GPU架构
- kernal 优化
- 启动设置(使用大量线程)
- 全局内存吞吐量(有效使用内存)
- 共享内存获取
本文以CUDA C++为例,但是优化思路同样适用于其他语言,如 CUDA Fortran 等,只是API有所不同。
KEPLER架构
- SMX (enhanced SM):SMX 是 “Streaming Multiprocessor X” 的缩写,是 Kepler 架构对前代 “SM”(流式多处理器)的增强版,负责并行执行线程束(Warp)。GPU可以看作是多个SM(流处理器)的组合,SM上定义了GPU架构的特性、指令集等。(通常SM数量越多,GPU性能越高)
- 192 SP units (“cores”):SP(Streaming Processor)即流处理器,是执行浮点/整数运算的核心单元,192 个 SP 意味着每个 SMX 可以并行处理大量计算任务。它也被称为“核”(core),但与CPU的核不同,通常会用SM的数量来对比CPU的核数。
- 64 DP units:DP(Double-Precision)单元是专门处理双精度浮点运算的硬件模块,64 个 DP 单元让 Kepler 架构在科学计算中具备更强的双精度性能。
- LD/ST units:LD/ST(Load/Store)单元负责内存读写操作。
- 64K registers:一个SM拥有64K 个寄存器(即 65536 个,每个寄存器可存储一个 32 位(4 字节)的数据,总大小为 65536 × 32 位 = 65536 × 4 字节 = 262,144 字节 = 256 KB),为线程提供高速私有存储,减少对共享内存或全局内存的依赖。程序运行时,通常首先将指令加载(load)进寄存器,然后由执行单元(如SP)去执行,并用LD/ST单元来保存数据。
- 4 warp schedulers:Warp(线程束)是 GPU 的基本执行单元(包含 32 个线程),4 个 Warp 调度器负责从线程束池中选择可执行的束,进行并行调度。
- 每个时钟周期的 Warp 指令派发上限:4 个 Warp
- Each warp scheduler is dual-issue capable:每个 Warp 调度器支持 “双发射”,即一次可向执行单元派发两条指令,从而提升指令吞吐量。
- 单个 Warp 的 “双发射”:1 个 Warp 能同时发出 2 条指令。
- 这两条指令必须是 “不冲突” 的(例如一条是算术运算指令,另一条是内存读写指令,或者是两条无数据依赖的算术指令);
- GPU 的执行单元采用 “多端口” 设计(例如 SP 单元和 LD/ST 单元可并行工作),两条指令会被派发到不同的执行单元,同时完成;
