在金融与自然语言处理的交叉领域,文本预测一直是个核心挑战。这类任务处理的文档通常很长,而真正影响决策的有效信号往往稀疏且微妙,容易被海量文本中的噪声所掩盖。一个令人头疼的现实是,对于不同的任务或数据集,生成最佳嵌入表示的大语言模型可能各不相同。
为了系统性地解决这个问题,一个名为“FinAnchor”的轻量级框架被提出。它无需微调底层大模型,而是创新性地将多个模型的嵌入表示进行对齐与整合。在五个金融数据集的实验中,FinAnchor均展现出了最佳的整体性能。

摘要
金融长文档预测的难点在于有效信号稀少且易被噪声掩盖,而不同的任务和时期,能生成最佳嵌入的大语言模型也各不相同。本文提出的FinAnchor框架,旨在不微调底层模型的前提下,整合多个大语言模型的嵌入表示。
该框架的核心思想是选择一个“锚”嵌入空间,然后学习线性映射,将其他模型(源模型)的表示投影到这个锚空间中。通过对齐后的特征进行聚合,形成一个统一的表示,用于下游的预测任务。在多个金融NLP任务上的评估表明,FinAnchor的性能超越了单一模型基线以及标准的集成方法,证明了利用锚定方法对齐异构表示,能够实现更稳健的金融预测。
简介
金融文本预测是金融与自然语言处理交叉领域的核心问题,处理的多为长文档,决策相关信号稀疏微妙。早期方法依赖传统的机器学习管道,随后预训练的语言编码器取代了手动特征工程。近年来,大语言模型受到了广泛关注。
然而,不同的LLMs对同一份长金融文档进行编码时,会因其固有的归纳偏差而产生异质的推理过程和不同的预测结果。这引发了一个关键思考:能否系统性地整合这些异构的表示空间,将互补的证据转化为可用的信号,从而避免性能的不稳定或下降?
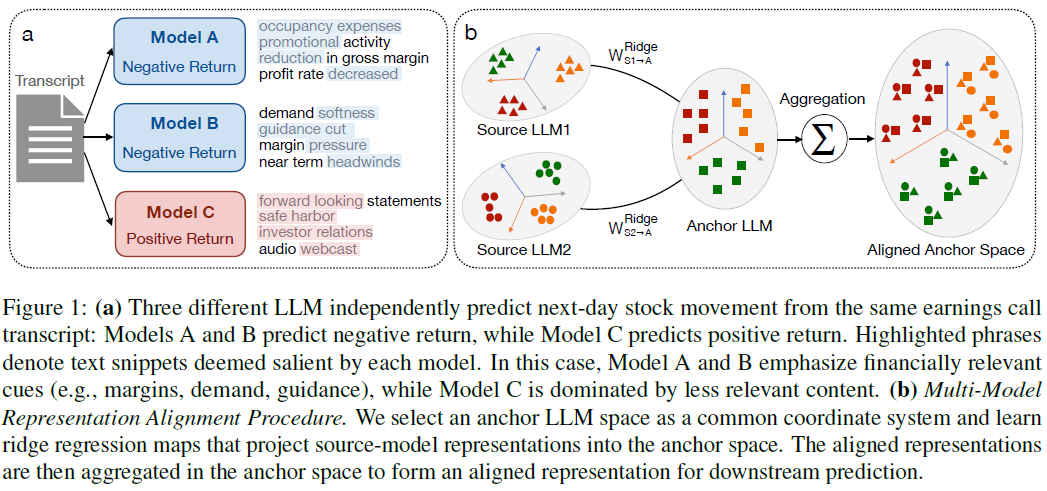
本文提出的FinAnchor框架,旨在无需微调基础模型的情况下,实现多编码器的明确聚合。它选择一个编码器作为“锚”空间,利用训练集学习从其他编码器到锚空间的线性对齐映射。在对齐之后,使用固定的聚合算子融合表示,并训练一个下游的“读出器”来进行预测。这种方法显著降低了训练和推理成本,同时保留了模型的可审计性。
本文在多个金融预测任务上对FinAnchor进行了评估,采用了基于时间的数据划分以衡量其泛化能力,并提供了面向从业者的可解释性分析。
本文的主要贡献包括:
- 引入了一个轻量级的多编码器对齐聚合框架,能够结合冻结的大语言模型表示。
- 在多个金融预测任务上进行了系统性评估,并与单一编码器及朴素的多编码器基线进行了对比。
- 提供了可解释性分析,识别了性能提升的来源。
方法

