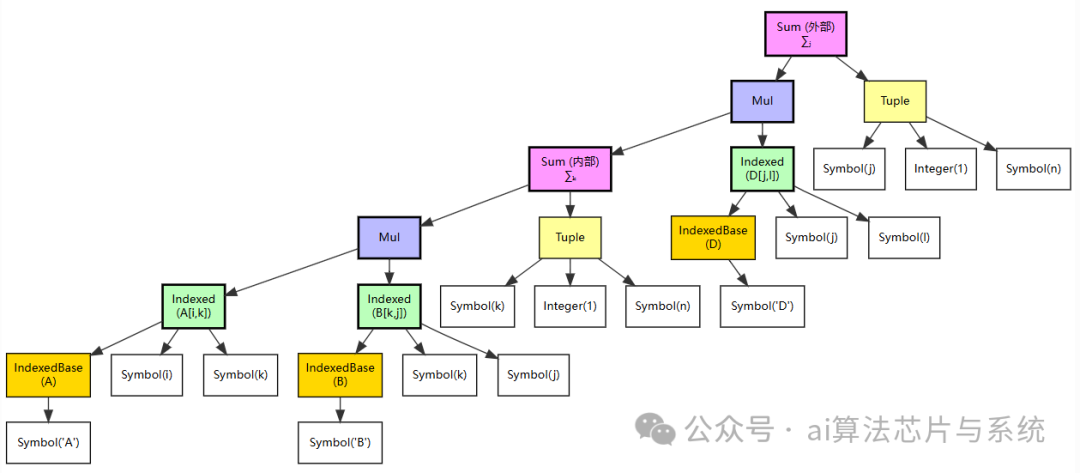
通过树形图,可以直观看到替换如何改变表达式结构。
3.4 表达式树详解
在 SymPy 中,Indexed 节点并非叶子,它的子节点包括 IndexedBase 和索引符号,而 IndexedBase 下还有 Symbol 表示名称。这种精细的树结构使得 subs 能够精确匹配特定基对象和索引。
4. 卷积的im2col符号推导
现在我们将目光转向深度学习中最重要的算子——卷积。卷积的标准定义(无填充、步长为1)为:
$Y[k_{out}, p, q] = \sum_{i=0}^{C-1} \sum_{j=0}^{K_h-1} \sum_{k=0}^{K_w-1} X[i, p+j, q+k] \cdot W[k_{out}, i, j, k]$
其中 $X$ 形状 $(C, H, W)$,$W$ 形状 $(K, C, K_h, K_w)$,$Y$ 形状 $(K, H_{out}, W_{out})$,且 $H_{out} = H - K_h + 1$, $W_{out} = W - K_w + 1$。
在许多高性能实现中,卷积被转化为矩阵乘法,即 im2col + GEMM。本部分将用 SymPy 符号化描述这一变换,并通过代入验证其等价性。
4.1 问题描述与符号定义
首先定义所需的维度符号和索引符号:
from sympy import symbols, Eq, IndexedBase, Sum
# 维度符号
C, H, W, K, Kh, Kw, H_out, W_out = symbols(‘C H W K Kh Kw H_out W_out’, integer=True, positive=True)
# 索引符号
i, j, k = symbols(‘i j k’, integer=True) # 通道内偏移:i(通道), j(行), k(列)
p, q = symbols(‘p q’, integer=True) # 输出空间位置:p(行), q(列)
k_out = symbols(‘k_out’, integer=True) # 输出通道
# 矩阵乘法通用索引
m, n, k_mat = symbols(‘m n k_mat’, integer=True)
# IndexedBase 对象
X = IndexedBase(‘X’) # 输入张量 X[i, h, w]
W = IndexedBase(‘W’) # 卷积核 W[k_out, i, j, k]
Y = IndexedBase(‘Y’) # 输出张量 Y[k_out, p, q]
X_col = IndexedBase(‘X_col’) # im2col 矩阵,形状 (C*Kh*Kw, H_out*W_out)
W_col = IndexedBase(‘W_col’) # reshape 核矩阵,形状 (K, C*Kh*Kw)
Y_col = IndexedBase(‘Y_col’) # GEMM 结果矩阵,形状 (K, H_out*W_out)
注意:维度符号中的 W(输入宽度)与卷积核基对象 W 同名,但它们是不同的 Python 变量,在表达式中 SymPy 通过符号名称区分,不会混淆。
4.2 四个基本变换的符号等式
4.2.1 im2col:将输入窗口展平为矩阵列
im2col 将输入张量中每个与卷积核重叠的窗口展平为一列。对于输出位置 $(p, q)$,窗口左上角在 $(p, q)$,窗口内的元素索引为 $(i, p+j, q+k)$,其中 $i$ 为输入通道,$(j, k)$ 为空间偏移。该窗口被展平后存储在矩阵 $X_{col}$ 的列索引 $n = p \cdot W_{out} + q$ 中,行索引由 $i \cdot (K_h K_w) + j \cdot K_w + k$ 给出。于是有:
eq1 = Eq(
X_col[i*(Kh*Kw) + j*Kw + k, p*W_out + q],
X[i, p + j, q + k]
)
数学形式:
$X_{col}[i K_h K_w + j K_w + k, \; p W_{out} + q] = X[i, p+j, q+k]$
4.2.2 卷积核reshape:将四维核转为二维矩阵
将卷积核 $W$ 重塑为二维矩阵 $W_{col}$,每行对应一个输出通道 $k_{out}$,每列对应一个输入通道和空间偏移的组合 $(i, j, k)$,列索引同样为 $i K_h K_w + j K_w + k$:
eq2 = Eq(
