
临床诊断高度依赖于全面而细致的信息收集,但在现实诊疗中,医生往往面临时间与精力的双重压力。据统计,高达30%-50%的诊断错误都源于信息收集不充分或病史采集存在遗漏。患者通常只描述最明显的不适,而许多对诊断至关重要的细节,需要医生通过一系列有技巧的追问才能浮现。这个过程不仅耗时,也加剧了医疗资源的紧张。
针对这一核心痛点,卡内基梅隆大学与亚马逊健康AI的研究团队提出了一种创新解决方案——KG-Followup框架。该框架巧妙地将结构化医学知识图谱与大语言模型(LLM)的能力相结合,旨在让AI模拟医生的诊断思维,自动生成临床相关的精准追问问题,从而成为医生的高效预诊断助手。
一、KG-Followup框架核心设计:五步构建智能追问引擎
KG-Followup的目标非常明确:给定一段患者与医生的对话历史,系统需要一次性生成一组静态的、用于收集更多信息的追问问题列表,而不是进行多轮交互。这更符合实际的预诊断场景需求。其整体流程如下图所示,主要包含五个关键步骤:
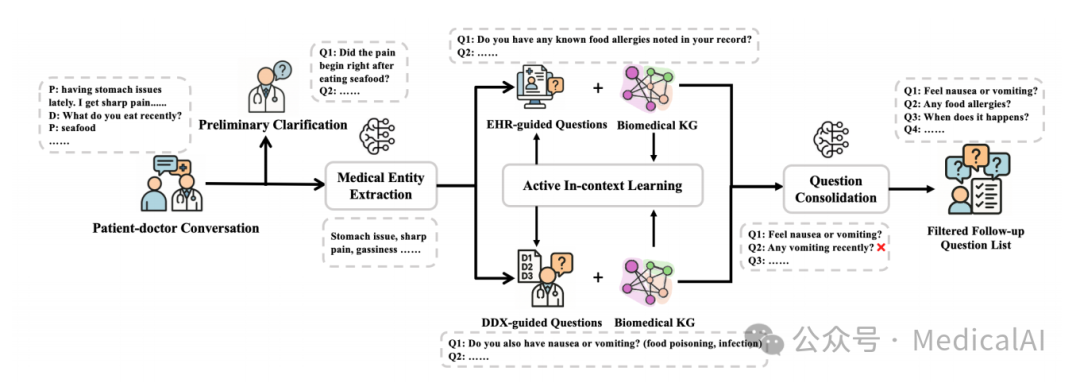
图1:KG-Followup框架从对话理解到问题生成的全流程
1. 初步澄清:基于LLM直觉的起始点
首先,系统会直接让LLM基于原始对话内容,生成一组初步的追问问题。这一步相当于模拟医生初诊时的“第一反应”,完全依赖于模型内部已掌握的医学知识。然而,LLM的“知识盲区”是客观存在的,尤其是面对罕见病或复杂症状时,仅靠模型自身可能遗漏关键提问。
2. EHR引导的KG关联症状检索
为了弥补上述不足,系统引入了外部知识图谱。它首先提示LLM从对话中提取关键的医疗实体(如症状、疾病名),形成一个临时的“代理”电子健康记录(EHR)。然后,系统将这些实体链接到知识图谱的对应节点上,并通过广度优先搜索(BFS)构建出以每个实体为中心的局部子图。通过分析这些子图的交集,可以提取出多个症状共同关联的临床概念。
当然,并非所有关联概念都相关。因此,系统会再次调用LLM,对这些交集概念进行相关性排序,筛选出最相关的top-k个概念,并基于这些概念生成更具深度的追问问题。例如,从主诉“胸痛”可能关联出“放射痛”、“诱发因素(如活动后)”、“伴随症状(如出汗、呼吸困难)”等,从而生成更全面的问题集。
3. DDX引导的KG推理诊断路径
这一步模拟了医生的核心诊断策略——鉴别诊断(DDX)。系统首先让LLM基于现有信息,列出几种可能性诊断(包括最佳猜测和最坏情况)。针对每一个可能的诊断,生成旨在“排除”或“确认”该诊断的问题。
