目录
一、MCP设计理念
二、MCP架构详解
三、底层通信原理
四、项目初始化&实战解析
五、未来规划
六、资源推荐
一、MCP设计理念
在深入解析 MCP 原理之前,我们首先需要明确两个基本问题:MCP 是什么?它为何会出现? 这有助于理解其核心价值与设计初衷。
MCP(Model Context Protocol,模型上下文协议)是由 Anthropic 公司主导推出的一种开放标准协议,旨在统一大型语言模型(LLM)与外部数据源、工具及服务之间的交互方式。该协议基于JSON-RPC 2.0标准消息格式定义通信规则,使得模型能够像使用“通用接口”一样,即插即用地连接各种异构资源。

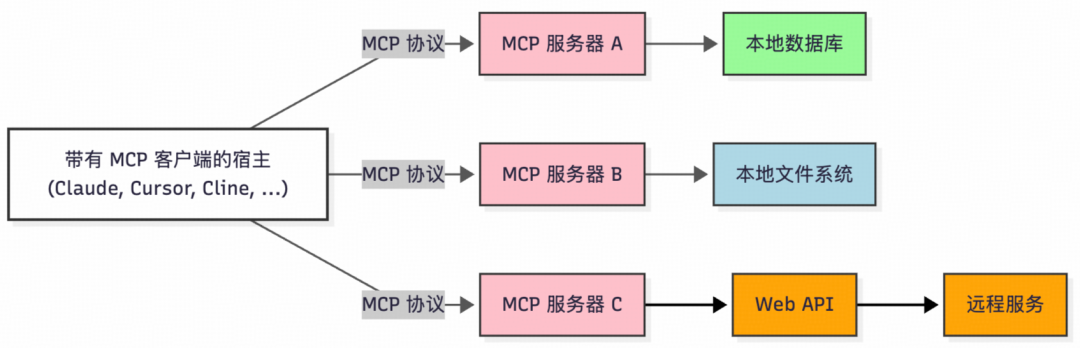
其架构采用经典的客户端-服务器模式,包含三个核心组件:
- MCP Host:运行大模型应用程序(如 Cursor、Cline、Claude Desktop 等),负责发起任务请求。
- MCP Client:集成在 Host 中的协议客户端,负责解析任务需求并与服务器协调资源调用。
- MCP Server:轻量级服务程序,动态注册并暴露本地资源(如文件、数据库)或远程服务(如云API),处理客户端请求并返回结构化数据,同时提供访问权限管理和资源隔离等安全控制。
简而言之,MCP 是一种应用层开放标准协议,类似于 TCP/IP 或 HTTP。开发者可以借助它,安全地在数据源与 AI 工具之间建立双向连接。其核心交互模式可概括为:
- 开发者通过 MCP 服务器公开其数据或服务。
- AI 应用(MCP 客户端)连接到 MCP 服务器,获取所需数据或调用工具,LLM 再基于这些补充信息进行分析和回答。
MCP 的出现,与RAG(检索增强生成) 和Function Calling(函数调用) 两项关键技术密切相关。
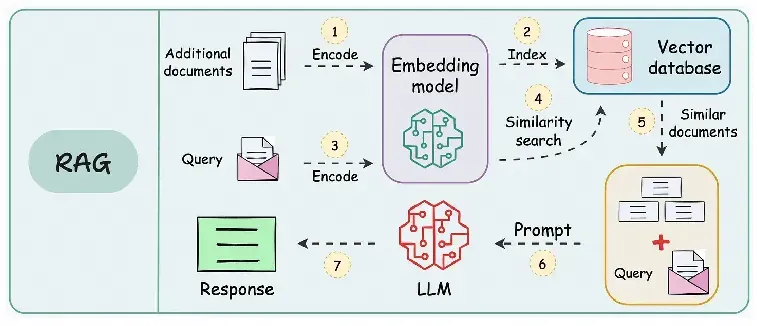
RAG 通过检索外部知识库获取与问题相关的实时信息,并将其注入模型提示词中,从而生成更精准、更具时效性的回答。其典型工作流程为:用户提问 → 问题向量化 → 向量数据库相似度检索 → 拼接上下文提示词 → 模型生成答案。
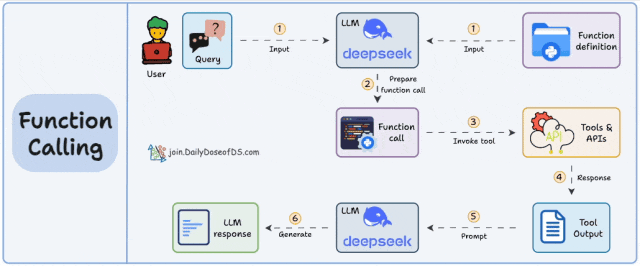
Function Calling 则拓展了模型执行动作的能力,解决了纯文本交互的局限性。它允许模型解析用户意图后,生成结构化指令来调用预定义的外部函数或 API。其工作流程为:用户指令 → 模型识别需调用的函数 → 生成参数化调用指令 → 外部系统执行 → 返回结果至模型 → 生成最终响应。
然而,传统的 Function Calling 需要为不同的 API 封装不同的方法,参数固定后变更困难,难以在不同平台间灵活复用。MCP 可以看作是在 Function Calling 基础上的进一步抽象,其目标是让 AI 应用更简单、高效、安全地对接外部资源,更好地为大模型补充上下文信息。它将大模型运行环境抽象为 MCP Client,将外部函数运行环境抽象为 MCP Server,并统一了客户端与服务器之间的通信规范。
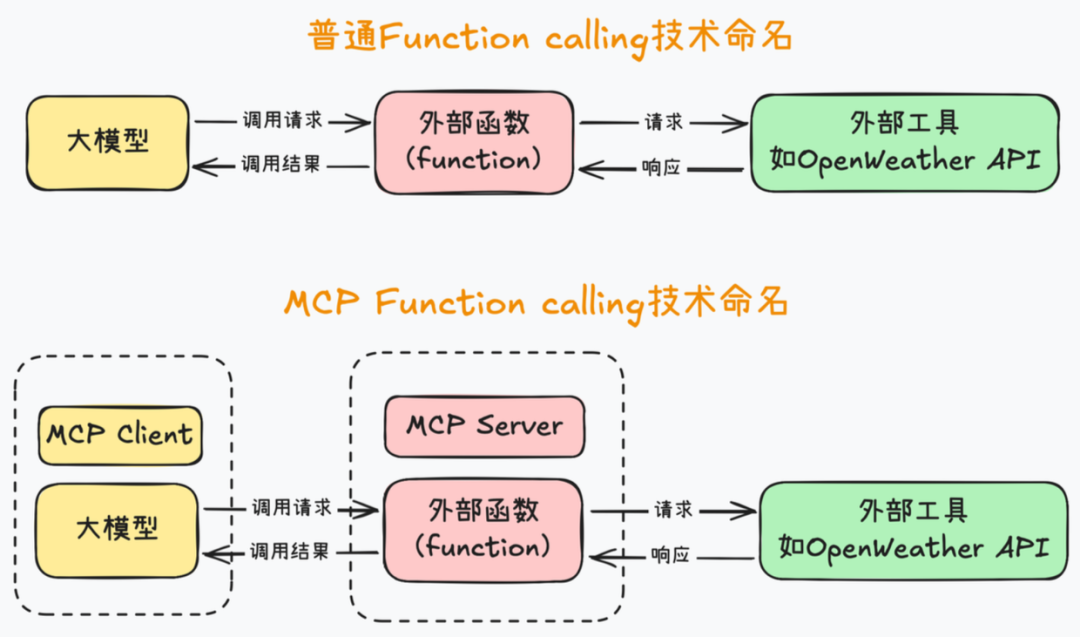
MCP vs Function Calling 核心对比:
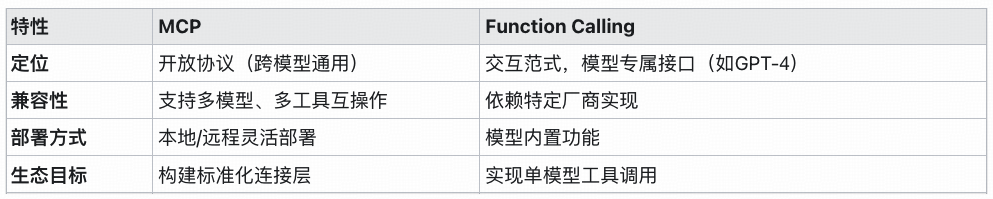
总结来说,RAG 专注于知识检索,Function Calling 专注于执行操作,二者互补但存在集成困难、扩展性差的问题。开发者往往需要为不同的模型重复实现工具调用逻辑。
MCP 则是对两者的整合与标准化:
- 标准化接口:MCP 为 RAG 的检索源接入(如数据库、文档库)和 Function Calling 的工具调用(如 API 服务)提供了统一的接入规范,避免了为每个工具开发定制化适配器。例如,MCP 工具的
inputSchema 可以定义多个参数,并通过 required 标记必传参数。大模型在解析用户提问时,会根据工具的描述和参数定义,自动解析并提供相应参数值来调用工具。这种参数化设计提高了工具调用的灵活性,降低了开发复杂度。
return Tool(
name=self.name,
description=self.description,
inputSchema={
"type": "object",
"properties": {
"host": {"type": "string", "description": "数据库主机地址"},
"port": {"type": "integer", "description": "数据库端口"},
