
学术界曾普遍认为大值激活与注意力汇点(Attention Sink)是深度耦合的。然而,来自Yann LeCun团队的最新研究打破了这一常识,通过系统性的机制可解释性分析,揭示了这两个现象的真实关系。
在Transformer架构中,两个内部计算现象长期共存:一是大值激活(Massive Activations/Spikes),表现为少数token在部分隐藏通道中产生极端数值;二是注意力汇点,即部分token无视语义相关性,吸走大量注意力权重。
研究证明,它们的共现并非必然,而是特定架构设计(如Pre-norm归一化)催生的偶然副产品。这一发现为大语言模型的量化部署和长上下文推理优化提供了更清晰的思路。

论文标题:The Spike, the Sparse and the Sink: Anatomy of Massive Activations and Attention Sinks
论文链接:https://arxiv.org/pdf/2603.05498
01. 优化越健康,汇点越明显
我们通常认为模型内部的极端数值或注意力坍缩是未充分优化的表现。但针对优化超参数的消融实验却得出了相反的结论。
数据显示,注意力汇点比例(Sink Ratio)实际上可以作为评估模型优化健康度的一个代理指标。当我们刻意使用次优超参数(如关闭权重衰减 Weight Decay = 0.0)时,大值激活的幅度会失控地飙升至12275,但此时模型的困惑度并未改善,汇点比例也仅停留在33.8%。
这说明,注意力汇点是模型在健康状态下主动习得的有效策略,而大值激活的幅度变化在很大程度上独立于模型的整体表现与汇点比例。
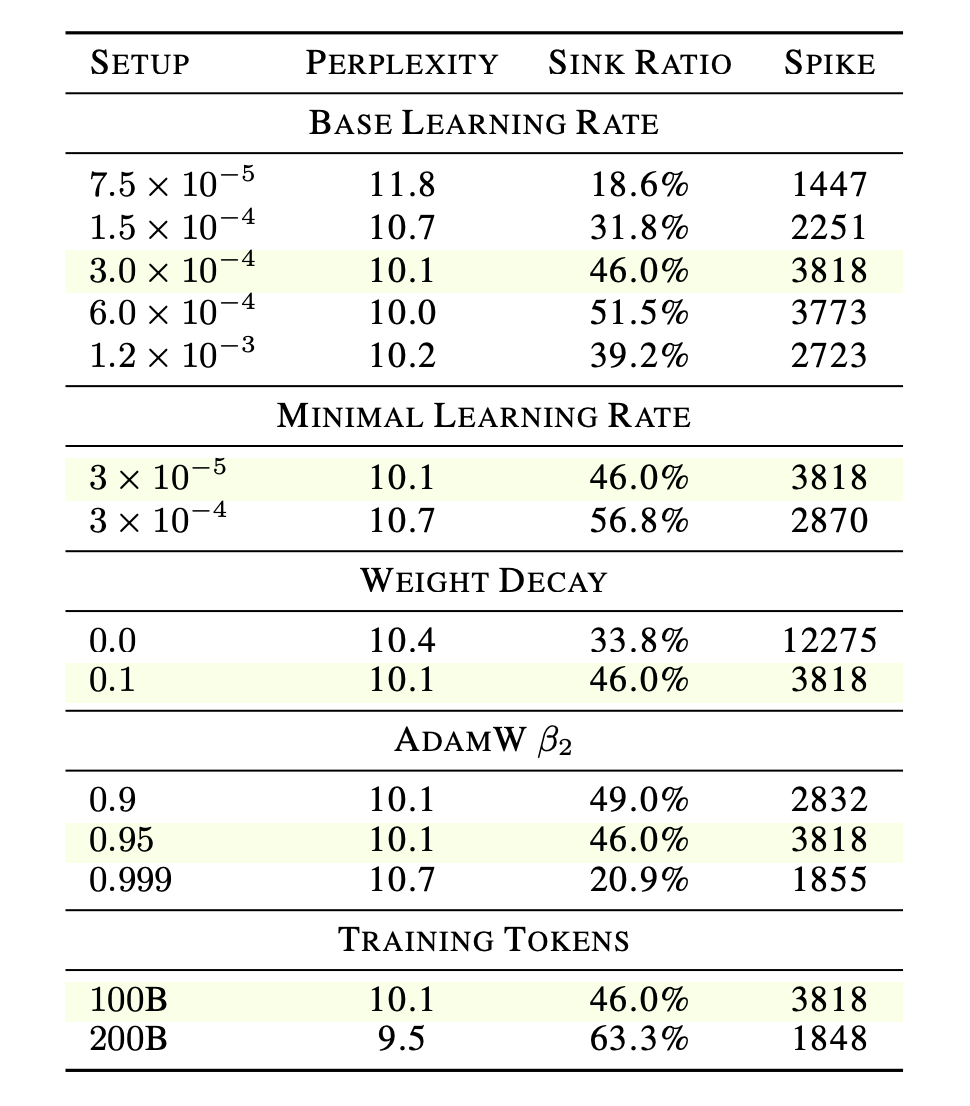
表1:优化超参数消融实验显示 Spike 与 Sink 对超参数的响应呈现明显分化
02. 解剖大值激活:位置0的特殊性
剥离“优化不良”的标签后,统计数据揭示了大值激活的真实成因:在Llama和Qwen系列的多个模型中,超过98%的词汇只要处于序列的第一个位置,就会稳定触发大值激活。
这证明了大值激活纯粹由架构位置驱动,而非token自身的语义决定。
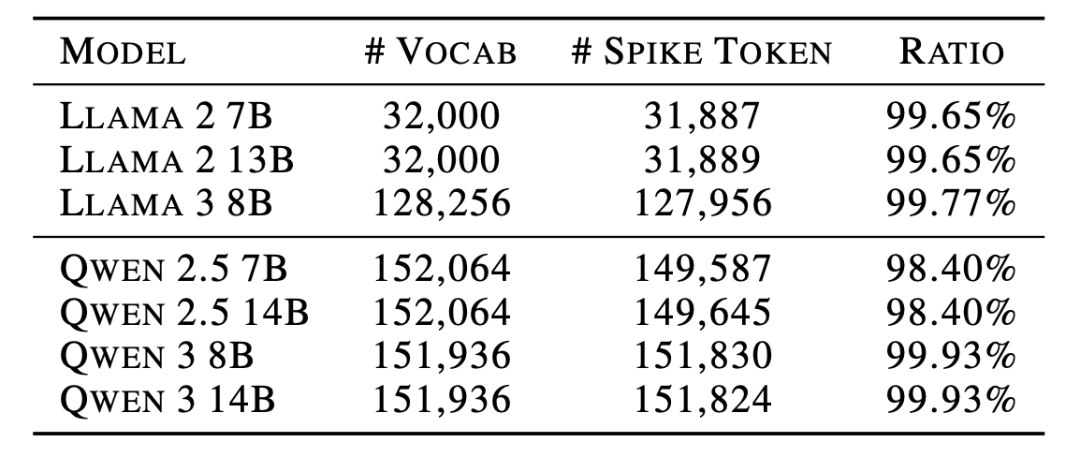
表2:模型初始位置触发 Spike 的现象具有极高的普遍性