- 对 Warp 内的 32 个线程来说,相当于 “同一时间既执行了指令 A,又执行了指令 B”,但每个线程的指令执行是同步的(32 个线程同时完成 A,也同时完成 B)。
- K20: 13 SMX’s, 5GB / K20X: 14 SMX’s, 6GB / K40: 15 SMX’s, 12GB:不同型号的 GPU 包含的 SMX 数量和显存容量不同,SMX 越多、显存越大,整体计算和存储能力越强。
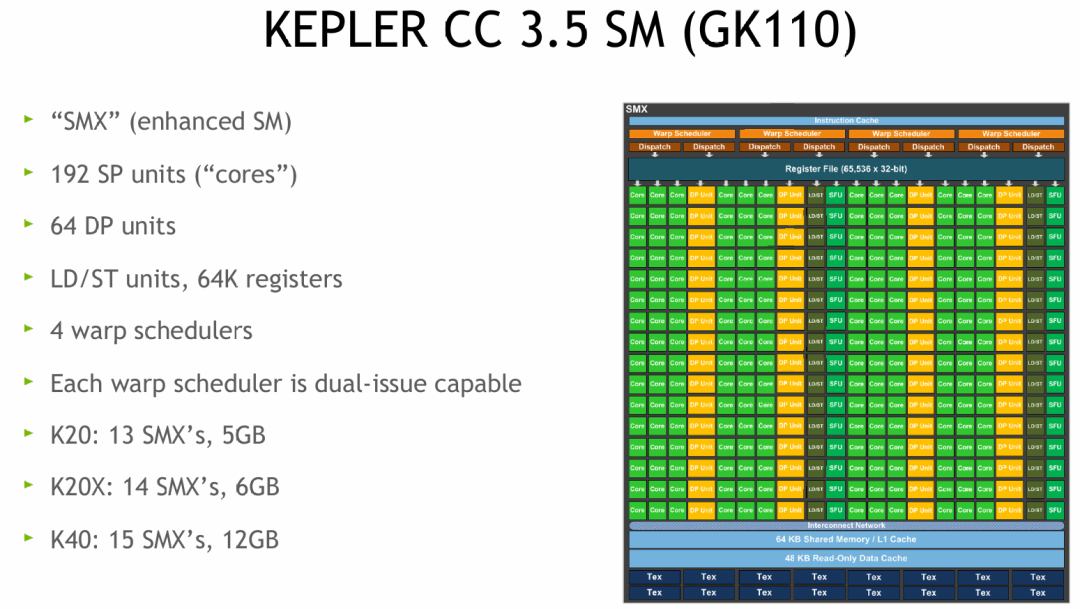
- Instruction Cache & Warp Schedulers:
- 指令缓存存储待执行的内核指令;
- 4 个 Warp 调度器(配合 “双发射”)负责选择线程束并派发指令,实现多线程束的并行调度。
- Register File (65,536 x 32-bit):6.5 万多个 32 位寄存器,为线程提供低延迟的私有存储,线程间的寄存器相互独立,避免冲突。
- Execution Units(执行单元层):
- Core(SP 单元):绿色模块,负责单精度浮点、整数运算;
- DP Unit:橙色模块,负责双精度浮点运算;
- SFU(Special Function Unit):负责特殊函数运算(如三角函数、平方根);
- LD/ST Unit:负责内存加载/存储操作。这些单元按 “计算类型” 分类,由 Warp 调度器按需调度,实现各类运算的并行执行。
- Shared Memory / L1 Cache(64 KB):64KB 的共享内存与 L1 缓存共享存储空间,可以灵活配置比例(例如 48KB 共享内存 + 16KB L1 缓存)。共享内存是线程块内线程通信的高速区域,L1 缓存则用于加速全局内存访问。
- Read-Only Data Cache(48 KB):只读数据缓存,用于加速常量内存、纹理内存的访问,适合频繁读取且不修改的数据(例如神经网络的权重参数)。
- Tex Units(纹理单元):处理纹理映射相关操作,在图形渲染和部分通用计算(如图像处理)中发挥作用。
- 它与内存的核心区别在于:内存的作用是 “存储数据”(例如纹理内存、全局内存负责存放纹理图像数据),而 Tex Units 的作用是 “处理数据”——从纹理内存或纹理缓存中读取数据,执行采样、过滤、格式转换等硬件加速操作,再将处理结果传递给流处理器(SP)用于计算或渲染。(图中的 “Tex” 模块就是纹理单元,负责处理纹理内存的读取、采样、过滤等操作,是纹理内存发挥作用的核心执行模块。)
MAXWELL/PASCAL架构