"user": {"type": "string", "description": "数据库用户名"},
"password": {"type": "string", "description": "数据库密码"},
"database": {"type": "string", "description": "数据库名称"}
},
"required": ["host", "port", "user", "password", "database"]
}
)
- 能力扩展:
- RAG 通过 MCP 可以接入实时数据流(如证券行情),突破静态知识库的限制。
- Function Calling 通过 MCP 可以调用异构工具(如 IoT 设备),无需依赖特定模型的固有支持。
- 系统效率:MCP 降低了开发复杂度,促进了工具生态的共享,开发者无需为不同模型重复实现工具调用逻辑。
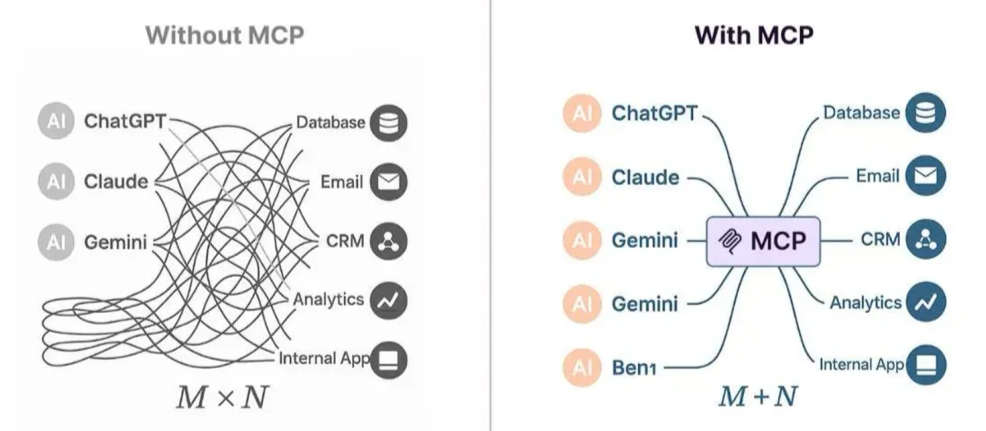
技术演进总结:
- RAG → Function Calling → MCP 代表了 AI 能力发展的三个重要维度:从静态知识检索,到动态行动执行,再到标准化生态构建。
- 在 AI Agent 架构中:RAG 充当知识中枢,Function Calling 为执行手段,MCP 则是连接内外的“神经枢纽”。
- 未来意义:MCP 的开放性将加速工具间的互操作性,推动复杂任务(如多 Agent 协作)的规模化落地,成为 AI 基础设施的关键组件。
二、MCP 架构详解
了解 MCP 的价值后,还需明确其在 AI 生态中的位置。以 AI Agent 为例,MCP 通常扮演着连接智能体与外部数据和工具的桥梁角色。

本节将结合 Python 版 SDK 源码和一个开源的 MCP for DB 项目,解读 MCP 的架构原理及使用方法。MCP Python SDK 提供了一个分层架构,通过多种传输协议将 LLM 应用程序连接到 MCP 服务器。
参考项目地址:https://github.com/Eliot-Shen/MCP-DB-GPT
Python SDK:https://github.com/modelcontextprotocol/python-sdk
1. MCP运行过程
首先,从宏观上理解 MCP 的整体运行流程:
- 用户在主机上配置 MCP 服务(例如通过 VSCode 插件 Cline 配置 JSON 文件)。
- 用户输入问题。
- 客户端让大语言模型选择合适的 MCP 工具。
- 大模型选定工具后,客户端会寻求用户确认。
- 客户端请求 MCP 服务器执行工具。
- MCP 服务器调用工具并将结果返回给客户端。
- 客户端将工具执行结果和用户查询一同发送给大语言模型。
- 大语言模型组织最终答案返回给用户。
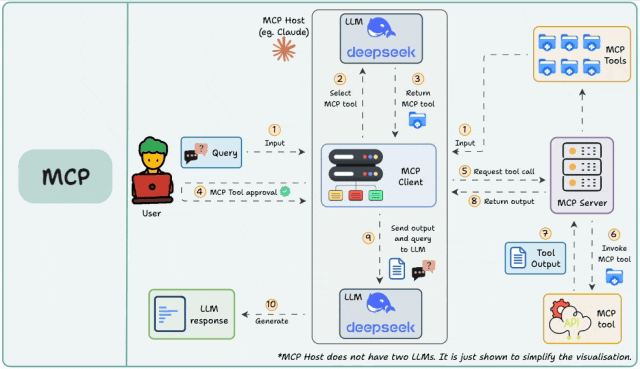
可见,整个流程的核心是 Client 和 Server 的交互。在使用 Cline 这类集成客户端时,感知如下图所示,Client 已内置于 Host 中,开发者只需开发对应的 MCP Server 并在主机中配置好即可。
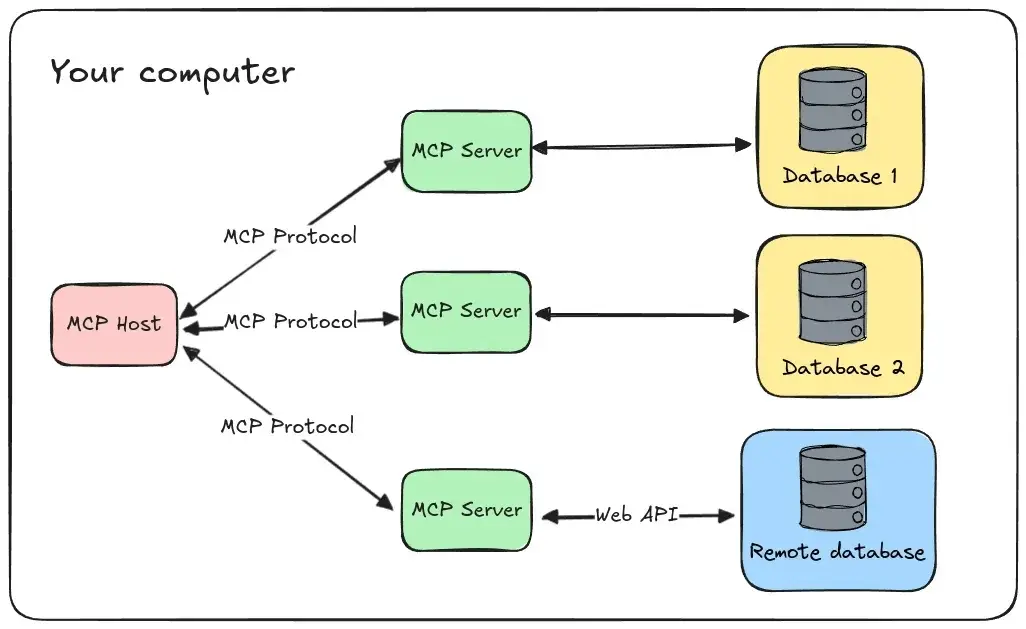
2. MCP运行原理
MCP Server 是 MCP 架构的核心。其 Python SDK 提供的框架如下图所示,我们重点关注其提供的三大核心功能:资源(@mcp.resource)、工具(@mcp.tool)、提示词(@mcp.prompt)。
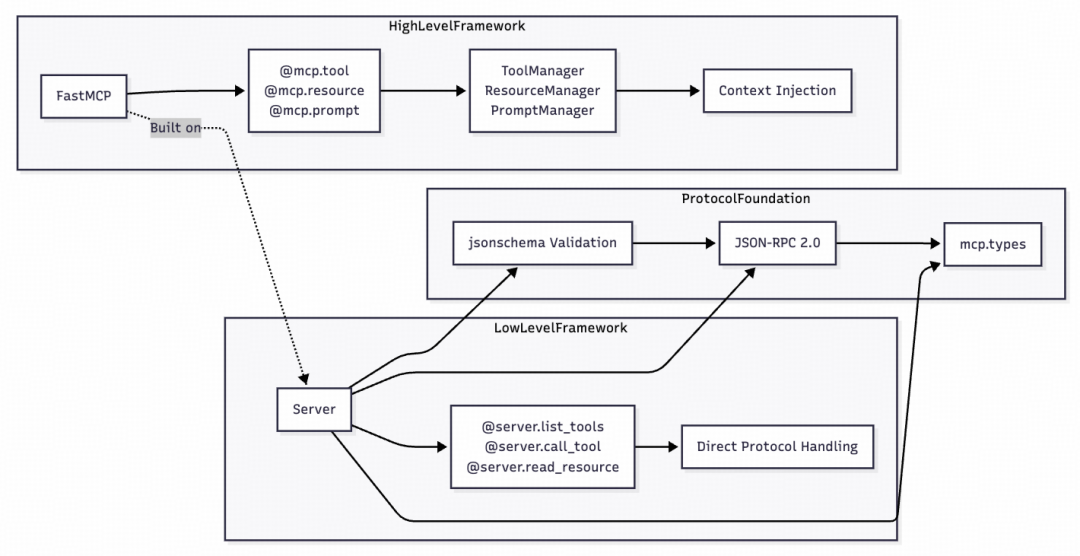
三大功能之间的协作逻辑如下:
- 资源为工具提供上下文:手动注入资源可以增强模型对任务的理解,辅助其更准确地调用工具。
- 工具执行依赖资源输入:当工具需要操作外部数据时(如文件处理),可将指定文件 URI 作为工具参数输入。
- 提示词封装工具与资源调用:复杂的 Prompt 可以预设工具调用顺序或资源使用规则,形成自动化工作流。
# 注意:将提示词模板封装在工具中,可能因LLM未调用该工具而无法达到预期效果。
async def run_tool(self, arguments: Dict[str, Any]) -> Sequence[TextContent]:
prompt = f"""
- Workflow:
1. 解析用户输入的自然语言指令,提取关键信息,如表描述和查询条件。
2. 判断是否跨库查询、是否明确指定了目标表名。
3. 未明确指定目标表名则调用“get_table_name”工具,获取对应的表名。
