Apache Hive是一款建立在Hadoop之上的开源数据仓库系统,能够将存储在Hadoop文件中的结构化、半结构化数据文件映射为数据库表,并基于表提供一种类似SQL的查询模型(HQL),用于访问和分析存储在Hadoop中的大型数据集。Hive的核心作用是将HQL转换为MapReduce程序,然后提交到Hadoop集群执行。
一、为什么选择Hive?
直接使用Hadoop MapReduce处理数据面临诸多挑战:人员学习成本高(需掌握Java),且实现复杂查询逻辑的开发难度太大。而Hive则带来了以下优势:
- 类SQL操作:提供快速开发能力,简单易上手。
- 降低学习成本:避免了直接编写MapReduce代码。
- 易于扩展:支持自定义函数,功能扩展方便。
- 海量数据处理:背靠Hadoop,擅长存储与分析海量数据集。
二、核心架构与设计
Hive的分布式特性主要由Hadoop实现,包括分布式存储和计算。
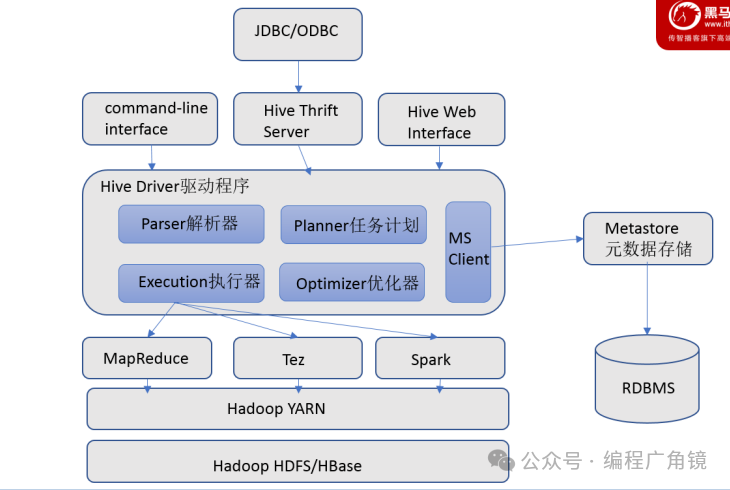
1. 用户接口
包括CLI(命令行)、JDBC/ODBC、WebGUI,允许用户通过多种方式与Hive交互。
2. 元数据存储(MetaStore)
元数据(如表名、列信息、分区属性、数据位置等)通常存储在MySQL等关系型数据库中。Metastore服务管理这些元数据,对外暴露服务地址,客户端通过连接该服务来存取元数据,无需直接访问数据库,保证了安全性与可管理性。生产环境推荐使用远程模式。
3. 驱动与执行引擎
Driver完成HQL语句的词法分析、语法分析、编译、优化及执行计划生成。Hive本身不直接处理数据文件,而是通过执行引擎,目前支持MapReduce、Tez、Spark三种引擎。
4. 数据模型
Hive的数据存储在HDFS中,主要数据模型包括:
- 内部表(Table):数据由Hive管理,删除表时元数据和数据一同删除。
- 外部表(External Table):仅记录数据在HDFS中的路径,删除表时只删除元数据,不删除数据文件,便于数据共享。
- 分区(Partition):根据指定列(如日期
dt)将数据划分到不同目录,提升查询效率。
- 分桶(Bucket):根据指定列的哈希值将数据分散到多个文件中,旨在提升并行处理与采样效率。
5. 设计特性
- 批处理擅长:适用于海量数据的静态批处理,如数据迁移、清洗、挖掘。
- 弹性扩展:存储与计算能力随Hadoop集群规模线性扩展。
- 高容错性:依赖Hadoop的容错机制。
三、数据定义与操作实战
1. 表定义
Hive表定义的核心是描述数据文件与表结构的映射关系(元数据)。
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type, ...)]
[CLUSTERED BY (col_name, ...) INTO num_buckets BUCKETS]
[ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\001'
COLLECTION ITEMS TERMINATED BY ','
MAP KEYS TERMINATED BY '#'
LINES TERMINATED BY '\n']
[STORED AS file_format]
[LOCATION hdfs_path];
- EXTERNAL:创建外部表。
- PARTITIONED BY:创建分区表。
- ROW FORMAT:指定字段、集合、Map键值及行之间的分隔符。
- STORED AS:指定存储格式(如TEXTFILE, SEQUENCEFILE)。
- LOCATION:指定表数据在HDFS的存储路径(外部表必须指定)。
2. 分区表操作
分区通过将数据组织到不同目录下来大幅提升查询性能。
- 静态分区:插入数据时需明确指定分区值。
LOAD DATA LOCAL INPATH '/path/data.txt' INTO TABLE log_table PARTITION (dt='20231001');
- 动态分区:根据查询结果的列值自动创建分区,需先启用相关设置。
SET hive.exec.dynamic.partition=true;
SET hive.exec.dynamic.partition.mode=nonstrict;
INSERT OVERWRITE TABLE target_table PARTITION (dt)
SELECT ..., dt FROM source_table;
- 修改表结构(CASCADE):对分区表变更字段时,需使用
CASCADE关键字级联更新所有分区的元数据。
ALTER TABLE table_name CHANGE COLUMN old_name new_name BIGINT CASCADE;
3. 数据加载与插入
- 加载数据(LOAD):将数据文件移动到Hive表对应的HDFS目录下,效率高。
LOAD DATA LOCAL INPATH '/local/path/data.txt' [OVERWRITE] INTO TABLE my_table;
- 插入数据(INSERT):通常将查询结果插入到另一张表。
INSERT INTO/OVERWRITE TABLE target_table SELECT ... FROM source_table;
INSERT OVERWRITE会覆盖目标表或分区的现有数据。
四、查询优化与执行顺序
1. 基础查询与聚合
SELECT [ALL|DISTINCT] col1, agg_func(col2)
FROM table
WHERE condition
GROUP BY col1
HAVING agg_condition
ORDER BY col1
LIMIT n;
WHERE:在分组前进行过滤,不能使用聚合函数。HAVING:在分组后对聚合结果进行过滤。- 执行顺序:
FROM -> WHERE -> GROUP BY -> 聚合函数 -> HAVING -> SELECT -> ORDER BY -> LIMIT。
2. 排序区别
- ORDER BY:全局排序,但可能效率低下。
- SORT BY:在每个Reduce任务内部排序。
- DISTRIBUTE BY + SORT BY:先按指定字段分区到不同Reduce,再在每个分区内排序。
- CLUSTER BY:当
DISTRIBUTE BY和SORT BY字段相同时,可使用CLUSTER BY(仅升序)。
3. 连接查询(JOIN)
Hive支持等值连接、左/右/外连接。优化原则:将最大的表放在JOIN语句的最后,以减少Reduce端需要缓存的数据量,降低内存压力。
-- 建议写法:大表放最后
SELECT a.val, b.val, c.val
FROM medium_table a
JOIN small_table b ON a.key = b.key
JOIN large_table c ON a.key = c.key;
 发表于 2025-12-10 01:17:47
|
查看: 151|
回复: 0
发表于 2025-12-10 01:17:47
|
查看: 151|
回复: 0