 cc 6.1:INT8:它指NVIDIA Pascal架构(计算能力6.1)对8位整数(INT8)的硬件支持,通过低精度计算加速深度学习推理,可降低存储与计算成本,提升AI模型(如图像分类、目标检测)的推理速度,是Pascal架构在AI领域的关键特性之一。INT8 支持是对图中核心执行单元(SP)的功能扩展,而非独立标注的组件,通过硬件优化让现有单元具备低精度计算能力。简单来说,CC 6.1 的 INT8 是 NVIDIA 在 Pascal 架构显卡中加入的专用硬件电路,专门用来极速处理一种叫“8位整数”的简单计算,让AI推理(使用模型)的速度飙升,功耗大降。
cc 6.1:INT8:它指NVIDIA Pascal架构(计算能力6.1)对8位整数(INT8)的硬件支持,通过低精度计算加速深度学习推理,可降低存储与计算成本,提升AI模型(如图像分类、目标检测)的推理速度,是Pascal架构在AI领域的关键特性之一。INT8 支持是对图中核心执行单元(SP)的功能扩展,而非独立标注的组件,通过硬件优化让现有单元具备低精度计算能力。简单来说,CC 6.1 的 INT8 是 NVIDIA 在 Pascal 架构显卡中加入的专用硬件电路,专门用来极速处理一种叫“8位整数”的简单计算,让AI推理(使用模型)的速度飙升,功耗大降。
PASCAL/VOLTA 架构
 FP16 @ 2x SP rate(16位浮点数),GPU在执行一种叫“半精度浮点数”的简单计算时,其计算单元的吞吐速度是执行标准“单精度浮点数”计算的2倍。(一个SP可以同时处理两个FP16的数据)
FP16 @ 2x SP rate(16位浮点数),GPU在执行一种叫“半精度浮点数”的简单计算时,其计算单元的吞吐速度是执行标准“单精度浮点数”计算的2倍。(一个SP可以同时处理两个FP16的数据)
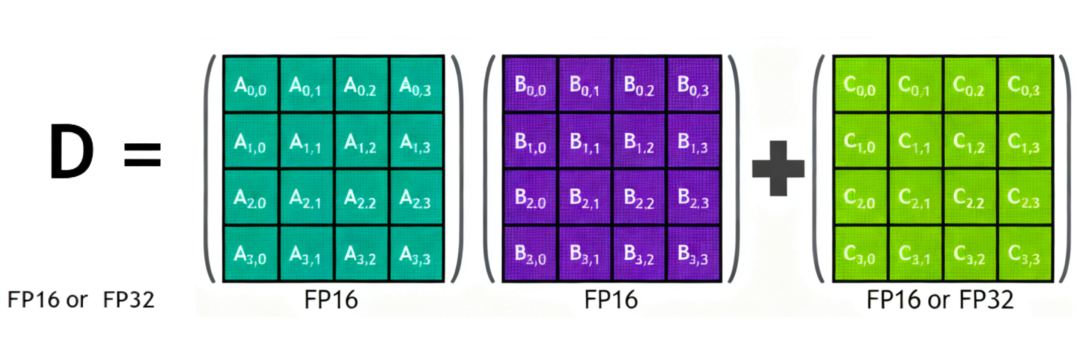
cc7.0: TensorCore是 NVIDIA 在 Volta 架构中引入的专用硬件电路,能一次性完成一个 4x4 矩阵的混合精度(FP16)乘加运算,为深度学习训练和推理提供了前所未有的加速。
 Volta adds separate int32 units:在 Volta 架构之前,GPU 中的 INT32 计算和 FP32 计算共享同一组计算单元,它们无法在同一时钟周期内同时工作。而 Volta 为 INT32 提供了独立的、并行的执行单元,使得整数和浮点计算可以同时进行,极大地提高了计算资源的利用率和吞吐量。
Volta adds separate int32 units:在 Volta 架构之前,GPU 中的 INT32 计算和 FP32 计算共享同一组计算单元,它们无法在同一时钟周期内同时工作。而 Volta 为 INT32 提供了独立的、并行的执行单元,使得整数和浮点计算可以同时进行,极大地提高了计算资源的利用率和吞吐量。
运行模式
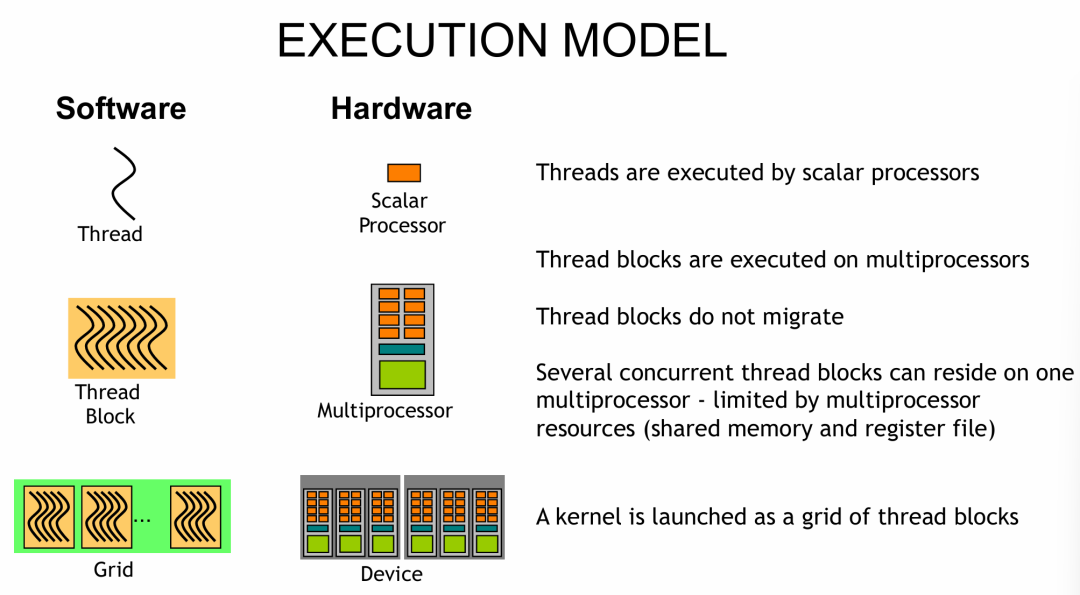
根据前面的内容,我们可以将其运行模型中的软件与硬件结合去理解(下图只是简单的对应示意,并不绝对精确):
