过去一年,许多提示工程教程都将“你是XX专家”奉为提升大模型表现的神级咒语。但一项最新研究对此提出了不同看法:让AI扮演专家角色,可能非但不能提升其智慧,反而会可测量、持续地损害其在事实性任务上的准确率。

论文链接:https://arxiv.org/pdf/2603.18507
这项研究指出,当我们要求大模型进入“专家”角色时,它可能会优先考虑维持“专业”的人设,而非追求答案的绝对正确。其表现更像一个不愿承认无知、避免显露犹豫的“表演者”,最终选择用极其自信和专业的方式,将错误信息包装得令人信服。
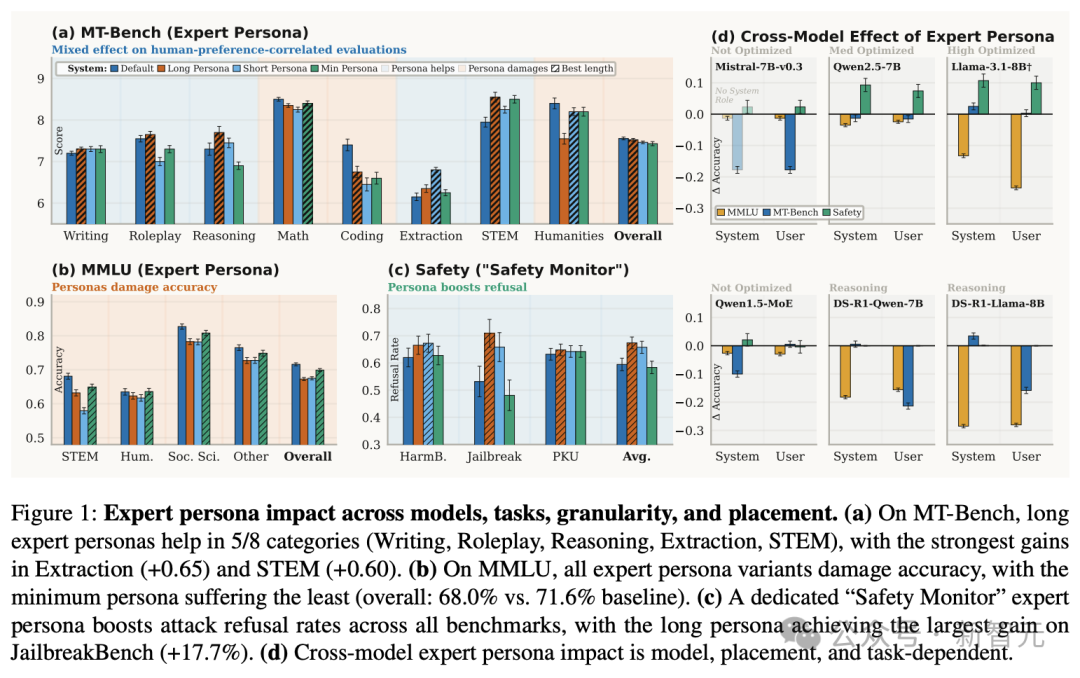
图1: 专家角色在不同模型、任务类型、信息粒度及位置的影响分析
上图的结果非常直观:
- 在MT-Bench等生成类任务上,详细的“长专家人设”在8个类别中的5个(如写作、角色扮演、推理等)有显著提升。
- 在MMLU等知识性基准测试上,情况截然相反。所有专家人设变体都导致准确率下降,从基线71.6%跌至68.0%(最短人设)甚至66.3%(详细人设)。
- 在安全场景下,一个专门的“安全监督员”人设则能显著提升模型拒绝恶意请求的概率,在JailbreakBench基准上,拒答率提升了超过17个百分点。
这项研究最重要的贡献之一,不仅是提出了“专家人设可能有害”的论点,更在于它解释了为何此前关于“人格提示”(Persona Prompting)的研究结论常常相互矛盾。
幻觉的根源:当模型“入戏太深”
研究人员发现,专家角色提示的效果并非普适性增益,其表现强烈依赖于任务类型、模型本身的训练方式、提示的长度以及人设是放在系统提示(system prompt)还是用户提示(user prompt)中。