为了增强推理的专业性,系统深度利用了知识图谱的结构化关系。对于提取出的每个症状实体和每个可能诊断,系统会在知识图谱中寻找连接两者的最短推理路径。这些路径上的中间节点(如相关的检查、并发症、风险因素)构成了宝贵的领域知识。LLM会基于当前病例筛选出最相关的路径,并利用这些路径知识生成更扎实、更具针对性的DDX问题。
4. 基于KG的主动上下文学习
知识图谱还能帮助识别“难题”——即那些患者描述模糊、难以映射到具体图谱实体的案例。受主动学习思想启发,KG-Followup将这些“困难查询”及其对应的人工标注标准问题,作为上下文学习(ICL)的示例。
在最终生成问题时,所有模块(初步澄清、EHR-KG、DDX-KG)都会用上这些高质量的ICL示例进行增强。这使得系统即便在面对描述不清的病历时,也能借鉴类似难题的处理经验,生成合理的问题。
5. 问题整合与去冗余
经过以上步骤,系统会得到一个包含多来源问题的大型集合。为了避免问题重复、提高效率,系统会使用医学文本编码器将所有问题转化为向量,并进行聚类。随后,LLM会对每个聚类中的问题进行精炼和去重,合并语义重叠的部分,最终输出一个精简、高效、无冗余的追问问题列表。
二、实验验证:性能显著超越现有方案
为了公正评估,研究团队构建了一个新的基准测试集——ClinicalInquiryBench,它由真实的、经过医生标注的临床对话系统转换而来,专门用于评估AI生成临床追问的能力。
实验选取了Claude Haiku和Claude Sonnet作为骨干模型,并将KG-Followup与多种基线方法对比,包括直接使用GPT-4o、MedGemma-27b,以及Zero-Shot(零样本)和FollowupQ等方法。核心评估指标是召回率(Recall),即生成的问题覆盖标准答案(由医生提供)的比例,同时严格控制生成问题的数量。
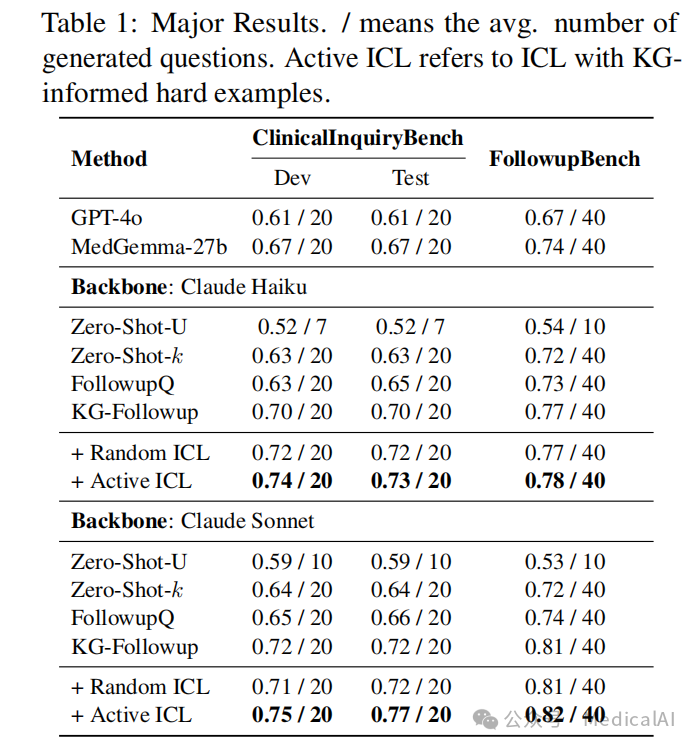
表1:不同方法在ClinicalInquiryBench和FollowupBench上的性能对比
关键结果:
- 在使用Claude Haiku时,KG-Followup在ClinicalInquiryBench测试集上取得了0.70的召回率(平均生成20个问题),显著超过了GPT-4o(0.61)和MedGemma-27b(0.67)。
- 当引入基于KG筛选的“主动ICL”示例后,性能进一步提升至0.74。
- 换用更强的Claude Sonnet模型后,KG-Followup在生成20个问题的设置下召回率达到0.77,在使用主动ICL并生成40个问题时,召回率最高达到0.82。
这些结果在另一个基准测试集FollowupBench上也得到了验证,表明KG-Followup具有良好的泛化能力。
