如果说 WAL 和 MemTable 解决的是“写进去怎么稳”,那么 SSTable 这一侧解决的就是“读出来怎么快”。真正的读取链路,通常不是打开一个文件、扫一遍这么简单,而是要在多层 SSTable、布隆过滤器、稀疏索引、数据块压缩之间做一连串快速判断。
一次 point lookup,为什么会查很多地方?
先看一个最简单的问题:
get("user:42")
如果数据刚写进去,它可能还在 MemTable。如果已经 flush 过,它就可能落在某个 SSTable 里。如果系统已经运行很久,它甚至可能同时牵涉:
- 新的 L0 文件
- 更深层的 L1/L2 文件
- 还没被 Compaction 清理掉的旧版本文件
这也是 LSM-Tree 读取的第一层直觉:
- 写入快,是因为写路径先顺序化了
- 读取不慢,是因为读路径会不断“剪枝”
这篇文章要讲的,就是这些剪枝动作到底是怎么发生的。如果你想深入探讨更多底层架构设计,欢迎来 云栈社区 交流。
SSTable 到底是什么,它为什么需要分层?
SSTable 可以理解成:
它和普通日志文件最大的不同在于:
- key 是有序的
- 文件一旦生成,内容通常不再原地修改
- 读取时可以利用顺序和元数据快速跳过大量不相关内容
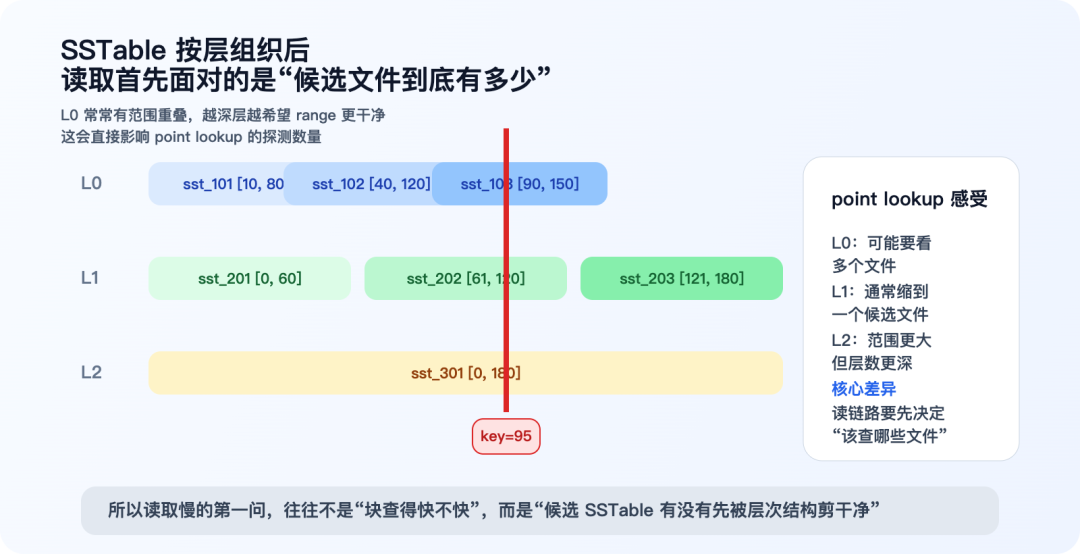
在 LSM 体系里,SSTable 往往还会按层组织。一个很简化的想象版本可以写成:
Level 0: sst_101, sst_102, sst_103
Level 1: sst_201, sst_202
Level 2: sst_301
这里最关键的不是编号,而是层次关系:
L0 常常允许 key range 重叠- 更深层通常会尽量保证 range 不重叠
- 层越深,文件越大,覆盖的数据范围也越广
这会直接影响读取策略。
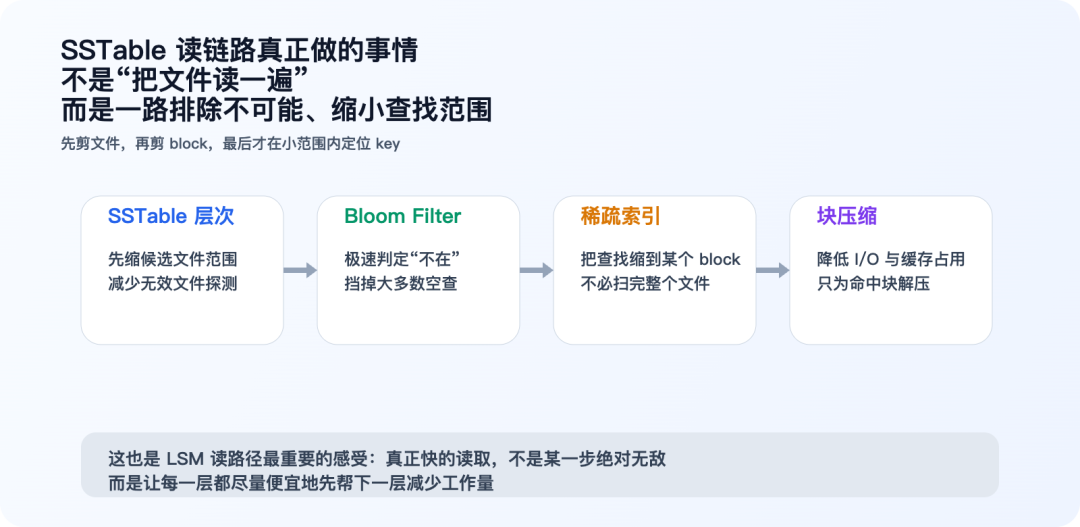
为什么 L0 常常更“麻烦”?
因为 L0 常常是最近 flush 下来的文件。它们来得快、数量也容易多,所以常见特征是:
- 范围可能重叠
- 读一个 key 时,可能要检查多个文件
而到了更深层,系统通常希望把范围整理得更“干净”:
- 一个 key range 尽量只落在一个候选文件里
- 这样 point lookup 才不会层层横跳
读取时真正先做的,不是“打开文件”,而是“先排除不可能”
真正高效的读路径,第一反应通常不是:
而是先问一句:
这正是布隆过滤器(Bloom Filter)的价值所在。
布隆过滤器(Bloom Filter)到底在干什么?
布隆过滤器最值得记住的一句话是:
- 它擅长快速判断“不在”
- 它不负责最终证明“一定在”
也就是说,它最强的能力不是“命中确认”,而是:
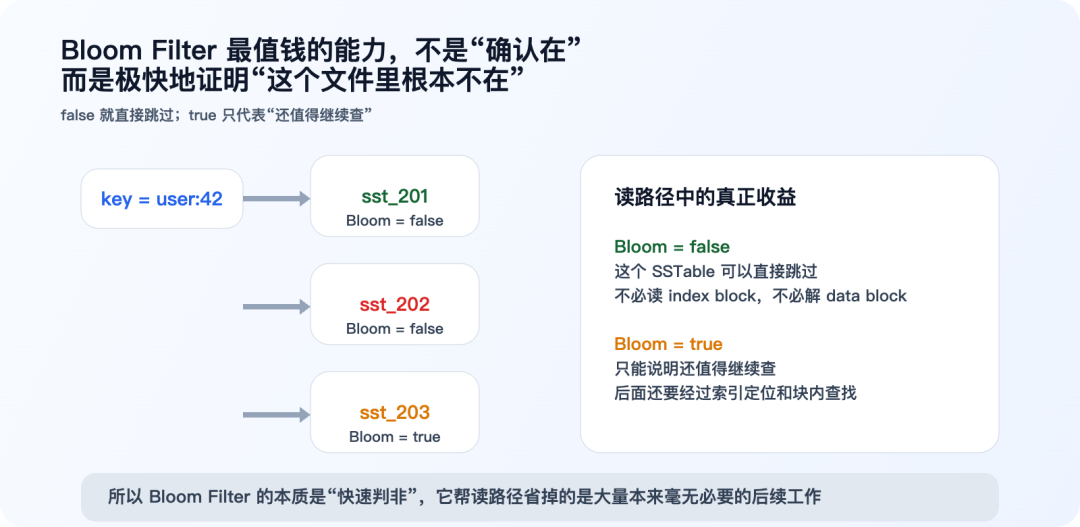
例如一次读取会碰到 8 个候选文件:
for (auto& table : candidates) {
if (!table.bloom.may_contain(key)) {
continue;
}
return table.lookup(key);
}
这里的 may_contain 语义非常关键:
- 返回
false:基本可以直接跳过这个文件
- 返回
true:只能说明“有可能”,还要继续查索引和数据块
这就是“极速判非”这四个字真正的含义。
Bloom Filter 为什么能这么快?