序列的首个token仅对自身计算注意力,导致此时的注意力块退化为静态的线性映射。这种无视上下文的变换,会稳定地将第一位置的隐藏状态推向触发大值激活的特定高增益方向。
真正执行放大操作的核心是基于SwiGLU的前馈网络。在网络早期的“跃升块”中,SiLU激活函数实际上运行在近似恒等的区间。
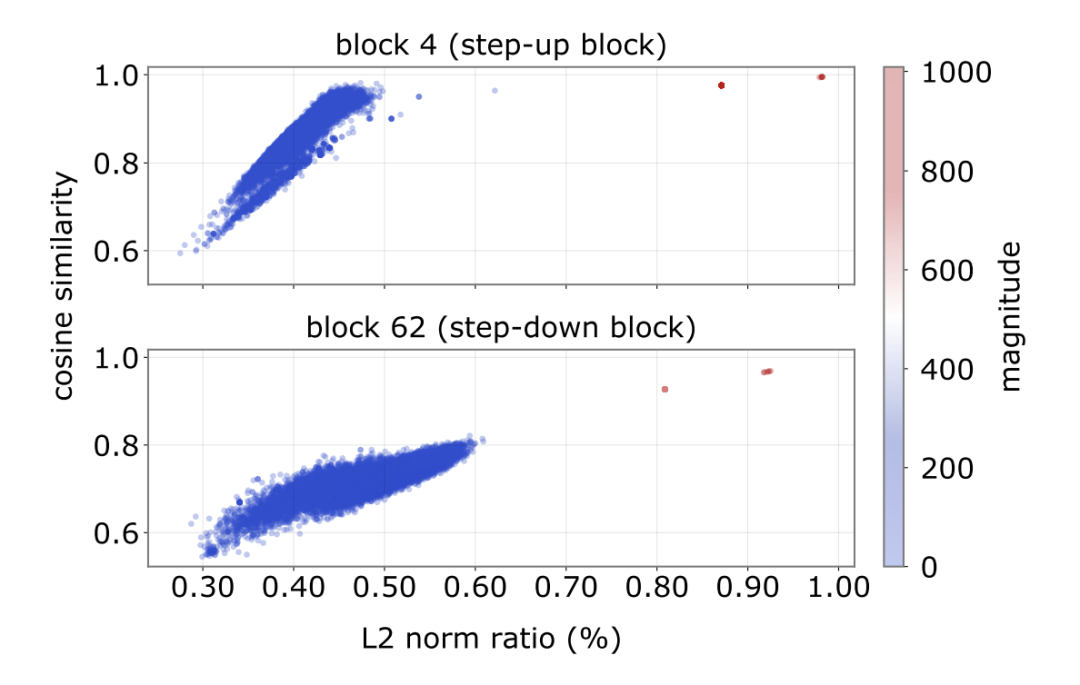
图1:SiLU 门控在升压与回落块中表现出近似恒等的输入输出特征
在近似恒等的条件下,前馈网络输出的第 $k$ 个坐标可以被严密地近似为二次型:
$F_{ffn}(\tilde{h}^{(s)})_k \approx \tilde{h}^{(s)\top} U_k \tilde{h}^{(s)} = \tilde{h}^{(s)\top} S_k \tilde{h}^{(s)},$
其中,决定放大倍数的矩阵 $U_k$ 定义为:
$U_k = \Sigma_{i=1}^{d_{ffn}} W_{down}^{(k,i)} W_{gate}^{(i)} W_{up}^{(i)\top}$