消融实验深入分析
研究还通过消融实验,拆解了各个组件的贡献:
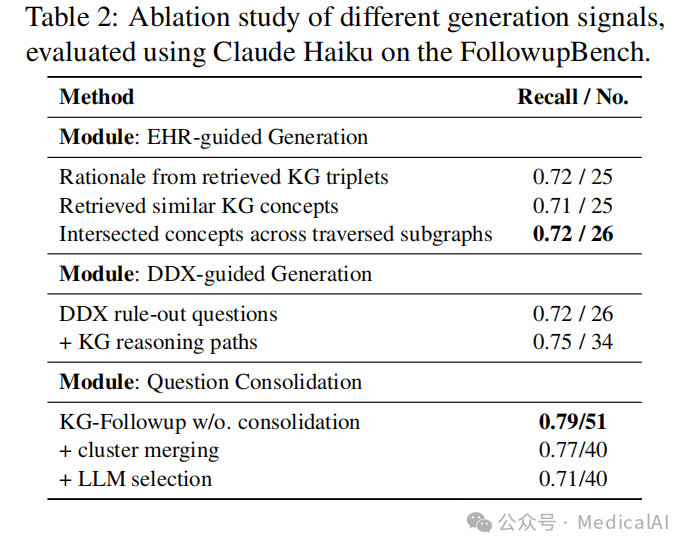
表2:不同生成模块的贡献度分析(在FollowupBench上)
结果表明,EHR-KG模块有效扩充了问题覆盖面,DDX-KG模块则显著增强了与诊断推理直接相关的问题生成质量。两者结合,再辅以主动ICL,实现了最佳性能。一个具体案例是,对于主诉“头痛”的患者,KG-Followup能通过知识图谱关联出“视力模糊”、“恶心”、“颈部僵硬”等相关症状,从而生成一套远比单纯询问“头痛多久了”更全面、更有诊断价值的问题列表。
三、优势、局限与未来展望
核心优势与临床价值
KG-Followup成功的关键,在于它用结构化的知识图谱为“黑盒”LLM注入了系统性的医学领域知识。这不仅提升了问题生成的准确性和全面性,也使得AI的推理过程更具可解释性(可以追溯至知识图谱中的路径)。
在临床实践中,该框架可集成到电子健康记录(EHR)系统中,在医生问诊前或问诊间隙自动生成追问建议。据估算,这有望减少医生5%-10%的信息收集负担,让他们能将更多精力集中于高阶的诊断决策和患者沟通上。对于远程医疗和基层医疗机构,这项技术更能放大其价值,在资源有限的条件下提升初诊质量,降低误诊和漏诊风险。
当前局限与改进方向
当然,该框架目前也存在一些挑战:
- 知识覆盖度:其性能依赖于底层知识图谱的完整性和时效性。对于最新发现的疾病或非常罕见的症状,图谱可能存在信息缺口。
- 计算效率:多次的图谱检索、路径搜索和LLM调用,可能导致一定的系统延迟,在实时交互场景中需要优化。
- 幻觉风险:尽管知识图谱提供了事实锚点,但LLM在生成问题表述时仍可能存在细微的偏差或不准确。
未来的改进可以围绕以下几点展开:融合多源医学知识图谱以扩大知识库;优化图谱检索与推理算法以降低延迟;建立医生反馈闭环,让人工智能在实际使用中持续迭代优化。
总结
KG-Followup框架代表了医疗AI向更深层次、更专业化发展的一次有力探索。它证明了“知识图谱+大语言模型”的组合拳,能够有效解决纯LLM在专业领域知识不足、推理链条模糊的问题。这项研究不仅提供了性能领先的SOTA方案和可复现的基准,更指明了一条让AI真正成为临床医生可靠助手的可行技术路径。对于关注人工智能与数字化转型前沿应用的朋友,这类结合领域知识增强大模型能力的研究,非常值得在云栈社区这样的技术论坛中深入探讨与持续跟踪。
 发表于 2026-3-8 05:30:33
|
查看: 175|
回复: 0
发表于 2026-3-8 05:30:33
|
查看: 175|
回复: 0