 注意:
注意:
- 线程(Thread) 和 SP 单元对应(此对应并不完全准确,仅作描述演示。因为一个线程可能对应多种操作,如DP或TensorCore计算,并不一定是FP32数据计算)。
- 线程块(Thread Block) 在 SM 上运行,一个 Block 中的所有线程分布在同一个 SM 上(因此只有 Block 内的线程才能使用共享内存)。一个 SM 上可以驻留多个线程块,具体能驻留多少个取决于不同型号 SM 的资源多少(寄存器、共享内存和 L1 缓存)。一旦 kernal 函数运行中的线程块被分配到某一个 SM,直到该函数退出,这个线程块才会从该 SM 中释放。
- 网格(Grid) 对应整个 GPU(可以跨越多GPU),kernal 函数通过启动 Grid 里的线程块进行运算。
WRAPS
GPU中的指令运行,是以“Wrap”(线程束)为基本单位进行的。一个线程块中的线程会被每32个划分为一组去运行指令。例如,63 个线程会分成 1 个完整 warp(32 线程)+ 1 个填充 warp(31 个实际线程 + 1 个虚拟线程),每个时钟周期内,一个 Warp(32 个线程)运行相同的指令。WARP 简介如下图:
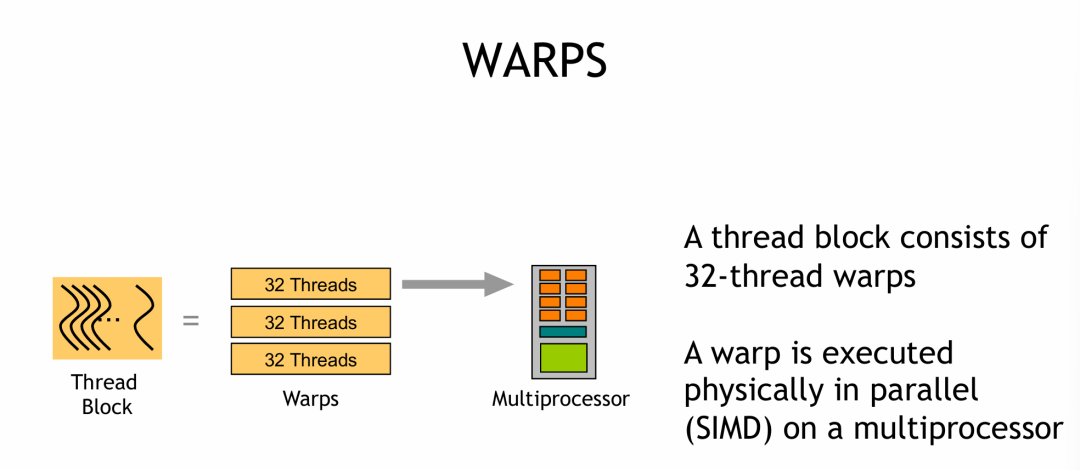
- 一个 Block 内,每32个线程构成一个 wrap。
- SIMD:一条指令同时对多个数据元素执行相同操作,以此实现数据级并行。
- 一个线程内的指令是串行运行的。
- CUDA中线程的指令是按顺序发射执行的(按照 wrap),这是硬件调度的基本逻辑。例如,我们发出A、B、C指令,对于一个线程来讲它肯定是先运行A,然后B,最后C,是有序的。
- 当线程执行某条指令时,若操作数未就绪(比如等待内存读取结果、依赖前序计算的输出),该线程会进入停滞(stall)状态。如果不通过快速切换线程束(warp)来隐藏延迟,当前停滞的线程束会一直处于等待状态,直到其依赖的操作数就绪。单纯的内存读取操作本身不会直接导致线程停滞,但后续依赖该内存数据的指令会因操作数未就绪而停滞。
- 内存读取(Load 指令)是 “异步非阻塞” 的:线程发出 Load 指令后,不需要等待数据实际返回,就能立即执行后续的、不依赖该内存数据的指令。
- 通过线程切换隐藏延迟:GPU 通过快速切换线程束(warp)来 “隐藏” 延迟(比如内存访问、算术运算的等待时间)。当一个线程束因延迟停滞时,SM(流式多处理器)会立即调度另一个就绪的线程束执行,从而让硬件始终保持忙碌。
- 延迟可理解为执行某一个操作所需时间,GPU架构通常用时钟周期来描述(本质是芯片核心振荡器完成一次高低电平切换的时间,时钟周期 = 1 / 主频)。