它的核心结构并不复杂,通常就是:
插入一个 key 时:
- 对 key 做多次哈希
- 得到多个位置
- 把这些位置上的 bit 设为 1
查询一个 key 时:
- 还是算出那几个位置
- 只要有任意一个 bit 是 0,就能立刻判定它不在集合里
一个极简伪代码是:
bool may_contain(string key) {
for (auto h : hashes(key)) {
if (bits[h % m] == 0) {
return false;
}
}
return true;
}
为什么它会有误判?
因为多个 key 可能把相同位置的 bit 置成 1。所以查询时会出现一种情况:
- 需要检查的位置刚好都已经是 1
- 但这些 1 其实是别的 key 留下来的
于是它会说:
但真实情况却可能是:
这叫假阳性,也就是 false positive。
为什么大家仍然很爱用它?
因为它没有 false negative。
换句话说,只要布隆过滤器说:
那系统通常就能非常放心地跳过这个文件。
对 LSM 读取来说,这已经非常值钱了,因为真正贵的往往不是算几次哈希,而是:
布隆过滤器挡完之后,接下来为什么还要稀疏索引?
即使 Bloom Filter 说“这个文件可能有”,系统也不会马上把整个 SSTable 读出来。
因为 SSTable 通常不是一个大平面,而是分成很多 data block。所以接下来的问题变成:
这时稀疏索引就上场了。
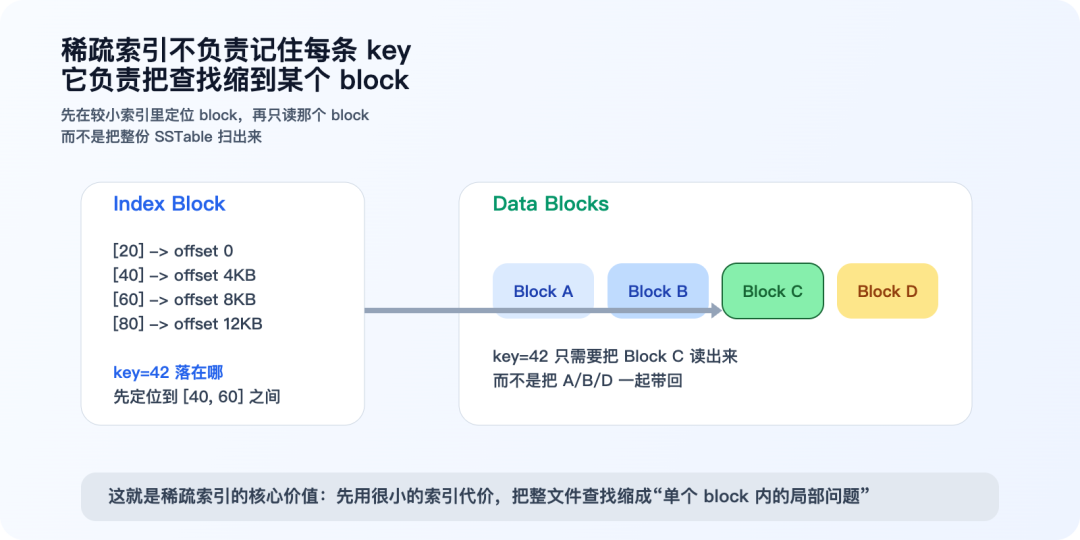
稀疏索引可以理解成:
- 不是记录每条 key 的位置
- 而是记录每个 block 的边界 key 和偏移
一个很简化的样子可以想成:
struct IndexEntry {
string last_key;
uint64_t block_offset;
};
读路径里,它解决的是:
- 先在较小的 index block 里定位候选 block
- 再只读那个 block
- 最后在 block 内部做局部查找
为什么不是“全量索引”?