W_col[k_out, i*(Kh*Kw) + j*Kw + k],
W[k_out, i, j, k]
)
数学形式:
$W_{col}[k_{out}, \; i K_h K_w + j K_w + k] = W[k_{out}, i, j, k]$
4.2.3 矩阵乘法:GEMM核心
矩阵乘法 $Y_{col} = W_{col} \cdot X_{col}$ 按元素定义为:
eq3 = Eq(
Y_col[m, n],
Sum(W_col[m, k_mat] * X_col[k_mat, n], (k_mat, 0, C * Kh * Kw - 1))
)
数学形式:
$Y_{col}[m, n] = \sum_{k_{mat}=0}^{C K_h K_w - 1} W_{col}[m, k_{mat}] \cdot X_{col}[k_{mat}, n]$
4.2.4 输出reshape:恢复张量形状
将矩阵乘结果 $Y_{col}$ 重塑为输出张量 $Y$,即把列索引 $n$ 映射回空间位置 $(p, q)$:
eq4 = Eq(
Y[k_out, p, q],
Y_col[k_out, p*W_out + q]
)
数学形式:
$Y[k_{out}, p, q] = Y_{col}[k_{out}, \; p W_{out} + q]$
4.3 逐步合并表达式
我们希望从上述四个等式推导出 $Y[k_{out}, p, q]$ 直接用 $X$ 和 $W$ 表示的表达式,即标准卷积定义。这需要逐步代入消去中间变量 $X_{col}$、$W_{col}$、$Y_{col}$。
4.3.1 第一步:代入 $Y_{col}$
将 eq4 右侧的 $Y_{col}[k_{out}, p W_{out} + q]$ 替换为 eq3 的右侧,同时将 eq3 中的通用索引 $m, n$ 映射为 $k_{out}, p W_{out} + q$:
expr = eq4.rhs.subs(
Y_col[k_out, p*W_out + q],
eq3.rhs.subs({m: k_out, n: p*W_out + q})
)
此时 expr 为:
$Y[k_{out}, p, q] = \sum_{k_{mat}=0}^{C K_h K_w - 1} W_{col}[k_{out}, k_{mat}] \cdot X_{col}[k_{mat}, p W_{out} + q]$
4.3.2 第二步:将单变量求和转换为三重求和
观察索引 $k_{mat}$ 的范围是 $0$ 到 $C K_h K_w - 1$,这恰好对应于 $(i, j, k)$ 的线性化索引 $i K_h K_w + j K_w + k$,其中 $i \in [0, C-1]$, $j \in [0, K_h-1]$, $k \in [0, K_w-1]$。因此我们可以将单变量求和转换为三重求和:
# 提取被加项(不含求和符号)
sum_term = expr.args[0] # 被加项
new_sum = Sum(
sum_term.subs(k_mat, i*(Kh*Kw) + j*Kw + k),
(i, 0, C-1), (j, 0, Kh-1), (k, 0, Kw-1)
)
得到:
$Y[k_{out}, p, q] = \sum_{i=0}^{C-1} \sum_{j=0}^{K_h-1} \sum_{k=0}^{K_w-1} W_{col}[k_{out}, i K_h K_w + j K_w + k] \cdot X_{col}[i K_h K_w + j K_w + k, p W_{out} + q]$
4.3.3 第三步:代入 $W_{col}$ 和 $X_{col}$
现在将 $W_{col}[k_{out}, i K_h K_w + j K_w + k]$ 替换为 eq2 的右侧,$X_{col}[i K_h K_w + j K_w + k, p W_{out} + q]$ 替换为 eq1 的右侧:
expr_final = new_sum.subs(
W_col[k_out, i*(Kh*Kw) + j*Kw + k],
W[k_out, i, j, k]
)
expr_final = expr_final.subs(
X_col[i*(Kh*Kw) + j*Kw + k, p*W_out + q],
X[i, p + j, q + k]
)
最终得到:
$Y[k_{out}, p, q] = \sum_{i=0}^{C-1} \sum_{j=0}^{K_h-1} \sum_{k=0}^{K_w-1} X[i, p+j, q+k] \cdot W[k_{out}, i, j, k]$
