你可能见过这样一类人:他们工作稳定细致,把特定流程背得滚瓜烂熟,那套方法也曾为他们带来过成效与成就感。然而,当环境改变、规则重构、新变量不断涌入时,他们下意识拿起的还是那套旧解法。相比于停下脚步重新审视框架的适用性,他们总是更用力地去打磨自己熟悉的流程。
在家庭教育中也能观察到类似场景:父母凭借旧时代的学习方式实现了上升路径,便将其视为黄金标准,希望原封不动地复制给下一代,却忽略了新环境下的竞争结构与选择空间。
这些人往往是特定“题型”的优等生。正是因为经验曾带来过回报,他们更容易形成路径依赖,把曾经的正确答案背得烂熟。可当游戏规则悄然变化,那些不再奏效的经验反而成了决策的干扰项。
这种现象不仅是个体的困局。企业依赖旧的商业模式难以转型,管理者沿用过时的激励机制管理新世代,品牌用上一代的逻辑去猜测新消费群体…… 这背后都指向一种认知上的过拟合。我们在熟悉问题上训练得太“好”,但精进的往往不是对底层规律的理解,而是某个具体的做法或流程。结果就是,当题型变了、系统重构、变量更迭,大脑仍在不假思索地套用旧答案。
成功经验是如何演化为过拟合的?
为什么越是过去做得出色的人,反而越容易在变化中失速?
在机器学习中,有一个核心概念叫做 过拟合(Overfitting)。它描述的是一种“学得太好反而失效”的现象:模型在训练集上表现堪称完美,却在面对新数据时一败涂地。原因在于,它并非学到了通用规律,而是记住了过去数据中的特定细节与噪声。
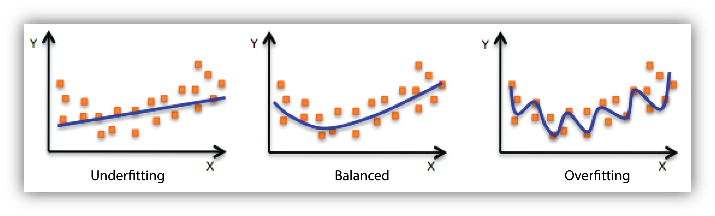
如上图所示:
- 左图是欠拟合:模型太简单,浅尝辄止,只抓到了皮毛而错过了关键结构。
- 中间是恰到好处的平衡:模型既理解了数据的整体趋势,也不过度追逐每一个噪声点。这就像我们理性中的认知状态:能抽象出底层结构,同时保留对变化的弹性。
- 右图就是过拟合:模型看似学得非常努力,把每一个数据点都照顾到了,但它其实把数据中的噪声也当成了规律来学习。这就像在某一类问题上训练得过于精细,以至于一旦题型稍有变化,就无法应对。因为学到的不是原理,而是背熟了“答案”。
这也是我们每个人在成长中极容易陷入的陷阱。凭借某一套方法一路披荆斩棘,建立起优势与自信,于是便自然而然地将其奉为普遍适用的真理。
我们为何会不自觉地陷入这种模式?
1. 对成功的错误归因
当使用某种方法获得过成功时,我们下意识会将功劳归于方法本身,却忽略了一个关键事实:是方法与特定场景之间的匹配,才让它奏效。即便当场景变化,我们也很少会立刻质疑方法是否过时,而更倾向于怀疑自己是不是哪里没做好,执行得还不够彻底。
2. 认知的自我强化机制
我们的大脑远没有想象中开放。认知科学中的“预测编码”理论指出,大脑并非完全开放地理解现实,而是会基于既往经验预判出一个世界的“模样”,再用感官去验证这个猜测。只要现实没有明显违背预判,我们就会默认它是正确的。久而久之,我们不仅会越来越相信自己的经验,还会下意识地屏蔽可能动摇它的证据。
容易陷入过拟合而停滞不前的人,通常有几个共同点:
1. 过度依赖即时反馈
他们缺乏长期意义的标尺,判断一件事值不值得做,更多看当下有没有反馈,能不能立即见效。只要眼前的数据好看、获得认可,就觉得方向对了,哪怕这件事早已是边际效益极低的重复动作。一旦短期内看不到回报,就会焦虑并迅速放弃,很难撑过那些看不到即时结果但价值巨大的“深水区”。
2. 极度追求确定性
他们偏爱标准答案和清晰流程,对模糊性和不确定性感到本能的不安。只有当任务清晰、路径熟悉,才能获得掌控感。这让他们在面对复杂新问题时,更倾向于从过去寻找“参考答案”,而不是搭建新模型。
3. 缺乏迁移能力
这类人往往擅长记住“怎么做”,却很难跳出具体案例,从中抽取出底层逻辑,并将其迁移到新的情境中。
局部最优陷阱:每一步都极致优化,最后却走向死路?