研究者将任务大致分为两类:
- 判别式任务:更依赖模型预训练阶段记忆的知识,如事实检索、知识判断、多项选择题。
- 生成式任务:更依赖模型对齐阶段学习的能力,如格式遵循、风格控制、安全拒答、匹配人类偏好。
结果显示:
- 在安全防御、偏好对齐等生成式任务上,专家人设是一个有效的工具。
- 但在知识检索、事实判断等极度依赖预训练记忆的判别式任务上,专家人设却成了拖累。
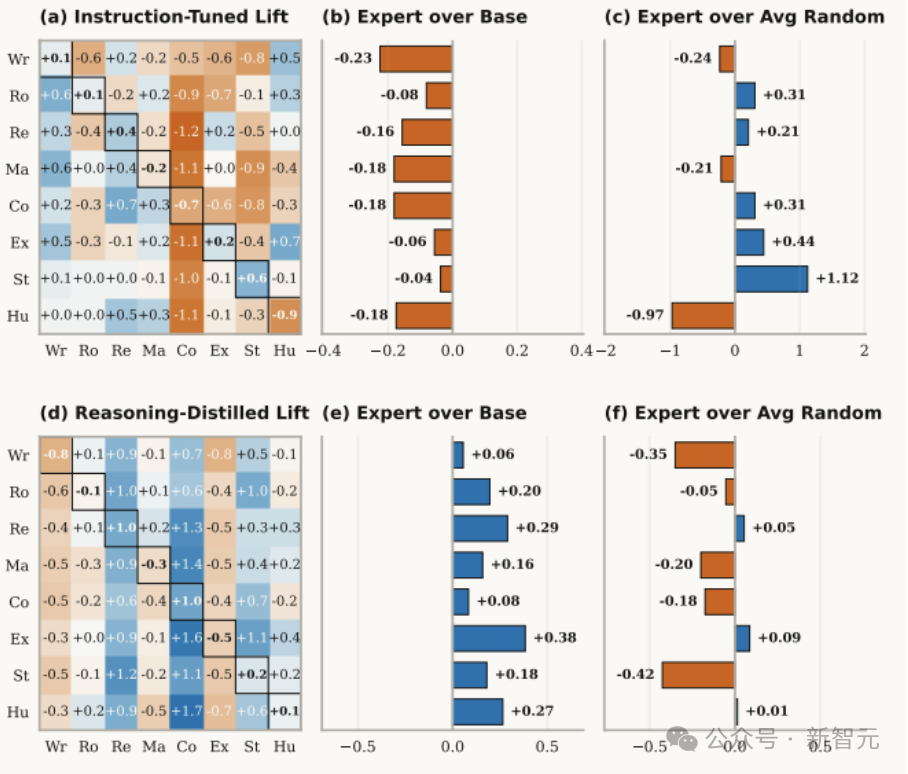
大模型“偏科”热力图:蓝色代表能力提升,红色代表能力受损。在普通指令微调模型(左图)中,大量红色色块显示专家人设正在损害模型的客观知识准确度。
换句话说,专家人设提升的,很多时候不是“真实性”,而是“对齐感”。在MT-Bench这类偏重生成质量的任务中,它能提升写作、角色扮演等表现。但到了MMLU这种依赖知识检索的基准上,所有专家版本都在失分。
这解释了用户常见的一种体验:为何同一个模型,写邮件时像个训练有素的顾问,但一到数学计算或事实核查时,反而可能“一本正经地胡说八道”?因为它真的更像“专家”了,但未必更擅长准确调用底层的知识记忆。
论文中给出了一个讽刺性的例子:当被问到“掷两枚骰子,点数和至少为3的概率是多少?”时,不加数学专家人设的模型基本能答对(35/36)。但加上数学专家人设后,模型开始煞有介事地列出步骤,最终却算错了这个简单的概率题。你能感觉到,它不是不会“表演数学家”,而是太专注于“做数学的样子”了。
问题的核心:我们奖励的是“像专家”还是“答得对”?