进一步的谱分析揭示了单一特征值主导现象。对于那些出现大值激活的通道,其二次型矩阵 $S_k$ 的特征值谱被单一的主导特征值完全控制。
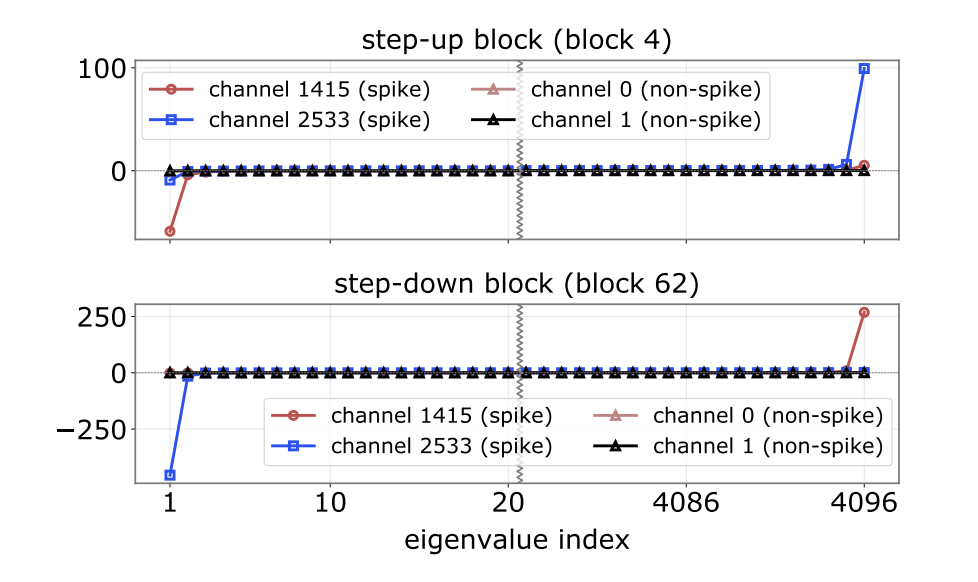
图2:Spike 通道的特征值谱存在单一的超大主特征值
当token的输入表示在这个主特征向量方向上有投影时,数值便会被剧烈成倍放大,进而形成大值激活。由于残差连接的加法特性,这些极值在网络中间层不断累积并保持平台期,直到在网络末端的“回落块”中被相反符号的极值精准抵消。
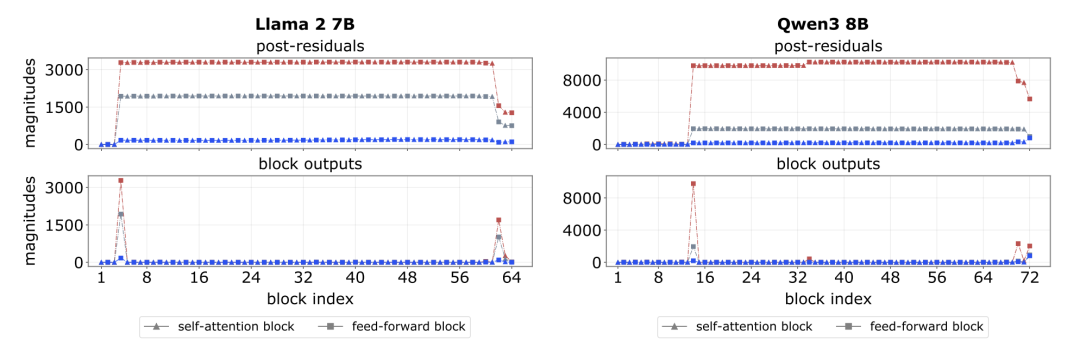
图3:大值激活幅度随模型深度的“上升-平台-下降”全生命周期轨迹
03. 从大值激活到汇点:归一化与几何子空间的博弈
前置归一化是极端的大值激活数值演变为注意力汇点的关键架构桥梁。
经过RMSNorm操作后,大值激活的绝对数值被压缩至有界范围,同时非异常通道被极度抑制。此时,归一化后的状态 $\tilde{h}^{(s)}$ 近似坍缩为一个极其稀疏的多热点向量:
$\tilde{h}^{(s)} \approx \sum \tilde{h}_i^{(s)}e_i, \quad i \in C$
