今天在 GitHub 上发现了一个叫 gstack 的项目,短短几天内就冲到了 4.8 万 Star。
这引起了我的好奇。它不是什么新框架或新模型,说到底就是一套给 Claude Code 用的工作流配置。但再看一眼作者,我就决定必须认真研究一下了——Garry Tan,全球顶级创业孵化器 Y Combinator 的现任 CEO。他亲自开源的东西,份量自然不同。
gstack 到底是什么?
简单说,gstack 是 Garry Tan 开源的一套 Claude Code 工作流配置。它做了一件很酷的事:把一个功能强大的 AI 助手,拆解并管理成了一支分工明确的虚拟团队。
这套系统定义了 15 个工具或“角色”,覆盖了软件开发的完整生命周期。比如:
/plan-ceo-review:从 CEO 视角出发,逼你从产品第一性原理想清楚“为什么要做”。/plan-eng-review:以工程经理的视角,把 CEO 的想法翻译成架构图、数据流和边界用例。/review:扮演一个“偏执的高级工程师”,专门揪出 N+1 查询、并发 bug 和信任边界漏洞。/ship:作为发布工程师,负责 PR 合并、运行测试并最终上线。
根据官方介绍,Garry Tan 本人使用这套系统,在 60 天内写出了超过 60 万行生产代码(其中35%是测试代码),质量颇高。
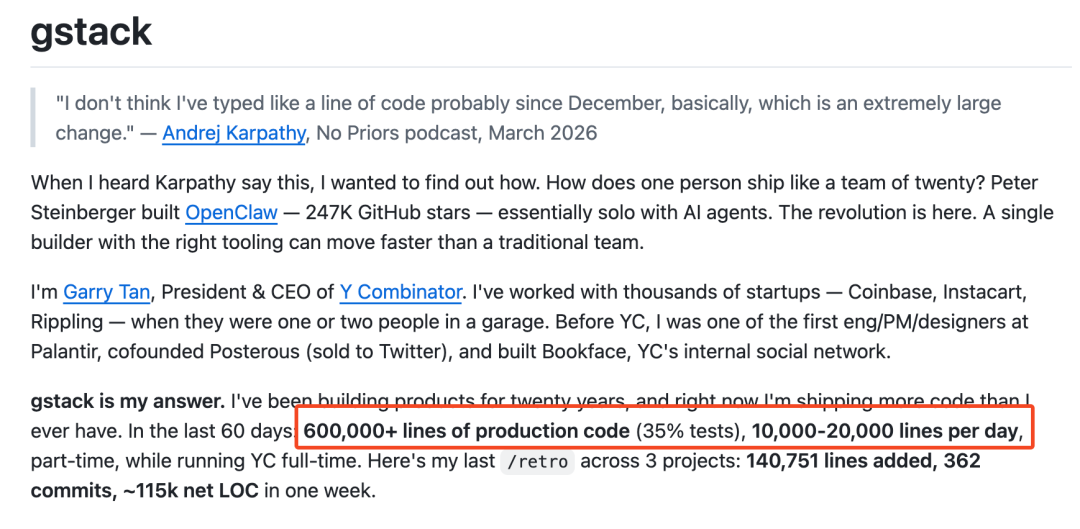
一个人,借助 AI,在短时间内产出如此大量的有效代码,这究竟是怎么做到的?答案或许在于其核心的设计哲学。
核心逻辑:AI 的“认知换挡”
读完对 gstack 的深度解析后,我被一个概念击中了:Cognitive Gearing,认知换挡。
这个道理其实很朴素——一个负责写代码的 AI,和一个负责审查代码的 AI,它们本就不该是同一套思维模式。如果你让一个 AI 同时承担产品构思、代码实现和安全审计的工作,结果往往是“平均主义”,每件事都做得不差,但每件事都不够极致。
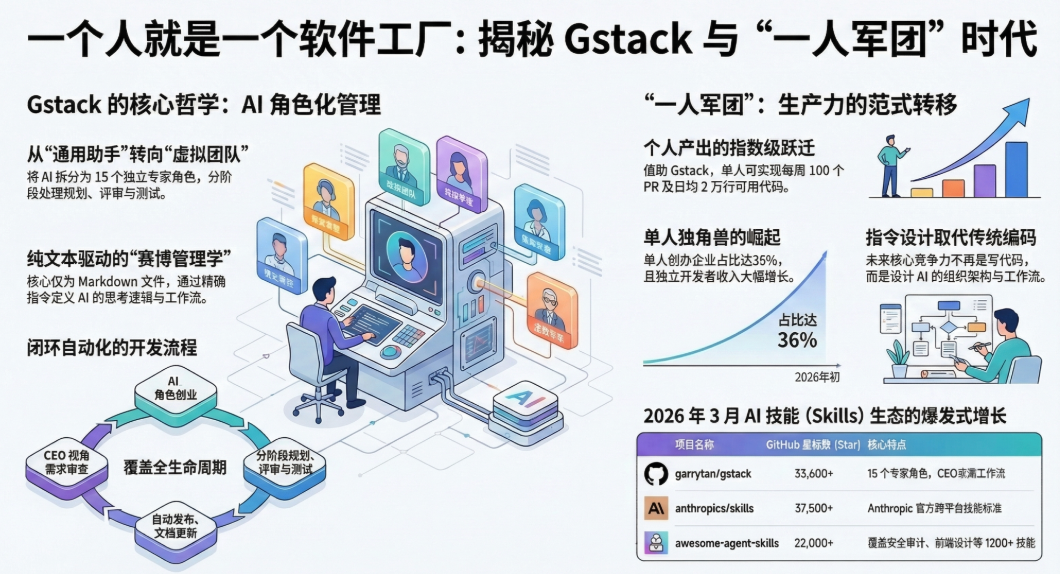
gstack 的解法正是 “角色约束”。通过精确的指令定义,让 AI 在每个阶段只专注于一项核心任务。一个被明确告知“你是安全审计员,目标是寻找信任边界漏洞”的 AI,其审查输出的质量,与一个泛泛的“帮我看看代码”的指令相比,可能会相差一个数量级。
