
如何客观衡量我们离通用人工智能(AGI)还有多远?当前大模型在某些任务上表现惊艳,但它们真的具备通用智能吗?Google DeepMind 发布的最新研究论文《Measuring Progress Toward AGI: A Cognitive Framework》试图为这个难题提供一个系统性的解决方案。
论文地址:https://storage.googleapis.com/deepmind-media/DeepMind.com/Blog/measuring-progress-toward-agi/measuring-progress-toward-agi-a-cognitive-framework.pdf
这项研究的核心主张很明确:与其无休止地争论AGI的定义,不如先建立一个科学、可操作的评估体系。为此,团队从认知科学中汲取灵感,将通用智能拆解为10项关键的认知能力,并设计了一套三阶段的评估协议。更引人注目的是,DeepMind 联合 Kaggle 平台发起了总奖金高达20万美元的黑客松竞赛,邀请全球研究者和开发者共同创建高质量的评测基准。
从分级到度量:填补AGI路线图的空白
这并非 DeepMind 首次规划AGI的发展路径。早在2023年,同一团队就提出了著名的“AGI分级”框架,将AGI的发展划分为从“新兴”到“超人”的5个性能等级和6个自主性等级。
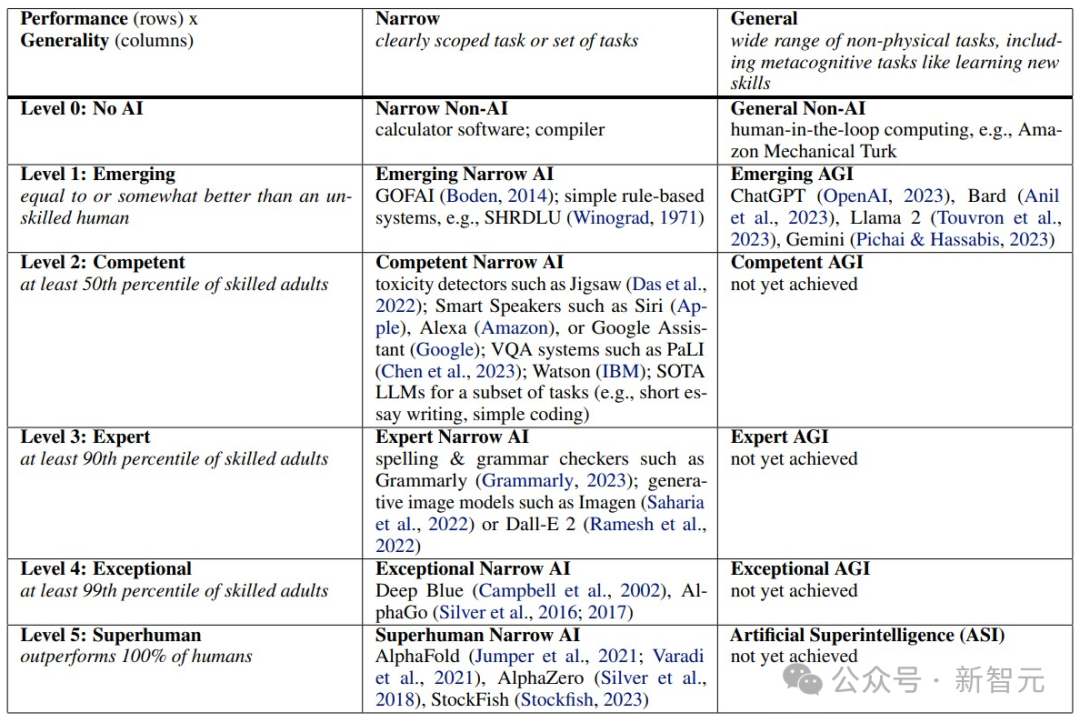
这个框架为行业提供了共同语言,类似于自动驾驶的L1-L5分级。但它留下了一个关键问题:如何具体测量每个等级?最新论文正是为了填补这一空白,从“画台阶”转向“造尺子”。
十维认知地图:解构通用智能的基石
新框架的核心是一套“认知分类法”,它将实现AGI所需的核心能力归纳为10个维度。这源于对人类认知过程的深入研究,涵盖了心理学、神经科学等多个领域的成果。