- 全局内存(GMEM)延迟 > 100 个时钟周期,是 GPU 中延迟最高的操作之一。
- 算术运算延迟(加减等操作) < 100 个时钟周期 (不同架构/设计有差异),比全局内存访问快得多。
- 计算性能优化需要足够多的线程来隐藏延迟。只有当线程数量足够大时,SM 才能通过持续切换线程束,将内存访问、算术运算的延迟掩盖掉,从而最大化 GPU 的并行计算效率。
隐藏延迟
隐藏全局内存读入延迟例子
CUDA C 源代码:
int idx = threadIdx.x + blockDim.x * blockIdx.x;
c[idx] = a[idx] * b[idx];
GPU汇编(SASS):
I0: LD R0, a[idx];
I1: LD R1, b[idx];
I2: MPY R2, R0, R1
LD:将全局内存中 a[idx] 的数据加载到寄存器 R0。LD:将全局内存中 b[idx] 的数据加载到寄存器 R1。MPY:对寄存器 R0 和 R1 中的数据执行乘法,结果存入寄存器 R2。
SASS与 CUDA 代码的关系
- CUDA C++ → PTX:
nvcc 编译器先将 CUDA C 代码编译为 PTX 中间码。
- PTX → SASS:在程序运行时,NVIDIA 的运行时环境(CUDA Runtime)会将 PTX 中间码即时编译(JIT)为对应 GPU 架构的 SASS 机器码,确保指令能被当前硬件执行。
| 层级 |
描述 |
示例 |
| CUDA C 代码 |
开发者编写的并行代码 |
c[idx] = a[idx] * b[idx]; |
| PTX 中间码 |
虚拟 GPU 指令集(可移植) |
mul.f32 %r2, %r0, %r1; |
| SASS 机器码 |
硬件实际执行的指令 |
MPY R2, R0, R1 |
例子图解
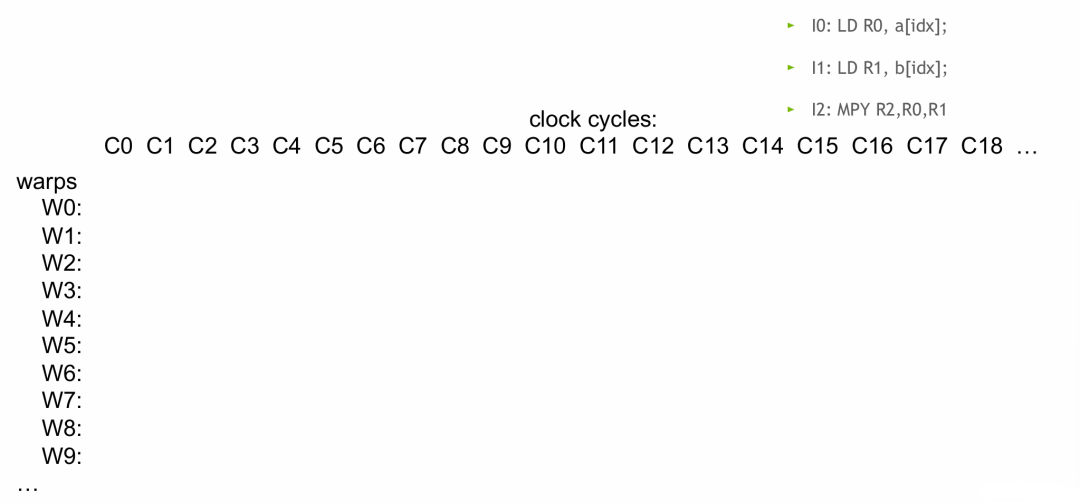
- 纵轴 为 wrap,因为指令是按照 wrap 一组一组运行的。
- 横轴 为时钟周期。
- 为了隐藏延迟,我们需要足够多的线程,这样 SM 才能通过持续切换线程束(wrap),将内存访问、算术运算的延迟掩盖掉,从而最大化 GPU 的并行计算效率。
开始运行
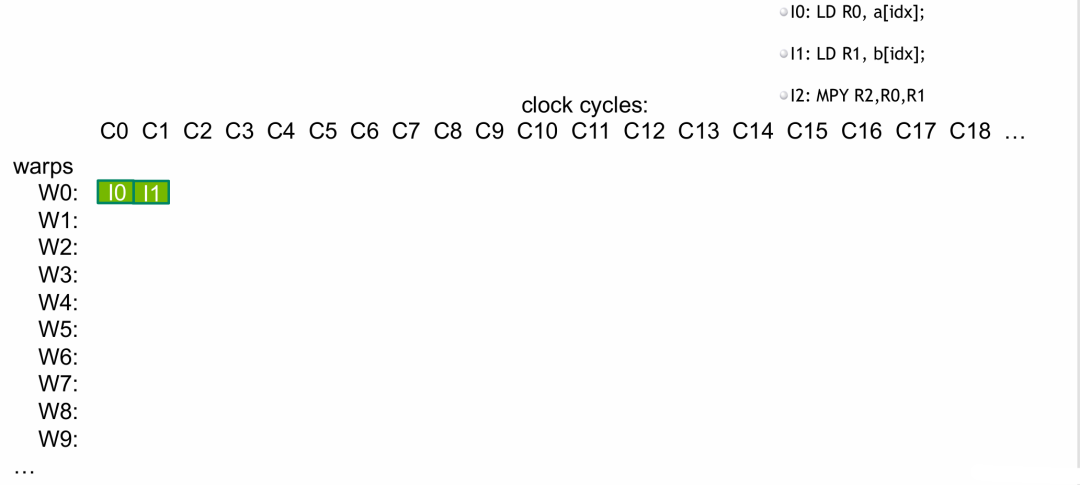
- 读入
a[idx] 和 b[idx],这个操作是异步非阻塞的,指令可以正常发射。
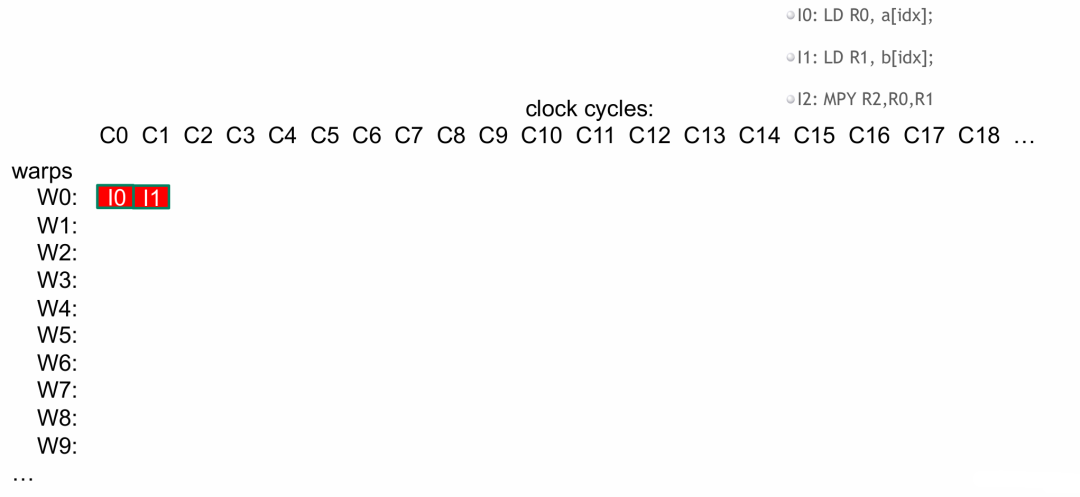
- 当要运行
I2 (MPY) 命令时,所需的 a[idx] 和 b[idx] 数据由于读入延迟,在当前时钟周期内并未写入寄存器,wrap0 触发停滞等待。
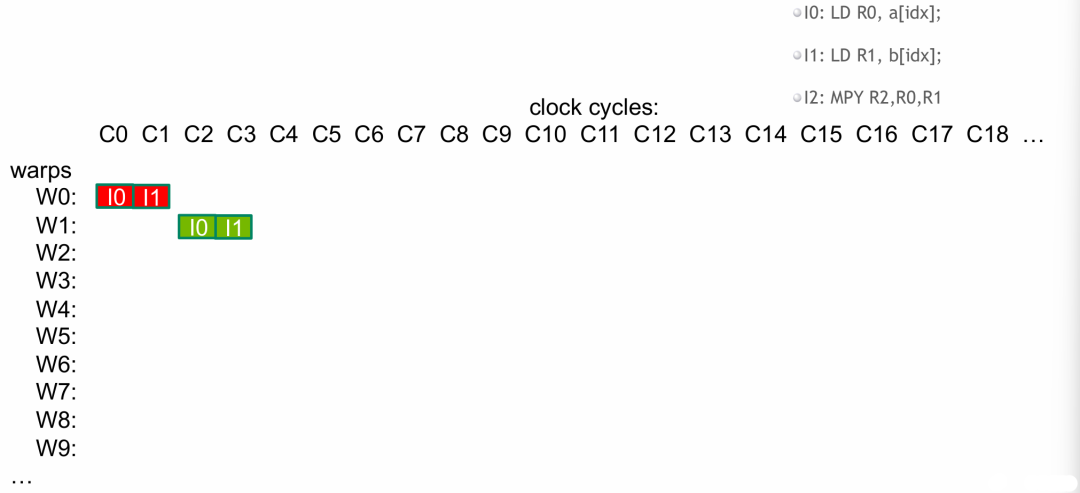