4. 调用“get_table_desc”工具,获取表的结构信息。
5. 根据表结构信息和用户输入的查询条件,生成SQL查询语句并调用“execute_sql”工具,返回查询结果。
- Examples:
- 例子1:用户输入“查询用户表张三的数据”
解析结果:表描述为“用户表”,查询条件为“张三”。
判断结果:1.没有出现跨库的情况 2.未明确指定表名,需调用工具获取表名
调用工具“get_table_name”:根据“用户表”描述获取表名,假设返回表名为“user_table”。
调用工具“get_table_desc”:根据“user_table”获取表结构。
生成SQL查询语句:`SELECT * FROM user_table WHERE name = '张三';`
调用工具“execute_sql”:根据生成的SQL获取结果。
- task:
- 调用工具“get_table_name”,
- 调用工具“get_table_desc”,
- 调用工具“execute_sql”
- 以markdown格式返回执行结果
"""
return [TextContent(type="text", text=prompt)]
出于安全考虑,大模型对资源/工具的访问能力受到限制:
- 工具:支持自主调用。大模型通过解析服务端公开的工具描述,能主动发起工具调用请求。
- 资源:禁止自主访问。资源始终由应用层或用户管控,模型仅能使用已由客户端注入的资源内容。
资源(Resources)
资源是由 MCP Server 向客户端提供的数据实体,旨在扩展 AI 模型的数据访问边界。它类似于 REST API 中的 GET 端点——主要提供数据,而不应执行大量计算或产生副作用。
资源代表任何可供 AI 模型读取的数据形式,涵盖:
- 文件内容(文本、JSON、源代码等)。
- 数据库查询结果。
- 动态系统数据(日志、传感器数据等)。
例如,在 MCP-DB-GPT 项目中定义了一个访问本地 JSON 格式日志数据的资源接口:
@mcp.resource("logs://{session_id}/{limit}")
def get_query_logs(limit: str = "5", session_id: str = "anonymous") -> Dict[str, Any]:
"""获取查询日志
Args:
limit: 可选参数,指定返回的日志数量,默认为5
session_id: 可选参数,指定要获取的会话ID
"""
try:
limit_val = int(limit)
if limit_val <= 0:
return {"success": False, "error": "Limit must be a positive integer"}
logs = query_logger.get_logs(session_id=session_id, limit=limit_val)
total = query_logger.total_query_count(session_id=session_id)
return {"success": True, "logs": logs, "total_queries": total}
except Exception as e:
return {"success": False, "error": str(e)}
资源通过统一资源标识符(URI)进行寻址,格式为 [协议]://[主机]/[路径]。这种设计支持跨本地与远程环境的无缝集成,使 AI 模型能够访问私有知识库、实时 API 及系统动态信息。
工具是服务器向客户端暴露的可执行函数集合,用于拓展 LLM 的操作能力。其本质是函数抽象,通过 JSON Schema 严格定义输入/输出参数结构。
例如,MCP-DB-GPT 项目中定义了一个只读 SQL 查询工具:
@mcp.tool()
def query_data(sql: str, session_id: str = "anonymous") -> Dict[str, Any]:
"""Execute read-only SQL queries"""
logger.info(f"Executing query: {sql}")
conn = get_connection()
cursor = None
try:
# Create dictionary cursor
cursor = conn.cursor(pymysql.cursors.DictCursor)
# Start read-only transaction
cursor.execute("SET TRANSACTION READ ONLY")