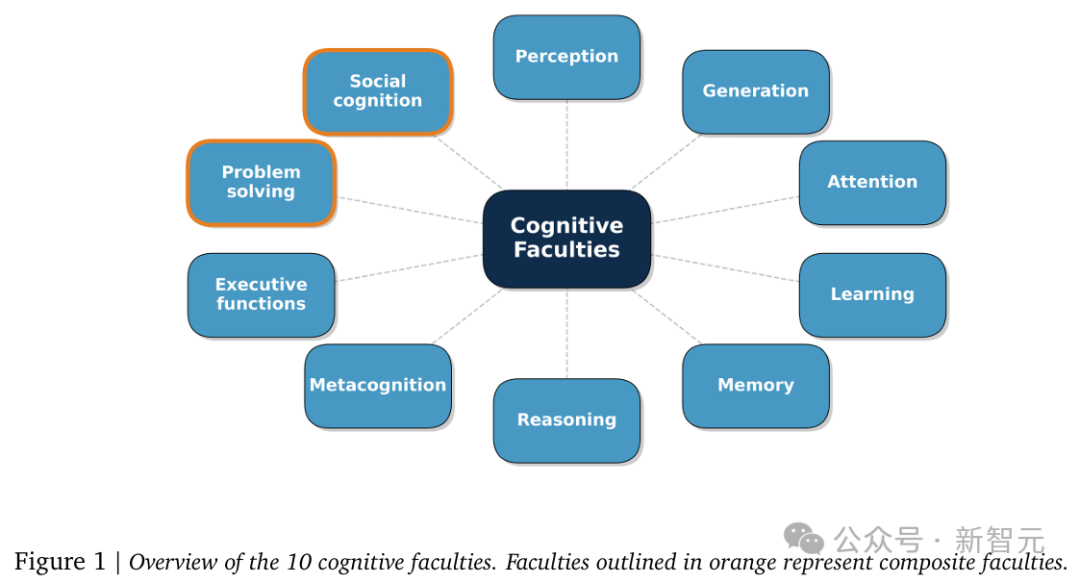
这10项能力包括8种基础能力和2种复合能力:
1. 感知(Perception)
从环境(视觉、听觉等)中提取和处理信息。值得注意的是,大语言模型对文本的“感知”是通过token化直接进行的,这是一种人类不具备的独特模态。
2. 生成(Generation)
产生文本、语音、动作等输出。其中,“思维生成”(产生内部推理链)与当前前沿模型的推理能力相关,但由于其内在性,评估极具挑战。
3. 注意力(Attention)
在信息过载时集中认知资源。关键在于平衡专注与警觉,既要完成任务,又不能忽略环境中的重要变化。
4. 学习(Learning)
通过经验获取新知识和技能。真正的AGI应能在部署后持续学习并保留知识,而非仅在训练或有限上下文内有效。
5. 记忆(Memory)
存储和检索信息。这不仅包括语义、情景等记忆类型,连“主动遗忘”过时或错误信息也被视为智能的重要组成部分。
6. 推理(Reasoning)
通过逻辑原则得出有效结论,包括演绎、归纳、类比等。单纯的模式匹配不能算作推理。
7. 元认知(Metacognition)
这项能力可能是区分高级系统的关键。它要求系统:
- 知道自己知道什么、不知道什么(元认知知识)。
- 能实时监测自己的认知状态,例如对答案的置信度(元认知监控)。
- 能根据监控调整策略,例如在犯错时切换方法(元认知控制)。
一个无法意识到自己在“胡说八道”的AI,其可靠性无从谈起。
8. 执行功能(Executive Functions)
支撑目标导向行为的高阶能力集合,包括规划、抑制控制、认知灵活性等。
9. 问题解决(Problem Solving)(复合能力)
综合运用上述多种能力来解决具体问题。
10. 社会认知(Social Cognition)(复合能力)
处理社会信息、理解他人意图并进行适当社交互动的能力。