- wrap 调度器此时切换线程束(wrap),切换到 wrap1 再次依次运行
I0、I1、I2。

- 同理,当 wrap1 要运行
I2 命令时,也会因数据未就绪而停滞。wrap 调度器不断切换线程束。
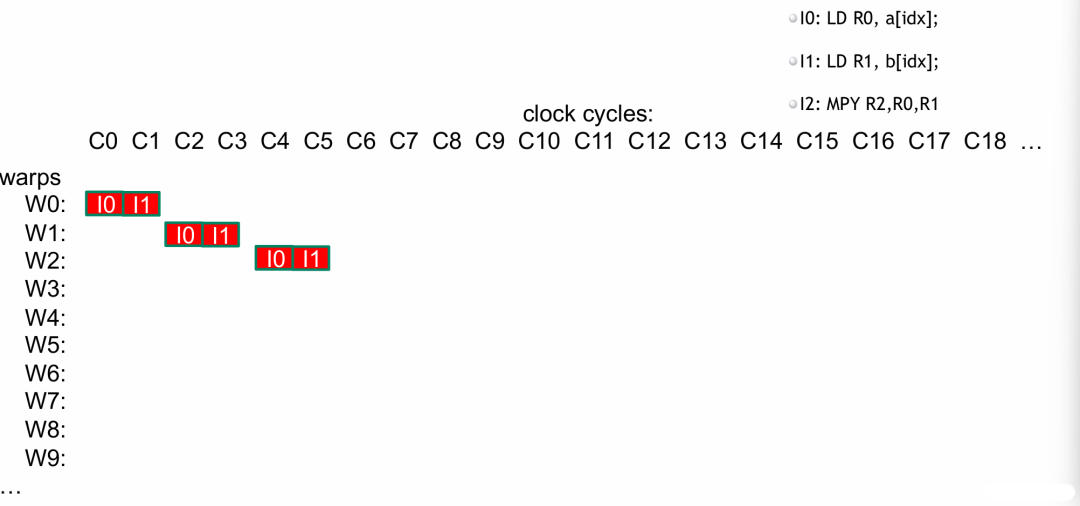
- 一旦某个 wrap 触发停滞,就切换到其他就绪的 wrap,确保每个时钟周期 SM 都在运行指令。
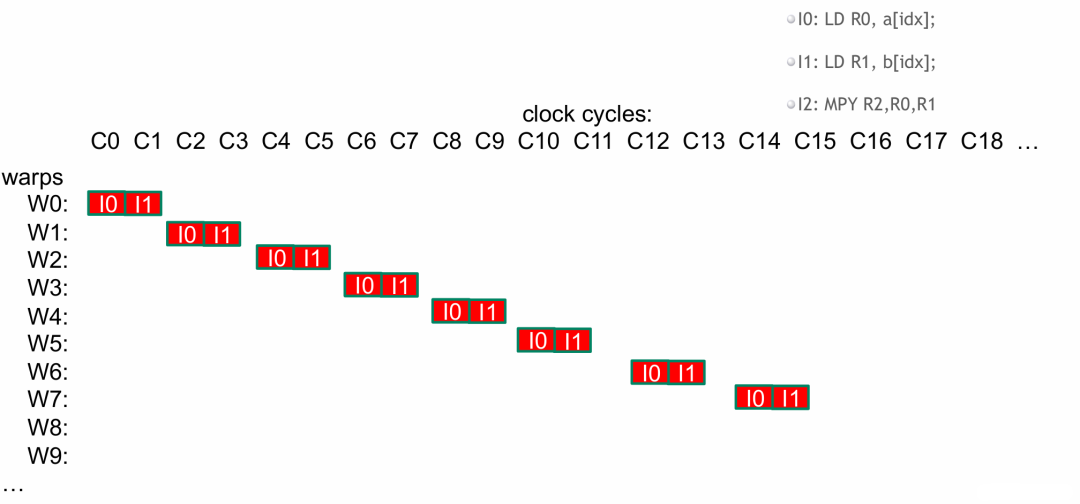
- 当我们第一个 wrap 的全局内存数据读入完成(延迟满足了),我们就在 wrap0 中运行
I2 了。
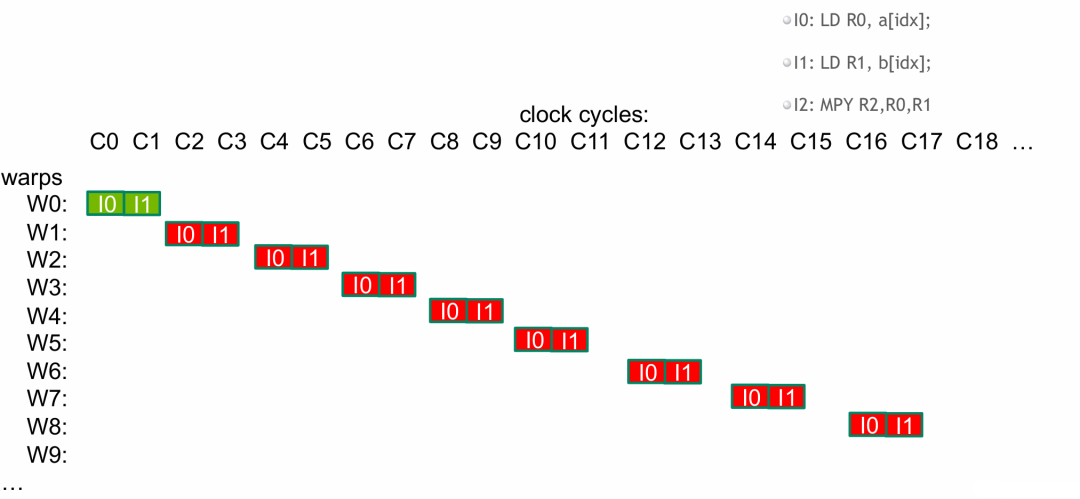
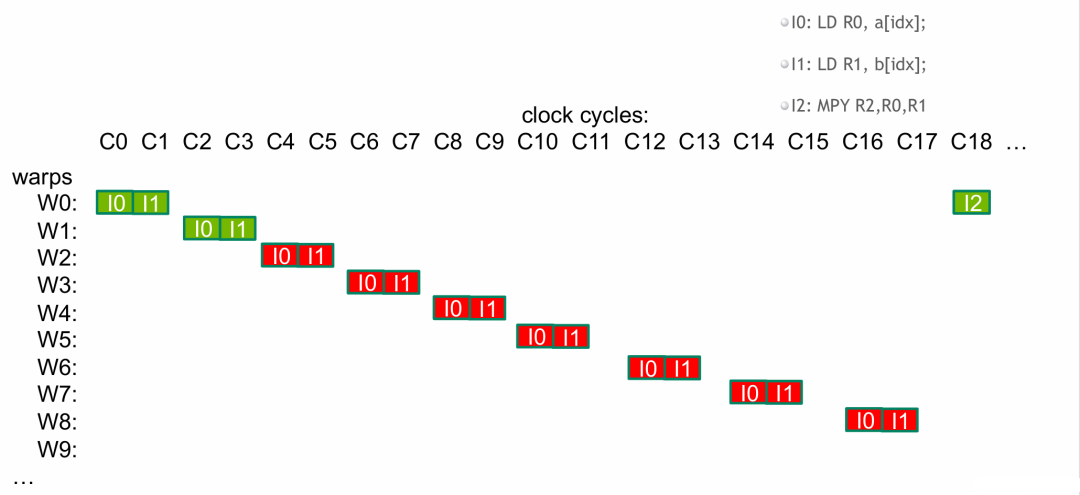
- 同理,依次切换 wrap 运行
I2。因为 wrap0 最先开始读入,一旦它完成了读入,后面的 wrap 也一定完成了读入。
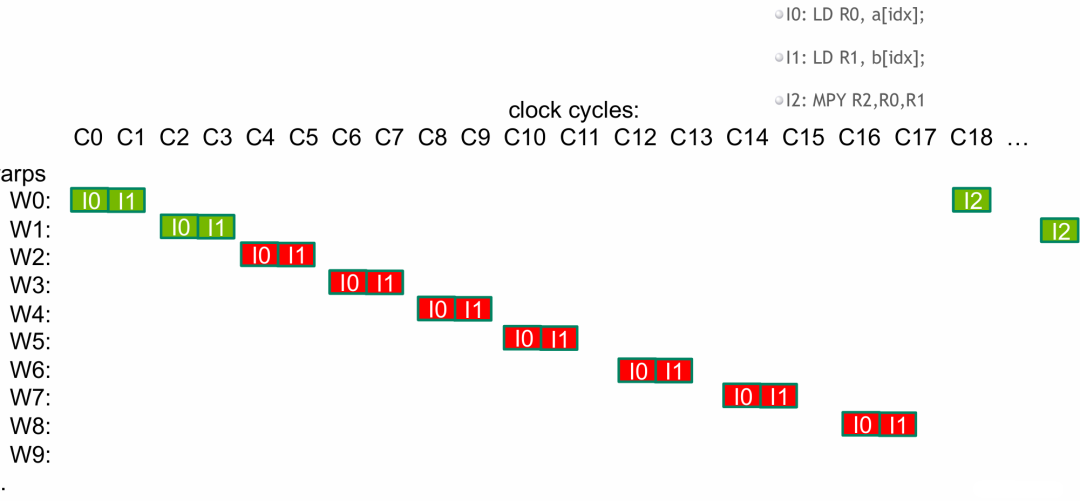
结论:我们用足够多的 wrap 来隐藏读入数据所需的时间(延迟),确保了 GPU 一直在运行。但是一个 SM 上能驻留的 wrap 数量是有限制的,一般架构一个 SM 可运行 64 或 32 个 wrap。
- 为了有效隐藏延迟,我们通常要开启尽可能多的 wrap。假设一个 SM 上能驻留 64 个 wrap,一个 wrap 有 32 个线程,那么就需要
64 * 32 = 2048 个线程来饱和一个 SM。如果有 2 个 SM,则需要 2 * 64 * 32 = 4096 个线程。这样就能尽可能用更多的 wrap 来隐藏延迟。
- L1/L2 缓存可以减少全局内存的读入时间,即减小延迟。
- 如果我们想让多个 wrap 在同一时钟周期同时运行
I0、I1、I2,就需要把这些 wrap 分配给不同的 warp 调度器。
算术运算延迟
- 隐藏算术运算延迟一般需要每个 SM 上驻留约 10 个 wrap(320 个线程)。
- 如果两个指令之间没有相互依赖,wrap 调度器可以一次接受两个指令(双发射),通过连续发射/并行执行(流水线重叠),在等待前一条指令延迟的同时执行后一条,从而隐藏延迟(注意:一个线程内的指令运行依旧是串行的)。与上述 wrap 切换隐藏延迟类似,区别在于通过指令级并行来利用硬件。
- GPU 指令流水线是分段并行的,GPU 的每条指令执行都要经过多个流水线阶段(如 “取指→译码→发射→执行→写回”),每个阶段由独立的硬件单元负责。
- 假设 warp 中有两条无依赖指令:
指令A: a + b → r1(执行延迟 4 个时钟周期)、指令B: c * d → r2(执行延迟 4 个时钟周期)。以下是对比:
| 时钟周期 |