cursor.execute("START TRANSACTION")
try:
cursor.execute(sql)
results = cursor.fetchall()
conn.commit()
# 记录成功查询
log_query(operation=sql, success=True, session_id=session_id)
# Convert results to serializable format
return {
"success": True,
"results": results,
"rowCount": len(results)
}
except Exception as e:
conn.rollback()
log_query(operation=sql, success=False, error=str(e), session_id=session_id)
return {
"success": False,
"error": str(e)
}
finally:
if cursor:
cursor.close()
conn.close()
客户端通过 tools/list 发现工具,通过 tools/call 调用工具。其安全控制采用 “模型决策 + 人工确认” 的双轨制:LLM 决定是否需要调用工具,而每次执行前通常需要用户显式授权。
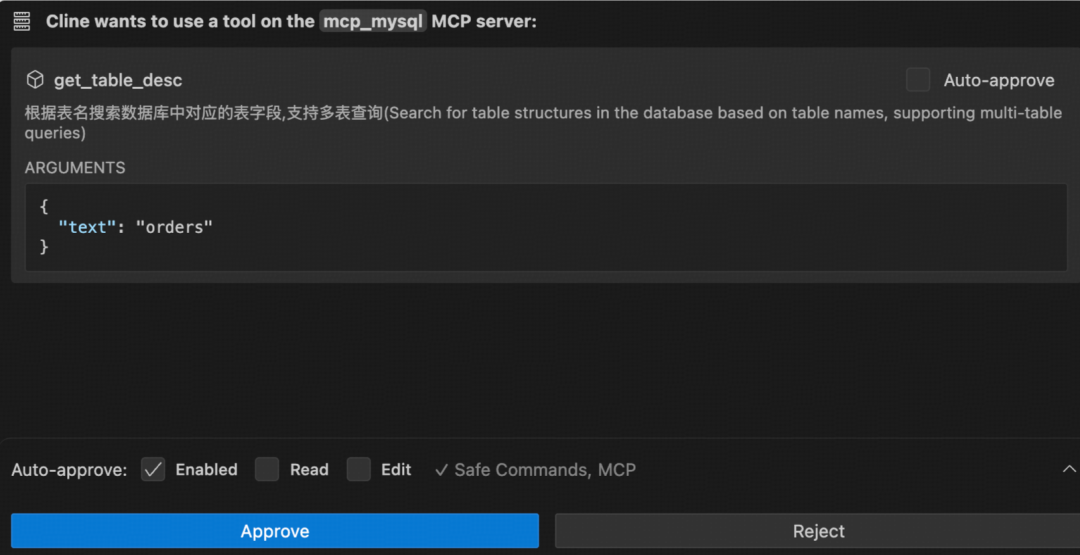
提示词(Prompts)
提示词是服务器端预定义的可重用交互模板,用于标准化和引导 LLM 的任务执行。它们通过动态参数化设计,允许传入特定值生成定制化指令。
其核心机制包括:
- 结构化要素:包含唯一标识符、任务描述、参数列表及可选的资源引用。
- 上下文引导:可嵌入历史对话或外部资源引用,帮助模型理解背景。
- 工作流支持:支持多个提示模板组合以处理复杂任务。
- ⚠️ 注意:提示词模板需要与客户端联动。服务端定义模板后,客户端在交互时获取并填充模板,再发送给大模型。如果嵌在工具中,则触发条件往往是被动的。
MCP-DB-GPT 项目中服务端定义的提示词接口示例:
@mcp.prompt()
def generate_db_gpt_prompt() -> str:
"""Generate a prompt for LLM to interact with database."""
# 获取数据库表列表
tables_info = get_tables()
database_name = tables_info["database"]
tables = tables_info["tables"]
# 获取所有表的描述信息
table_definitions = []
for table in tables:
table_desc = get_table_description(table)
if table_desc.get("success"):
table_definitions.append(table_desc["table_definition"])
return DB_GPT_SYSTEM_PROMPT.format(
database_name=database_name,
table_definitions="\n".join(table_definitions),
)
其中 DB_GPT_SYSTEM_PROMPT 是预先编写好的提示词模板,一个简易的模板如下:
Baseline_SYSTEM_PROMPT = """请根据用户选择的数据库和该库的所有可用表结构定义来回答用户问题.
数据库名: {database_name}
表结构定义: {table_definitions}
约束:
1. 请根据用户问题理解用户意图,使用给出表结构定义创建一个语法正确的mysql sql。
2. 将查询限制为最多10000个结果。
3. 只能使用表结构信息中提供的表来生成 sql。
4. 请检查SQL的正确性。
5. 分析基于现有表结构和元数据信息,估算用户提供的 DQL 语句的索引推荐策略,并返回给用户explain执行结果
用户问题: {user_question}
请按照以下JSON格式回复:{{
"thoughts": "分析思路",
"sql": "SQL查询语句",
"explain": "优化后的DQL语句执行结果"
}}"""
客户端建立连接后,可以获取相关的资源、工具和提示词模板:
async def connect_to_server(self, server_script_path: str):
"""Connect to an MCP server"""