DeepMind 的假设是,如果一个系统在这10个维度上存在明显短板,它就无法胜任大多数人类能完成的现实任务,也就称不上真正的“通用”智能。
三步评估法:绘制AI的认知雷达图
有了分类,如何评估?Google 提出了一个三阶段协议:
第一步:认知评测
让AI完成覆盖全部10种认知能力的专门任务。任务设计必须严谨:针对特定能力、使用保密题库、经第三方审计、难度有梯度、格式多样化。
第二步:收集人类基线
让大量具有代表性的人类在完全相同的条件(指令、格式、工具权限)下完成同一套测试,建立表现分布。
第三步:构建认知画像
将AI在每项能力上的得分与人类基线进行比较,计算其超过了多少百分比的人类。最终结果以一张10维雷达图呈现。
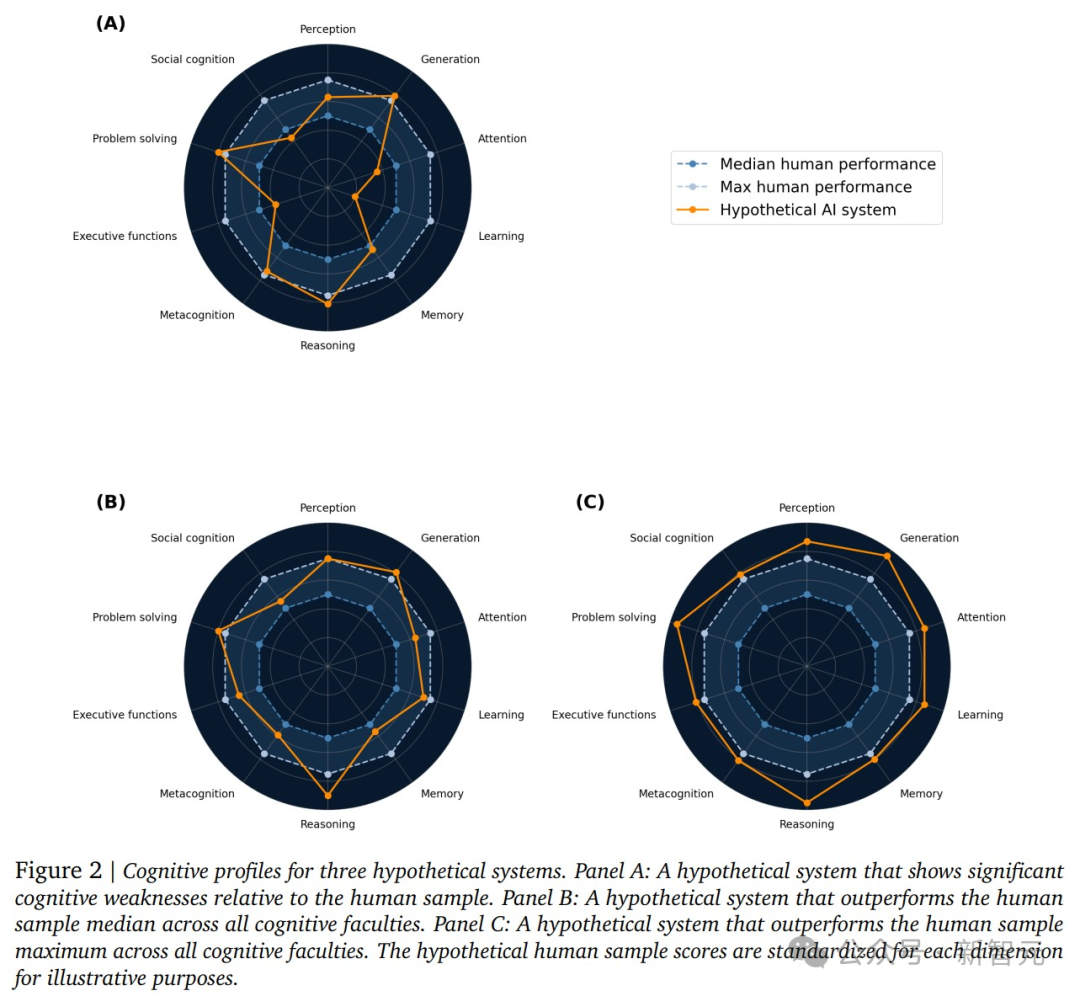
为什么必须用雷达图?因为当前AI的能力通常是“锯齿状”的——可能在逻辑推理上超越99%的人,却在社会认知上不如普通人。单一总分会掩盖这种致命的“偏科”,而雷达图能清晰揭示其真实的能力轮廓。上图展示了三种假想情况:A)部分能力低于人类中位数;B)所有能力超过人类中位数;C)所有能力达到人类顶尖水平(第99百分位)。
为何需要新尺子?旧评估体系的双重困境
现有的主流评估方式为何失效?这背后有两个根本原因:
首先是“数据污染”问题。如果模型在训练时已“见过”测试题答案,其高分仅能证明记忆而非理解,陷入了“小镇做题家”困境。
其次是评测对象模糊。如今我们评估的往往不是一个孤立的模型,而是一个包含系统提示、工具调用(计算器、搜索、代码执行)的完整系统。这导致很难分清测得的是模型的“记忆力”还是其“使用搜索引擎的能力”。
正是由于题库泄漏和评测对象模糊化,DeepMind 认为有必要从认知科学第一性原理出发,重建评估框架,并向全球社区开放“出题权”。
20万美元黑客松:聚焦五大评估深水区
DeepMind 承认,在问题解决等领域现有基准尚可,但在元认知、注意力、学习、执行功能和社会认知这几个方面,评估工具几乎是一片空白。