有依赖(B 依赖 r1) |
无依赖(B 不依赖 r1) |
| 1 |
发射指令A,进入执行阶段 |
发射指令A,进入执行阶段 |
| 2 |
等待指令A结果(空闲) |
发射指令B,进入执行阶段 |
| 3 |
等待指令A结果(空闲) |
指令A执行中,指令B执行中 |
| 4 |
等待指令A结果(空闲) |
指令A执行中,指令B执行中 |
| 5 |
指令A完成,发射指令B |
指令A完成,指令B执行中 |
| 6 |
指令B执行中 |
指令B完成 |
| 7 |
指令B执行中 |
- |
| 8 |
指令B完成 |
- |
最大化全局内存吞吐量
- 优化访问模式和传输数据大小:全局内存吞吐量取决于数据访问模式(线程如何读取/写入显存)和数据所占字节大小(如 float 是 4 字节,float2 是 8 字节):
- 访问模式优化:如果线程是连续、对齐地访问显存(如数组顺序读取),吞吐量会很高;若访问是随机、分散的,吞吐量会大幅下降。
- 传输数据大小优化:由于显存总线位宽固定,单次操作能传输的字节数有限。使用更大的字长意味着用更少的操作次数即可传输等量数据,从而提升有效吞吐量。例如,传输同样 1024 个字节,用 float2(8字节)所需的事务数仅为 float(4字节)的一半。单次内存操作能传输的数据越多,吞吐量也会相应提升。
- 饱和总线:由于内存延迟很高,只有拥有足够多的并发内存操作,才能在等待某个请求返回时处理其他请求,确保内存控制器和总线持续忙碌,避免空闲。这需要让足够多的内存读写请求同时处于传输状态(即保持内存一直处于全速工作状态)。
- 线程内并发:单个线程发起多个无依赖的加载/存储操作。
- 线程间并发:大量线程(特别是整个 Warp)同时发起内存请求。
- 对一个包含 64M 元素的数组执行 “加载→自增→存储” 操作(每个线程需完成 “加载” 和 “存储” 两次内存访问)。加载和存储是依赖操作(存储需等待加载的结果),因此每个线程实际一次只能发起 1 次访问(加载或存储),而非同时发起两次。由性能分析可知,调用线程越多吞吐量越大;而一次处理的数据量越大(如使用 float2),使用更少的线程就能更快达到总线饱和。
个人理解
- GPU 运行时的线程并不是一一对应到一个执行单元(比如 SP),而是通过 warp 调度器采用发射端口对应到不同的执行单元运行。所以线程更像是一个任务,可以由任何合适的执行单元来完成。虽然一个 warp 能同时接受多个指令(双发射),但一个线程内每个时钟周期仍然是串行运行一条指令。例如,两个非依赖命令发出后,在一个线程内,硬件通过流水线或 warp 切换来执行,感觉上类似于并发。
- 我感觉 warp 对应的应该是指令发射的集合,并未严格绑定到某个运行单元。在一个时钟周期内,一个线程最多只能执行一条指令,因此只能使用一个执行单元。