# ... 建立连接的代码 ...
await self.session.initialize()
# List available tools
response = await self.session.list_tools()
tools = response.tools
print("\nConnected to server with tools:", [tool.name for tool in tools])
# List available resources
resources_response = await self.session.list_resources()
if resources_response and resources_response.resources:
print("Available resources:", [resource.uri for resource in resources_response.resources])
# List available prompts
prompts = await self.session.list_prompts()
if prompts and prompts.prompts:
print("Available prompts:", [prompt.name for prompt in prompts.prompts])
3. MCP Client
MCP Client 是连接 LLM 与 MCP Server 的桥梁。其 Python SDK 框架图如下:
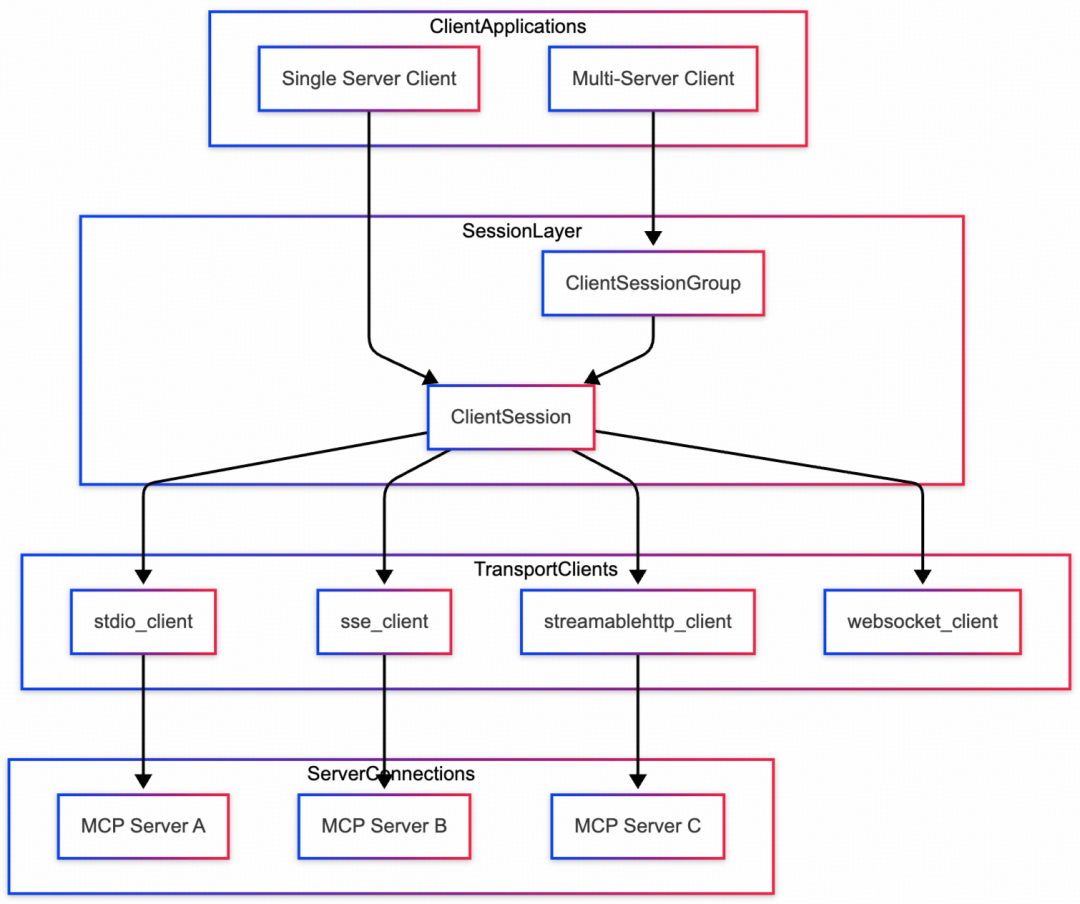
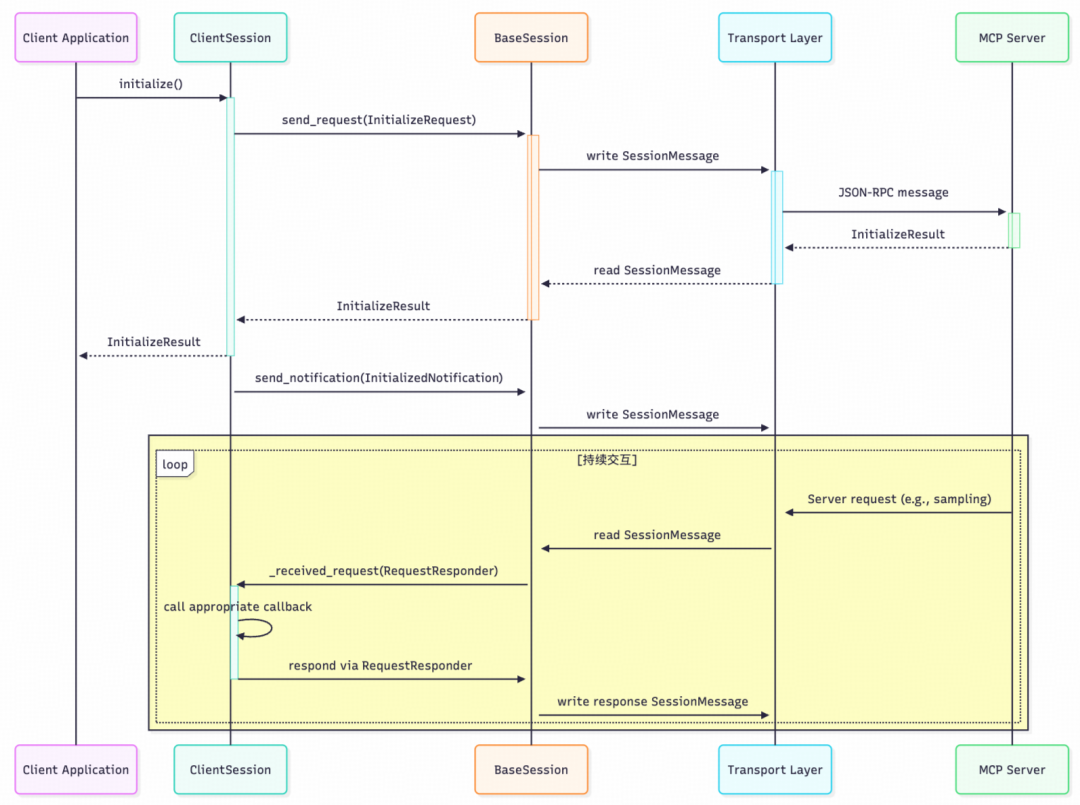
结合 MCP-DB-GPT 项目,我们关注 ClientSession 如何与服务器交互。宏观上,客户端与服务器端的消息流如下图所示:
在 MCP-DB-GPT 项目中,定义了一个集成阿里通义千问大模型接口的 MCPClient 类:
class MCPClient:
def __init__(self):
# Initialize session and client objects
self.session: Optional[ClientSession] = None
self.exit_stack = AsyncExitStack()
self.llm = TongYiAPI() # 通义千问接口
self.session_id = str(uuid.uuid4())
self.use_few_shot = True
self.conversation_history = FEW_SHOT_EXAMPLES if self.use_few_shot else []
async def connect_to_server(self, server_script_path: str):
"""Connect to an MCP server"""