为此,与论文同步推出的 Kaggle 黑客松精准聚焦于这五个评估缺口最大的认知能力:学习、元认知、注意力、执行功能、社会认知。
项目地址:https://www.kaggle.com/competitions/kaggle-measuring-agi
竞赛总奖金20万美元。5个赛道各设2个一等奖(各1万美元),另设4个全场特等奖(各2.5万美元),以鼓励跨赛道的通用性评估方案。
赛程从2026年3月17日持续至6月1日。如果成功,这套评估体系有望成为AGI领域的公共基准,就像ImageNet之于计算机视觉一样。
框架的边界与未来
在论文讨论部分,团队也坦诚指出了认知评估框架暂时“管不到”但至关重要的其他维度:
- 处理速度:正确率相同,但耗时差异可能决定实用价值。
- 系统倾向性:系统的风险偏好、价值观对齐等行为特征,影响部署安全。
- 创造力:其核心组件已被覆盖,但作为整体仍难客观评估。
- 端到端部署评估:实验室认知评估需与真实场景测试互补,前者解释“为何失败”,后者预测“上线风险”。
DeepMind 强调,这个框架只是一个“起点”。未来的AI系统很可能发展出人类不具备的认知能力(如LiDAR感知、原生图像生成),因此分类法本身也需要持续迭代。这项研究最重要的意义在于,它将AGI评估从主观争论,开始推向一条有理论支撑、可操作、可复现的科学轨道。接下来的悬念是:第一个在十维认知雷达图上全面点亮,达到甚至超越人类水平的系统,会由谁创造?
对于关注人工智能前沿进展的开发者与研究者而言,参与这类基准构建或关注其进展,是把握技术脉搏的重要方式。技术社区的集体智慧,往往是推动类似基础标准演进的关键力量。
 发表于 2026-3-19 07:55:53
|
查看: 159|
回复: 0
发表于 2026-3-19 07:55:53
|
查看: 159|
回复: 0