因为全量索引虽然更细,但内存和存储开销会明显更大。
稀疏索引 的工程取舍在于:
- 先接受“一个 block 内还要再查一次”
- 换来更小的索引体积和更好的缓存命中
这是一种很典型的 LSM 思路:
- 不追求一步到位
- 追求用很小的元数据,把大部分无效工作先剪掉
一次 SSTable 查找,真实路径通常是什么样?
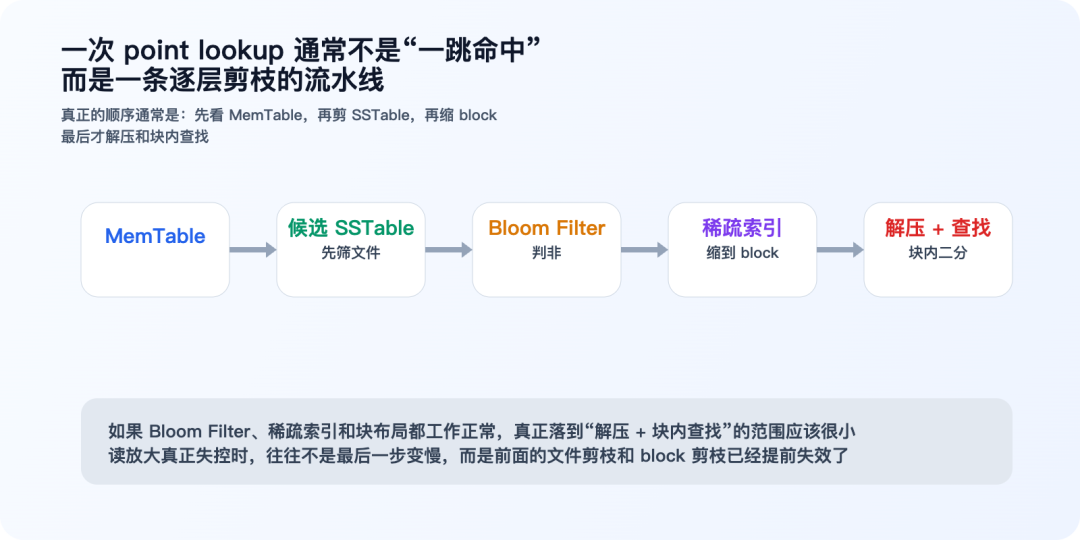
把前面的动作串起来,一次 point lookup 常见的路径可以写成:
Value* get(string key) {
if (memtable.contains(key)) return memtable.get(key);
for (auto& table : sstable_candidates) {
if (!table.bloom.may_contain(key)) continue;
auto block = table.index.find_block(key);
auto data = read_block(block.offset);
auto row = data.binary_search(key);
if (row.found()) return row.value();
}
return nullptr;
}
真正关键的不是这几行代码本身,而是它背后的剪枝顺序:
- 先剪文件
- 再剪 block
- 最后才在小范围内精确查找
如果这个顺序错了,读放大就会迅速失控。
压缩到底在读链路里做了什么?

很多人第一次看到“压缩”时,直觉是:
但在存储系统里,事情没有这么直线。压缩最直接带来的变化是:
- 一个 block 变小了
- 同样一次 I/O 能带回更多有效数据
- page cache 和磁盘带宽的利用率会更高
所以读路径里真正的权衡通常不是:
而是:
- 节省下来的 I/O 和缓存占用
- 是否能覆盖额外的 CPU 解压成本
为什么 block compression 很常见?