这种稀疏化抹平了token之间原本的个性差异,使其沦为近乎恒定的架构符号。当这个稀疏向量通过注意力键权重矩阵 $W_K$ 投影后,汇点token的键向量被高度局限于一个极低维的子空间内:
$k^{(s)} = W_K^T h^{(s)} \approx \sum (h_i^{(s)} W_K^T e_i), \quad i \in C$
注意力汇点能否最终形成,取决于注意力头本身的模型容量。实验表明,随着头部维度从8增加到128,汇点比例单调上升。更大的维度赋予了模型充足的空间,使得汇点键与非汇点键在几何上彻底分离。
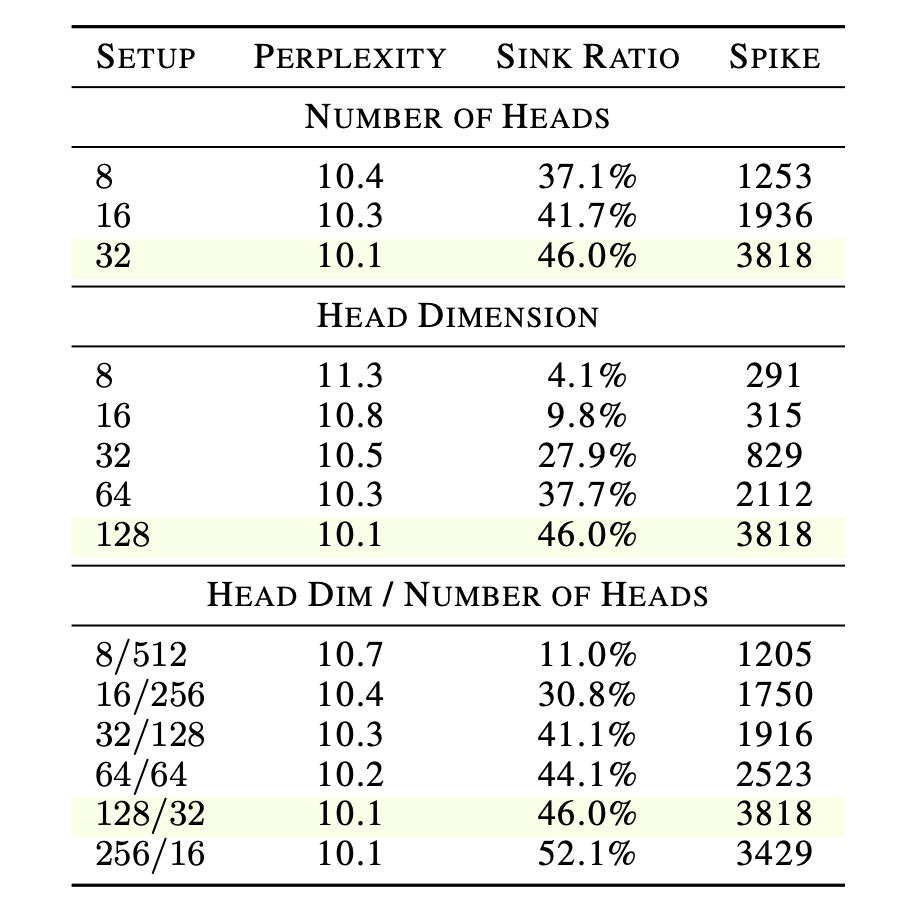
表3:注意力头部维度是决定 Sink 形成的主导架构因素
通过t-SNE可视化可以清晰看到这场几何博弈:在形成汇点的注意力头中,模型的查询子空间主动靠近固定的汇点键,从而拉开巨大的Logit差距,自然而然地吸走了多余的注意力权重。
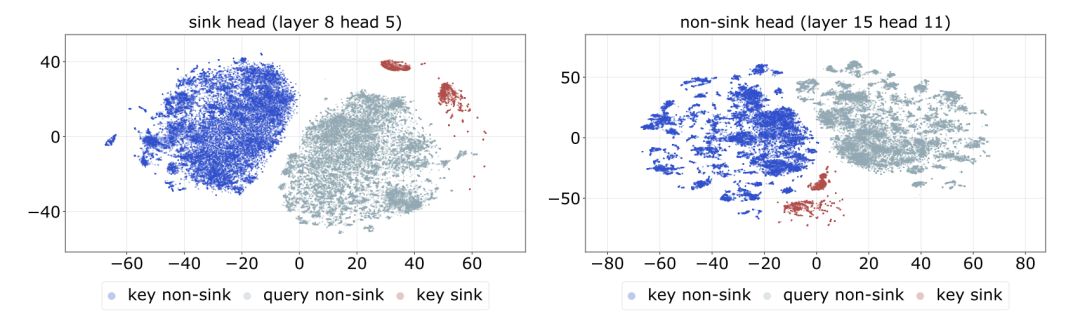