4.4 最终表达式与标准卷积对比
这正是标准卷积的定义。通过符号推导,我们严格验证了 im2col + GEMM 变换的数学等价性。注意,在推导过程中,我们使用了恒等式:
$\sum_{k_{mat}=0}^{N-1} f(k_{mat}) = \sum_{i=0}^{C-1} \sum_{j=0}^{K_h-1} \sum_{k=0}^{K_w-1} f(i K_h K_w + j K_w + k)$
并且假设求和范围正确。SymPy 的符号操作使得这一推导过程清晰且可重复。
4.5 表达式树在卷积推导中的应用
上述推导中的每一步 subs 都涉及复杂的表达式树替换。例如,new_sum 是一个三重求和,其内部包含 $W_{col}$ 和 $X_{col}$ 的 Indexed 节点。当我们将 $W_{col}$ 替换为 $W$ 时,SymPy 会遍历求和树中的每一项,找到匹配的 Indexed 节点并替换。同样,$X_{col}$ 的替换也是如此。最终生成的表达式树对应于标准卷积的三重求和。我们可以绘制简化后的树结构,但限于篇幅,这里只给出文字描述:根节点为三重求和,求和体为乘积节点,乘积的左子为 $X$ 的 Indexed,右子为 $W$ 的 Indexed,每个 Indexed 下面都有对应的基对象和索引符号。这个树结构完全等价于直接手写的卷积表达式。
5. 深度学习编译器中的应用
上述符号推导不仅仅是一个数学练习,它在深度学习编译器中有着广泛的实际应用。
5.1 算子融合与表达式化简
编译器经常将多个连续算子融合为单个核函数以减少内存访问和启动开销。例如,卷积 后紧跟激活函数 $\sigma$:$Z = \sigma(Y)$。通过符号表达式,我们可以将 $Z$ 表示为 $\sigma(\sum \sum \sum X \cdot W)$。如果 $\sigma$ 是逐元素函数,编译器可以生成融合后的循环,避免中间张量 $Y$ 的显式写出。符号化简还能合并常数因子、消除冗余计算,如 $0 \cdot x$ 项等。更复杂的融合如卷积+批量归一化,也可以通过符号变换推导出融合后的表达式。
5.2 模式匹配与重写规则
深度学习编译器通常包含一个基于规则的优化器,将计算图与预设模式进行匹配并替换为更高效的等价子图。符号表达式树提供了模式匹配的理想数据结构。例如,我们可以定义规则:
im2col(X) · reshape(W) → convolution(X, W)
将已经转化为矩阵乘法的卷积模式重新识别为卷积算子,以便利用专门的卷积库(如 cuDNN)。反过来,也可以将卷积替换为 im2col+GEMM 以利用矩阵乘优化库。这些规则可以表示为模式树与替换树,并通过 subs 风格的操作实现。更复杂的规则如:
convolution(X, W) (当 K_h, K_w 很小时) → direct_conv(X, W)
允许在特定条件下(如小卷积核)选择直接卷积实现。
5.3 维度推导与类型推断
通过符号表达式,编译器可以自动推导张量的形状和数据类型。例如,给定 $A$ 的形状 $(m, k)$ 和 $B$ 的形状 $(k, n)$,编译器可以推导出 $C = A B$ 的形状 $(m, n)$,即使这些维度是符号变量(如动态形状)。这种推导基于符号计算规则,如:shape(C) = (m, n)。
对于卷积,形状推导规则可以编码为符号表达式,并在编译期完成。这有助于在动态形状场景下生成通用代码,同时也能在静态形状下进行更激进的优化。
6. 总结
本文以 SymPy 为工具,展示了如何用符号表达式描述深度学习中的矩阵乘法和卷积变换。通过 IndexedBase、Eq 和 subs,我们可以形式化地定义中间变量,并逐步代入消去,验证优化变换的等价性。表达式树的可视化帮助理解 subs 的内部机制。重点展开的 im2col+GEMM 符号推导,证明了这种变换与标准卷积的一致性。
最后,探讨了这些技术在深度学习编译器中的应用,包括算子融合、模式匹配和维度推导。符号计算为编译器的自动化优化提供了坚实的数学基础,有望在未来实现更智能、更可靠的代码生成。随着深度学习模型和硬件的不断发展,符号推导将在编译器设计中扮演越来越重要的角色。希望这篇深入的技术解析能为你打开一扇窗,欢迎在 云栈社区 继续探讨相关话题。
 发表于 2026-3-8 03:41:01
|
查看: 110|
回复: 0
发表于 2026-3-8 03:41:01
|
查看: 110|
回复: 0