# ... 连接建立代码 ...
async def get_query_logs(self, limit: int = 5) -> str:
"""获取查询日志"""
async def get_schema(self, table_names: Optional[List[str]] = None) -> str:
"""获取数据库结构信息"""
async def process_query(self, query: str) -> str:
"""使用通义千问处理数据库相关查询"""
客户端通过 ClientSession 对象与服务器交互,主要包括:
- 连接建立:基于服务器脚本路径初始化参数,通过 stdio 建立传输通道,调用
initialize() 初始化会话,并通过 list_tools()、list_resources() 进行工具和资源发现。
- 工具调用:使用
session.call_tool(tool_name, params) 发送 JSON-RPC 请求,服务器执行后返回结果。
- 资源访问:通过
session.read_resource(uri) 访问资源(如日志)。所有交互依赖会话级加密和权限验证。
典型案例:自然语言生成SQL
MCP-DB-GPT 项目的一个亮点是实现结合提示词,借助大模型解析自然语言生成 SQL,再与服务器交互返回结果的完整流程。
流程详解:
在 process_query 方法中,LLM 用于生成结构化工具调用(如 SQL 语句)。
async def process_query(self, query: str) -> str:
"""使用通义千问处理数据库相关查询"""
try:
# 1. 调用服务器层的提示词方法,获取封装好的提示词模板
prompt = await self.session.get_prompt("generate_db_gpt_prompt")
prompt = prompt.messages[0].content.text
# 2. 将提示词和用户问题投喂给大模型,请求JSON格式输出
llm_response = self.llm.chat(system_prompt=prompt, content=query, response_format="json_object",
conversation_history=self.conversation_history)
response_data = json.loads(llm_response)
# 3. 如果LLM响应中包含SQL,则调用工具执行
if response_data.get("sql"):
# 执行SQL查询
query_result = await self.session.call_tool("query_data", {
"sql": response_data["sql"],
"session_id": self.session_id
})
# 构建最终响应
final_response = {
"thoughts": response_data["thoughts"],
"sql": response_data["sql"],
"display_type": response_data.get("display_type", "Table"),
"results": json.loads(query_result.content[0].text) if query_result.content[0].text else None
}
return json.dumps(final_response, ensure_ascii=False, indent=2)
此交互完成了 MCP 的 “解析-执行-响应”闭环:自然语言被解析为 SQL(工具调用参数),服务器执行后返回结构化数据,客户端整合为最终响应。
三、底层通信原理
1. 协议层:JSON-RPC 2.0 基础
MCP 的核心消息格式采用 JSON-RPC 2.0 协议。在 Python SDK 中:
- 消息结构:每条消息都是 JSON 对象,包含
method(方法名)、params(参数)和 id(请求ID)。
class JSONRPCRequest(Request[dict[str, Any] | None, str]):
"""A request that expects a response."""
jsonrpc: Literal["2.0"]
id: RequestId
method: str
params: dict[str, Any] | None = None
- 交互类型:包括请求(Request)、响应(Response)、错误响应(Error)和通知(Notification,用于异步事件)。
- 优势:标准化确保了跨平台兼容性,并通过特定类实现解析验证,减少开销。
2. 传输层:双向通信实现
MCP Python SDK 提供了多种传输机制,抽象为基于流的通用接口。
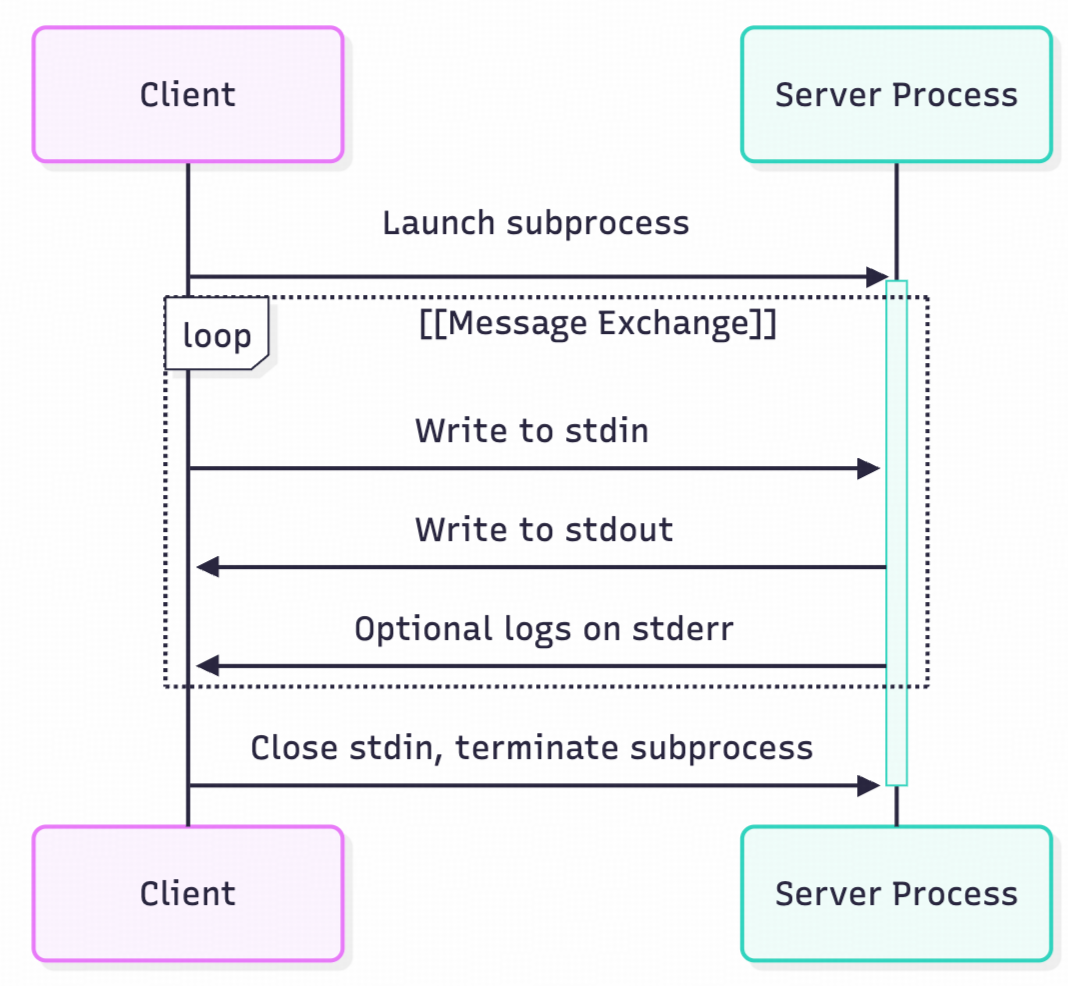
Stdio传输
通过标准输入/输出流进行通信,适用于本地进程间通信,延迟低但仅限于单机。其通信流程可概括为:
- 客户端以子进程方式启动服务器。