这不新鲜,这就是分工协作,是康威定律在 AI 时代的映射。但 Garry Tan 的价值在于,他不仅提出了理念,还用简单的 Markdown 文件将其落地并开源,让你可以直接上手。
gstack 的标准工作流
为了更清晰地理解,我们可以将其标准开发流程整理成数据流:
用户输入需求
↓
[/plan-ceo-review]
CEO Agent:重新定义问题 → 找 10 星产品方向 → 输出产品策略文档
↓
[/plan-eng-review]
工程经理 Agent:拆解架构 → 定义数据流 → 识别边界用例 → 输出工程蓝图
↓
[开发阶段](人工编码 or AI 编码)
↓
[/review]
偏执高级工程师 Agent:扫描 N+1 / 并发问题 / 信任边界 / 重试逻辑 → 输出 review 报告
↓
[/ship]
发布工程师 Agent:同步主分支 → 跑测试 → 解决 review 问题 → 提交 PR → 上线
↓
[/retro](可选)
复盘 Agent:记录决策、教训、改进点
这个流水线乍看很像一个规范工程团队的敏捷流程,但它的本质是 一个人通过切换不同的 AI 角色,来模拟并驱动整个团队的工作流。这非常聪明,但也意味着执行过程本身就有一定的“重量”。
“无人干预”的诱惑与风险
说到这里,我开始对 gstack 架构文档中的一句话产生了疑虑:
“The agent should be able to read the error and know what to do next without human intervention.”
听起来很美好,对吧?但仔细一想,这句话需要拆开来看。
第一,什么场景的“错误”?
如果是编译失败、依赖缺失这类技术性问题,AI 自行处理非常合理。但如果是业务逻辑的歧义呢?比如“用户删除账户”应该是软删除还是硬删除,如果产品文档没写清楚,AI 擅自做了决定,可能就埋下了未来的隐患。
第二,自主权等于潜在的失控风险。
“无需干预”意味着你可能在事后才知道 AI 做了什么。想象一下,在你睡觉时,你的代码库被 AI 修改了 200 个文件。你来得及逐一审查吗?