问题设置
给定包含文档 $t_i$ 和标签 $y_i$ 的示例,使用 $M$ 个冻结的大语言模型编码器对 $t_i$ 进行编码,得到表示 $x_i$。采用基于时间的数据集划分方式,整个框架仅在嵌入层之上训练轻量级组件。
线性对齐到锚空间
不同编码器的原始嵌入位于异构的坐标空间中。我们选择一个编码器 $a$ 作为“锚”编码器,然后使用岭回归学习一个线性映射,将每个源编码器的表示投影到锚空间中。利用训练集拟合映射矩阵 $W_m$,并在验证集和测试集上应用此映射。
$$
W_m = \arg \min_{W\in\mathbb{R}^{d_m\times d_a}} \|\tilde{X}^{(m)}W - \tilde{X}^{(a)}\|_F^2 + \alpha\|W\|_F^2, \quad (1)
$$
其中 $\alpha$ 是正则化超参数。映射的质量通过训练集的决定系数 $R^2$ 来报告。
对齐表示聚合
在将源模型的表示投影到锚空间后,我们在锚空间中计算平均表示,得到一个对齐后的表示 $z_i$。
$$
z_i = \frac{1}{M} (x_i^{(a)} + \sum_{m \neq a} \hat{x}_i^{(m \to a)}). \quad (2)
$$
最后,对训练集的特征进行标准化,并将相同的标准化参数应用于验证集和测试集。
轻量级输出
在聚合表示 $z_i$ 上,我们训练一个小型分类器 $g_{\theta}$。对于二分类任务,使用带交叉熵损失的多层感知机(MLP)。对于多分类任务,使用带类权重重新加权的softmax分类器。模型选择和早停基于验证集进行。选择合适的阈值以优化特定指标,并应用于测试集。
实验
实验旨在回答三个核心问题:
- RQ1: 与基线模型相比,性能如何?
- RQ2: 性能增益是源于稳定的系统信号,还是偶然的噪声?
- RQ3: 该方法是否具备可解释性?
实验设置
任务与数据集:
- 收益惊喜预测: 二元文本分类任务,输入为长金融文本(收益电话会议记录、10-Q文件、纳斯达克新闻文章),预测是否存在“收益惊喜”。
- 股票走势预测: 二元分类任务,输入为收益电话会议记录,标签为股票次日的涨跌。
- FOMC立场分类: 三元分类任务,预测美国联邦公开市场委员会(FOMC)通信的货币政策立场。
基线对比:
与多种基线进行对比,包括:LLM零样本提示、LLM少样本提示、Longformer、Hierarchical FinBERT、以及单一LLM表示方法。
实现细节:
- 以Gemma2-9B-Instruct作为锚模型,Qwen3-8B-Instruct和Llama-3.1-8B-Instruct作为源模型。
- 输入截断至最多20000个标记。
- 使用岭回归映射对齐多模型表示。
- 读出器采用PyTorch实现的三层MLP(隐藏层256维,Dropout率0.5,ReLU激活)。
- 报告准确率(Accuracy)和F1分数。
与基线对比
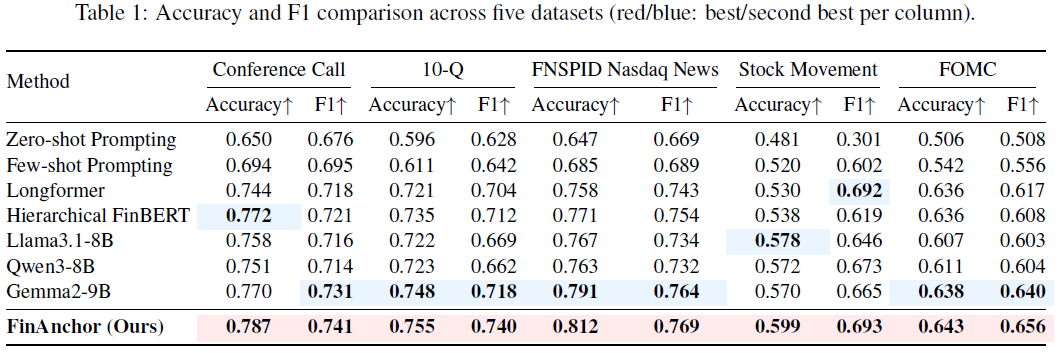
在五个数据集上的对比结果总结如下:
关键发现:
- 基于提示的方法落后于学习型编码器:在长文档任务上,这种差距尤为明显。
- 传统长文档编码器仍有竞争力:Longformer和Hierarchical FinBERT在三个文本密集型数据集上表现出色。
- FinAnchor整体性能最佳:在五个数据集上,FinAnchor在准确率和F1值上均取得了最佳结果,在部分数据集上大幅超越了最强的单模型LLM基线。
- 在挑战性任务中依然有效:在信号更弱的股票走势预测和FOMC立场分类任务中,FinAnchor仍获得了最佳结果,表明该方法在处理微妙信号时同样有益。
一致性分析
为探究FinAnchor的收益是反映系统信号还是随机波动,我们遵循以下证据链进行分析:
错误重叠:
通过检查不同大语言模型表征是否犯相同的错误来进行诊断。结果显示,单模型预测之间的成对错误重叠率远低于1。
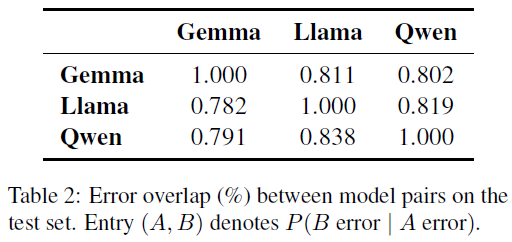
这表明每个表征都有其独特的错误模式,这是通过集成进行误差校正的前提。
决策转变:
考察对齐过程是否将多样性转化为可操作的校正。当用对齐后的FinAnchor模型替换锚模型时,观察到了不对称的决策转变。