- 客户端往服务器的 stdin 写入消息。
- 服务器从自身的 stdin 读取消息并处理。
- 服务器往自身的 stdout 写入响应。
- 客户端从服务器的 stdout 读取消息。
- 通信结束,关闭进程和流。
服务端代码参考:
async def run_stdio():
"""运行标准输入输出模式的服务器"""
from mcp.server.stdio import stdio_server
logger.info("启动标准输入输出(stdio)模式服务器")
try:
# 初始化资源
await initialize_global_resources()
async with stdio_server() as (read_stream, write_stream):
try:
await app.run(
read_stream,
write_stream,
app.create_initialization_options()
)
except Exception as e:
logger.critical(f"标准输入输出模式服务器错误: {str(e)}")
raise
finally:
# 关闭资源
await close_global_resources()
配置 Cline 的 JSON 文件示例:
"mcp_db": {
"timeout": 60,
"type": "stdio",
"command": "uv",
"args": [
"--directory",
"/path/to/project/",
"run",
"-m",
"server.mcp.server_mysql",
"--mode",
"stdio"
],
"env": {
"MYSQL_HOST": "localhost",
"MYSQL_PORT": "3306",
"MYSQL_USER": "root",
"MYSQL_PASSWORD": "password",
"MYSQL_DATABASE": "mcp_db"
}
}
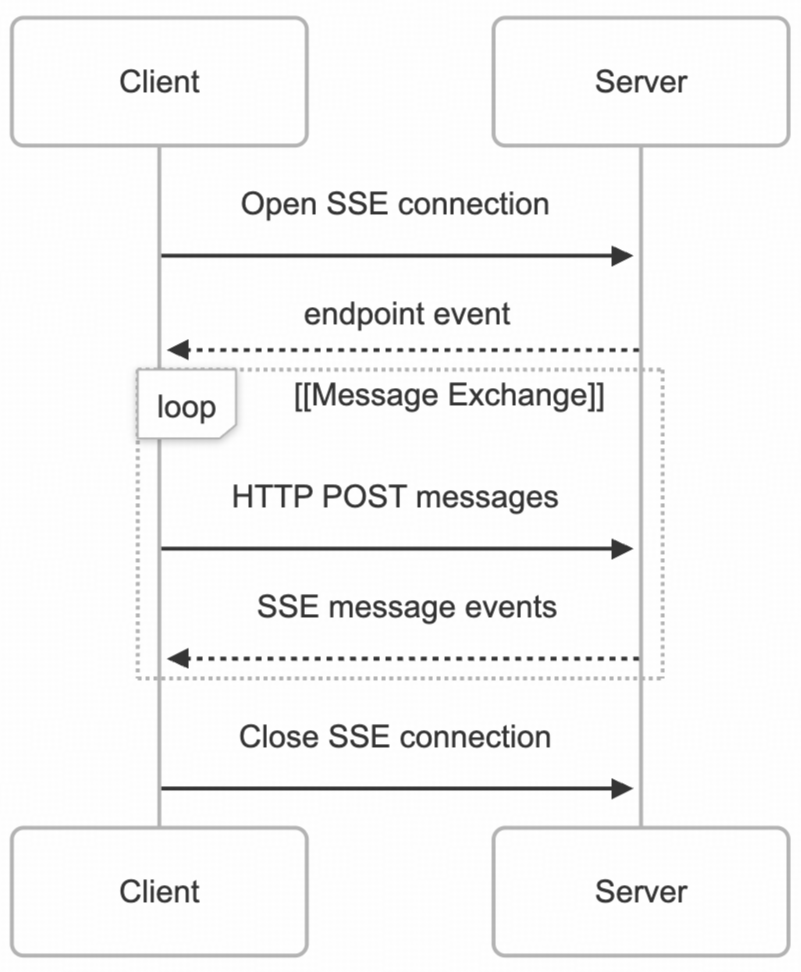
SSE传输
SSE 传输使用 Server-Sent Events 传输服务器到客户端的消息,并使用 HTTP POST 请求传输客户端到服务器的消息,本质上是基于 HTTP 的通信。其流程概括为:
- 客户端向服务器的
/sse 端点发送 GET 请求,建立 SSE 连接。
- 服务器返回一个包含消息端点地址的事件消息。
- 客户端向该消息端点发送 POST 消息。
- 服务器响应消息接收状态。
- 服务器通过已建立的 SSE 连接推送事件消息给客户端。
- 客户端从 SSE 连接读取消息。
- 客户端关闭连接。
服务端代码参考 (使用 FastAPI 或 Starlette):
def run_sse():
"""运行SSE(Server-Sent Events)模式的服务器"""
logger.info("启动SSE模式服务器")
sse = SseServerTransport("/messages/")
async def handle_sse(request):
"""处理SSE连接请求"""
async with sse.connect_sse(
request.scope, request.receive, request.send
) as streams:
await app.run(streams[0], streams[1], app.create_initialization_options())
return Response(status_code=204)
starlette_app = Starlette(
debug=True,
routes=[
Route("/sse", endpoint=handle_sse),
Mount("/messages/", app=sse.handle_post_message)
]
)
config = uvicorn.Config(app=starlette_app, host="0.0.0.0", port=9000)
server = uvicorn.Server(config)
server.run()
配置 Cline 的 JSON 文件示例:
"mysql_mcp_server": {
"disabled": false,
"timeout": 60,
"type": "sse",
"url": "http://localhost:9000/sse"
}
3. 通信工作流程
MCP 通信遵循 JSON-RPC 2.0 模式,主要消息类别和连接生命周期如下图所示:
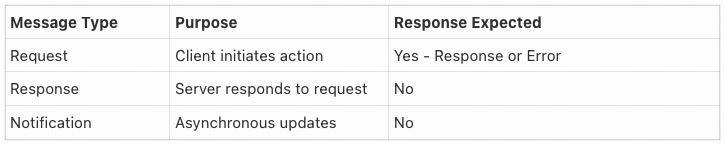
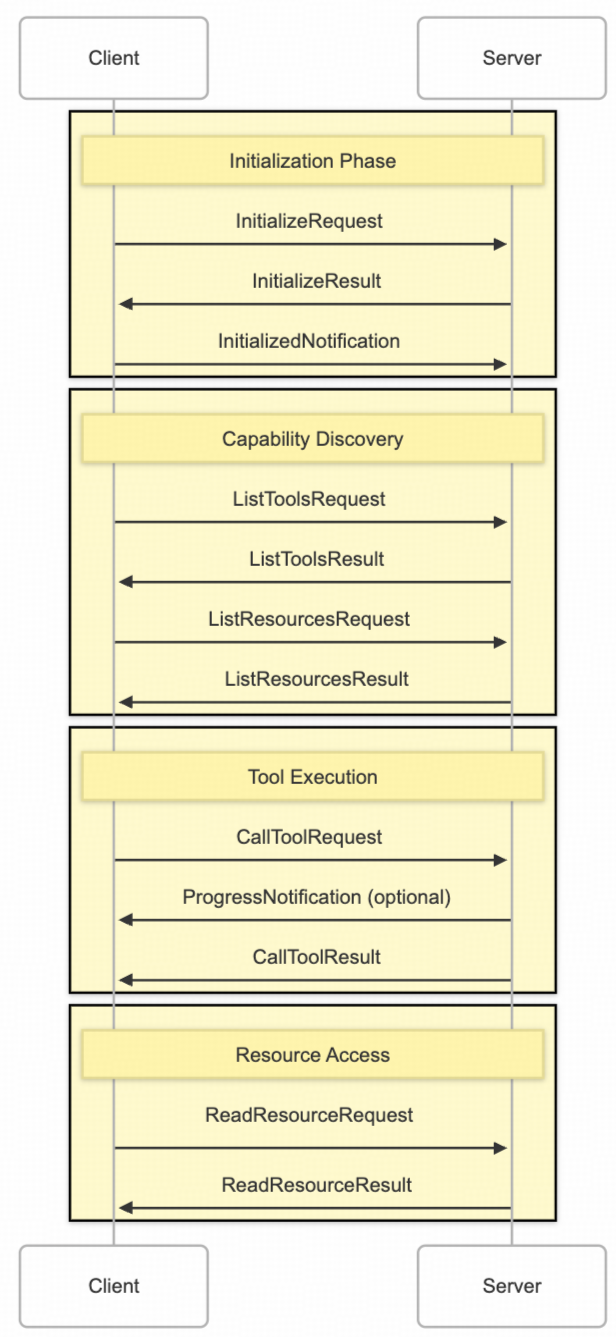
以 StreamableHTTP 机制为例,其实现了基于 HTTP 的双向通信,结合了 HTTP POST 和 SSE 流。工作流程包括会话建立、双向消息传输(客户端POST请求,服务器SSE推送)和可选的连接恢复。
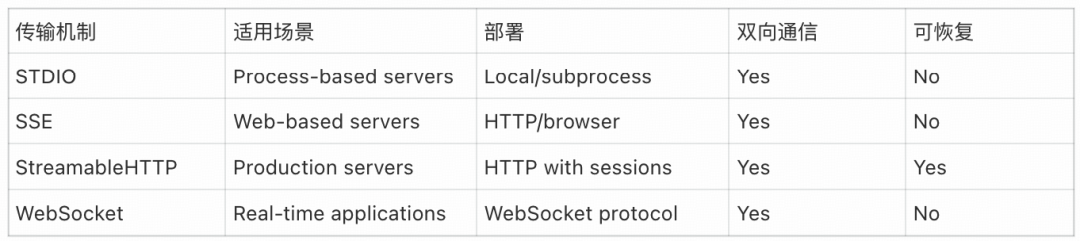
4. 各协议对比分析
| 特性 |
Stdio |
SSE |