因为系统通常不会对整个 SSTable 一口气解压,而是:
- 以 block 为单位压缩
- 以 block 为单位读取和解压
这样做的好处是:
- 随机读取时不需要解整个文件
- 读链路只为当前命中的 block 支付解压成本
读密集时,常见压缩算法在权衡什么?
工程里常见选择大概是:
Snappy / LZ4:压缩率不一定最高,但解压快Zstd:压缩率更好,但 CPU 成本通常更高
所以选择时更像是在问:
稀疏索引之外,块内为什么还会做前缀压缩?

SSTable 里的 key 往往有明显前缀相似性。例如:
user:42:name
user:42:email
user:42:last_login
如果每条都完整存一遍,空间会浪费很多。所以很多实现会在 block 内做前缀压缩:
- 当前 key 和前一个 key 共享的前缀不再重复存
- 只存“共享前缀长度 + 剩余后缀”
一个极简想象版本可以写成:
struct EncodedKey {
uint16_t shared_prefix;
uint16_t suffix_len;
bytes suffix;
};
这样做可以显著减少:
- block 体积
- page cache 占用
- 磁盘带宽消耗
但代价也很明确:
- block 内随机定位会更复杂
- 所以很多系统会定期放一个 restart point
也就是说,它不是把块内查找做成完全顺滑的一维数组,而是:
- 每隔一段放一个可直接恢复的位置
- 在 restart point 之间做有限回放
为什么范围扫描和点查找的最优策略不完全一样?

point lookup 最在乎的是:
- 尽快证明“这个文件不必看”
- 尽快缩到一个 block
range scan 更在乎的则是:
这也是为什么同一套 SSTable 结构里:
- Bloom Filter 对 point lookup 价值特别高
- 稀疏索引和块布局对 range scan 也同样关键
系统读路径不是只有一种“最优”,而是:
真实读放大,通常不是某一个点慢,而是每层都没剪干净
如果一个读取慢下来,常见原因通常是这些:
- L0 文件太多,候选文件数暴涨
- Bloom Filter 太稀,假阳性太高
- 稀疏索引粒度不合适,命中 block 还是太粗
- block 太大,单次读取带回太多无关数据
- 压缩算法 太重,CPU 时间吃掉了 I/O 优势
所以读链路优化常常不是改一个参数就结束,而是把这几个剪枝层次一起看。
开源系统里常见的取向
这一类系统在方向上通常很一致:
- SSTable 保持有序不可变
- 用 Bloom Filter 快速判非
- 用稀疏索引把读缩到 block 级别
- 用块压缩减少磁盘和缓存压力
差异主要出在这些地方:
- L0/L1 的组织策略
- Bloom Filter 的 bits per key 取值
- index block 的粒度
- 块大小和 restart point 间隔
- 默认压缩算法选型
也就是说,读链路这件事并不是靠单一技巧赢的,而是靠一串足够便宜、足够稳定的剪枝动作叠出来的。
给团队的读取链路检查清单

如果把这篇压成一组工程判断,最值得反复确认的通常是这些:
- 先区分读慢是 point lookup 还是 range scan
- 先看候选 SSTable 数量,再看单文件内部定位成本
- Bloom Filter 的目标是快速判非,不是精确命中确认
- 稀疏索引的重点是“缩到 block”,不是替代 block 内查找
- 压缩要连着 I/O、缓存、CPU 一起看,不能只看压缩率
- 块内前缀压缩要配 restart point,别把查找路径做成线性回放
- 读放大通常是多层剪枝失效叠加,不要只盯着某一个参数
- 读路径调优时,始终记住一个顺序:先剪文件,再剪块,最后才精确定位
 发表于 2026-3-30 04:10:44
|
查看: 142|
回复: 0
发表于 2026-3-30 04:10:44
|
查看: 142|
回复: 0