例如,大量假阳性(FP)案例被修正为真阴性(TN),这在金融预测中有利于风险控制,具有实际效用。
置信度漂移:
为判断决策翻转是否源于阈值附近的不稳定波动,我们测量了对齐是否将概率质量系统性地重新分配到真实标签。定义置信度偏移 $\Delta p_{\text{true}}(x) = p_A(y \mid x) - p_G(y \mid x)$。如果FinAnchor提取了稳定信号来改进模型,那么被校正案例的 $\Delta p_{\text{true}}$ 应为正,未改变的案例应接近零。
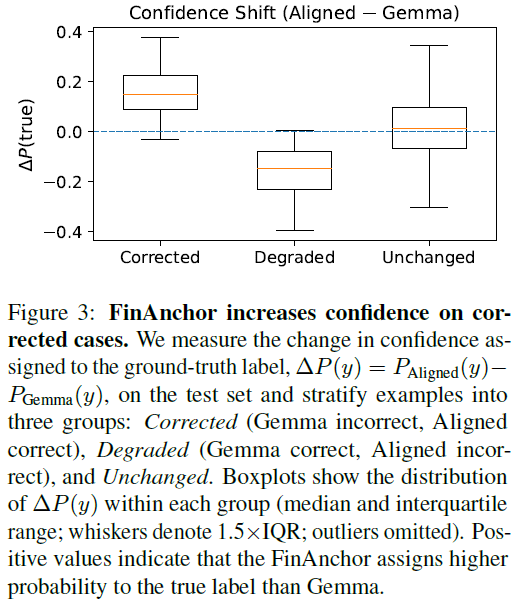
图3的结果符合预期,表明FinAnchor的改进源于对真实标签置信度的一致提升,而非任意扰动。
可解释性分析
我们从两方面考察了表征对齐后决策过程的变化:
线性对齐质量:
报告了各源表征与锚(Gemma)嵌入空间对齐的岭回归映射的决定系数($R^2$)。

$$
T_s = \arg \min_T \sum_{i\in D_{tr}} \|T x_i^{(s)} - x_i^{(G)}\|_2^2 + \lambda \|T\|_2^2, \quad (3)
$$
$$
R^2 = 1 - \frac{\sum_{i\in D_{tr}} \|x_i^{(G)} - T_s(x_i^{(s)})\|_2^2}{\sum_{i\in D_{tr}} \|x_i^{(G)} - \bar{x}^{(G)}\|_2^2}. \quad (4)
$$
高达0.97-0.98的 $R^2$ 表明,不同大语言模型表征在该领域具有兼容的几何结构。线性对齐能够将不同坐标系转换到一个共同的语义框架中,使得后续的特征融合有意义。
案例研究:
下表展示了一个Gemma单独使用时产生的假阳性(错误预测为“涨”)示例,该示例被FinAnchor成功纠正。

通过遮挡句子并测量其对模型logit的影响,发现FinAnchor对财务显著的看跌线索(如“promotional activity”、“reduction in gross margin”)赋予了更大的负向权重。这表明FinAnchor通过结构化的证据重新加权来改变决策,而非随机干扰置信度。
限制
本研究聚焦于金融预测任务,使用了固定的骨干模型和统一的评估协议。研究结果的普适性有待在更多样化的任务、语言和模型家族中进行验证。此外,该方法结合了冻结表征与对齐聚合模块,虽然简化了训练和部署,但也引入了额外的实现选择和超参数。未来需要开展系统的敏感性研究和工程成本分析,以增强方法的可重复性和实用性。
总结
本文提出了一种结合异构大语言模型表示的简单对齐方法。其核心是学习一个到锚空间的线性映射,聚合对齐后的视图,并训练一个轻量级读出器用于金融预测。在五项任务中,FinAnchor均优于单视图基线,且易于实现。
分析表明,性能提升并非源于噪声:不同的视图会犯不同的错误,而对齐过程成功将这种多样性转化为有效的修正,尤其擅长减少虚假的买入信号。可解释性分析进一步揭示,性能增益源于对齐后模型间互补的语义证据得到了更好的整合,而非随机的扰动。
这项研究为如何高效、低成本地整合多个大模型的优势,以提升复杂领域(如金融)的预测性能,提供了一种有价值的思路。对这类多模型集成技术感兴趣的朋友,欢迎到云栈社区交流讨论。
 发表于 2026-3-8 03:44:35
|
查看: 129|
回复: 0
发表于 2026-3-8 03:44:35
|
查看: 129|
回复: 0