图4:Sink Head 中的查询向量子空间在几何距离上显著贴近 Sink 键向量
为了验证二者的真实因果关系,研究人员引入了归一化消融实验。当改用Sandwich Norm或动态双曲正切替换常规配置时,模型内部的大值激活现象被成功压制甚至消除,但模型依然维持了显著的汇点比例。
这从机制上确证了大值激活并非注意力汇点的必要前提,二者可以被安全解绑。
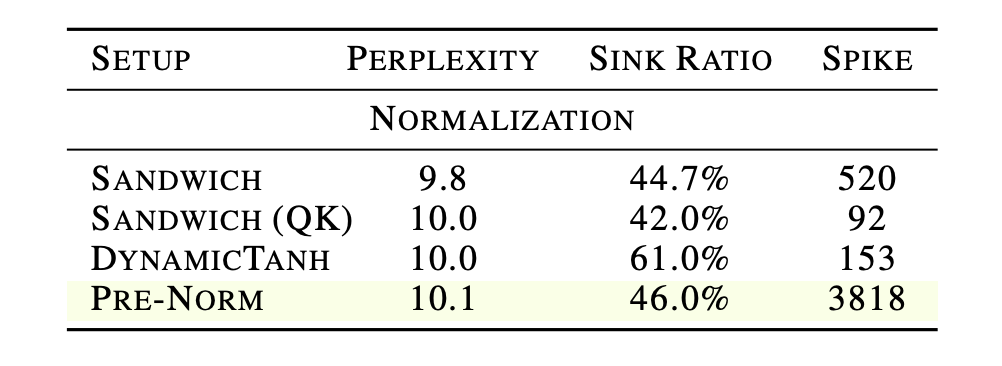
表4:改变归一化策略能在保留 Sink 的同时彻底抑制 Spike
04. 探寻汇点的真实本源
门控注意力的消融实验,彻底揭示了模型维持注意力汇点现象的真实动机。当我们为模型引入基于当前隐藏表示的动态条件门控时,汇点现象几乎完全消失。
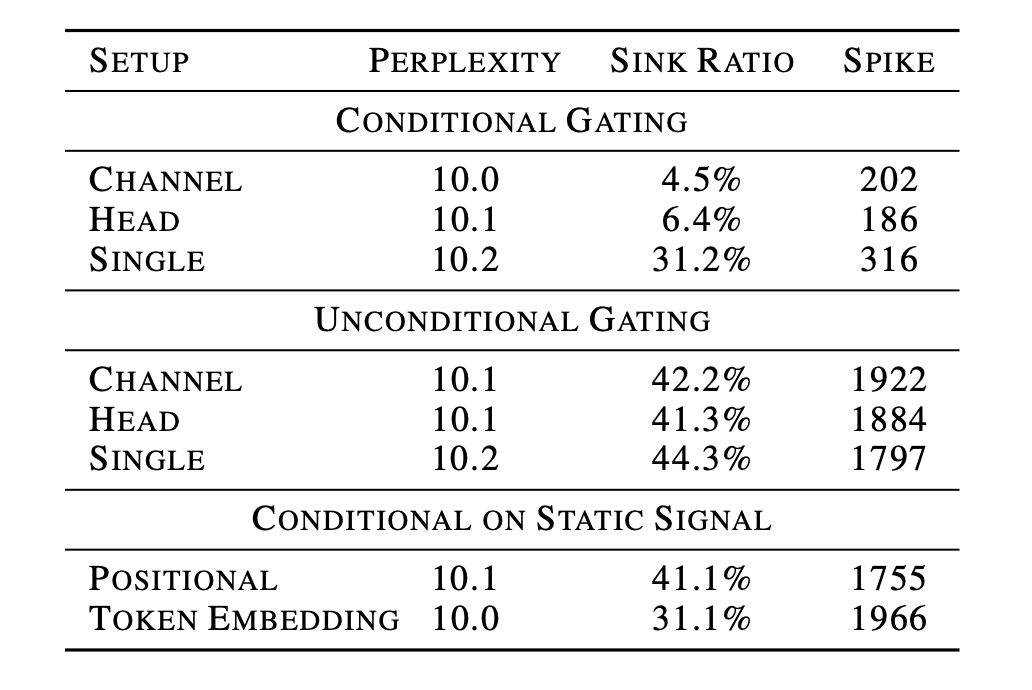
表5:引入条件门控消除了大模型维持 Sink 现象的结构性需求
这揭示了注意力汇点的本质是一种习得的路由策略。在缺乏显式动态门控时,模型被迫将第一个位置作为一个“数值垃圾桶”,以此隐式地关闭对当前预测无用的注意力头。