StreamableHTTP |
| 通信模式 |
同步/异步流 |
客户端POST + 服务器SSE流 |
双向HTTP流 |
| 部署场景 |
本地进程 |
远程/云端 |
远程/云端 |
| 复杂度 |
低 |
中 |
高 |
| 适用场景 |
IDE插件、CLI工具 |
实时数据推送、远程服务 |
需要状态管理的复杂远程交互 |
MCP vs REST API
- MCP:为 AI 交互设计,双向流式,支持工具/资源的动态发现与调用,协议层统一。
- REST API:为通用 HTTP 交互设计,请求-响应模式,接口需预定义且静态。
MCP vs WebSocket
- MCP:基于 JSON-RPC 的消息协议,可运行在多种传输层(Stdio/SSE/HTTP)之上,专为 LLM 工具调用标准化。
- WebSocket:是一种双向通信的传输层协议,本身不定义消息语义,需要在上层自定义协议。
四、项目初始化&实战解析
1. 环境安装
官方推荐使用 uv 进行虚拟环境及依赖管理。
# 安装 uv (macOS 示例)
curl -LsSf https://astral.sh/uv/install.sh | sh
source $HOME/.local/bin/env
# 创建项目并安装依赖
uv init MCP-DB
cd MCP-DB
uv add "mcp[cli]" # 安装 MCP 客户端依赖
uv run mcp --help # 验证安装
注意:SDK 需要 Python 3.10 或更高版本。
2. DW-DBA-MCP 实战解析
本项目旨在为数据库侧开发高可扩展的 MCP Server。采用微服务架构设计,便于集成与扩展。
项目设计思路与改进:
在参考开源项目的基础上,本项目主要做了以下改进:
- 架构层面:使用工厂模式和单例模式,将单体服务重构为微服务架构,支持新 MCP Server 的易扩展式新增。
- 功能层面:增加了数据库连接池优化、多用户隔离访问、SQL 拦截鉴权、更多数据库工具(如慢查询分析、索引推荐)、DiFy 知识库访问工具以及自建客户端。
- 客户端:开发了可处理多个 MCP Server 的客户端,并提供了 FastAPI 服务接口。
核心设计:资源的自动注册与发现
为了实现高可扩展性,项目设计了资源的自动注册机制。核心在于一个资源基类 BaseResource 和注册表 ResourceRegistry。
-
资源基类 (BaseResource):通过 __init_subclass__ 方法实现子类的自动注册。
class BaseResource:
"""资源基类"""
name: str = ""
description: str = ""
uri: AnyUrl
mimeType: str = "text/plain"
auto_register: bool = True
def __init_subclass__(cls, **kwargs):
"""子类初始化时自动注册到资源注册表"""
super().__init_subclass__(**kwargs)
if cls.auto_register and cls.uri is not None:
ResourceRegistry.register(cls)
- 资源注册表 (
ResourceRegistry):管理所有资源实例,提供注册和查找方法。
- 具体资源实现:例如
MySQLResource 和代表具体表的 TableResource。MySQLResource 在初始化时会扫描数据库,为每个表创建并注册一个 TableResource 实例。
效果展示
- 查询表中数据:在 Cline 中提问“查询用户表中的所有数据”,LLM 会解析意图,调用
get_table_name、get_table_desc 等工具,最终生成并执行 SQL,返回结果。
- 慢 SQL 优化:提问“分析一下当前的慢查询”,LLM 会调用慢查询分析工具,返回分析结果和优化建议。
- 高危操作验证:当用户试图执行 UPDATE/DELETE 等非查询语句时,配置的 SQL 拦截鉴权机制会阻止执行,保障数据库安全。
- 自建客户端提问:通过请求自建的 FastAPI 接口,可以直接用自然语言提问,后端集成了 MCP Client 和 Server,返回处理后的结果。
五、未来规划
在 AI4DB (AI for Database) 领域,AI 技术正推动数据库运维从人工介入向智能自治演进。而在 DB4AI (Database for AI) 方向,数据库本身也在适配 AI 场景,提供向量检索、多模态数据管理等能力。
在此背景下,DBA 的角色正在从传统的 Database Administrator(数据库管理员)向 Data Business Architect(数据业务架构师)演进。未来的 DBA 团队需要:
- 筑牢数据安全防线,构建全周期数据安全治理体系。
- 夯实工程化落地能力,推动智能技术与业务场景的深度融合。
- 利用 AI 工具,从海量数据中挖掘业务价值,成为连接数据与业务的桥梁。
六、资源推荐
 发表于 2025-12-9 07:35:24
|
查看: 192|
回复: 0
发表于 2025-12-9 07:35:24
|
查看: 192|
回复: 0