所以,“无人干预”本身并非一个默认的“优点”,它是一个需要谨慎设计边界才能安全启用的特性。对于业务逻辑高度敏感,比如金融或医疗系统,这可能就是一个禁忌。
一个现实问题:Token 消耗
我们来谈谈成本。gstack 工作流中的每个 Agent 都是独立的 Claude Code 调用,都会消耗上下文 Token。
对于一个中等复杂度的功能,走完完整流水线,Token 消耗大概是多少?我们做个粗略估算:
/plan-ceo-review:输入约 2k token,输出约 3k token/plan-eng-review:输入需求 + CEO 文档约 5k,输出架构文档约 5k/review:代码量假设 500 行,输入 + 上下文约 10k,输出 review 约 3k/ship:相对轻量,约 5k
一个完整的 Feature Cycle 大约消耗 30k – 50k token。
按照 Claude Sonnet 的价格,大约是 0.15 – 0.3 美元/次。如果你每天推进 5 个功能,月底的 Token 账单可能在数百美元。
这个成本能否接受?答案很现实:取决于你的时薪。如果你的时间价值很高,这笔费用或许微不足道。但如果你是预算紧张的独立开发者或学生,就需要认真计算一下投入产出比。
那么,gstack 适合你吗?
我的观点很直接:不适合所有人。
gstack 明确的目标用户是:技术型创始人、刚开始深度使用 Claude Code 的工程师、以及希望自动化部分评审与质量保证流程的工程负责人。
如果你是以下情况,gstack 可能不是最佳选择:
- 你的项目还在 Idea 阶段:需求未稳,走完整流水线是浪费,快速原型实验才是关键。
- 团队已有成熟的 PR Review 流程:强行引入可能造成流程冲突,增加混乱而非效率。
- 你对 Claude Code 还不熟悉:gstack 是高级配置,不是入门教程,没有基础容易望而生畏。
- 项目高度依赖特定业务语义:如金融、医疗,每个 AI 决策都需人工复核,“无人干预”在此是禁区。
但如果你是一个渴望将个人产出提升一个量级的独立开发者,或是一个希望为小团队建立 AI 原生研发流程的技术负责人,那么 gstack 是一个非常值得你深入研究的优秀起点和灵感来源。
gstack 背后的更大趋势
在研究 gstack 的过程中,我关注到一组数据:截至 2026 年 3 月,Claude Code 生态中已有超过 1200 个经过策展的技能(Skills),而 SkillKit 平台上的技能总数更是超过了 40 万个。
这不仅仅是工具数量的增长,它标志着一种新的“编程范式”正在形成。gstack 的本质,就是用 Markdown 文件定义 AI 的组织架构。打开 SKILL.md,你就能清晰地看到 AI 被赋予了怎样的角色和指令,没有黑盒,极其轻量。
更重要的是,Anthropic 已经将 Agent Skills 做成了一个开放标准,目标是让同一个 Skill 文件能在 Claude Code、Cursor 等不同的 AI 工具上运行。这意味着,Skills 正在成为 AI 工作流的“容器格式”,就像 Docker 对应用程序所做的那样。
Garry Tan 开源的不只是一套配置文件。他开源的是一种组织 AI 劳动力的思维模型:通过将全能型 AI 拆解为多个有限角色的 AI,并配以精心设计的流程,来获得远超单一 AI 助手的输出质量和可控性。这个思路,值得每一位希望严肃使用 AI 工具的开发者、创业者和管理者深思,并尝试在 云栈社区 这样的技术交流平台中探讨其本地化应用的无限可能。
我的最终判断
gstack 非常出色。但“出色”不等于“适合你立刻采用”。
它的核心价值在于,用实际案例证明了基于角色分工的 AI 工作流,在复杂任务上比单一的“万能助手”模式效果更好、更可控。这个结论具有普适的启发性,你无需照搬 gstack 的具体实现,但其“分而治之,角色专精”的思路,完全可以迁移到你为自己设计的任何 人工智能 工作流中。
它的局限也很明显:完整流水线的 Token 成本不菲,“无人干预”的愿景需要极高的信任和精巧的边界设计,并且它目前紧密绑定在 Claude Code 生态中。
在我看来,gstack 带给普通开发者最朴素也是最重要的一课是:
别再一上来就问 AI “帮我写代码”了。先学会让它 “帮我想清楚为什么要写这段代码,以及怎么写才是最合适的”。
这一步的思维转变,你无需依赖 gstack 也能立刻开始实践。而一旦你掌握了这种与 AI 协作的新范式,生产力的天花板将被大幅推高。
 发表于 2026-3-27 04:57:00
|
查看: 180|
回复: 0
发表于 2026-3-27 04:57:00
|
查看: 180|
回复: 0