局部最优 vs. 全局最优
想象你站在一片山地中,目标是登上整片区域的最高峰。你选择了一个看似聪明的策略:每一步都往上走。刚开始一切顺利,视野渐渐开阔,你以为离目标越来越近。直到某一刻,你发现四周全是下坡路——原来你站在了一座小山头上。而真正的高峰,藏在山谷的另一侧。
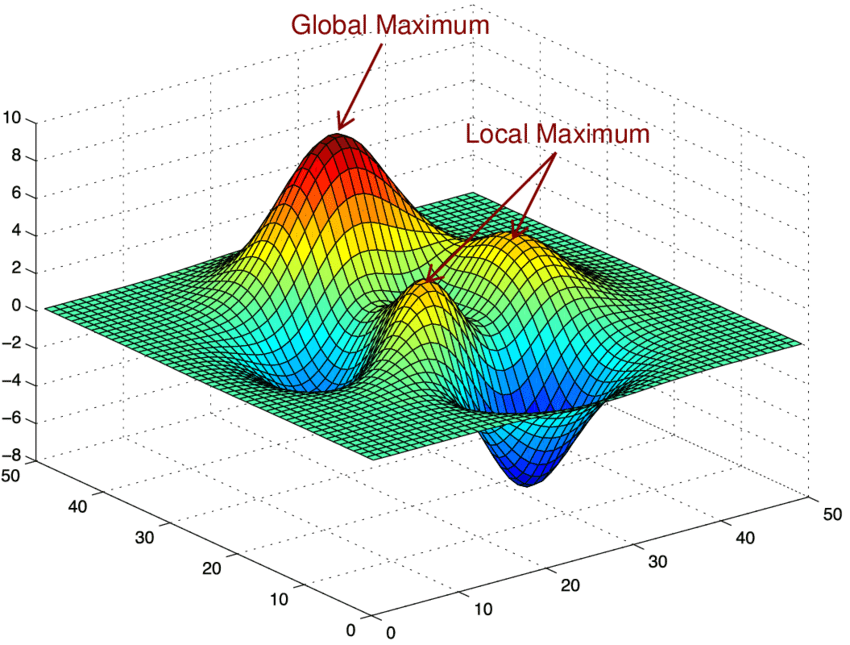
回头看,每一步选择似乎都没错,但向前却已无路可走。这就是经典的“爬山”算法会掉入的局部最优陷阱。在复杂、非线性的系统中,它的局限性暴露无遗:不考虑全局路径结构,不允许暂时的退步,也不具备探测远方高峰的能力。最终,它很可能卡在一个局部最优点上,无法跳出。
现实生活也是如此:我们每一步都希望在当下获得提升和快速反馈,但要想触及真正的回报转折点,往往需要承受一段充满探索、混乱、甚至看似“下行”的过程。

诺基亚:一步步赢得当下,最后输掉未来
诺基亚曾是功能机时代的绝对王者。在2000年代中期,其高管层已清楚意识到智能手机将颠覆行业,但他们的选择却是继续优化已有的Symbian系统,强化现有产品线,提升利润效率。
在当时看来,每一步都无比正确:节省成本、扩大市场份额、维持供应链效率。但这正是一种典型的局部最优困境:每次决策都以当下最优为标准,却一步步导致最终丧失了适应智能时代的弹性与能力。
对比同时期的苹果,其路线几乎是反向的:他们砍掉了当时最赚钱的iPod mini产品线,推翻了iPod固有的操作逻辑,重构了多点触控交互,甚至从构建封闭系统转向开放的App Store生态。每一步在当时看来都像是在拆掉自己的既有优势,却为未来十年的增长埋下了全新的曲线。
敢下坡,才可能换座山。
我们在个人决策中也经常无意识地选择通向局部最优的路径:每一次考虑职业方向,都优先选择当前最容易转换成功的岗位,于是始终在熟悉的领域打转;每次学习新技能,都挑上手最快、反馈最及时的。在每一个选择节点上,我们只关心哪个选项回报最快、最确定,却回避了更根本的发问:这一步,能否让我的下一个选择更宽阔、更自由? 越是害怕走弯路,反而越容易卡在一座“看起来还不错”的小山头上。
为何“局部最优”如此难以跳出?