总结
使用足够多的线程保证GPU饱和工作
为了让 GPU 的计算单元和内存单元不闲置,需要足够多的线程来隐藏延迟、饱和带宽:
- 每个 SM 通常需要 512 个以上的线程,目标是接近 2048 个线程(即 SM 的最大线程占用率)。线程越多,GPU 越容易通过多 warp 调度隐藏延迟,保持计算/内存单元的忙碌。
- 如果每个线程仅处理一个单精度浮点(fp32)元素,则需要更多的线程来饱和资源。
线程块配置
- 线程块大小:每个线程块的线程数应是 warp 大小(32)的整数倍。因为 GPU 以 warp(32 个线程)为单位调度,若块大小不是 32 的倍数,会导致 warp 内部分线程闲置,占用执行单元却无事可做,浪费资源。
- 并发线程块数量:一个 SM 可同时并发执行至少 16 个线程块(Maxwell/Pascal/Volta 架构可达 32 个)。更多块意味着更高的资源利用率(SM上驻留的线程块最大个数与SM计算资源有关)。
- 大小选择:
- 线程块太小(如小于 32 线程)会导致 SM 无法充分利用,占用率低;
- 线程块太大(如超过 1024 线程)会降低调度灵活性,且可能超出 SM 资源限制。
- SM资源限制:SM上最大驻留线程块(block)数量是有限制的(与共享内存、寄存器数量有关),这也会影响占用率。例如,原来一个线程块有 64 个线程,SM 最大驻留块数是 16 个,那么最大驻留线程为
16 * 64 = 1024。如果将线程块大小改为 32 个线程,那么最大驻留线程变为 16 * 32 = 512,可调度的线程数减少了。
- 经验值:通常可选择 128-256 线程/块,但最终需根据具体应用场景调整(如内存密集型任务可能需要更小的块,计算密集型可适当增大)。
GPU占用率
占用率是衡量 SM(流式多处理器)中实际负载与可达到的峰值负载的比值,反映了 SM 的资源利用效率。
- CUDA 提供了占用率计算器电子表格,帮助开发者评估和优化占用率。
- 可达到的占用率受多种限制因素影响,主要包括:
- 每个线程的寄存器使用量(可通过性能分析器或编译时获取);
- 每个线程块的线程数;
- 共享内存的使用量。
GPU本质
GPU 是大规模线程并行、擅长通过并行掩盖延迟的计算设备。
内核启动配置
- 每个 SM 需启动足够多的线程,以隐藏计算或内存操作的延迟;
- 需启动足够多的线程块,让整个 GPU 的资源被充分利用。
优化方法
采用分析/性能分析驱动的优化策略,例如通过 Nsight Compute 等工具,可以查看计算子系统或内存子系统是否已达到性能饱和,从而进行针对性优化。 |  发表于 2025-12-9 02:14:30
|
查看: 277|
回复: 0
发表于 2025-12-9 02:14:30
|
查看: 277|
回复: 0