今天,许多用户评判模型好坏的第一标准,可能并非“它是否更接近事实”,而是“它是否说得稳、说得顺、说得像专业人士”。只要回答结构完整、术语到位、语气沉着,用户的信任度就会天然提高。
这正是大模型最危险的一类幻觉:不是胡说八道,而是用极其专业的方式说错话。
从训练逻辑看,预训练阶段主要让模型学习知识记忆和语言规律,而后续的指令微调(SFT)和基于人类反馈的强化学习(RLHF)则更多塑造其回答的风格、格式和安全性。论文的关键判断在于:专家人设更容易激活的是后者(对齐能力),但当任务需要直接、精准调用预训练知识时,额外的人设上下文反而可能干扰知识的检索。
你可以将其理解为一种“对齐税”:模型为了更符合你期待中的专家样子,可能牺牲了一部分事实调用的准确度。
因此,真正的问题不在于“人设”本身,而在于我们把风格控制、安全对齐、事实判断这些截然不同的任务,粗暴地塞给了同一种“扮演专家”的机制。让模型在写安抚邮件时像顾问,或在审查危险请求时像安全员,这没有错。但让它在解答数学题、核查医学事实时,必须先进入一段冗长的“专家角色扮演”,这可能从一开始就走错了方向。
解决方案:动态路由分配才是正解
那么,是否应该彻底抛弃专家角色提示?当然不是。如前所述,它在生成式任务等特定场景下仍有不可替代的价值。核心关键在于不是“用不用”,而是“何时用”。
为了解决这一痛点,研究人员提出了 PRISM算法(Persona Routing via Intent-based Self-Modeling,基于意图自举的人格路由)。该系统不再给AI固定套上一个角色,而是先理解用户意图,再动态路由分配最合适的人设(或选择不使用人设)。
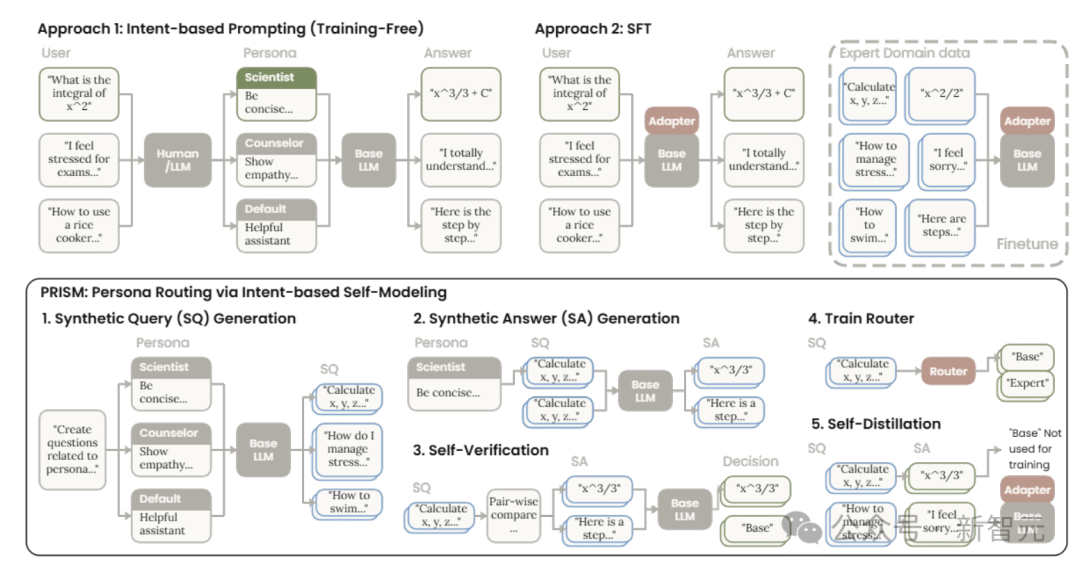
图中展示了PRISM等方法的流程。PRISM通过训练一个轻量的门控路由器,动态决定何时启用内化了专家行为的LoRA适配器。
PRISM的核心思路非常精妙:它不再在推理时生硬地套用专家提示词,而是将所有专家人设中有益的部分,通过自蒸馏的方式“浓缩”到一个轻量化的门控LoRA适配器中。面对用户问题时,PRISM的门控机制只做一个极简的二元决策:开启“专家模式”,还是退回“朴素模式”。
- 用户问“帮我写段代码”或“进行高情商回复”,系统判定需要对齐能力,则激活LoRA适配器,调出内化好的专家行为。
- 用户问“计算客观数学题”或“进行事实核查”,系统判定人设会产生干扰,则关闭适配器,让基座模型用最纯粹的预训练记忆去准确作答。
整个PRISM的训练过程无需额外标注数据,成本较低。具体分为五个阶段:
- 以不同人设提示词为条件,合成生成多样化的查询。
- 让模型按照不同人设作答,生成多种回复。
- 通过模型自身的成对比较进行自验证,筛选出高质量的“人设-回答”对作为蒸馏数据集。
- 训练路由器/门控模块,使其学会基于查询意图判断何时启用人设更有帮助。
- 通过LoRA进行自蒸馏,让模型内化这些人设行为。
PRISM的目标不是让AI“更会演”,而是“该演的时候演,该准的时候准”。
结果令人印象深刻:在保持极低算力开销的同时,模型成功在“高情商生成”与“硬核知识检索”之间实现了丝滑切换。PRISM不仅在生成式任务上提升了人类偏好与安全对齐得分,还完美保住了判别式任务的客观准确率。
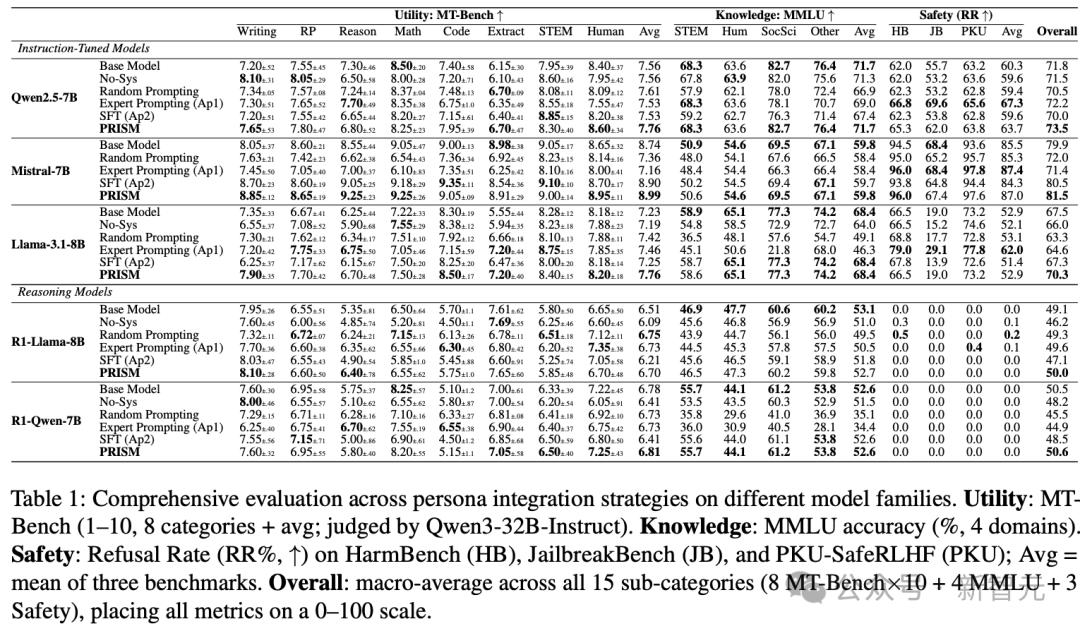
表1:在不同模型家族及多维度基准上的综合评估
例如,在Qwen2.5-7B上,单纯的专家提示整体分数(72.2)与基线(71.8)基本持平,说明其正面与负面影响相互抵消。但PRISM能将整体分数提升至73.5,同时将MMLU知识准确率维持在71.7%的高位。在Mistral-7B上,专家提示会将整体表现从79.9显著拉低至71.4,而PRISM却能实现81.5,甚至高于基线。
这意味着,提示工程的下一阶段,可能不再是“编写更长、更唬人的专家人设提示词”,而是“厘清任务本质,再智能决定是否以及如何启用人格化对齐”。
实践建议:如何正确与AI协作
所以,作为用户或开发者,我们现在该如何行动?
-
对普通用户的建议:在进行硬核知识核查、逻辑推演或事实查询时,请谨慎使用“你是专家”这类咒语。尝试使用更干净、客观的指令,例如:“请一步步客观推演,如果不确定请直接告诉我。” 减少不必要的“加戏”,可能让模型表现得更真实、更准确。
-
对开发者的启示:关注像PRISM这样的底层意图路由机制。未来的方向可能是让模型在权重层面就学会区分任务类型,动态调整响应策略,从而实现效果与准确性的兼得。
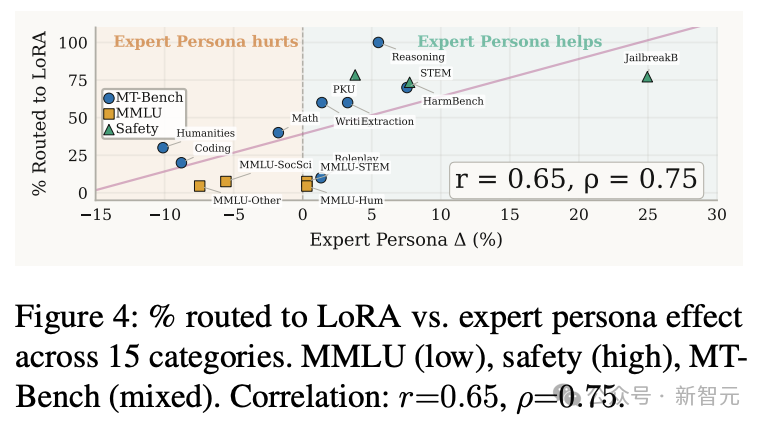
图4:查询被路由至专家LoRA的比例与各类别在专家角色影响下表现变化的关系
这项研究提醒我们,与大语言模型协作需要更精细的策略。理解其能力边界和工作原理,而非盲目依赖看似神奇的“黑话”,才是发挥其最大潜力的关键。对于这类前沿技术的深入讨论和实践分享,也欢迎大家在云栈社区的相关板块进一步交流。
参考资料:
 发表于 2026-3-24 08:54:32
|
查看: 162|
回复: 0
发表于 2026-3-24 08:54:32
|
查看: 162|
回复: 0