路径依赖带来的结构性锁定
很多人以为,做选择的是自己。但到了某一阶段你会发现:你并非完全自主地选择路径,而是反过来被路径所塑造。当一个系统朝某个方向积累得足够多,就会产生强大的自我强化效应:越往前走,越难调头;越表现得优秀,越难逃脱原位。看似自主,实则早已被生态、反馈和身份标签所绑定。
例如,一个操作系统一旦用户量足够大、生态成型,开发者就“只能”为它开发应用;一个城市一旦确立了某种交通模式,想要进行基础设施转型也需要付出巨大代价;企业中日益复杂的数据架构,最终可能不是为了效率而存在,而是为了系统不彻底崩坏而不得不持续运转。
结构锁定的可怕之处在于,它会让你越来越无法忍受 “短期无反馈” 。如果你曾经在某条路径上收获过丰厚回报,建立起强烈的成就感,那么当你站在一条潜在更优但短期内看不到成功的道路上时,会本能地觉得“划不来”。哪怕是学习新技能、写作或探索新职业方向,你也会本能地反问:“做这个能立刻带来什么?” 如果答案不是立刻可见的回报,就很难产生行动的动力。
同样,系统也会反过来强化你的身份标签。你在一个领域走得越深,系统对你的定义就越强:“报表专家”、“XX技术高手”…… 这些标签一旦形成,你可能会开始为他人的期望服务,而非为真实的自我探索服务。
此外,我们对 “潜在失去”的感知,也远远大于对“可能获得”的渴望。你可能已经意识到当前路径的局限,但脑海中会不断预演:如果尝试新方向失败,会不会连现有的都保不住?在正反馈依赖、身份标签强化和风险厌恶的共同作用下,你已很难自主选择跳出,而是整个系统在“强迫”你持续选择当下最优。于是,你会一直选择继续做自己最擅长的事,即便在这条路上的投入,其边际价值正在逐渐递减。
跳出锁死的方法:培养泛化能力
在机器学习中,与过拟合相对的概念是泛化能力(Generalization)。它指的是一个优秀的模型,不仅能在训练集上表现良好,面对未知的新数据时也依然稳定有效。
关键在于,它不是死记硬背特定的套路,而是真正学到了普适的规律。对人而言,要跳出路径锁死、避免陷入局部最优,不能靠背熟答案,而是必须锻炼自身的泛化能力,使得从旧经验中抽象出的底层方法,能够迁移到全新的环境中依然奏效。
以下是三种从局部跳向全局的策略:
1. 引入新变量,打破惯性
在“模拟退火”算法中,为了跳出局部最优,系统会主动引入随机扰动,跳出原有轨迹。生活中,我们同样需要主动创造新的可能性。例如:
- 每月尝试一件完全不在舒适区的事,比如与跨领域的人深度对话、探索一项新技能、尝试一个小副业。
- 打破一些固定习惯,比如换一条上班路线、参加一场陌生主题的聚会、在不同的平台尝试表达自己。
2. 从终点反推,重新评估路径
定期审视并更新你的长期目标(例如是追求财富、创造力、高效能还是自由)。学会从你期望的“终点”反推,回看当前所在的位置。只有不断对着“整体地图”审视自己的行进轨迹,才能识别出你是否正卡在一个看起来还不错,实则限制了视野的小高地上。
3. 培养抽象与迁移能力
跳出局部最优的关键是提升经验的可迁移性。例如:
- 做科研时训练的逻辑思辨和严谨论证能力,在商业环境中同样能用于谈判和复杂决策。
- 学习一门外语过程中掌握的记忆方法和语义理解系统,也能有效迁移到学习其他语言上。
- 在健身中养成的“设定目标-分解步骤-获取反馈”的机制,同样适用于备考、学习新技能等需要自律的长期任务。
我们常常被那些“看起来还不错”的路径所困,在老路上不断“过拟合”。因为它们太容易带来熟悉的满足感,以至于我们慢慢失去了对“更好可能”的追问。跳出局部最优,意味着要学会不断刷新自己对“更好”的定义,并且能够允许自己在探索期“掉线”,在看不到即时反馈的道路上坚定穿行。

有时,转弯并非离开,而是为了更好地抵达。在技术学习和个人成长的路上,保持开放心态,勇于将底层规律应用于新场景,是避免认知过拟合、持续突破自我的关键。更多关于思维模型与学习方法的探讨,欢迎在云栈社区交流分享。
参考资料:
[1] Predictive coding in the brain: Functional implications. Friston, K. Nature Reviews Neuroscience (2005). https://www.nature.com/articles/nrn1530
[2] Path dependence, lock-in, and history. David, P. A. Journal of Economic Perspectives (1985). https://www.jstor.org/stable/2138761
[3] When good performance backfires: Success-induced rigidity in strategic decision making. Audia, G., Locke, E. & Smith, K. https://www.sciencedirect.com/science/article/abs/pii/S0749597808000573
[4] The Optimization Paradox: Why better solutions often require worse decisions. Medium – Towards Data Science. https://medium.com/towards-data-science/the-optimization-paradox-6c158f40de10
 发表于 2026-3-15 05:01:52
|
查看: 209|
回复: 0
发表于 2026-3-15 05:01:52
|
查看: 209|
回复: 0