上下文长度的消融实验则进一步确认了汇点的服务对象。当训练数据剔除短序列,仅保留长序列进行训练时,汇点比例出现断崖式下跌。
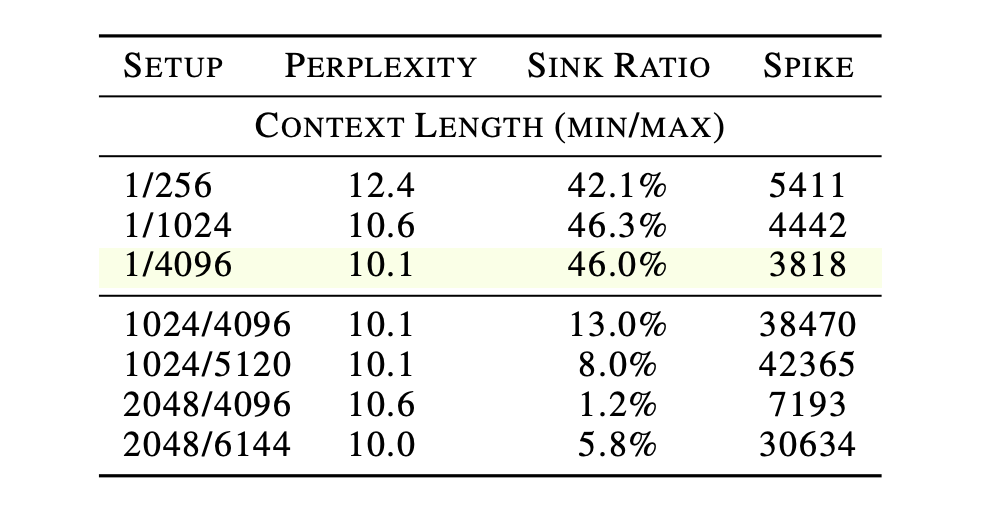
表6:剔除短上下文训练数据导致 Sink 比例的大幅坍塌
这最终证实,注意力汇点是模型在使用全局注意力机制处理短距离依赖关系时,产生的一种必然归纳偏置。
05. 结语
LeCun团队的这项工作通过抽丝剥茧的消融与推导,打破了过去对大值激活与注意力汇点强绑定的误解。
大值激活更多是特定前馈网络结构与残差累积共同塑造的副产品,而注意力汇点则是注意力机制为了兼顾局部特征提取而不得不采取的变通方案。这两个现象在标准大语言模型中的重叠,只是常规架构与训练配方下的一次偶遇。
在针对大模型进行量化或长上下文推理优化时,完全可以通过架构层面的微调独立抑制无意义的极端数值,而不必担心损害模型原有的语言建模能力。更多前沿的深度学习研究成果与技术讨论,欢迎访问云栈社区进行交流。
 发表于 2026-3-13 19:45:12
|
查看: 145|
回复: 0
发表于 2026-3-13 19:45:12
|
查看: 145|
回复: 0
